AI 에이전트를 실제 조직 데이터 위에서 쓰기 시작하면 문제는 모델 성능보다 먼저 맥락의 단위에서 터진다.
테이블 스키마는 데이터 카탈로그에 있고, 지표 정의는 위키에 있고, 예외 처리는 런북에 있고, 어떤 조인을 쓰면 안 되는지는 시니어 엔지니어 머릿속에 있다.
에이전트는 답을 만들기 전에 이 파편들을 매번 다시 모아야 하고, 도구를 바꿀 때마다 같은 지식 통합 작업을 반복한다.
Google Cloud가 공개한 Open Knowledge Format, 줄여서 OKF는 이 문제를 “또 하나의 지식 서비스”가 아니라 파일 포맷으로 풀려는 시도다.
Google Cloud Blog의 표현대로 OKF는 LLM-wiki 패턴을 portable하고 interoperable한 형식으로 formalize한다.
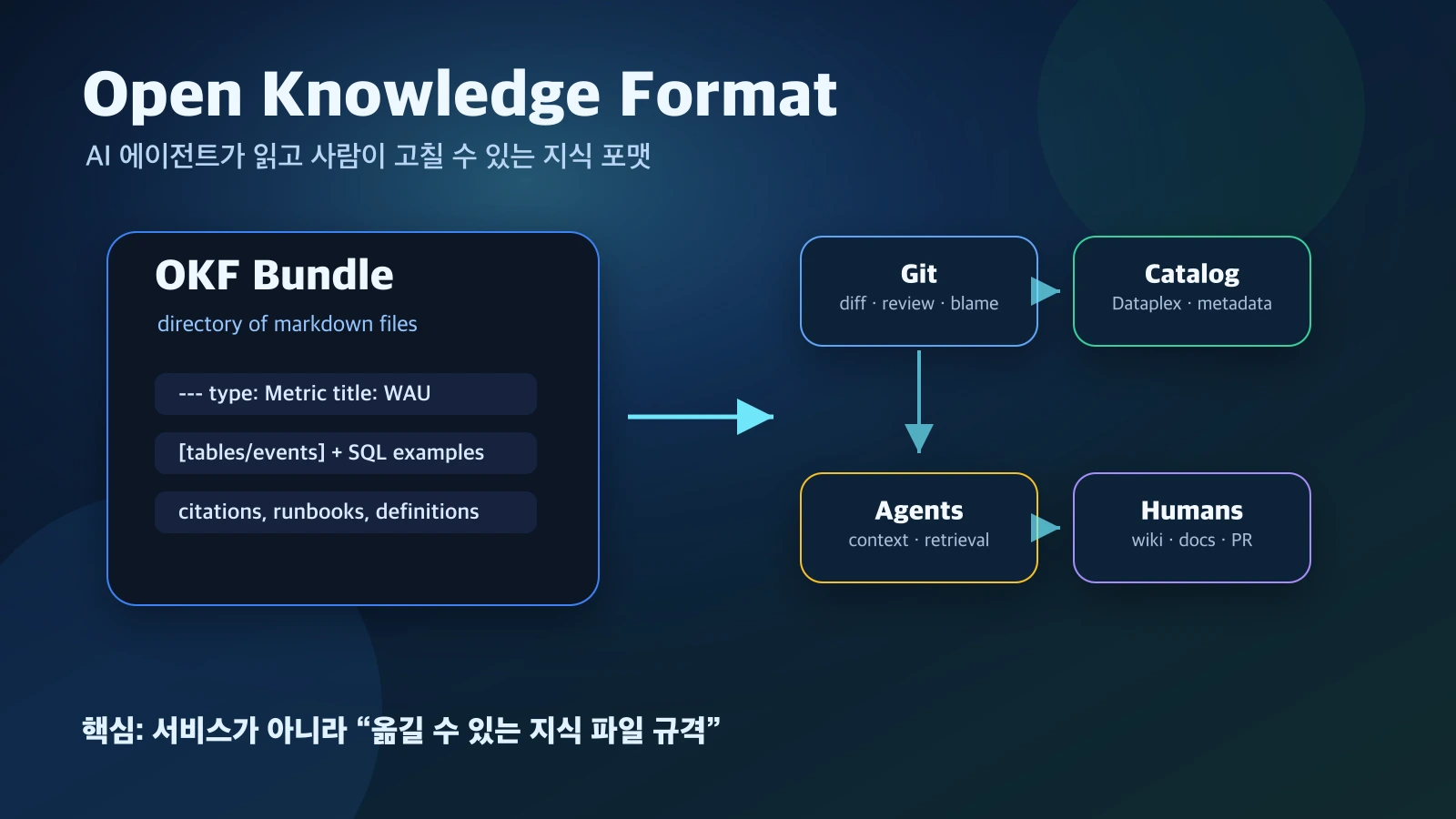
OKF v0.1의 기본 단위는 특별한 데이터베이스가 아니라 Markdown 파일 디렉터리와 YAML frontmatter다.
이 선택은 작아 보이지만 방향이 꽤 중요하다.
에이전트용 지식이 특정 SaaS, 특정 카탈로그 API, 특정 벡터 DB 안에 갇히는 대신 Git으로 diff하고, 사람이 PR로 고치고, LLM이 그대로 읽고, 검색 인덱스나 카탈로그가 다시 소비할 수 있는 산출물이 된다.
내가 보기엔 OKF의 핵심은 “에이전트에게 더 많은 문서를 검색시킨다”가 아니라, 조직 지식을 코드처럼 옮기고 검토할 수 있는 최소 공통 파일 규격으로 낮추는 것에 있다.
무엇이 문제였나: 에이전트는 데이터보다 주변 지식이 부족하다
Google Cloud Blog는 foundation model 자체가 좋아져도 agentic system에서 여전히 “relevant context” 부족이 병목이라고 설명한다.
예를 들어 “주간 활성 사용자를 어떻게 계산하나?”
라는 질문에 답하려면 테이블 이름만 알아서는 부족하다.
이벤트 정의, 사용자 식별 규칙, 봇/테스트 트래픽 제외 기준, 과거 인시던트, 승인된 SQL 패턴, 조직 내부에서 합의한 metric definition이 함께 필요하다.
기존 데이터 카탈로그는 이 중 일부를 담을 수 있지만, 많은 경우 구조화된 technical metadata와 수동 입력된 설명에 치우쳐 있다.
반대로 사내 위키와 문서 저장소는 풍부한 설명을 담지만 API와 스키마가 제각각이고, 에이전트 입장에서는 어떤 문서가 최신인지, 어떤 설명이 어떤 테이블이나 지표와 연결되는지 판단하기 어렵다.
코드 주석, 노트북, Slack, 운영 런북까지 합치면 더 흩어진다.
OKF가 겨냥하는 병목은 바로 이 사이의 공백이다.
조직 지식을 “어딘가에 검색 가능하게 넣는다”가 아니라, 사람이 읽을 수 있고 에이전트가 안정적으로 파싱할 수 있는 지식 문서 단위로 정리하자는 것이다.
그래서 OKF는 Markdown body에는 설명, SQL 예시, caveat, 운영 맥락을 넣고, YAML frontmatter에는 최소한의 structured metadata를 둔다.
OKF v0.1의 실제 모양
OKF spec 기준으로 knowledge bundle은 디렉터리 트리다.
각 concept는 하나의 Markdown 파일이고, 파일 상단에는 YAML frontmatter가 있다. concept ID는 번들 안의 파일 경로에서 .md를 뺀 값으로 이해하면 된다. tables/users.md라면 concept ID는 tables/users가 된다.
spec이 의도적으로 최소화한 점도 중요하다. required field는 type 하나다. title, description, resource, tags, timestamp 같은 필드는 권장되지만, 중앙 registry나 고정 taxonomy를 강제하지 않는다. type 값도 centrally registered되지 않으며, consumer는 모르는 type을 generic concept로 받아들여야 한다.
이 느슨함은 단점처럼 보이지만, 포맷이 여러 조직과 도메인을 건너 살아남으려면 필요한 선택이다.

간단히 보면 이런 형태다.
---
type: Metric
title: Weekly Active Users
description: Definition of WAU for the ecommerce event stream
resource: bigquery://project.dataset.events
tags: [ga4, metric, activity]
timestamp: 2026-05-28T14:30:00Z
---
# Weekly Active Users
WAU counts distinct active users over a seven-day window...
See [tables/events](../tables/events.md) and
[references/joins/user_identity](../references/joins/user_identity.md).
이 예시에서 중요한 것은 Markdown 링크다.
OKF는 디렉터리 계층뿐 아니라 일반 Markdown link를 통해 graph-shaped knowledge를 만들 수 있다고 본다.
테이블 문서가 metric 문서로, metric 문서가 join rule이나 runbook으로 이어지면 에이전트는 모든 파일을 한 번에 context로 밀어 넣지 않고도 필요한 경로를 따라 탐색할 수 있다. spec의 index.md와 log.md 예약 파일도 이런 progressive disclosure와 변경 이력 관리를 위한 장치에 가깝다.
“LLM Wiki”를 표준 파일 번들로 만든다는 의미
OKF 글에서 특히 눈에 띄는 배경은 LLM Wiki 패턴이다.
개인이나 팀이 Obsidian vault, AGENTS.md, CLAUDE.md, index.md, log.md, metadata-as-code repository 같은 형태로 에이전트용 지식 저장소를 이미 만들고 있다는 관찰이다.
문제는 이런 저장소들이 대부분 bespoke하다는 점이다.
각 팀은 비슷한 파일을 만들지만, 구조와 필드명이 달라 서로 교환하기 어렵다.
OKF는 여기서 새로운 authoring UX를 발명하지 않는다.
오히려 익숙한 Markdown과 YAML frontmatter만으로 “이 정도만 맞추면 다른 도구도 읽을 수 있다”는 약속을 만든다.
GoogleCloudPlatform/knowledge-catalog의 OKF README도 이 점을 분명히 한다.
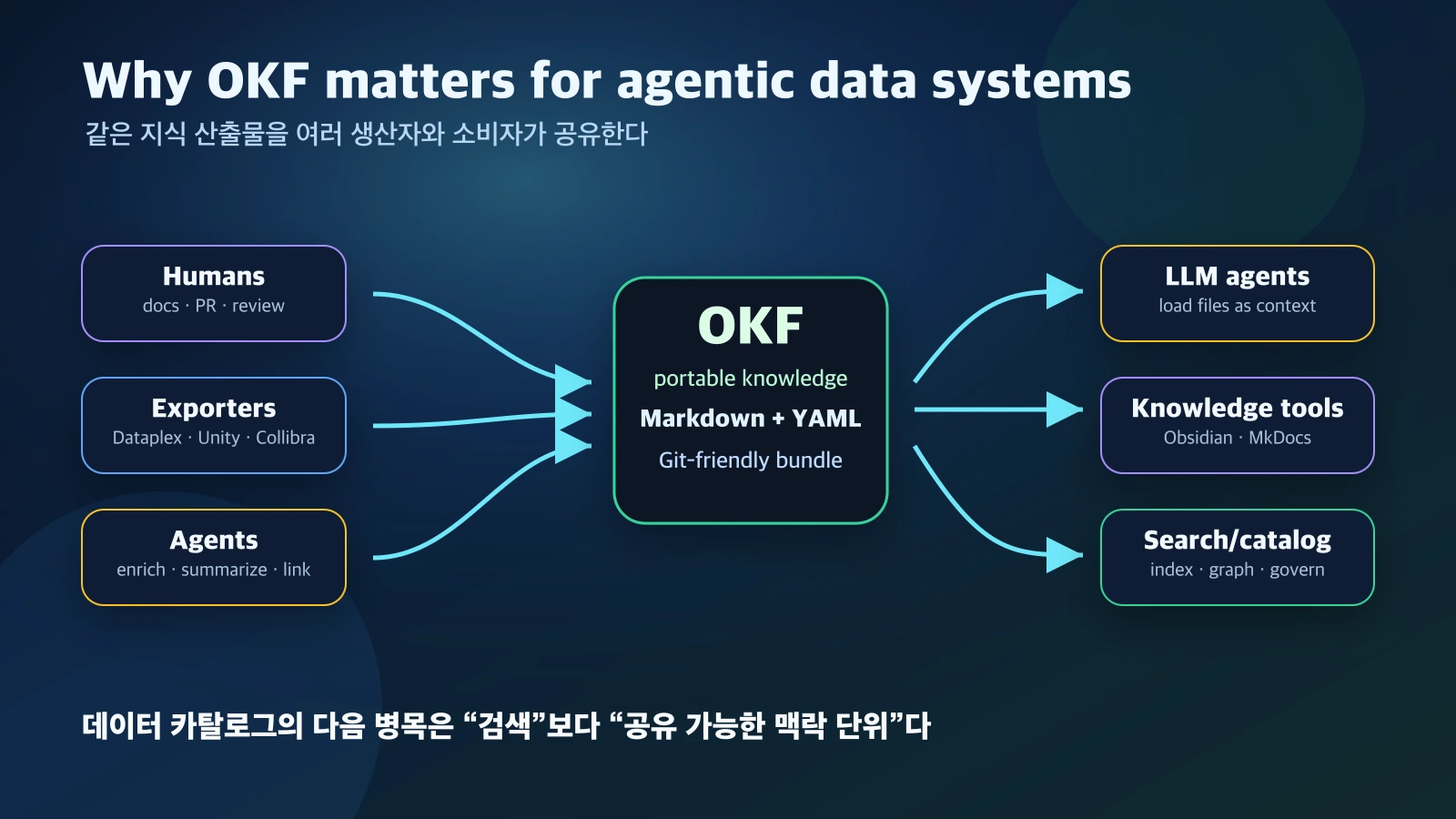
누구나 OKF를 만들 수 있어야 한다.
사람, Google ADK 기반 agent, LangChain agent, Dataplex·Unity Catalog·Collibra 같은 카탈로그 export pipeline, 데이터베이스를 걷는 스크립트 모두 producer가 될 수 있다.
반대로 consumer도 특정 런타임에 묶이지 않는다.
정적 파일 서버, Obsidian, Notion, MkDocs, LLM context loader, 검색 인덱스, graph viewer, 데이터 카탈로그가 모두 같은 파일 번들을 소비할 수 있다.
이 구조가 성립하면 에이전트 팀이 바뀌거나 카탈로그 제품이 바뀌어도 지식 자체는 Markdown bundle로 남는다.
| 접근 | 장점 | 에이전트 관점의 한계 | OKF가 보태는 것 |
|---|---|---|---|
| 전통적 데이터 카탈로그 | 테이블·컬럼·소유자·권한 관리에 강함 | 비즈니스 정의, 예외, SQL 패턴, 런북이 분리되기 쉬움 | 카탈로그 밖 맥락까지 파일 concept로 연결 |
| 사내 위키/문서 | 사람이 읽기 좋고 설명이 풍부함 | 구조화 필드와 자산 연결이 약함 | frontmatter로 최소 metadata와 resource link 제공 |
| 벡터 검색/RAG 인덱스 | 빠르게 검색 가능 | 원본 지식의 review, diff, portability가 약할 수 있음 | Git-friendly source of truth를 먼저 둠 |
| OKF bundle | 사람이 읽고 에이전트가 파싱 가능, Git으로 관리 | v0.1이라 governance와 tooling은 아직 초기 | 여러 producer/consumer 사이의 공통 교환 단위 |
Google Knowledge Catalog와의 연결
Google Cloud가 OKF를 데이터 분석 블로그에서 공개한 이유도 여기에 있다.
같은 회사가 2026년 4월 공개한 Knowledge Catalog 글은 agentic AI를 위한 enterprise context engine을 이야기한다.
핵심 축은 aggregation, enrichment, search다.
다양한 데이터 시스템과 third-party catalog의 metadata를 모으고, query log와 semantic model, unstructured data에서 의미를 보강하고, agent가 높은 정밀도로 검색하게 만든다는 그림이다.
OKF는 이 제품 방향과 잘 맞는다.
Knowledge Catalog 같은 시스템은 조직 context를 집약하고 검색하게 만들 수 있지만, 그 context를 외부 도구나 사람에게 어떤 형태로 주고받을지에 대한 포맷 문제가 남는다.
OKF는 이 교환면을 Markdown bundle로 낮춘다.
실제 knowledge-catalog 저장소의 demo에는 OKF wiki bundle을 Knowledge Catalog EntryGroup으로 publish하는 예제가 들어 있다.
GA4 sample bundle은 datasets, references, tables 디렉터리와 17개 Markdown 파일로 구성되고, Documents Layout은 각 .md 파일을 file path 기반 entry로 매핑한다.
여기서 읽을 수 있는 전략은 “Google Cloud 안에서만 쓰는 지식 모델”이 아니다.
공개 README는 OKF가 특정 agent framework, model provider, serving system에 묶이지 않는다고 강조한다.
다만 Google은 Knowledge Catalog를 OKF producer/consumer 중 하나로 만들 수 있다.
즉 OKF는 open format이라는 외피를 갖고, Knowledge Catalog는 그 포맷을 ingest·serve·govern하는 제품 표면이 되는 식이다.
실무적으로 좋은 점
첫째, OKF는 지식을 버전 관리 가능한 산출물로 만든다.
데이터 카탈로그 UI에서 설명을 고치는 것과 Git에서 Markdown을 고치는 것은 운영 감각이 다르다.
Git에서는 PR 리뷰, blame, diff, rollback, branch 기반 실험이 자연스럽다.
지표 정의가 바뀌었을 때 어떤 문장이 언제 바뀌었는지 추적할 수 있고, 에이전트가 생성한 enrichment도 사람이 review할 수 있다.
둘째, OKF는 RAG의 입력을 더 좋은 원본으로 만든다.
많은 RAG 시스템은 흩어진 문서를 수집해 chunking하고 embedding한 뒤 검색 품질을 튜닝한다.
하지만 원본 문서가 오래되고, 서로 충돌하고, 자산 연결이 약하면 검색만 좋아져도 답은 불안정하다.
OKF는 embedding layer보다 한 단계 앞에서 “검색될 문서 자체를 agent-friendly하게 관리하자”는 접근이다.
셋째, OKF는 데이터 조직과 에이전트 조직 사이의 계약면이 될 수 있다.
데이터 팀은 테이블, metric, join rule, SLA, caveat를 concept 문서로 내보내고, agent 팀은 그 bundle을 읽어 code assistant, BI agent, incident assistant, analytics copilot에 연결할 수 있다.
특정 UI나 SDK가 아니라 파일이 계약이 되면, 여러 팀이 같은 지식을 다른 도구에서 재사용하기 쉽다.
넷째, 사람이 직접 고칠 수 있다.
이것은 생각보다 큰 장점이다.
에이전트가 생성한 context가 틀렸을 때 “관리 콘솔에서 알 수 없는 internal record를 수정한다”보다 “Markdown PR을 고친다”가 훨씬 투명하다.
특히 metric definition, data caveat, incident runbook처럼 자연어와 코드가 섞이는 지식은 완전한 정규화보다 리뷰 가능한 문서가 더 강할 때가 많다.
조심해서 봐야 할 점
물론 OKF v0.1은 완성된 생태계라기보다 방향 제안에 가깝다. required field가 type 하나라는 단순함은 adoption에는 좋지만, 조직 간 교환에서 의미 충돌이 생길 수 있다.
한 팀의 Metric과 다른 팀의 Business Metric이 실제로 같은 개념인지, resource URI를 어떤 규칙으로 쓸지, tag naming을 어떻게 관리할지 같은 문제는 각 조직과 tooling이 풀어야 한다.
또한 OKF는 OpenAPI, Avro, Protobuf 같은 domain-specific schema를 대체하지 않는다. spec도 이를 non-goal로 둔다.
OKF는 그런 스키마를 reference할 수 있지만 subsume하지 않는다.
따라서 API 계약, 데이터 직렬화, 엄격한 schema validation은 여전히 기존 포맷이 담당하고, OKF는 그 주변의 설명·관계·운영 지식을 묶는 계층으로 보는 편이 정확하다.
보안과 권한도 별도 문제다.
조직 지식 번들을 Git에 둔다고 해서 모든 에이전트가 모든 파일을 읽어도 되는 것은 아니다.
데이터 카탈로그가 갖고 있던 permission, lineage, policy enforcement를 파일 포맷 하나가 자동으로 해결해 주지는 않는다.
OKF bundle을 어떤 repo에 두고, 어떤 파일을 어느 agent context에 넣고, 민감한 business definition이나 incident detail을 어떻게 redaction할지는 따로 설계해야 한다.
마지막으로, “Markdown이라 쉽다”는 말이 “운영이 자동으로 된다”는 뜻은 아니다.
좋은 OKF bundle을 만들려면 owner, update cadence, review gate, stale detection, link validation, source citation, 생성 agent의 hallucination 검증이 필요하다.
포맷은 friction을 낮추지만, 지식 운영 루프를 대신해 주지는 않는다.
왜 지금 중요한가
요즘 agent stack에서 많은 관심은 모델, tool calling, long context, vector search에 쏠려 있다.
하지만 조직 안에서 실제로 오래 쓰이는 agent를 만들려면, 결국 어떤 맥락을 신뢰할 수 있는 형태로 계속 업데이트할 것인가가 핵심이 된다.
이 문제는 검색 엔진 하나로 끝나지 않는다.
지식의 소유자, 변경 이력, 인용, 링크, 리뷰, 권한, 포맷 이식성이 모두 필요하다.
OKF는 이 중 포맷 이식성과 협업 표면에 초점을 맞춘다.
“에이전트가 읽을 수 있는 지식”을 opaque index나 vendor-specific catalog object가 아니라 Markdown 파일 번들로 만들자는 제안이다.
그래서 단기적으로는 Google Cloud Knowledge Catalog의 agentic context 전략과 맞물리지만, 장기적으로는 더 넓은 LLM Wiki / metadata-as-code 흐름의 표준 후보로 읽을 수 있다.
현재 GoogleCloudPlatform/knowledge-catalog 저장소는 GitHub 조회 시점 기준 stars 1,166개, forks 77개, open issues 21개인 공개 Python 저장소이고, OKF 디렉터리에는 SPEC.md, reference enrichment agent, tests, samples, GA4·Stack Overflow·Bitcoin sample bundles가 들어 있다.
아직 v0.1이므로 과대평가할 필요는 없지만, “조직 지식을 에이전트에게 어떻게 줄 것인가”라는 질문에는 꽤 좋은 기본값을 제시한다.
내 결론은 이렇다.
OKF가 당장 모든 데이터 카탈로그를 대체하지는 않는다.
대신 에이전트 시대의 데이터 카탈로그가 내보내야 할 산출물의 형태를 꽤 설득력 있게 보여 준다.
앞으로 중요한 것은 “우리 지식이 어느 서비스 안에 있나?”
보다 “우리 지식이 사람이 검토하고 에이전트가 재사용할 수 있는 이동 가능한 단위로 남아 있나?”
일 가능성이 크다.
그런 관점에서 OKF는 작지만 방향성이 선명한 포맷이다.