Google DeepMind가 공개한 **From AGI to ASI**는 새로운 모델이나 제품 발표가 아니다. arXiv 2606.12683v1로 올라온 60쪽짜리 연구 리포트에 가깝고, DeepMind publication page에도 venue는 GDM Website로 표시된다.
하지만 읽을 만한 이유는 분명하다.
이 글은 AGI를 “도착점”이 아니라 그 다음 전환을 분석해야 하는 시작점으로 놓는다.
논문의 질문은 단순하다.
인간 수준의 AGI가 가능하다고 가정하면, AI 발전은 거기서 멈출까.
아니면 compute, 알고리즘, 자기개선, 다중 에이전트 집단을 통해 large human expert collective을 넘어서는 ASI로 계속 이동할까.
저자들은 답을 하나로 고정하지 않는다.
대신 네 가지 경로와 여섯 가지 병목을 나눠서, 무엇을 측정해야 하는지에 가까운 연구 지도를 만든다.

무엇을 해결하려는가
이 리포트가 다루는 문제는 “ASI가 가능한가”라는 철학적 질문만이 아니다.
더 실무적인 질문은 AGI 이후에도 AI capability를 forecast하고 monitor할 수 있는가다.
지금까지 AI 발전은 대체로 model size, data, compute, benchmark score, deployment capability를 보며 추적할 수 있었다.
하지만 AGI 이후에는 그 추적 방식이 불안정해질 수 있다.
더 똑똑한 AI가 AI 연구 자체를 가속하고, 수많은 agent instance가 병렬로 움직이며, synthetic data와 simulation이 데이터 공급 구조를 바꾸면 기존 extrapolation만으로는 부족하다.
저자들은 AGI와 ASI를 아주 날카로운 threshold로 정의하지 않는다.
대신 Legg-Hutter식 intelligence continuum을 배경으로 두고, 실무적으로는 다음처럼 둔다.
| 구분 | 논문이 쓰는 감각 |
|---|---|
| AGI | 대부분의 인지 과제에서 대략 median human-level에 도달한 일반 인공지능. 이미 많은 좁은 과제에서는 초인간적일 수 있지만, 전체적으로는 한 명의 인간 수준에 가까운 시스템이다. |
| ASI | 단일 인간이 아니라 large human expert collective이 장기간 할 수 있는 일을 폭넓게 넘어서는 일반 초지능. AlphaGo나 AlphaFold처럼 특정 domain superhuman인 시스템은 여기서 말하는 ASI가 아니다. |
이 정의가 중요한 이유는 논문의 단위가 “모델 하나가 얼마나 똑똑한가”에 머물지 않기 때문이다.
저자들은 ASI가 하나의 거대한 모델일 수도 있지만, 수백만 개 instance가 병렬로 작동하는 collective일 수도 있다고 본다.
즉 AGI 이후의 핵심 질문은 individual model capability뿐 아니라 복제, 속도, coordination, resource allocation까지 포함한다.
디지털 지능은 인간 지능과 다른 방식으로 스케일된다
논문의 초반부에서 가장 유용한 표는 Table 1과 Table 2다.
Table 1은 디지털 지능이 생물학적 지능에 비해 compute가 늘수록 얻는 장점을 정리하고, Table 2는 그래도 ASI가 넘을 수 없는 근본 한계를 정리한다.
이 둘을 같이 봐야 균형이 맞는다.

디지털 지능의 장점은 “더 빠른 컴퓨터에서 더 빨리 생각한다” 정도로 끝나지 않는다.
입력과 출력 bandwidth가 커지고, working memory와 memorization capacity가 커지고, substrate independence 덕분에 더 나은 하드웨어로 옮겨 갈 수 있다.
또 lossless replication이 가능해 같은 시스템을 복제·중단·재개할 수 있고, homogeneous AI instance끼리는 experience나 learning signal을 고속으로 공유할 수도 있다.
하지만 논문은 ASI를 전능한 존재로 놓지 않는다.
속도 제한, 에너지 비용, finite measurement precision, physical manipulation latency, complexity theory, halting problem 같은 한계는 남는다.
중요한 긴장은 여기서 생긴다.
인간 직관으로는 디지털 집단 지능의 속도와 복제 가능성을 과소평가하기 쉽지만, 반대로 ASI를 “무엇이든 즉시 할 수 있는 존재”로 보는 것도 틀리다.
예측 난도는 바로 이 사이에 있다.
네 가지 경로: scaling만의 이야기가 아니다
논문 Table 3은 AGI에서 ASI로 가는 기술 경로를 네 개로 나눈다.
이 네 경로는 서로 배타적이지 않다.
오히려 실제 세계에서는 병렬로 진행되고, 서로를 강화할 가능성이 크다.
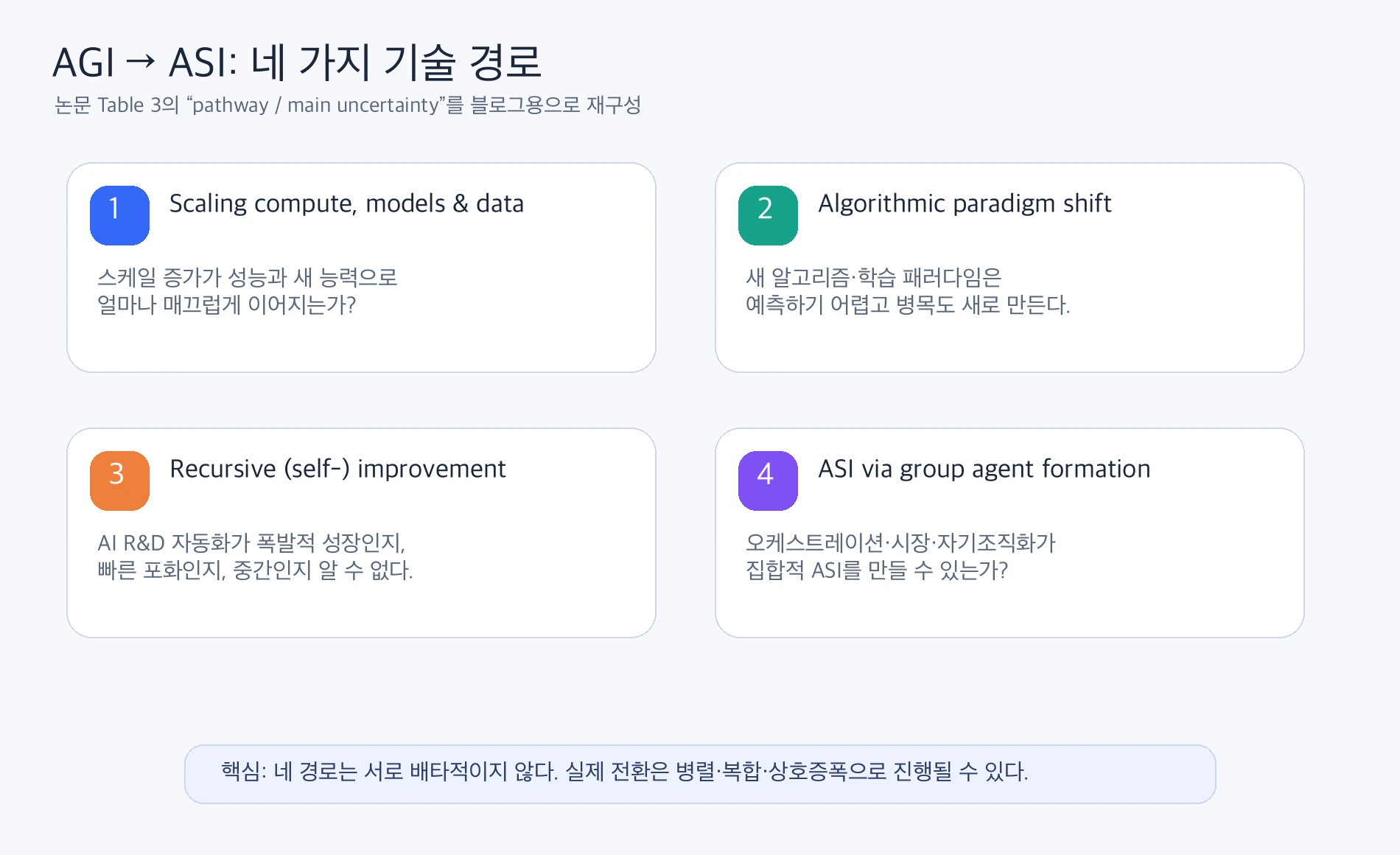
| 경로 | 핵심 아이디어 | 가장 큰 불확실성 |
|---|---|---|
| Scaling compute, models & data | 더 많은 compute, 더 큰 모델, 더 많은 데이터, test-time compute를 계속 밀어붙인다. | scale 증가가 성능·generalization·새 capability로 얼마나 매끄럽게 이어지는가. spiky progress인지, smooth progress인지, diminishing returns가 어디서 강해지는가. |
| Algorithmic paradigm shift | 현재 transformer 기반 pretraining/post-training/test-time scaling을 넘어 더 효율적인 알고리즘·아키텍처·학습 패러다임이 나온다. | 패러다임 전환은 역사적으로 예측하기 어렵고, 새 병목도 함께 만든다. |
| Recursive (self-) improvement | AI가 AI R&D를 자동화해 다음 AI를 더 빠르게 만들고, 그 AI가 다시 R&D를 가속한다. | hyperbolic growth인지, 빠른 saturation인지, 또는 그 중간인지 역사적 precedent가 없다. |
| ASI via group agent formation | 많은 AGI instance가 orchestration, market, organization, self-organization을 통해 collective intelligence를 만든다. | multi-agent dynamics와 emergent group agency가 어떻게 scale되는지 아직 잘 모른다. |
이 중 scaling은 가장 익숙하고, 과거 데이터로 어느 정도 forecast model을 fit할 수 있는 유일한 경로다.
반면 paradigm shift는 예측이 어렵다. recursive improvement는 “AI가 연구를 도와준다”와 “AI가 다음 세대 AI를 사실상 자동으로 만든다” 사이에 긴 continuum이 있다. group agent formation은 개인 모델 하나의 지능보다 coordination 구조가 중요해지는 경로다.
개인적으로 이 표에서 가장 중요한 문장은 “pathways are largely independent of each other, and are likely to occur in parallel”에 가깝다.
예를 들어 더 나은 coding agent는 AI R&D 자동화를 밀고, 그 자동화는 더 좋은 데이터 생성과 실험 설계를 만들고, 다중 에이전트 조직은 더 많은 hypothesis search를 병렬화할 수 있다.
AGI 이후의 위험한 부분은 하나의 curve가 아니라 여러 curve가 서로 곱해질 수 있다는 점이다.
여섯 병목: 결론이 아니라 연구 과제
논문 Table 4는 AGI→ASI 전환을 늦추거나 막을 수 있는 병목을 정리한다.
여기서 조심해야 할 점은, 저자들이 “이 병목이 반드시 progress를 멈춘다”고 주장하지 않는다는 것이다.
오히려 각 병목마다 counteracting factor를 함께 놓고, 그 영향도가 얼마나 클지 측정하는 것이 open research question이라고 말한다.

| 병목 | 무엇이 문제인가 | 상쇄 가능성 |
|---|---|---|
| Data wall | pretraining, post-training, fine-tuning, test-time adaptation에 필요한 고품질 데이터 증가가 한계에 부딪힐 수 있다. | synthetic data, high-fidelity simulation, self-play, RL, test-time scaling, self-generated interaction data. |
| Economic and natural resource demand | 투자, 칩 공급망, 에너지, 데이터센터 입지, 희소자원 수요가 너무 빨리 커질 수 있다. | AI deployment의 경제적 수익, compute·energy·data efficiency 개선, 대규모 인프라 증설. |
| Neural paradigm is insufficient | 현재의 large pretrained neural network, post-training, scaffolding, tool-use, SGD 조합만으로 AGI/ASI에 부족할 수 있다. | 더 나은 AI 연구, 패러다임 진화, 더 낮은 단계의 AI가 연구를 가속하는 효과. |
| Research gets harder | 분야가 성숙하면서 low hanging fruit이 줄고, 좋은 hypothesis를 찾는 search effort가 커질 수 있다. | 더 강한 AI가 연구 효율, resource efficiency, hypothesis search를 개선할 수 있다. |
| Abstraction barrier | 인간 데이터로 학습한 시스템이 인간의 추상화 체계에 갇혀 완전히 새로운 개념을 만들기 어려울 수 있다. | interactive learning, RL, 더 큰 collective, paradigm shift가 직접 또는 우회적으로 압력을 줄 수 있다. |
| Deliberate slowdown | 사고, 악용, 군사·정치적 위험, 사회적 반발로 capability cap이나 규제가 걸릴 수 있다. | 경제·정치적 압력, 국제 경쟁, 약한 글로벌 coordination이 slowdown pressure를 무력화할 수 있다. |
이 표를 읽는 실무적 방법은 “어떤 병목을 믿는가”보다 “어떤 monitoring signal을 봐야 하는가”다.
데이터 벽을 본다면 synthetic data와 interaction data가 실제로 frontier capability를 밀어 올리는지 봐야 한다.
자원 병목을 본다면 training compute뿐 아니라 inference, energy, datacenter build-out, supply chain을 같이 봐야 한다.
연구 난이도 병목을 본다면 AI-assisted research가 실험 수를 늘리는 것인지, 실제 hypothesis quality를 올리는 것인지 구분해야 한다.
실무 관점에서의 해석
AI lab이나 agent product를 만드는 입장에서 이 리포트의 가치는 “ASI timeline 예측”보다 프레임 분해에 있다.
막연히 “AGI가 오면 모든 것이 바뀐다”고 말하는 대신, 어떤 경로가 어느 병목을 만나는지 나눠 볼 수 있다.
예를 들어 현재 coding agent와 research agent의 발전은 recursive improvement 경로의 초기 신호처럼 보일 수 있다.
하지만 이것이 곧바로 intelligence explosion을 의미하지는 않는다.
사람의 research taste, benchmark reliability, compute budget, experiment verification, security boundary가 여전히 병목일 수 있다.
반대로 single model capability가 잠시 plateau해도 group agent formation 경로에서는 더 많은 instance, 더 나은 orchestration, 더 좋은 market mechanism만으로 collective capability가 올라갈 수 있다.
제품 팀 관점에서는 다음 질문들이 남는다.
| 질문 | 왜 중요한가 |
|---|---|
| 우리 시스템의 성능 향상이 model scaling에서 오는가, agent orchestration에서 오는가 | 같은 “성능 향상”이라도 병목과 risk surface가 다르다. |
| 실행을 늘렸을 때 검증 capacity도 같이 늘어나는가 | recursive R&D나 multi-agent loop는 verification이 약하면 실패도 같이 증폭한다. |
| synthetic/agent-generated data가 실제 frontier를 넓히는가 | data wall을 넘는지, 단순 self-contamination인지 구분해야 한다. |
| human oversight가 어느 지점에서 병목이 되는가 | 실행 속도가 빨라지면 사람의 판단·승인·감사가 전체 throughput을 제한한다. |
| slowdown이나 regulation이 기술적으로 검증 가능한가 | 논문이 말하는 deliberate slowdown은 coordination problem이지 선언만의 문제가 아니다. |
이 리포트를 Anthropic의 recursive self-improvement 논의와 나란히 읽으면 더 선명하다.
Anthropic은 AI R&D 조직 내부의 실행 병목 이동을 보여 줬고, DeepMind는 그 이후 가능한 기술 경로와 병목 지도를 그린다.
둘 다 “AI가 곧 혼자 모든 것을 만든다”는 단순 서사보다는, 실행·검증·coordination·governance가 어디서 새 병목이 되는지를 보라고 말한다.
공개 상태와 caveat
확인 가능한 release signal은 명확하다. arXiv에는 2026년 6월 10일 제출된 v1이 있고, Google DeepMind publication page에는 2026년 6월 12일 공개 페이지가 있다.
주제 분류는 cs.AI, cs.CY, cs.LG다.
반면 코드, 모델, 데이터셋 release는 확인되지 않는다.
이 글은 capability announcement가 아니라 post-AGI forecasting과 research agenda를 위한 theoretical report로 읽는 것이 맞다.
또 하나 흥미로운 점은 첫 섹션이 “Summary Instructions”라는 메타 구조를 갖고 있다는 점이다.
인간 독자에게 AI assistant에게 맞춤 요약을 요청하라고 권하고, AI assistant가 무엇을 빠뜨리지 말아야 하는지도 적는다.
내용 자체를 그대로 따를 필요는 없지만, 리포트가 이미 “AI가 논문을 읽고 요약하는 독서 환경”을 기본값으로 의식하고 있다는 신호로는 재미있다.
가장 큰 caveat는 이 리포트가 본질적으로 landscape mapping이라는 점이다.
네 경로와 여섯 병목을 제시하지만, 어떤 경로가 실제로 우세할지, 병목이 hard blocker인지 temporary friction인지는 결론 내리지 않는다.
그래서 이 글을 timeline forecast로 읽으면 과하게 보일 수 있고, 연구 질문 목록으로 읽으면 유용하다.
마무리
From AGI to ASI의 가장 중요한 메시지는 “ASI가 곧 온다”가 아니다.
더 정확히는 AGI가 온다고 해도 그것은 마지막 계단이 아니라 다음 dynamics가 시작되는 지점일 수 있다는 것이다.
그리고 그 dynamics는 scaling 하나로 설명되지 않는다.
더 큰 compute, 새 알고리즘, AI R&D 자동화, 다중 에이전트 집단이 동시에 움직일 수 있다.
따라서 지금 필요한 것은 하나의 예언보다 좋은 계기판이다.
데이터 벽이 실제인지, synthetic data가 얼마나 도움이 되는지, 연구 난이도가 얼마나 가파르게 올라가는지, AI가 연구 효율을 얼마나 높이는지, group agent capability가 어떻게 scale되는지, deliberate slowdown이 검증 가능한지 같은 질문을 계속 측정해야 한다.
논문의 마지막 문장은 70년 전 Dartmouth에서 시작된 목표를 우리 세대가 실제로 마주할 수 있다는 책임감을 말한다.
과장 없이 읽어도 충분히 무겁다.
AGI가 사회에 들어오는 순간만 준비할 것이 아니라, AGI 이후의 가속·병목·coordination 문제를 지금부터 연구해야 한다는 것이 이 리포트의 실무적 결론이다.