코딩 모델 경쟁에서 이제 중요한 질문은 단순히 “코드를 잘 생성하는가”가 아니다.
실제 개발 자동화에서는 모델이 큰 리포지토리를 읽고, 터미널 로그와 테스트 실패를 추적하고, 여러 차례의 수정 루프를 버티며, MCP나 파일시스템 같은 도구 호출을 안정적으로 이어 가야 한다.
즉 모델 점수 하나보다 model + agent harness + context retention + serving stack이 함께 중요해진다.
Moonshot AI가 Hugging Face에 공개한 moonshotai/Kimi-K2.7-Code는 이 흐름을 정면으로 겨냥한 릴리스다.
모델 카드는 Kimi K2.7 Code를 Kimi K2.6 위에 만든 coding-focused agentic model로 설명하며, 장기 코딩 작업의 end-to-end completion을 높이고, K2.6 대비 thinking token 사용량을 약 30% 줄였다고 주장한다.
API 문서에서는 kimi-k2.7-code가 thinking과 preserved thinking을 항상 켠 상태로 동작한다고 명시한다.
내가 보기에 이 릴리스의 핵심은 “1T 공개 코딩 모델이 하나 더 나왔다”가 아니다.
더 정확히는 Moonshot이 Kimi를 코딩 에이전트 런타임의 백본으로 포지셔닝하면서, 모델 카드·Kimi Code CLI·OpenAI/Anthropic 호환 API·vLLM/SGLang/KTransformers 배포 가이드를 한 묶음으로 정리했다는 점이다.
무엇을 해결하려는가
Kimi K2.7 Code가 겨냥하는 문제는 장기 코딩 에이전트의 두 가지 병목이다.
첫째는 작업 성공률이다.
실제 소프트웨어 엔지니어링 작업은 한 번의 함수 작성으로 끝나지 않는다.
이슈를 이해하고, 여러 파일을 수정하고, 테스트를 돌리고, 실패 로그를 다시 읽고, 가끔은 도구 호출 결과를 바탕으로 계획을 바꿔야 한다.
이런 작업에서는 일반적인 코드 완성 능력보다 긴 문맥 유지와 실행 루프의 안정성이 더 중요하다.
둘째는 reasoning 비용이다. thinking 모델은 복잡한 작업에서 강하지만, 에이전트가 오래 실행될수록 reasoning token이 비용과 latency를 크게 만든다.
Kimi K2.7 Code의 모델 카드는 K2.6 대비 thinking-token usage를 약 30% 줄였다고 말한다.
이것이 실제 환경에서 그대로 재현된다면, 성능 개선만큼이나 중요한 운영 지표다.
코딩 에이전트는 한 번 호출하고 끝나는 챗봇이 아니라, 수십 번의 step을 반복하는 시스템이기 때문이다.
API 문서의 preserved thinking도 이 문제 설정과 맞닿아 있다. kimi-k2.7-code는 thinking을 끌 수 없고, preserved thinking도 항상 켜진다.
다중 턴 대화에서는 이전 assistant 메시지의 reasoning_content를 그대로 유지해야 한다.
이는 일반 사용자에게는 다소 까다로운 인터페이스지만, 에이전트 런타임 관점에서는 이전 사고 흔적과 작업 맥락을 보존해 다음 step에서 이어받게 하려는 설계로 읽힌다.
핵심 아이디어 / 구조 / 동작 방식
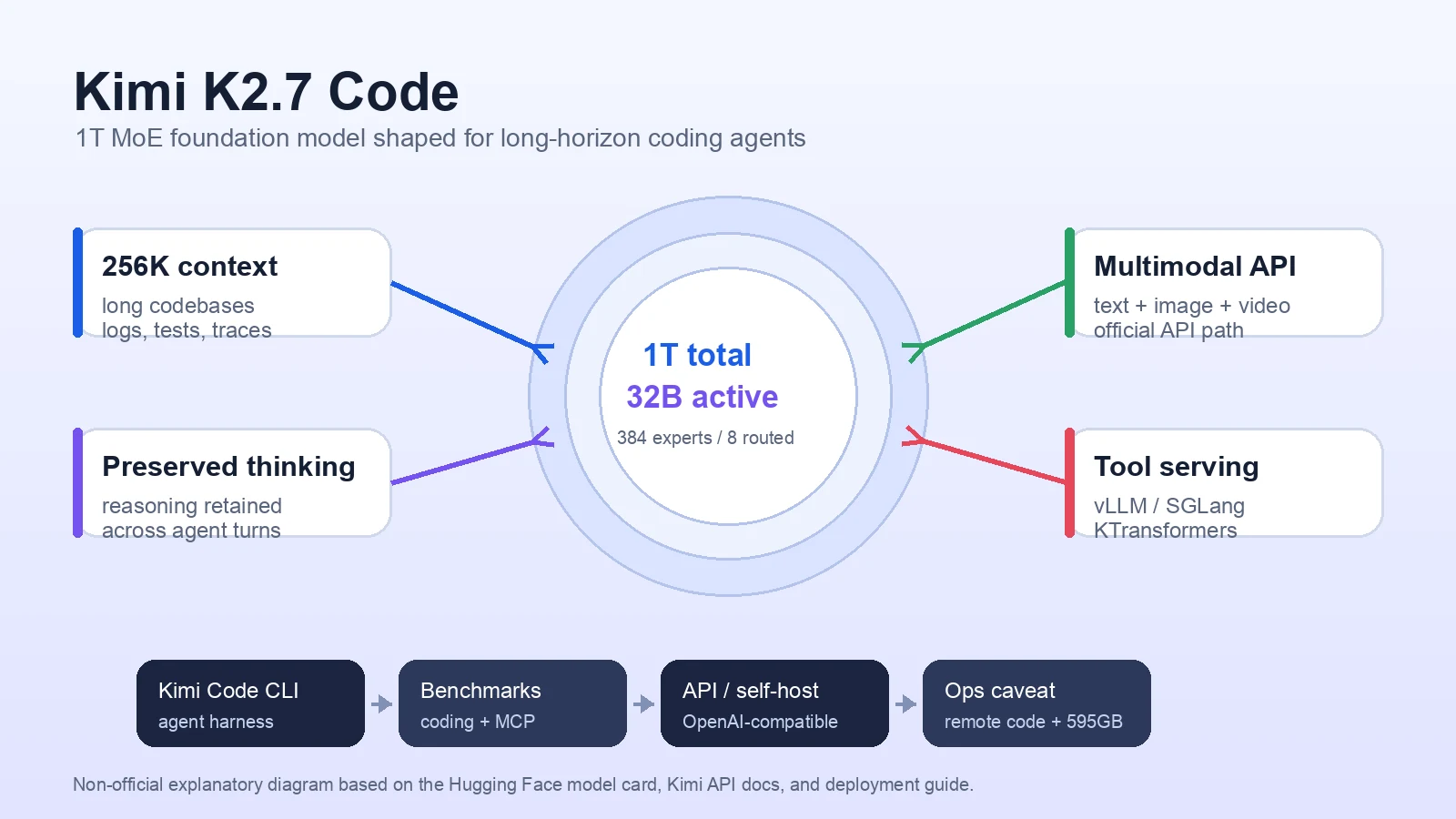
구조적으로 Kimi K2.7 Code는 거대한 sparse MoE 모델이다.
공개 모델 카드 기준 전체 파라미터는 1T, 활성 파라미터는 32B다.
61개 레이어 중 dense layer는 1개이며, 384개 expert 중 토큰당 8개 routed expert와 1개 shared expert를 사용한다. attention hidden dimension은 7168, attention head는 64개, vocabulary는 160K, context length는 256K다. attention mechanism은 MLA, activation은 SwiGLU로 적혀 있다.
흥미로운 점은 이 모델이 순수 텍스트 코딩 모델로만 패키징되지 않았다는 것이다.
모델 카드에는 MoonViT 기반 400M vision encoder가 포함되어 있고, pipeline tag는 image-text-to-text다.
공식 API 사용 예시도 이미지 입력과 비디오 입력을 모두 보여 준다.
다만 모델 카드는 third-party API나 자체 vLLM/SGLang 배포에서 “video content chat”은 아직 공식 API에서만 지원되는 experimental feature라고 구분한다.
따라서 “멀티모달 입력 가능”은 맞지만, 모든 self-host 경로에서 같은 수준으로 지원된다고 보면 안 된다.
배포 표면은 세 갈래다.
첫째, Kimi API에서는 kimi-k2.7-code 모델 ID로 OpenAI 호환 방식의 chat completions를 호출할 수 있다.
가격 문서는 100만 토큰 기준 cache hit input $0.19, cache miss input $0.95, output $4.00, context window 262,144 tokens를 제시한다.
둘째, Kimi Code CLI는 K2.7 Code로 구동되는 코딩 에이전트 제품 표면이다.
셋째, self-host 쪽은 vLLM, SGLang, KTransformers를 권장한다.
| 구성 | 공개 자료에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| 모델 구조 | 1T total / 32B active MoE, 384 experts, 8 routed + 1 shared | 큰 capacity와 제한된 활성 계산량을 결합한 sparse 모델 전략 |
| 문맥/추론 | 256K context, thinking always on, preserved thinking always on | 긴 리포지토리·로그·도구 루프를 한 대화 상태 안에 유지하려는 설계 |
| 입력 모달리티 | 텍스트, 이미지, 공식 API의 비디오 입력 예시 | 코드와 스크린샷·녹화 repro를 함께 넣는 워크플로우 가능성 |
| 배포 경로 | Kimi API, Kimi Code CLI, vLLM, SGLang, KTransformers | API 제품과 오픈 웨이트 self-host를 동시에 제공 |
| 운영 caveat | 64개 safetensors, 약 595GB storage, custom_code, Modified MIT |
가볍게 로컬 실행하는 모델이 아니라 인프라·보안 검토가 필요한 릴리스 |
공개된 근거에서 확인되는 점
벤치마크 표에서 가장 먼저 보이는 것은 K2.6 대비 개선이다.
Kimi Code Bench v2는 50.9에서 62.0으로, Program Bench는 48.3에서 53.6으로, MLS Bench Lite는 26.7에서 35.1로 오른다. agentic benchmark에서도 Kimi Claw 24/7 Bench는 42.9에서 46.9, MCP Atlas는 69.4에서 76.0, MCP Mark Verified는 72.8에서 81.1로 개선된다.
모델 카드가 “long-horizon coding tasks”를 강조하는 이유가 이 표에 그대로 드러난다.
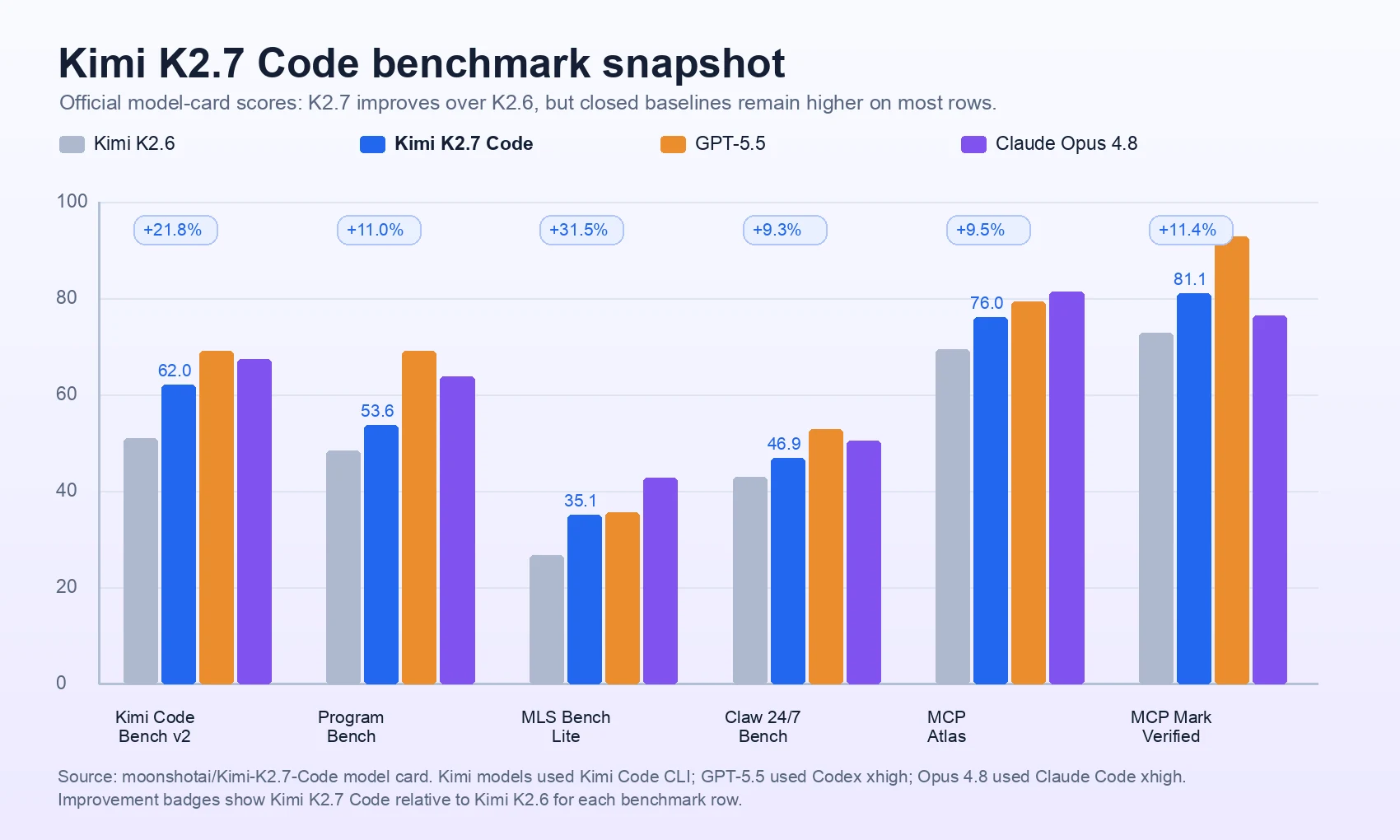
다만 이 표를 “Kimi K2.7 Code가 폐쇄형 frontier를 이겼다”로 읽으면 안 된다.
GPT-5.5는 Kimi Code Bench v2 69.0, Program Bench 69.1, MCP Mark Verified 92.9로 대부분의 행에서 더 높다.
Claude Opus 4.8도 Program Bench 63.8, MLS Bench Lite 42.8, MCP Atlas 81.3에서 K2.7 Code보다 높다.
K2.7 Code가 Opus 4.8보다 앞서는 대표 행은 MCP Mark Verified 81.1 대 76.4다.
중요한 caveat는 평가 harness다.
모델 카드 footnote에 따르면 Kimi K2.7 Code와 K2.6은 thinking mode가 켜진 Kimi Code CLI에서 temperature 1.0, top-p 0.95, 262,144-token context로 평가됐다.
GPT-5.5는 Codex xhigh mode, Claude Opus 4.8은 Claude Code xhigh mode다.
즉 이 표는 순수 모델 하나의 logit 품질만이 아니라, 각 모델이 들어간 코딩 에이전트 제품·CLI·모드의 합성 성능을 보여 준다.
실무적으로는 오히려 이 점이 중요하지만, 논문식 모델 비교처럼 해석하면 과장될 수 있다.
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | 해석 |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | K2.6 대비 큰 개선, 폐쇄형 상위권보다는 낮음 |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | binary/documentation 기반 재구현에서는 격차 존재 |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | GPT-5.5와는 근접, Opus가 더 높음 |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | 지속형 coworking task에서 개선 |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | tool-use 환경에서 경쟁권 진입 |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | Opus 4.8보다 높게 보고된 행 |
릴리스 성숙도 측면에서는 양면성이 있다.
Hugging Face API 확인 시점 기준 이 리포지토리는 gated가 아니고 private도 아니며, 64개 safetensors와 configuration/modeling Python 파일, chat template, deployment guide, license, third-party notice를 함께 제공한다.
사용량 지표는 확인 시점에 downloads 1,689, likes 469로 표시됐다.
모델 파일의 총 storage는 약 595.2GB로, 1T급 MoE를 native INT4/Compressed Tensors 형태로 공개했다는 점을 감안해도 매우 큰 패키지다.
동시에 이 모델은 custom_code 태그와 trust_remote_code 배포 예시를 가진다. vLLM 예시는 --tool-call-parser kimi_k2 --reasoning-parser kimi_k2를 요구하고, SGLang도 동일한 parser 옵션을 명시한다.
KTransformers 예시는 8× NVIDIA L20 + 2× Intel 6454S 환경에서 48-way concurrency 기준 prefill 640.12 tokens/s, decode 24.51 tokens/s를 보고한다.
즉 self-host 가능성은 열려 있지만, 실제 운영은 일반적인 7B/30B 모델처럼 단순하지 않다.
라이선스도 “MIT”이라고만 요약하기에는 약간의 조건이 붙는다.
파일 이름은 Modified MIT License이며, 기본적으로 MIT와 유사한 권한을 부여하지만, 해당 소프트웨어나 derivative를 월간 활성 사용자 1억 명 초과 또는 월매출 2천만 달러 초과 상업 제품·서비스에 사용할 경우 UI에 “Kimi K2.7 Code”를 prominently display해야 한다는 추가 조건이 있다.
대부분의 개인·소규모 팀에는 큰 제약이 아닐 수 있지만, 대형 제품에 넣을 때는 법무 검토 대상이다.
실무 관점에서의 해석
Kimi K2.7 Code의 가장 큰 강점은 “오픈 웨이트 코딩 모델”과 “실제 코딩 에이전트 제품” 사이의 간극을 줄이려 한다는 점이다.
Kimi Code CLI, API 문서, self-host deployment guide가 함께 정리되어 있기 때문에, 이 모델은 단순 checkpoint보다 운영 표면이 분명하다.
특히 preserved thinking이 항상 켜진 구조는 장기 작업에서 이전 reasoning context를 잃지 않으려는 방향으로 설계된 것으로 보인다.
또 하나의 장점은 비용 서사다.
공식 가격 기준 cache miss input $0.95/M, output $4.00/M이면, 긴 컨텍스트 코딩 에이전트 호출을 많이 돌리는 팀 입장에서는 매력적인 가격대다.
여기에 K2.6 대비 thinking token 약 30% 감소라는 주장이 실제 작업에서도 유지된다면, 단순 토큰 단가 이상의 비용 절감 효과가 생길 수 있다.
에이전트 비용은 입력 토큰보다 반복 step과 reasoning output에서 크게 터지는 경우가 많기 때문이다.
하지만 도입 판단은 조심해야 한다.
벤치마크는 대부분 Moonshot이 제시한 모델 카드 기반이고, Kimi Code Bench v2와 Kimi Claw 24/7 Bench는 in-house 성격이 강하다.
Program Bench, MCP Atlas, MCPMark 계열처럼 더 공개적인 기준도 있지만, 각 모델이 서로 다른 CLI와 high-effort mode에서 평가됐다는 점은 계속 남는다.
따라서 이 릴리스는 “공식 표상 경쟁력 있는 코딩 에이전트 백본”이지, 모든 팀의 실제 repo에서 곧바로 같은 pass rate를 낸다는 보장은 아니다.
self-host 관점에서도 마찬가지다.
595GB 규모의 가중치, custom code, parser 옵션, nightly 또는 특정 stable inference engine 요구사항, 비디오 입력의 공식 API 한정 caveat는 모두 운영 난이도를 높인다.
오픈 웨이트라는 사실과 “쉽게 로컬에서 돌릴 수 있다”는 말은 다르다.
대형 팀이라면 vLLM/SGLang/KTransformers 중 어느 경로가 자신의 하드웨어와 tool-call schema에 맞는지 별도로 검증해야 한다.
그럼에도 Kimi K2.7 Code는 중요한 릴리스다.
오픈 모델 경쟁이 이제 일반 채팅 성능보다 long-horizon coding, tool use, preserved reasoning, cost per agent step, deployment parser compatibility로 이동하고 있음을 보여 준다.
Kimi K2.7 Code가 폐쇄형 최고 모델을 전부 넘었다고 말하기는 어렵지만, K2.6 대비 개선 폭과 API/CLI/self-host 패키징을 함께 보면, 코딩 에이전트 백본으로서 Moonshot이 어디를 향하고 있는지는 꽤 선명하다.