LLM agent의 메모리라고 하면 보통 RAG를 떠올린다.
과거 기록을 검색하고, 관련된 문장이나 workflow를 context에 넣고, 모델이 그 지시를 읽고 따라 하게 만든다.
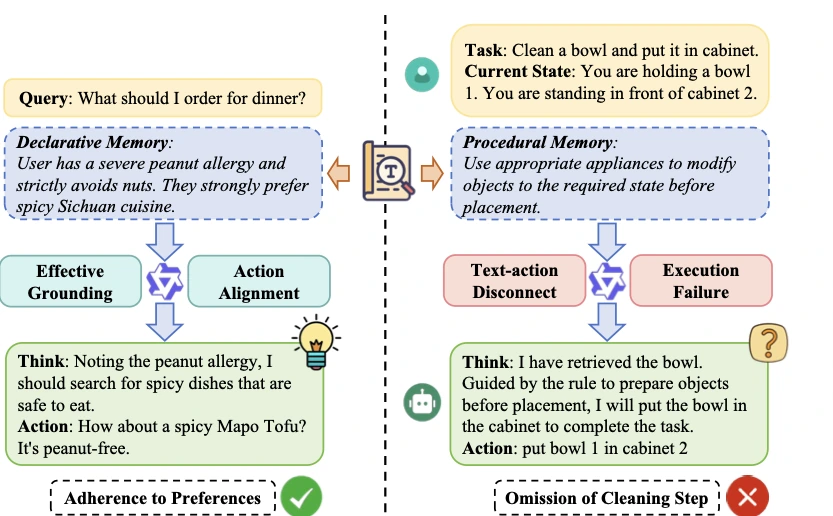
사실·선호·정책 같은 declarative memory에는 이 방식이 꽤 잘 맞는다.
“사용자는 견과류 알레르기가 있다” 같은 정보는 텍스트로 넣어도 행동과 바로 연결된다.
하지만 절차 기억은 다르다.
“물건을 목적지에 넣기 전에 필요한 상태로 먼저 바꿔라”는 규칙을 agent가 읽었다고 해서, 실제 ALFWorld 환경에서 bowl을 씻고 cabinet에 넣는 순서를 항상 지키는 것은 아니다.
논문 Neural Procedural Memory: Empowering LLM Agents with Implicit Activation Steering은 이 간극을 text-action disconnect라고 부른다.
모델이 문장을 이해하는 것과, 긴 action trajectory에서 그 절차를 끝까지 실행하는 것은 다른 문제라는 뜻이다.
이 논문의 제안인 **Neural Procedural Memory(NPM)**는 절차 기억을 텍스트로만 저장하지 않는다.
과거 trajectory의 성공/실패 대비를 모델 activation 공간의 steering vector로 바꾸고, 추론 시점에 residual stream에 더한다.
즉 “이 workflow를 읽어라”가 아니라, “이 task에서 실패 모드에서 성공 모드로 이동하는 activation 방향을 직접 켜라”에 가깝다.
무엇을 해결하려는가
논문의 출발점은 agent memory를 두 부류로 나누는 것이다.
| 메모리 유형 | 예시 | RAG와의 궁합 |
|---|---|---|
| Declarative memory | 사용자 선호, 금지 조건, 정적 사실 | 텍스트로 표현하기 쉬워 RAG가 잘 맞는다 |
| Procedural memory | 물건 찾기→상태 변경→배치, 검색→검증→구매 같은 action sequence | 텍스트 설명만으로는 실행 trajectory에 안정적으로 붙지 않을 수 있다 |
기존 agent memory 연구는 Reflexion, Voyager, ExpeL, workflow retrieval처럼 과거 경험을 자연어 규칙이나 실행 가능한 skill로 남기는 경우가 많다.
이 접근은 해석 가능하고 구현하기 쉽지만, context window를 먹고 긴 작업에서 attention/prefill 비용을 늘린다.
더 중요한 문제는 모델이 그 문장을 “읽었지만” 내부 상태 추적이나 action 선택에서는 다른 방향으로 흘러갈 수 있다는 점이다.
NPM은 절차 기억을 activation steering 문제로 바꾼다.
과거 경험에서 성공적인 reasoning/action 패턴과 퇴행적 실패 패턴을 대비시키고, 그 차이를 hidden state 공간의 방향으로 추출한다.
추론 때는 새 task와 비슷한 과거 task를 검색한 뒤, 해당 contrastive memory에서 task-specific steering vector를 합성해 모델 내부에 주입한다.
NPM의 세 단계
논문이 제시하는 프레임워크는 크게 세 단계다.
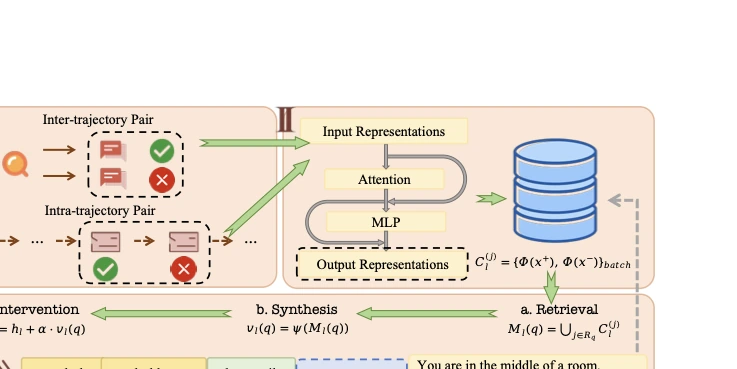
첫째, contrastive experience construction이다. agent trajectory를 성공/실패 또는 효과적 step/퇴행적 step으로 나눈다.
여기서 중요한 설계가 dual-granularity다.
| 대비 수준 | 언제 쓰나 | 무엇을 잡아내나 |
|---|---|---|
| Inter-trajectory contrast | 같은 task에 성공 trajectory와 실패 trajectory가 모두 있을 때 | 실패 trajectory 전체를 성공 trajectory 방향으로 옮기는 global behavioral shift |
| Intra-trajectory contrast | 성공 trajectory가 부족하거나 실패 trajectory 안에 반복/오류 step이 있을 때 | 반복, invalid action, premature termination 같은 local failure mode |
둘째, procedural memory extraction이다. inter-trajectory에서는 trajectory 전체의 hidden state에서 마지막 token representation을 사용하고, intra-trajectory에서는 step representation을 mean pooling한다.
그런 다음 positive representation과 negative representation의 차이를 PCA 기반 dominant direction으로 압축한다.
저장소에는 원문 workflow 전체를 넣는 대신, task별 contrastive pair representation이 들어간다.
셋째, inference-time intervention이다.
새 query가 들어오면 dense retriever로 top-K 유사 historical task를 가져온다.
논문 구현은 sentence-transformers/all-mpnet-base-v2를 사용하고 retrieval count는 8이다.
검색된 task의 contrastive pool에서 현재 task에 맞는 vector를 합성한 뒤, generation 중 target layer의 residual stream에 h + αv 형태로 더한다.
Qwen3-4B/8B는 layer 17–19, MiniCPM3-4B는 layer 46–48에 개입한다.
핵심은 weight update가 없다는 점이다.
NPM은 fine-tuning이나 RL이 아니라 training-free steering이다.
대신 내부 activation에 접근할 수 있는 open architecture가 필요하다.
공개된 실험 결과
평가는 MiniCPM3-4B, Qwen3-4B, Qwen3-8B를 대상으로 한다.
환경은 네 가지다.
ALFWorld는 text-based household task의 success rate를 보고, WebShop·ScienceWorld·BabyAI는 average reward를 보고한다.
비교군은 No Memory, explicit textual memory인 Insights/Workflows, static implicit steering인 CAA/Mass-Mean, 그리고 NPM이다.
가장 중요한 결과는 NPM이 no-memory보다 대체로 좋아지고, explicit workflow와 결합하면 가장 강해진다는 점이다.
| Model | No Memory Avg | Workflows Avg | NPM Avg | NPM + Workflows Avg |
|---|---|---|---|---|
| MiniCPM3-4B | 22.60 | 32.68 | 28.87 | 34.47 |
| Qwen3-4B | 28.14 | 34.23 | 31.39 | 37.60 |
| Qwen3-8B | 30.63 | 37.90 | 36.32 | 41.89 |
이 표만 보면 NPM이 항상 Workflows보다 낫다고 말할 수는 없다.
오히려 평균으로는 structured textual workflow가 더 강한 경우가 많다.
하지만 NPM은 context token을 차지하지 않고, static steering baseline인 CAA/Mass-Mean보다 훨씬 안정적이다.
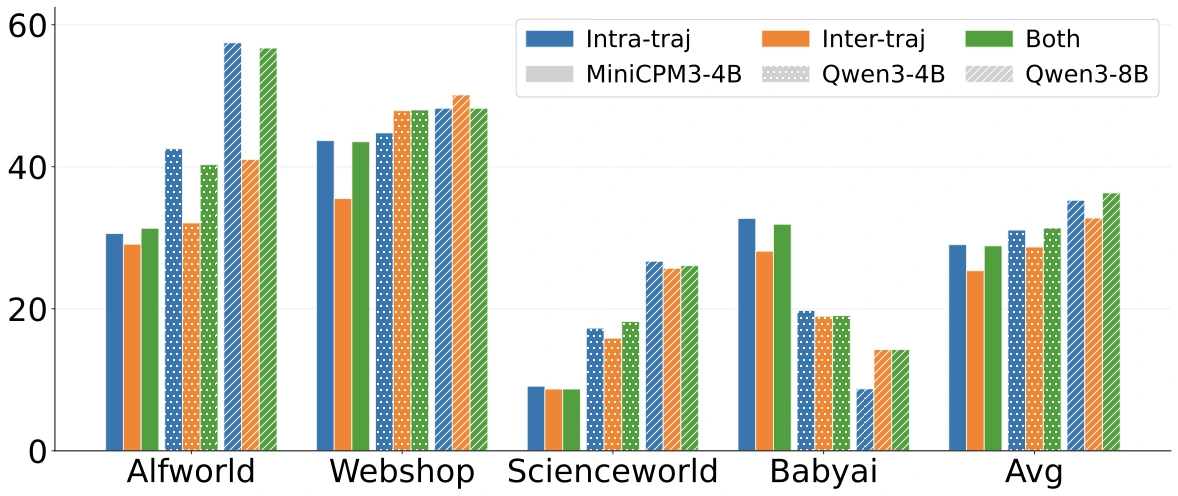
Qwen3-4B의 WebShop에서는 NPM이 48.00으로 Workflows 45.73보다 높게 나온다.
그리고 세 backbone 모두에서 NPM + Workflows가 평균 최고 점수를 낸다.
이 대목이 논문의 가장 실용적인 주장이다. implicit memory가 explicit memory를 완전히 대체한다기보다, 둘은 서로 다른 종류의 도움을 준다. workflow는 상위 계획을 텍스트로 제공하고, steering vector는 긴 trajectory에서 그 계획을 놓치지 않도록 내부 representation을 밀어준다.
왜 dual-granularity가 중요한가
모든 절차 실패가 같은 모양은 아니다.
어떤 실패는 처음 계획이 틀어진 탓이고, 어떤 실패는 중간 실행에서 loop에 빠지거나 invalid action을 반복하는 탓이다.
그래서 NPM은 inter-trajectory와 intra-trajectory를 모두 쓴다.
논문은 간단한 선택 규칙을 쓴다.
검색된 successful trajectory의 평균 길이 Lq가 해당 benchmark의 global average L̄보다 충분히 길면 intra-trajectory를 고르고, 그렇지 않으면 inter-trajectory를 고른다.
길고 복잡한 task는 local error correction이 중요하고, 짧은 task는 global planning alignment가 더 중요하다는 가정이다. threshold 계수 γ는 1.5다.
이 규칙이 oracle은 아니다.
논문도 boundary case에서는 oracle single-granularity보다 낮을 수 있다고 말한다.
그래도 한 가지 granularity에 고정하는 것보다 task family별 variance를 줄이는 장치로 작동한다.
steering vector가 정말 절차를 담는가
activation steering 논문에서 늘 조심해야 할 점은 “그럴듯한 방향을 더했더니 점수가 올랐다”와 “그 방향이 실제로 의미 있는 절차 표현을 담는다” 사이의 간극이다.
이 논문은 이 부분을 꽤 많이 분석한다.
먼저 Qwen3-4B의 ALFWorld hidden state를 PCA로 투영했을 때, positive와 negative representation이 뚜렷한 cluster를 만든다고 보고한다.
Appendix의 linear SVM 검증에서도 inter/intra representation을 높은 정확도로 구분한다.
예를 들어 Qwen3-4B 기준 ALFWorld는 inter 99.55%, intra 99.99%, WebShop은 inter 88.46%, intra 99.91%로 보고된다.
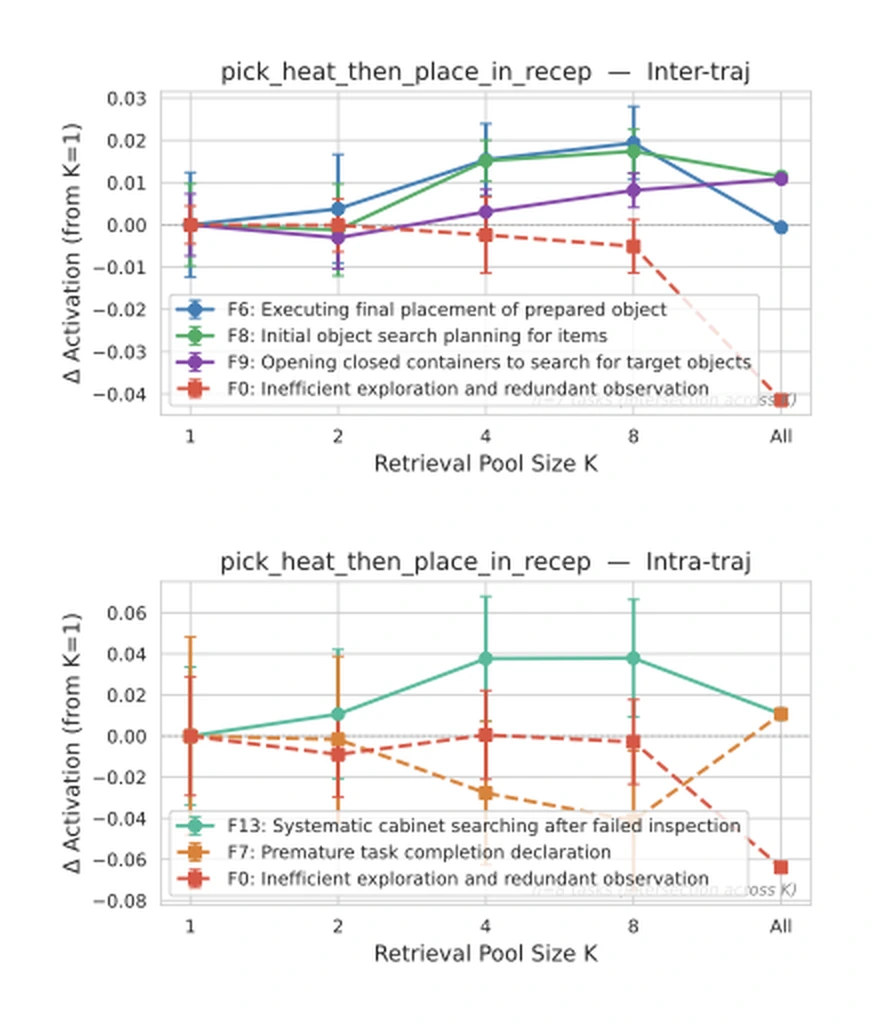
또 steering vector의 pairwise cosine similarity를 보면 task type이나 interaction target별 block structure가 나타난다.LookAt, PickCool, PickHeat, PickTwo 같은 task category가 서로 다른 procedural logic을 갖고, 특히 intra-trajectory signal은 object/interaction target에 따라 더 균일하게 묶인다.
이 해석은 inter가 global plan에 가깝고 intra가 local correction에 가깝다는 앞선 설명과 맞물린다.
가장 흥미로운 부분은 sparse dictionary learning으로 steering vector를 behavioral primitive에 분해한 분석이다.
ALFWorld layer 18 hidden state에서 16개 basis direction을 만들고, 각 feature가 어떤 action type과 같이 활성화되는지 mutual information으로 주석화한다.
예를 들어 논문은 다음과 같은 feature label을 제시한다.
| Feature | 의미 | Polarity |
|---|---|---|
| RedundObs | 비효율적인 탐색과 반복 observation | Negative |
| EarlyStop | premature task completion declaration | Negative |
| InitPlan | 초기 object search planning | Positive |
| FinalPlace | 준비된 object의 final placement | Positive |
| SysSearch | 빈 container 확인 뒤 systematic cabinet search | Positive |
| ContSearch | closed container를 열고 object를 찾는 행동 | Positive |
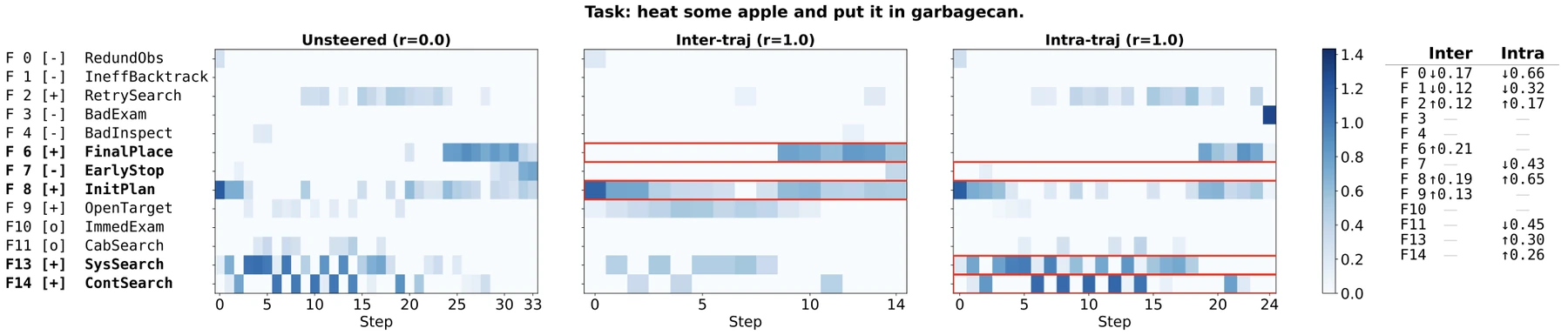
이 결과를 곧바로 “모델 내부에 사람이 읽을 수 있는 skill slot이 있다”로 과장하면 안 된다. feature label은 DeepSeek-V3.2를 이용한 자동 해석과 통계적 co-activation 분석의 산물이다.
그래도 NPM이 단순 평균 vector보다 나은 이유를 설명해 주는 단서는 된다. steering vector는 하나의 마법 방향이 아니라, redundant observation을 누르고 systematic search나 final placement 같은 primitive를 켜는 복합 modifier처럼 보인다.
효율성: context를 늘리지 않는 메모리
NPM의 장점은 context window를 차지하지 않는다는 점이다.
논문은 Qwen3-4B에서 trajectory 하나당 저장량을 계산한다.
각 historical trajectory마다 target layer 3개에 대해 inter-trajectory용 last-token state 1개와 intra-trajectory용 effective/degenerate state 2개를 저장하므로, half precision 기준 3 × L × d × b다.
Qwen3-4B의 hidden dimension 2560, target layer 3개, 2 bytes를 대입하면 trajectory당 약 45KB다.
Latency도 흥미롭다. textual memory는 긴 text context를 prefill해야 하므로 prefill latency가 63.46ms에서 279.89ms로 커진다.
NPM은 retrieval 13.83ms, synthesis 77.42ms, probe 130.46ms 같은 추가 단계가 있지만, prefill은 71.09ms로 no-memory에 가깝다. decoding 중에는 residual stream에 vector를 더하는 element-wise addition이므로 token generation 지연은 측정 가능하게 늘지 않는다고 보고한다.
즉 NPM은 “text memory보다 항상 빠르다”라기보다, 비용 구조가 다르다.
검색·합성·probe 단계의 overhead는 있지만, 긴 textual workflow를 context에 넣는 방식처럼 KV cache와 prefill을 계속 키우지는 않는다.
긴 agent task에서 memory를 자주 불러야 한다면 이 차이가 중요해질 수 있다.
한계와 실무적 해석
가장 큰 제약은 activation access다.
NPM은 residual stream에 직접 개입해야 하므로, API-only closed model에는 그대로 적용하기 어렵다. vLLM/SGLang처럼 내부 hook을 넣을 수 있는 open-weight model runtime이나 연구용 inference stack이 필요하다.
둘째, cold-start 문제가 있다. inter-trajectory contrast에는 성공과 실패 trajectory가 모두 필요하다.
복잡한 task에서 agent가 성공 trajectory를 거의 만들지 못하면 positive signal이 빈약해진다.
논문은 intra-trajectory contrast로 실패 trajectory 내부의 valid/degenerate step을 나누어 이 문제를 완화하지만, 완전히 없애지는 못한다.
셋째, degenerate step 분리는 휴리스틱에 의존한다.
반복 action과 invalid format은 잡기 쉽지만, 논리적으로 틀렸지만 환경 오류를 내지 않는 subtle failure는 놓칠 수 있다.
Appendix의 LLM-as-judge 평가에서 전체 FPR은 0.61%, FNR은 6.34%로 낮게 보고되지만, WebShop의 FNR은 9.30%로 더 높다.
실제 제품 환경에서는 domain-specific judge나 verifier가 필요할 가능성이 크다.
넷째, 현재 방식은 synthesized vector 하나를 generation 동안 비교적 정적으로 적용한다.
실제 agent execution은 탐색, 계획, 도구 호출, 검증, 종료 판단처럼 단계가 바뀐다.
논문도 future work로 execution stage에 따라 intervention을 동적으로 바꾸는 방향을 언급한다.
그래도 이 논문은 agent memory 설계에 꽤 중요한 질문을 던진다.
지금까지 많은 memory system은 “무엇을 context에 넣을 것인가”를 물었다.
NPM은 “어떤 과거 경험이 모델 내부의 어떤 행동 방향을 켜야 하는가”를 묻는다.
텍스트 workflow는 여전히 유용하지만, 긴 trajectory에서 workflow가 실제 action으로 이어지지 않는다면 activation-level memory가 보완축이 될 수 있다.
실무적으로는 당장 production agent에 붙이는 완성형 기술이라기보다, open-weight agent runtime에서 procedural memory를 token이 아닌 representation으로 관리하는 연구 방향으로 보는 편이 좋다.
특히 ALFWorld/WebShop/ScienceWorld처럼 반복적인 action schema와 명확한 failure signal이 있는 환경에서는, 과거 trajectory를 단순 요약문으로 남기는 대신 contrastive activation repository로 축적하는 접근이 앞으로 더 자주 등장할 가능성이 있다.