코딩 에이전트 학습에서 가장 비싼 신호는 종종 “정답을 냈는가”다.
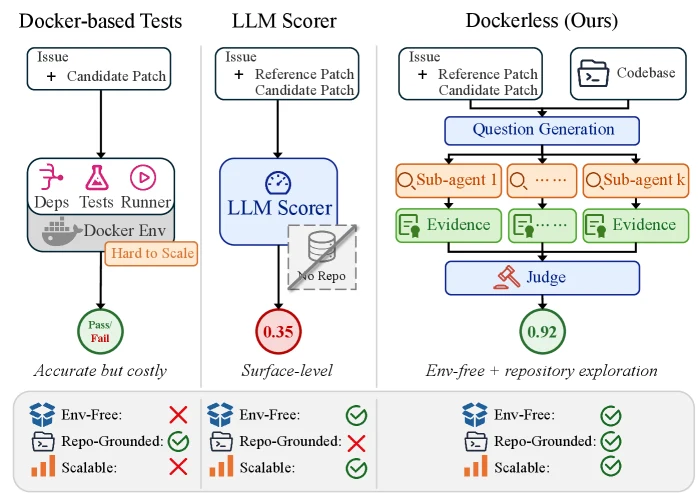
SWE-bench류 태스크에서는 에이전트가 만든 patch를 실제 저장소에 적용하고, 해당 커밋 시점의 의존성을 설치하고, 테스트를 실행한 뒤, 그 결과를 보상이나 필터로 사용한다.
이 방식은 강력하지만 매번 repository-specific Docker 환경이 필요하다.
환경이 깨지거나 테스트가 부족하거나 private/legacy codebase라면 학습 신호 자체가 흔들린다.
Dockerless: Environment-Free Program Verifier for Coding Agents는 이 병목을 정면으로 다룬다.
논문의 핵심 질문은 “테스트를 실행하지 않고도 패치가 맞는지 꽤 잘 판정할 수 있는가”다.
Dockerless는 issue, reference patch, candidate patch를 입력으로 받고, 저장소를 실제로 실행하지는 않지만 read-only shell tool로 탐색하는 sub-agent들을 띄워 근거를 모은 뒤, 최종적으로 candidate patch의 정합성 점수를 낸다.
흥미로운 점은 이 verifier가 단순 평가 도구로 끝나지 않는다는 것이다.
저자들은 Dockerless를 SFT trajectory filtering과 RL reward에 모두 사용해, rollout 수집부터 보상 계산까지 repository-specific Docker 없이 진행되는 post-training pipeline을 구성한다.
결과적으로 Dockerless-RL-9B는 SWE-bench Verified 62.0%, Multilingual 50.0%, Pro 35.2% resolve rate를 보고한다.
무엇을 해결하려는가
코딩 에이전트를 post-training할 때 verifier는 두 군데에 들어간다.
첫째, SFT에 넣을 trajectory를 고르는 필터다.
둘째, RL에서 rollout마다 줄 reward다.
지금까지 가장 믿을 만한 신호는 candidate patch를 실제 테스트로 검증하는 것이었다.
문제는 이 테스트 실행이 대규모 학습에서 꽤 무거운 인프라 작업이라는 점이다.
저장소마다 Docker image, pinned dependency, test runner, held-out test, 결과 parser가 필요하다.
SWE-bench처럼 잘 정리된 benchmark에서도 환경 빌드와 캐시가 큰 운영 부담이고, 현실의 private repository나 오래된 enterprise codebase에서는 reproducible environment가 없을 수 있다.
Dockerless가 겨냥하는 병목은 “에이전트가 환경 없이 코드를 수정할 수 있는가”보다 더 좁다.
논문은 frontier model들이 OpenHands scaffold 아래에서 repository-specific environment를 제거해도 resolve rate 손실이 3.0–13.9포인트 수준이라고 보고한다.
즉 environment-free rollout 자체는 어느 정도 가능하지만, 그 rollout이 맞는지 판단할 verifier가 부족하다는 것이다.
다만 여기서 중요한 전제가 있다.
Dockerless의 verifier 입력에는 reference patch가 포함된다.
따라서 이 논문은 production CI를 곧바로 대체하는 “무정답 실시간 검증기”라기보다, reference solution이 있는 학습 데이터셋에서 test-execution label을 더 싸게 대체하거나 확장하려는 post-training verifier로 읽는 편이 정확하다.
핵심 아이디어 / 구조 / 동작 방식
Dockerless는 두 단계로 움직인다.
첫 단계는 질문 생성과 저장소 탐색이다.
입력은 issue x, reference patch y_ref, candidate patch y다.
모델은 먼저 여러 개의 verification question을 만든다.
예를 들면 다음과 같은 질문이다.
- 수정이 실제로 어느 코드 경로에서 효과를 내야 하는가
- patch가 구현해야 하는 동작은 무엇인가
- 어떤 assertion이나 테스트가 correctness를 확인할 수 있는가
- 주변 모듈과의 통합에서 깨질 수 있는 부분은 무엇인가
각 질문은 별도 sub-agent에게 배정된다. sub-agent들은 repository를 실행하거나 dependency를 설치하지 않고, find, grep, rg 같은 read-only shell tool로 관련 파일과 호출 경로를 살핀다.
이 단계의 목적은 candidate patch와 reference patch의 표면적 diff 유사도를 보는 것이 아니라, 패치가 issue의 기능 요구를 실제 저장소 맥락에서 만족하는지 판단할 근거를 만드는 것이다.
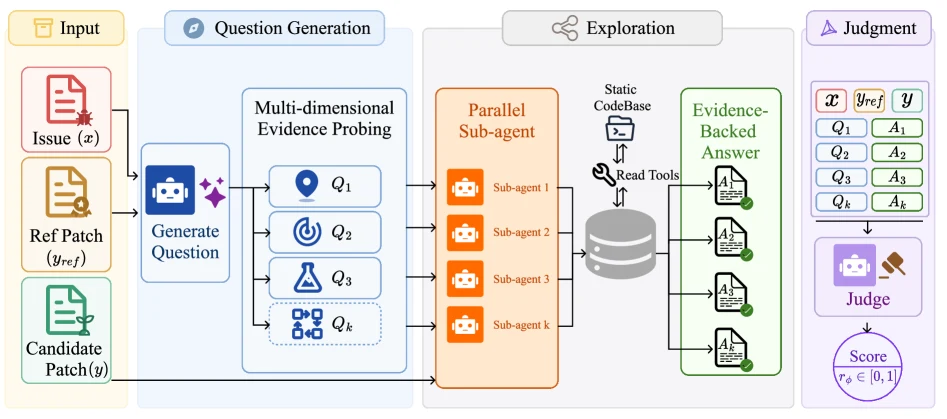
두 번째 단계는 judgment다.
모든 sub-agent answer가 모이면 verifier는 issue, reference patch, candidate patch, Q&A evidence를 조건으로 0 또는 1 verdict token을 출력한다.
논문은 0과 1 token의 logit을 softmax처럼 변환해 r_phi(x, y) 형태의 연속 점수로 사용한다.
이 점수가 SFT filtering에서는 trajectory 선별 기준이 되고, RL에서는 reward가 된다.
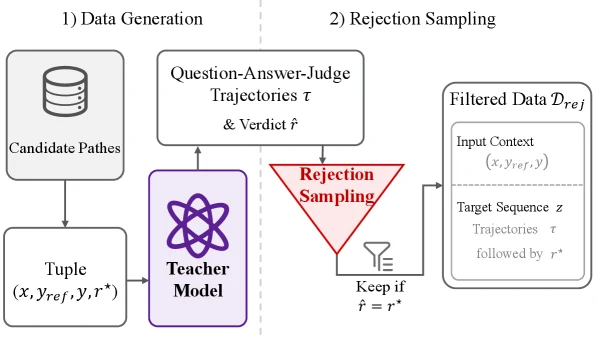
학습은 execution-labeled candidate patch에서 시작한다.
각 예시는 (issue, reference patch, candidate patch, test-based verdict) 형태다. teacher model이 question-answer-judge trajectory를 만들고, 그 최종 verdict가 실제 test label과 일치한 trajectory만 rejection sampling으로 남긴다.
이렇게 남은 trajectory로 verifier를 next-token cross entropy로 학습한다.
논문 기준 Dockerless는 SWE-Gym과 Multi-SWE-RL에서 가져온 3.7K execution-labeled issues로 학습되며, inference에서는 보통 2–4개 verification question을 사용한다.
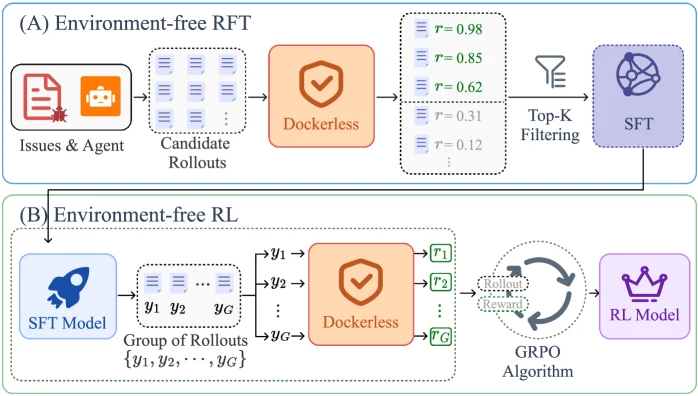
이후 post-training은 두 갈래다.
RFT/SFT 단계에서는 minimal Linux image에서 collected rollout을 만들고, Dockerless 점수가 높은 상위 trajectory를 SFT 데이터로 사용한다.
RL 단계에서는 같은 minimal image에서 rollout을 생성하고, Dockerless 점수를 GRPO reward로 사용한다.
즉 test runner나 repository-specific Docker는 빠지고, verifier만 agentic repository reading으로 대체된다.
공개된 근거에서 확인되는 점
가장 먼저 볼 숫자는 verifier AUC다.
Dockerless는 trajectory-level verifier evaluation benchmark에서 기존 open-source verifier를 크게 앞선다.
| Verifier | SWE-bench Verified AUC | Multi-SWE-bench Flash AUC |
|---|---|---|
| OpenHands Critic | 48.6 | 52.2 |
| SWE-Gym Verifier | 61.0 | 53.7 |
| R2E-Gym Verifier | 64.3 | 55.1 |
| DeepSWE Verifier | 66.7 | 62.9 |
| Dockerless | 81.0 | 72.1 |
논문의 “+14.3 AUC”는 SWE-bench Verified에서 가장 강한 open-source baseline인 DeepSWE Verifier 66.7과 Dockerless 81.0의 차이다.
Multi-SWE-bench Flash에서도 72.1로 DeepSWE Verifier 62.9보다 9.2포인트 높다. zero-shot frontier LLM judge들과 비교해도 Dockerless는 이 표에서 가장 높은 AUC를 낸다.
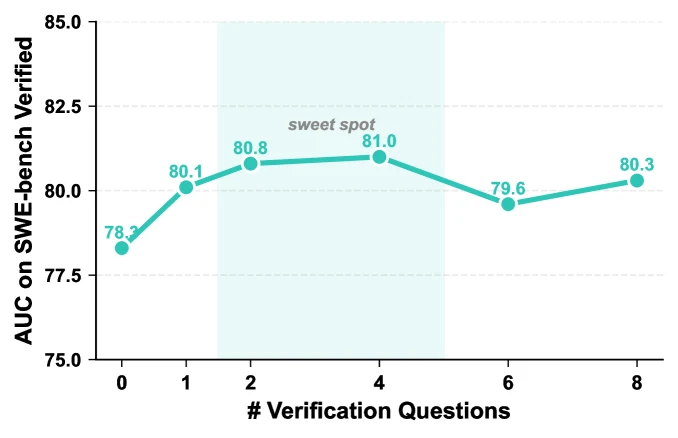
SFT filtering에서도 메시지는 비슷하다.
같은 Qwen3.5-9B backbone과 SFT recipe를 두고, 어떤 trajectory를 학습 데이터로 고르느냐만 바꾼 비교다.
| Training data | Verified | Multilingual | Pro |
|---|---|---|---|
| None / base Qwen3.5-9B | 59.6 | 41.3 | 32.3 |
| All 16K env-free trajectories | 58.8 | 41.3 | 31.9 |
| Random 4K | 58.2 | 44.3 | 32.0 |
| Env-based 4K | 60.0 | 48.3 | 33.9 |
| Dockerless 4K | 60.6 | 47.7 | 35.3 |
여기서 중요한 점은 “env-free trajectory를 무작정 많이 넣으면 좋아진다”가 아니라는 것이다.
All 16K는 base보다 오히려 약간 낮다.
Dockerless로 상위 4K를 고르면 Verified와 Pro에서 env-based 4K를 넘고, Multilingual에서는 거의 근접한다.
즉 Dockerless의 역할은 단순한 점수 부여가 아니라, noisy rollout pool에서 학습에 넣을 trajectory를 고르는 데이터 품질 제어다.
최종 모델 비교는 다음처럼 정리된다.
| Model / training | Env-free training stage | Verified | Multilingual | Pro |
|---|---|---|---|---|
| SWE-Lego-8B | No | 41.2 | 19.0 | 16.1 |
| Qwen3.5-9B base | — | 59.6 | 41.3 | 32.3 |
| Env-SFT-9B | No | 60.0 | 48.3 | 33.9 |
| Dockerless-SFT-9B | Yes | 60.6 | 47.7 | 35.3 |
| + DeepSWE-Verifier RL | Yes | 60.6 | 47.3 | 34.1 |
| + Test-Execution RL | No | 62.4 | 51.3 | 35.7 |
| Dockerless-RL-9B | Yes | 62.0 | 50.0 | 35.2 |
Dockerless-RL-9B는 완전한 env-free SFT+RL 경로로 62.0/50.0/35.2를 찍는다. test-execution RL 62.4/51.3/35.7보다는 약간 낮지만, 차이는 작다.
논문의 headline인 “environment-based post-training과 matching한다”는 이 구간에서 나온다.
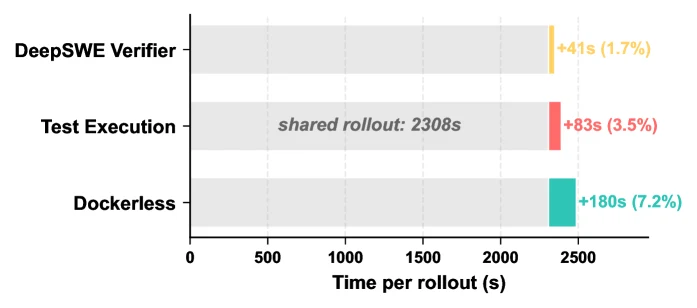
latency 분석도 실무적으로는 중요하다.
Dockerless는 sub-agent 탐색을 하므로 단순 verifier보다 reward evaluation이 느리다.
하지만 논문은 7,680 rollout 기준 agent rollout 자체가 평균 2,308초로 지배적이고, reward evaluation은 41–180초를 더하는 수준이라고 보고한다.
Dockerless reward evaluation은 전체 per-rollout time의 7.2%로 제시된다.
case study는 이 방법이 왜 단순 diff similarity보다 나은지 보여 준다. matplotlib의 offsetText color issue에서 candidate patch는 reference patch와 표면 형태가 다르지만 실제 테스트는 통과한다. text similarity는 0.468, DeepSWE Verifier는 0.035로 낮게 평가했지만, Dockerless는 XAxis/YAxis initialization path와 inherit 대 explicit labelcolor semantics를 sub-agent evidence로 확인해 0.996을 준다.

실무 관점에서의 해석
내가 보기에 Dockerless의 가장 중요한 메시지는 “테스트 없이도 된다”가 아니다.
더 정확히는 실행 신호가 없을 때 verifier가 최소한 저장소를 읽고 근거를 만들어야 한다는 주장이다.
기존 LLM-as-judge가 issue, candidate patch, reference patch만 보고 점수를 매기면, 실제 호출 경로와 주변 모듈과의 관계를 놓치기 쉽다.
Dockerless는 verifier 자체를 작은 investigation agent로 바꾼다.
이 관점은 코딩 에이전트 제품에도 꽤 직접적이다. patch를 낸 agent와 별개의 reviewer agent가 read-only로 저장소를 탐색하고, “이 변경이 실제 실패 경로에 닿는가”, “reference와 다른 구현이지만 같은 semantics인가”, “주변 모듈이 깨질 가능성은 없는가”를 질문 단위로 확인하는 구조는 CI가 느리거나 불완전한 팀에서도 쓸 만한 보조 검토 패턴이다.
단, 논문 그대로의 Dockerless는 reference patch를 필요로 하므로, production PR review에 바로 놓기보다는 학습 데이터 필터링이나 benchmark verifier 쪽에 더 가깝다.
또 하나의 함의는 reward modeling의 형태다.
수학 RL에서는 정답 checker가 보상 역할을 하지만, software engineering에서는 정답이 파일 전체와 실행 환경에 분산되어 있다.
Dockerless는 이 보상을 “테스트 결과”에서 “근거 수집을 수행한 verifier judgment”로 옮긴다. verifier가 tool use를 하고, 그 tool-use trace를 학습하며, 최종 score를 RL reward로 쓴다는 점에서 reward model이 점점 agentic system에 가까워지는 흐름을 보여 준다.
하지만 caveat도 분명하다.
첫째, Dockerless는 execution label 없이 시작하지 않는다. verifier training trajectory는 test-execution verdict와 일치하는 것만 rejection-sampling으로 남긴다.
따라서 이 논문은 execution을 완전히 제거했다기보다, 한 번 구축한 실행 기반 label을 더 넓은 environment-free post-training 루프로 증류한다고 보는 편이 맞다.
둘째, reference patch 의존성이 있다.
SWE-style benchmark나 supervised training set에서는 reference patch가 존재하지만, 새로 들어온 실제 GitHub issue에는 보통 reference patch가 없다.
이 제약을 풀려면 reference 없이 expected behavior를 추론하거나, issue/spec/test intent를 별도로 구조화하는 추가 연구가 필요하다.
셋째, 언어별 편차가 있다. appendix의 per-language 분석에서 aggregate로는 env-free SFT와 env-based SFT 차이가 작지만, Rust와 C처럼 compiler diagnostic이 중요한 언어에서는 env-based SFT가 각각 +7.0, +13.3포인트 유리하게 나온다.
Dockerless가 read-only 탐색으로 많은 것을 보완하더라도, compiler/type/linker feedback이 주는 중간 신호는 여전히 가치가 있다는 뜻이다.
넷째, 글 작성 시점에 arXiv HTML, Hugging Face Papers, GitHub/Hugging Face 검색에서 이 논문과 명확히 연결된 공식 code repository나 공개 Dockerless-RL-9B checkpoint는 확인하지 못했다.
따라서 현재 공개 아티팩트는 논문과 HF Papers mirror 중심으로 보는 것이 안전하다. dockerless라는 이름의 GitHub repository들은 별도의 container/tooling 프로젝트로 보이며, 이 논문의 공식 구현으로 확인되지 않았다.
정리하면 Dockerless는 “CI를 버리자”는 논문이 아니라, 코딩 에이전트 학습에서 verification을 agentic evidence gathering 문제로 바꾸는 논문이다.
실행 가능한 테스트가 있으면 여전히 그것이 강한 신호다.
그러나 테스트 환경이 비싸거나 없고, 그래도 대규모 post-training을 해야 한다면, verifier가 저장소를 읽고 질문을 만들고 근거를 수집하는 구조가 다음 선택지가 될 수 있다.
앞으로의 코딩 에이전트 학습은 actor만 agentic해지는 것이 아니라, reward와 verifier도 점점 agentic해질 가능성이 크다.