지금의 foundation model은 대체로 각자의 출력 형식에 맞춰 학습된다.
언어 모델은 다음 토큰을 맞히고, 비디오 모델은 다음 프레임을 만들고, 로봇 정책은 다음 행동을 예측한다.
이 방식은 강력하지만 한 가지 질문을 남긴다.
모델이 정말 세계를 이해하는가, 아니면 각 인터페이스에서 그럴듯한 출력을 만드는가?
Orca: The World is in Your Mind는 이 질문을 Next-State Prediction으로 바꿔 묻는다.
다음 단어, 다음 이미지, 다음 action을 직접 맞히기보다, 먼저 세계의 latent state와 그 전이를 학습하고, 이후 텍스트·이미지·행동은 그 latent를 읽어내는 readout으로 다루자는 제안이다.
논문은 이를 “general world foundation model”의 초기 실체라고 부른다.
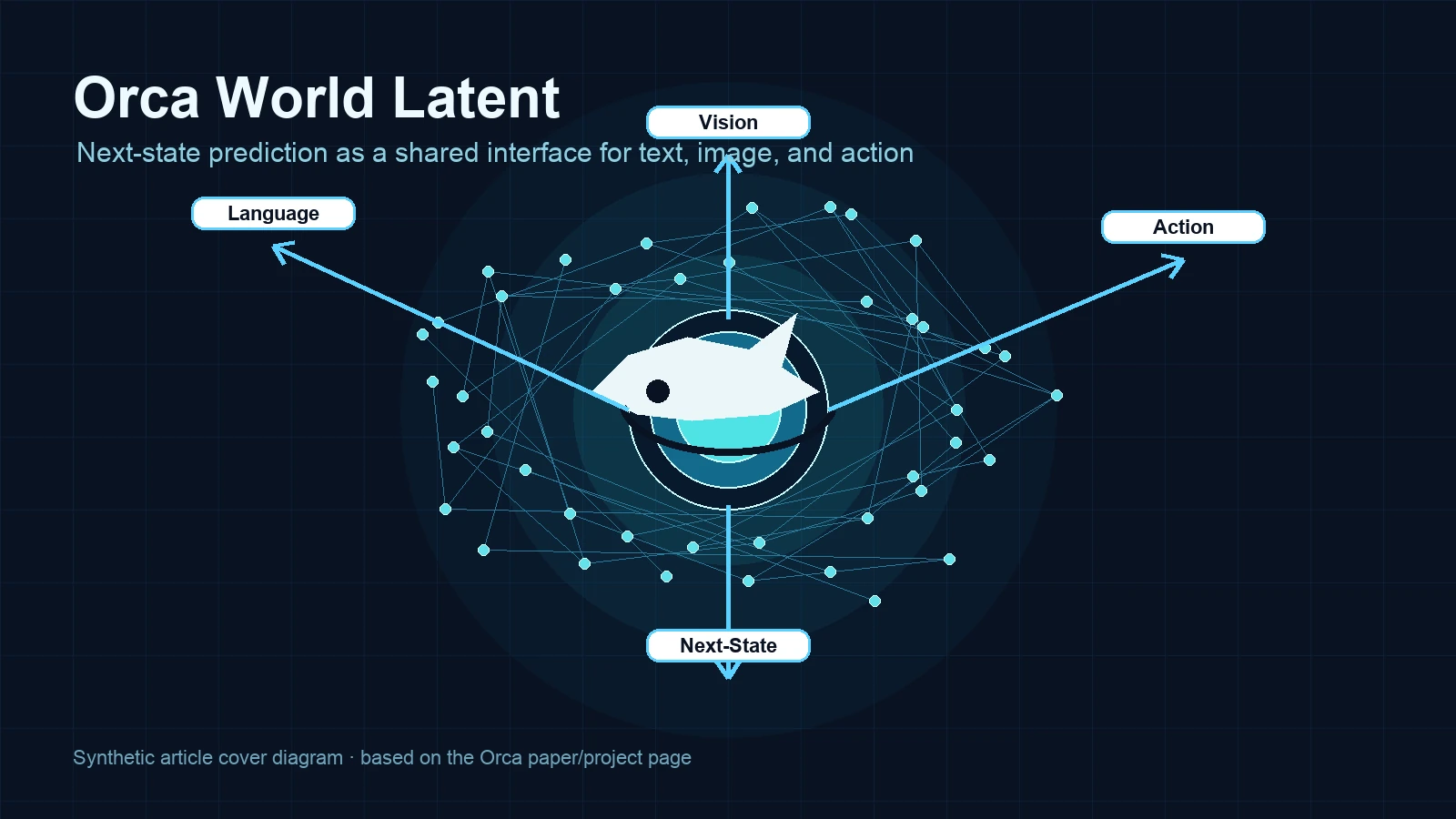
핵심은 “세계 상태”라는 중간 표현이다.
Orca는 멀티모달 신호를 받아 latent world state S로 추상화하고, 현재 상태 S_t에서 미래 또는 과거 상태 S_{t+Δ}로 전이하는 문제를 푼다.
여기서 z_t는 물리 법칙, 물체 속성, 장면 동역학 같은 암묵적 조건이고, c_t는 지시문, 사건, 의도, 질문처럼 언어로 주어진 명시적 조건이다.

무엇을 해결하려는가
논문이 겨냥하는 병목은 “모달리티별 예측 목표가 서로 분리되어 있다”는 점이다.
텍스트 모델은 말로 설명할 수 있지만 물리적으로 일관된 장면 전이를 반드시 갖고 있지는 않다.
비디오 모델은 그럴듯한 프레임을 만들 수 있지만 물체 영속성이나 접촉 관계가 흔들릴 수 있다.
로봇 정책은 demonstration을 흉내낼 수 있지만, 행동 이후 세계가 어떻게 바뀌는지까지 일반화하지 못할 수 있다.
Orca의 답은 출력을 하나로 통일하는 것이 아니다.
오히려 출력은 계속 다르게 둔다.
대신 그 앞단에 공유 world latent를 만들고, 여러 출력 인터페이스가 이 latent를 읽게 한다.
| 구분 | 기존 예측 목표 | Orca의 관점 |
|---|---|---|
| 언어 | 다음 토큰 | 세계 상태에 대한 설명·추론 readout |
| 이미지/비디오 | 다음 프레임 또는 이미지 | latent 상태의 시각적 readout |
| 로봇 | 다음 action | latent 상태와 목표 조건에서 행동 chunk를 생성하는 readout |
| 학습 중심 | 출력 형식별 objective | 상태 전이 자체를 모델링하는 Next-State Prediction |
이 관점에서 Orca는 단순한 VLM이나 비디오 생성기가 아니다.
오히려 “언어, 시각, 행동이 같은 world latent를 다른 방식으로 읽는다면 무엇이 달라지는가”를 실험한 연구에 가깝다.
핵심 구조: 무의식 학습과 의식 학습
Orca는 학습 방식을 두 갈래로 나눈다.
이름은 다소 철학적이지만, 실제 구현상으로는 dense observation learning과 language-conditioned event learning의 조합으로 읽으면 된다.
Unconscious learning은 연속 비디오에서 조밀한 자연 상태 전이를 배운다.
명시적 사건 라벨이나 질문 없이, 현재 프레임에서 다음 프레임의 latent를 예측한다.
물체의 움직임, 접촉, 가림, 장면 변화처럼 언어로 설명하지 않아도 관찰 가능한 동역학을 흡수하는 경로다.
Conscious learning은 언어로 기술된 사건, 지시문, VQA를 이용해 의미 있는 상태 전이를 배운다.
어떤 일이 일어났는지, 다음에 무엇이 일어날지, 왜 그런지, 특정 조건이 주어졌을 때 세계가 어떻게 달라지는지를 언어 조건으로 묶는다.
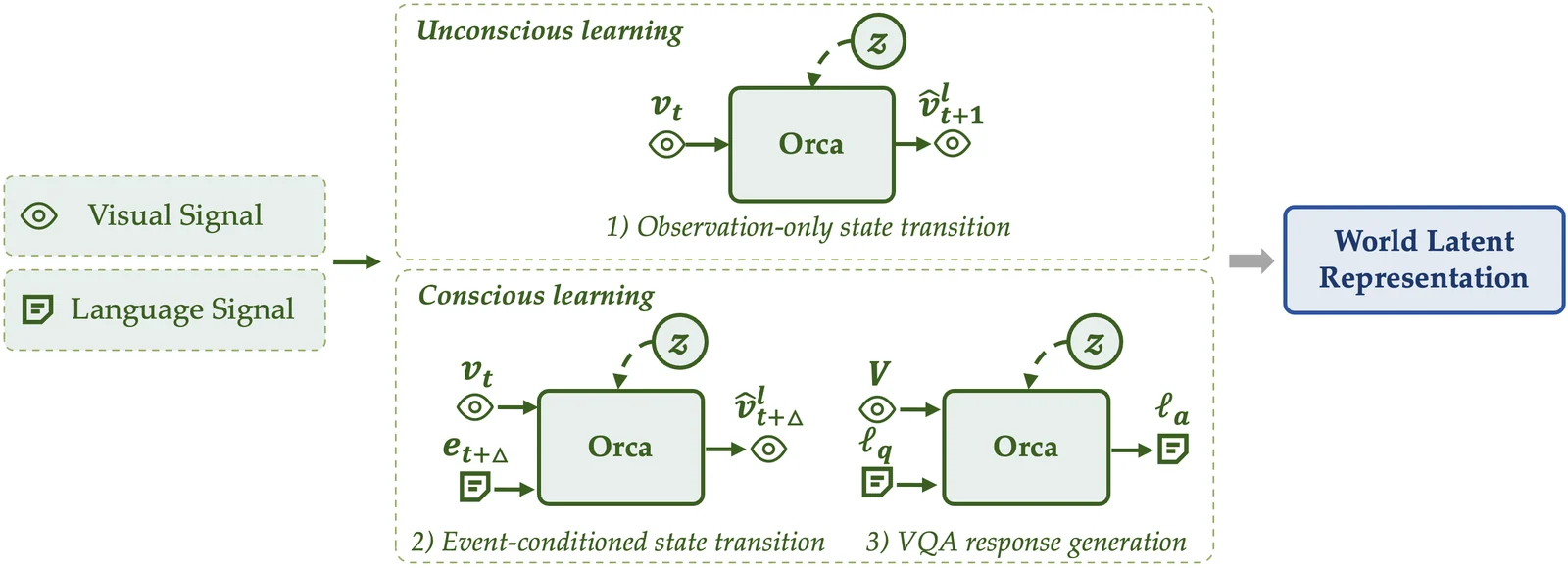
구현은 Qwen3.5 기반 native VLM에서 출발한다.
논문은 Orca-0.8B와 Orca-4B를 제시한다.
입력은 대략 <visual token>, <Query 1>, <Instruction>, <Query 2> 형태이고, 두 query가 서로 다른 전이 경로를 담당한다. <Query 1>은 관찰-only transition을, <Query 2>는 instruction/event-conditioned transition을 맡는다.
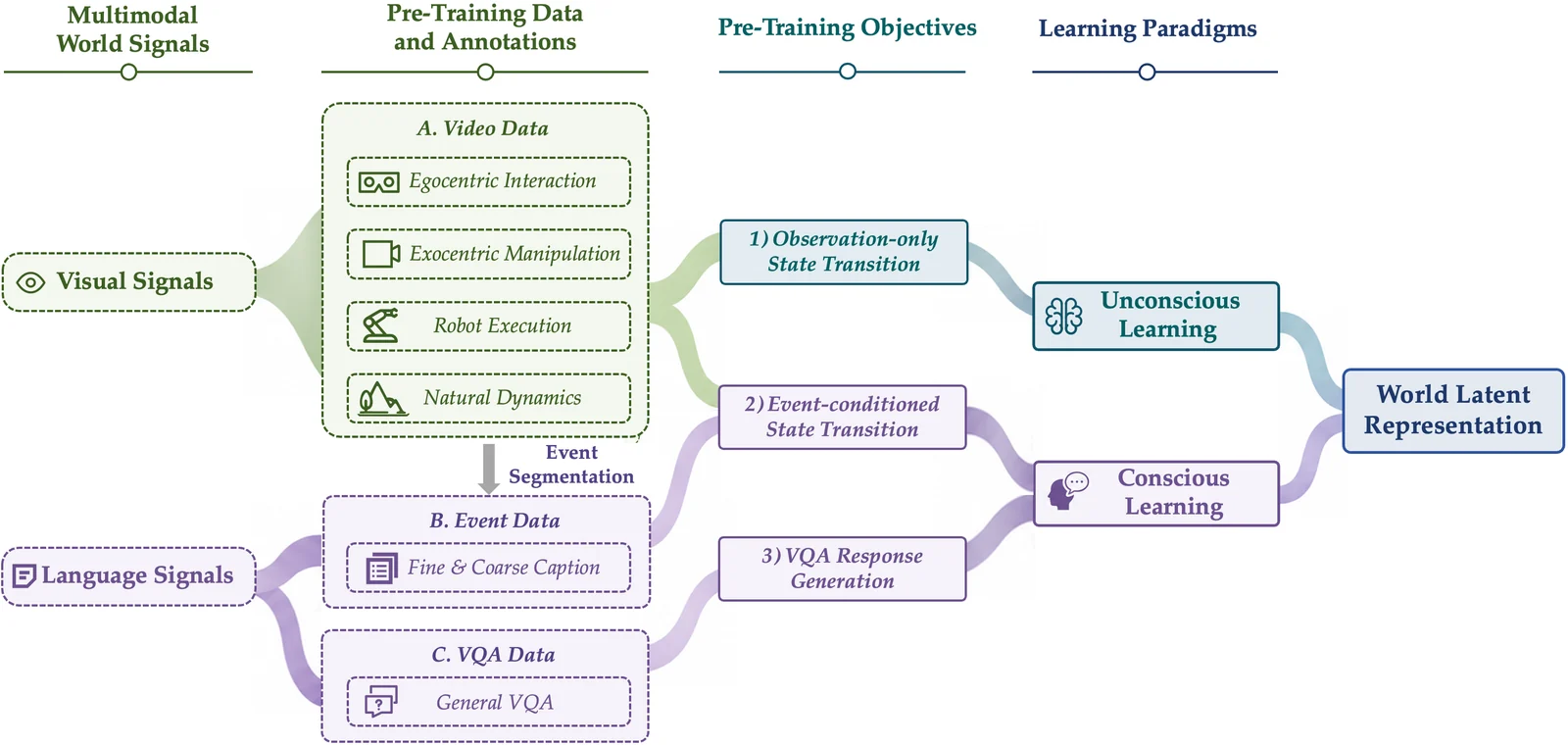
Pre-training objective는 세 가지다.
| objective | 쓰는 데이터 | 역할 |
|---|---|---|
| Observation-only state transition | 연속 비디오 | 현재 시각 상태에서 다음 상태 latent를 맞힌다 |
| Event-conditioned state transition | 이벤트 주석 | 언어로 주어진 사건 조건 아래 이전/다음 상태를 맞힌다 |
| VQA response generation | VQA 샘플 | world latent가 질문 조건의 언어 응답에도 쓸 수 있게 한다 |
공식 project page가 정리한 world-learning resource 규모는 꽤 크다.
| 리소스 | 규모 | 학습 역할 |
|---|---|---|
| Continuous video | 125K hours | 조밀한 자연 상태 전이를 위한 관찰 신호 |
| Event annotations | 160M events | 의미 있는 causal state transition을 위한 추론 신호 |
| VQA examples | 11.5M examples | 질문 조건의 세계 이해 신호 |
다만 여기서 inventory 전체 규모와 실제 보고된 training run은 구분해야 한다. arXiv 부록의 hyperparameter table은 Orca-4B와 Orca-0.8B pre-training 설정에 대해 32 nodes / 256 GPUs, 10,844 training steps, approximate video hours 12.5K h를 적고 있다.
즉 논문은 125K 시간급 inventory를 구축했다고 말하지만, 이번 실험의 핵심 run은 그 일부 규모로 읽는 편이 안전하다.
Readout 실험: backbone을 얼리고 latent를 시험한다
논문의 좋은 점은 “world latent를 배웠다”는 말을 downstream readout으로 시험한다는 데 있다.
Pre-training 후 Orca backbone은 frozen 상태로 둔다.
그리고 각 모달리티별로 상대적으로 가벼운 decoder/readout만 학습한다.
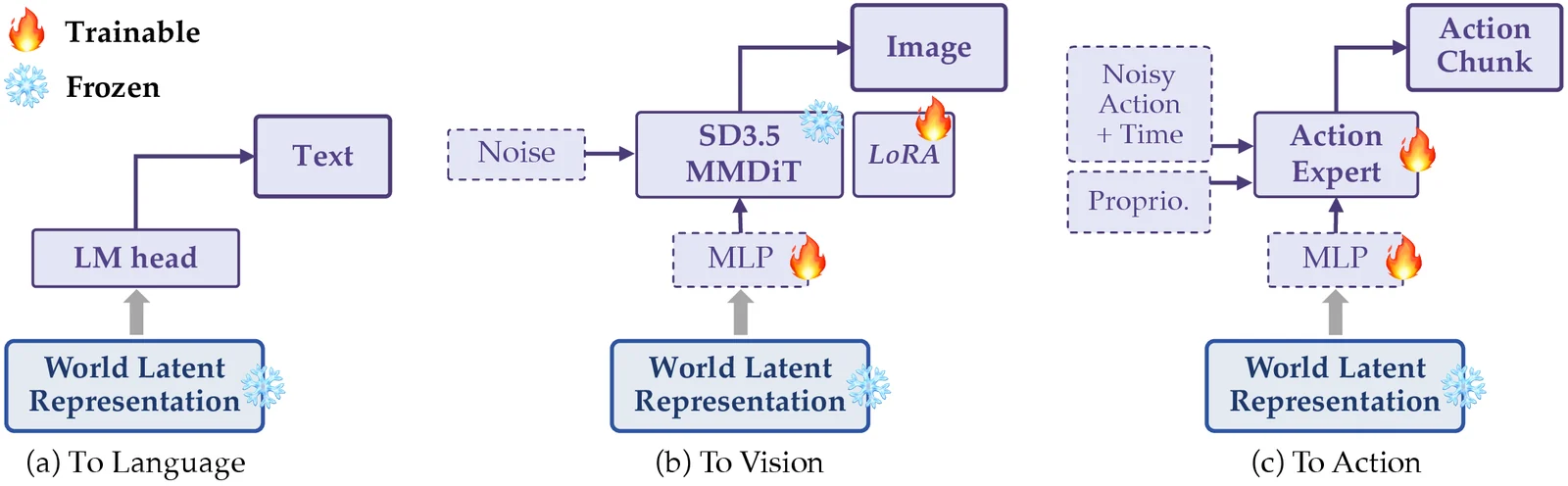
이 설계는 평가상 중요한 의미가 있다.
Downstream 성능이 오르면 “readout decoder가 모든 것을 새로 배웠다”기보다, frozen Orca latent가 더 쓸모 있는 상태 정보를 담고 있다고 해석할 여지가 생긴다.
물론 readout 자체도 학습되므로 완전히 순수한 probing은 아니지만, backbone을 고정했다는 점은 논문의 주장에 힘을 준다.
실험은 세 방향으로 간다.
| readout | 평가 의도 | 대표 결과 신호 |
|---|---|---|
| Text generation | video/spatial/temporal reasoning | 4B Orca overall 51.8, Qwen3.5-4B 46.7 |
| Image prediction | instruction-conditioned real-world image prediction | 4+2B Orca Avg. 59.8±10.9, FLUX.2 [klein] 56.1±18.1 |
| Action generation | real-robot OOD manipulation | Overall rule-based score Orca 32.4, π₀.₅ 29.4, V-JEPA 2.1 17.0, Qwen3.5 10.5 |
공개된 근거에서 확인되는 점
첫 번째 근거는 scaling이다.
Orca의 world-learning loss는 pre-training data scale이 커질수록 내려가고, 4B backbone이 0.8B보다 낮은 loss를 보인다.
Downstream readout도 pre-training scale과 함께 올라간다.
논문이 말하는 핵심은 “Next-State Prediction objective가 scale에 반응한다”는 것이다.
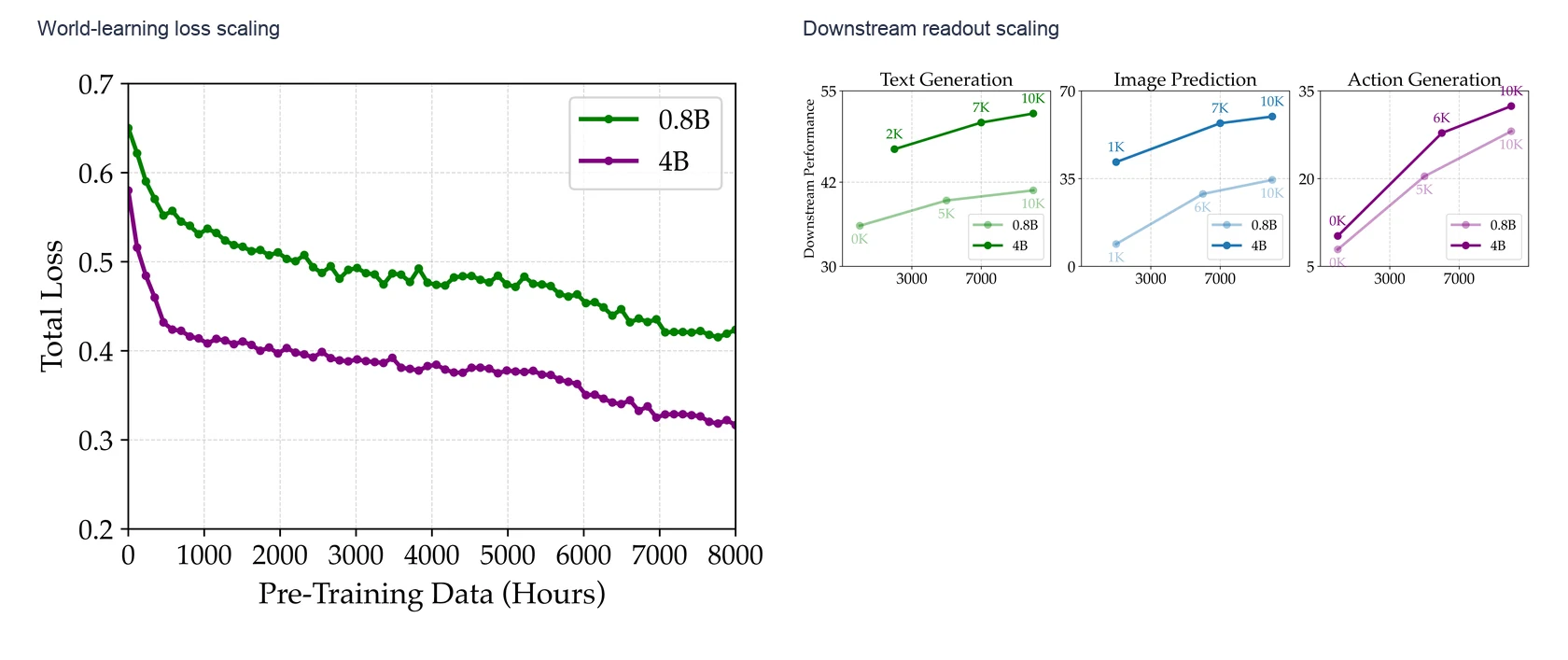
두 번째 근거는 text generation readout이다.
Project page의 표 기준으로 Orca-0.8B는 overall 40.8을 기록해 Qwen3.5-0.8B의 33.1보다 높다.
Orca-4B는 overall 51.8로 Qwen3.5-4B 46.7, Gemma 4-4B 40.8보다 높다.
세부적으로 TemporalBench는 Orca-4B 34.2, Qwen3.5-4B 25.2이고, SWITCH는 Orca-4B 55.6, Qwen3.5-4B 42.8이다.
능력별 집계에서도 차이가 보인다.
Orca-4B는 Qwen3.5-4B 대비 State Transition 64.13 vs 51.86, Dynamic Motion 65.55 vs 57.03을 보고한다.
이 두 축은 논문 주장과 잘 맞는다.
단순 시각 QA가 아니라 상태 변화와 동역학 쪽에서 이득이 커야 world-state objective의 설득력이 생기기 때문이다.
세 번째 근거는 image prediction이다.
PRICE benchmark에서 Orca-4B + 2B vision decoder는 평균 59.8±10.9를 보고한다.
같은 표의 FLUX.2 [klein]은 56.1±18.1, FLUX.1-Kontext는 40.9±13.5, OmniGen2는 39.6±10.2다.
Orca-0.8B + 2B는 34.5±15.3으로 낮으므로, 이 방향은 backbone scale의 영향을 크게 받는다고 보는 편이 맞다.
네 번째 근거는 action readout이다.
공식 표에서 Overall rule-based score는 Orca 32.4, π₀.₅ 29.4, V-JEPA 2.1 17.0, Qwen3.5 10.5다.
Environment OOD에서는 Orca가 rule-based 36.6으로 가장 높지만, Object OOD에서는 π₀.₅가 33.1이고 Orca는 28.2라 모든 축을 압도한다고 읽으면 과하다.
그래도 frozen backbone에서 Action Expert만 새로 학습했다는 설정을 고려하면, latent가 로봇 manipulation에도 일부 전이된다는 신호로는 흥미롭다.
Objective ablation도 중요하다.
VQA만 쓰면 평균 29.3, observation+event만 쓰면 44.6, observation+VQA는 41.6, event+VQA는 42.6이다.
세 objective를 모두 결합했을 때 평균 48.0으로 가장 높다.
즉 “비디오만 많이 보면 된다”거나 “VQA만 더 넣으면 된다”가 아니라, 조밀한 관찰 전이와 언어 조건 전이, 질문 응답 학습이 함께 작동해야 한다는 메시지다.
공개 아티팩트 상태와 주의할 점
확인 가능한 공식 표면은 arXiv v2, Hugging Face Papers page, 공식 project page다. arXiv abstract는 2026년 6월 29일 v1 제출, 6월 30일 v2 revision을 표시하고, project page를 공식 companion으로 링크한다.
반면 확인 시점 기준으로 논문 제목이나 arXiv ID에 대응되는 명확한 공식 GitHub repository, Hugging Face model, dataset, space는 찾지 못했다.
그래서 이 글은 “곧바로 다운로드해 재현할 수 있는 공개 모델 릴리스” 소개가 아니다.
현재 공개 자료만 기준으로 보면 Orca는 큰 world-modeling research proposal과 실험 결과에 가깝다.
모델 weight, data recipe, action expert training code, PRICE evaluation harness가 공개되지 않은 상태라면, 제3자가 수치를 바로 재현하거나 실무 시스템에 붙이는 것은 별도 문제다.
또 한 가지는 평가 해석이다.
PRICE image prediction은 Gemini, GPT, Doubao, Gemma 같은 judge를 쓰는 비교이고, action generation은 PRM-as-a-Judge 기반 trajectory-level diagnostic을 포함한다.
이런 평가는 실제 사용감을 잘 반영할 수 있지만, judge 선택과 task construction에 민감하다.
따라서 숫자는 “Orca가 모든 image/video/robotics 모델을 일반적으로 이겼다”가 아니라, 저자들이 구성한 readout 평가에서 frozen world latent가 경쟁력 있는 신호를 냈다로 읽는 편이 안전하다.
실무 관점에서의 해석
Orca의 가장 큰 의미는 멀티모달 모델을 “입력과 출력이 많은 VLM”이 아니라 상태 전이 모델로 다시 보게 만든다는 점이다.
에이전트, 로봇, 장기 planning, video understanding에서 중요한 것은 단순히 현재 프레임이나 현재 질문에 답하는 능력이 아니다.
지금 세계가 어떤 상태이고, 어떤 조건을 주면 다음 상태가 어떻게 바뀌는지를 모델 내부에 유지하는 능력이다.
이 관점은 LLM 시스템에도 꽤 직접적으로 연결된다.
장기 에이전트가 실패하는 많은 이유는 검색이 부족해서라기보다 state update가 흔들리기 때문이다.
이미 완료한 단계, 실패한 시도, 바뀐 제약 조건, 사용자의 새 요구가 매 turn마다 현재 상태에 반영되어야 한다.
Orca가 모델 architecture 차원에서 world latent를 이야기한다면, 실무 시스템에서는 외부 memory, task state, environment simulator, verifier가 그 역할을 나눠 맡는다.
다만 Orca를 너무 크게 읽을 필요는 없다.
현재 버전은 주로 vision-language 기반이고, 논문이 상상하는 force, tactile, infrared, scientific signal까지 실제로 통합한 범용 세계 모델은 아니다.
또한 32 nodes / 256 GPUs급 설정은 개인이나 작은 팀이 가볍게 재현할 수 있는 규모가 아니다.
“world foundation model이 완성됐다”보다는 “next-state prediction을 중심 objective로 두면 text·image·action readout이 함께 좋아질 수 있다는 초기 실험”으로 보는 편이 더 정확하다.
그럼에도 방향은 흥미롭다.
멀티모달 모델이 정말 세계와 상호작용하려면, 출력 token이나 pixel보다 앞서 상태를 다뤄야 한다.
Orca는 그 상태를 하나의 latent 공간으로 학습하고, 언어·이미지·행동을 그 위의 readout으로 해석한다.
실무적으로는 아직 release maturity가 부족하지만, 연구 방향으로는 “다음에 무엇을 생성할까”에서 “세계가 다음에 어떤 상태가 될까”로 질문을 옮긴다는 점에서 충분히 주목할 만하다.