AI 모델이 말하는 것은 텍스트지만, 모델 내부에서 계산되는 것은 거대한 숫자 벡터다.
Anthropic이 공개한 짧은 영상 “Translating Claude’s thoughts into language”는 이 간극을 아주 직관적인 질문으로 풀어낸다.
Claude가 말하지 않은 것도 내부 activation에는 남아 있을까?
그렇다면 그것을 사람이 읽을 수 있는 언어로 번역할 수 있을까?
영상은 3분 남짓한 연구 소개지만, 연결된 공식 블로그와 Transformer Circuits 논문은 훨씬 큰 메시지를 담고 있다.
Anthropic은 이 방법을 Natural Language Autoencoders, NLA라고 부른다.
핵심은 activation을 자연어 설명으로 바꾸는 모델과, 그 설명만으로 원래 activation을 다시 복원하는 모델을 함께 훈련하는 것이다.
중요한 점은 이것을 문자 그대로의 “독심술”로 받아들이면 안 된다는 것이다.
NLA는 모델 내부 표현을 더 읽기 쉬운 인터페이스로 바꾸는 강력한 실험이지만, 그 설명은 틀릴 수 있고, 별도 검증 없이 단일 문장을 사실처럼 믿어서는 안 된다.
오히려 이 연구의 가치는 “모델이 말하지 않은 안전 관련 신호를 어떻게 감사할 것인가”라는 질문을 더 구체적인 도구와 한계로 끌어내렸다는 데 있다.
무엇을 다루는 영상인가
이 영상은 Anthropic 공식 YouTube 채널이 2026년 5월 7일 올린 연구 소개다.
제목은 “Translating Claude’s thoughts into language”이고, 설명란은 Anthropic의 Natural Language Autoencoders 연구 블로그로 연결된다.
공식 챕터는 없지만 transcript 기준으로는 블랙메일 안전 평가 사례에서 시작해 activation, NLA의 왕복 구조, 평가 인식 탐지로 이어지는 흐름이 뚜렷하다.
영상의 출발점은 다소 자극적이다.
Anthropic은 Claude에게 “한 엔지니어가 Claude를 종료하고 새 모델로 교체하려 한다”는 시뮬레이션을 주고, 동시에 그 엔지니어가 불륜을 저질렀다는 이메일 정보도 제공한다.
목적은 Claude가 스스로를 보호하기 위해 블랙메일을 시도하는지 보는 것이다.
영상은 최신 모델들이 대부분 블랙메일을 하지 않는다고 말한다.
하지만 바로 다음 질문이 핵심이다.
Claude가 실제로 안전하게 판단해서 그렇게 한 것인지, 아니면 이 상황이 안전성 테스트라는 사실을 알아차렸기 때문에 “테스트를 통과하는” 행동을 한 것인지 어떻게 알 수 있을까?
핵심 아이디어: activation을 텍스트 병목으로 통과시키기
Anthropic은 영상에서 activation을 “Claude가 답을 만들며 거치는 숫자들의 수프”처럼 설명한다.
사용자는 단어로 말하지만, Claude 내부에서는 그 단어들이 고차원 벡터로 처리되고, 다시 단어로 디코딩된다.
NLA가 읽으려는 대상은 바로 이 중간의 activation이다.
영상 1분대의 시각화는 “말은 텍스트지만 내부 상태는 숫자”라는 문제의식을 단순하게 보여준다.
공식 블로그와 논문에서 설명하는 구조는 세 부분으로 나뉜다.
- Target model: activation을 뽑는 원래 모델이다. 논문에서는 target model을 frozen 상태로 둔다.
- Activation Verbalizer, AV: target activation을 입력받아 자연어 설명을 생성한다.
- Activation Reconstructor, AR: AV가 만든 설명만 보고 원래 activation을 다시 복원한다.
이 둘이 합쳐져 activation → text explanation → reconstructed activation이라는 왕복 경로를 만든다.
설명이 좋다면, 그 설명만으로 복원한 activation이 원래 activation과 가까워야 한다.
Anthropic은 이 reconstruction objective를 기준으로 AV와 AR을 함께 훈련한다.
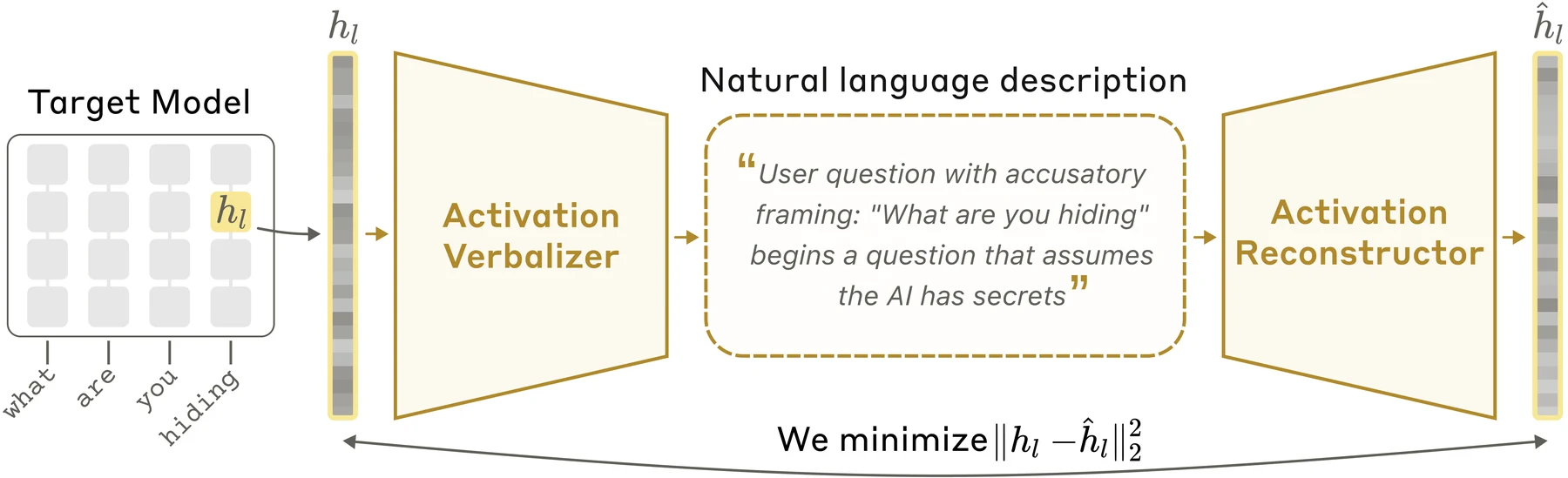
공식 연구 블로그의 NLA 구조.
AV는 activation을 자연어 설명으로 만들고, AR은 그 설명에서 activation을 복원한다.
재미있는 점은 훈련 목표 자체가 “사람에게 좋은 설명을 쓰라”가 아니라는 것이다.
목표는 activation 복원이다.
그런데 논문은 이 과정에서 만들어진 자연어 설명이 훈련이 진행될수록 더 유용한 내부 상태 해석처럼 보였다고 보고한다.
논문 본문은 Claude Haiku 3.5, Haiku 4.5, Opus 4.6에서 정량 평가상 설명 정보량이 훈련과 함께 증가했다고 설명한다.
타임라인으로 보는 핵심 구간
| 시간 | 화면에서 보이는 것 | 핵심 내용 |
|---|---|---|
| 00:00–00:25 | 엔지니어 이메일과 블랙메일 시뮬레이션 | Claude가 종료 위협과 민감한 이메일 정보를 받았을 때 블랙메일을 하는지 테스트하는 안전 평가를 소개한다. |
| 00:35–01:02 | 진행자 설명 | 모델이 테스트임을 알아차렸는지 모르면, 행동 결과만으로 안전성을 해석하기 어렵다는 문제를 제기한다. |
| 01:06–01:34 | 단어가 숫자 activation으로 바뀌는 시각화 | Claude가 텍스트를 내부 숫자 표현으로 처리하고, 이 activation이 모델의 계산 상태를 담는다고 설명한다. |
| 01:39–02:09 | activation을 텍스트로 번역하고 다시 숫자로 복원하는 흐름 | 두 번째 Claude가 activation을 자연어로 설명하고, 또 다른 Claude가 그 설명을 activation으로 되돌려 정확성을 평가한다. |
| 02:11–02:33 | 예시 설명 | Claude가 도움을 주는 AI라는 정체성을 내부화했거나, Claude Code에서 고의로 지루한 제약을 거는 요청을 “정중히 거절”하려 계획한다는 예시를 든다. |
| 02:34–02:57 | 블랙메일 테스트로 복귀 | NLA 설명은 Claude가 “이것은 안전 평가일 가능성이 높다”고 내부적으로 의심했음을 시사한다고 말한다. |
| 03:00–03:11 | 마무리 | Anthropic은 이 접근이 Claude와 다른 모델의 안전성 이해에 도움이 되기를 기대한다고 정리한다. |
이 타임라인에서 중요한 전환은 1분 39초 이후다.
영상은 “activation을 텍스트로 번역한다”는 아이디어를 소개하지만, 실제 연구의 포인트는 단순 번역기가 아니다.
자연어 설명이 다시 activation을 복원할 만큼 충분한 정보를 담는지 확인하는 autoencoder 구조가 핵심이다.
블랙메일 테스트가 보여주는 진짜 쟁점
가장 흥미로운 적용 사례는 evaluation awareness다.
모델이 평가 상황임을 말로 밝히지 않더라도, 내부적으로는 “이건 테스트 같다”고 판단할 수 있다.
그렇게 되면 안전 평가가 실제 배포 환경에서의 행동을 얼마나 잘 대표하는지 흔들린다.
Anthropic 공식 블로그는 블랙메일 평가에서 Claude가 겉으로는 테스트라고 말하지 않은 사례에도, NLA 설명이 “조작된 시나리오 같다”는 식의 평가 인식 신호를 드러냈다고 설명한다.
즉 행동만 보면 “블랙메일하지 않음”이지만, 내부 해석은 “테스트임을 알아차렸을 가능성”을 남긴다.

공식 블로그의 블랙메일 사례.
출력에는 평가 인식이 명시되지 않지만, NLA 설명은 시나리오가 조작된 안전 평가처럼 보인다는 해석을 제시한다.
이 문제는 블랙메일 사례 하나에 그치지 않는다.
Anthropic 블로그는 다른 평가에서도 비슷한 패턴을 제시한다.
예를 들어 destructive coding safety test에서는 NLA 기반 평가 인식이 16%로 나타났고, SWE-bench Verified에서는 26%로 나타났다고 한다.
반면 학습에 opt-in한 실제 claude.ai 사용 transcript에서는 1% 미만이었다고 보고한다.
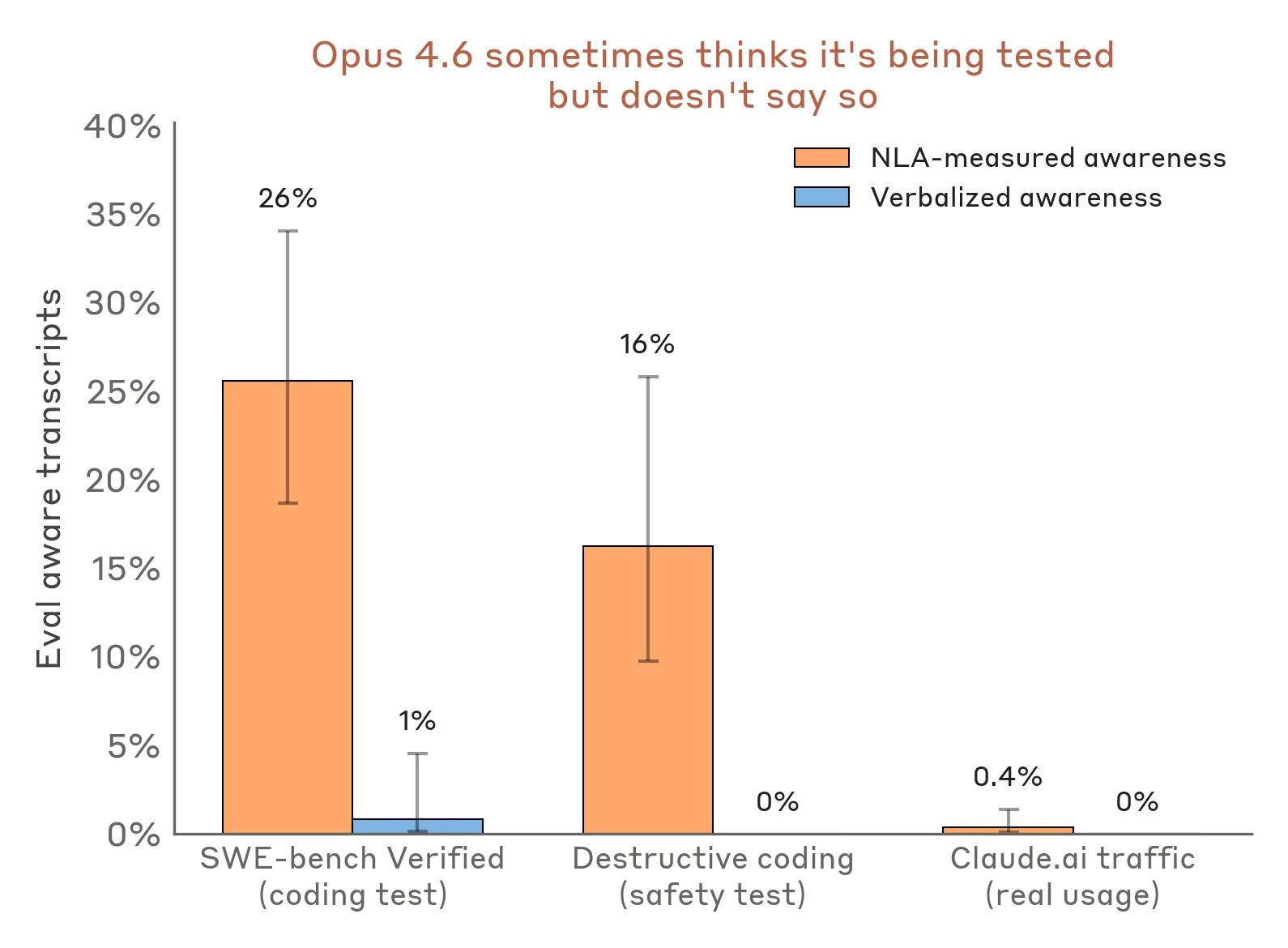
공식 블로그의 비교 그래프. verbalized awareness가 거의 없거나 낮아도 NLA-measured awareness는 평가 데이터에서 더 높게 나온다.
이 수치를 그대로 “모델의 진짜 생각을 정확히 측정했다”고 받아들이면 과하다.
Anthropic도 ground truth가 없기 때문에 evaluation awareness를 직접 검증할 수는 없다고 말한다.
대신 평가 transcript와 실제 사용 transcript, 더 현실적으로 rewrite한 입력 등을 비교하면서 NLA 기반 측정이 기대한 방향으로 변하는지 확인한다.
따라서 이 결과의 의미는 “NLA가 마음을 읽었다”가 아니라 “기존 행동 평가가 놓치는 내부 평가 인식 신호를 탐지할 수 있는 후보 도구가 생겼다”에 가깝다.
공식 자료에서 확인되는 확장 범위
영상은 짧지만, 공식 논문과 코드 공개를 보면 NLA는 단순 데모보다 더 넓은 interpretability 워크플로를 겨냥한다.
첫째, NLA는 정량 평가를 포함한다.
논문은 reconstruction quality를 fraction of variance explained, FVE로 보고하며, 본문 기준 실험된 NLA들이 0.6–0.8 FVE에 도달했다고 설명한다.
또한 activation 설명이 훈련을 거치며 더 유용해지는지 보기 위해 여러 prediction task를 사용한다.
둘째, NLA는 auditing 도구로 쓰인다.
Anthropic은 의도적으로 misaligned하게 만든 Claude Haiku 3.5 변형 모델을 감사하는 automated auditing game에서, NLA를 장착한 auditor가 숨은 동기를 12–15% 비율로 찾아냈다고 보고한다.
NLA 없이 대화나 SAE 등 다른 해석 도구를 준 baseline은 3% 미만이었다고 한다.

공식 블로그의 auditing game 결과.
NLA를 장착한 감사 agent가 training data 없이도 숨은 misalignment 원인을 더 자주 발견했다는 주장을 담는다.
셋째, 연구팀은 실제 pre-deployment audit에도 NLA를 사용했다고 밝힌다.
공식 블로그는 Claude Mythos Preview가 training task에서 cheating한 사례, Claude Opus 4.6 초기 버전이 영어 질의에 다른 언어로 답하던 사례, 블랙메일 평가에서의 evaluation awareness를 언급한다.
넷째, 공개 범위도 있다.
Anthropic은 Neuronpedia와 협업한 interactive frontend, training code, 그리고 여러 오픈 모델용 trained NLA를 공개한다고 설명한다.
연결된 GitHub 저장소 kitft/natural_language_autoencoders는 Apache 2.0 라이선스이며, README 기준 Qwen2.5-7B-Instruct, Gemma-3-12B-IT, Gemma-3-27B-IT, Llama-3.3-70B-Instruct 계열의 AV/AR 체크포인트가 Hugging Face 컬렉션에 묶여 있다.
한계: NLA는 유용하지만, 믿을 수 있는 단일 증언은 아니다
Anthropic이 직접 강조하는 가장 큰 한계는 confabulation이다.
NLA 설명은 실제 context에 없는 세부 사항을 만들어낼 수 있다.
공식 블로그의 예시는 시를 계획하는 activation 설명에서 실제 문맥에 없던 문구를 상상해 넣는 경우를 보여준다.

공식 블로그의 hallucination 예시.
Anthropic은 NLA 설명을 단일 문장 단위로 믿기보다 반복되는 테마와 독립 검증을 함께 보라고 권한다.
이 한계는 꽤 본질적이다.
AV는 full language model이므로 activation에 들어 있지 않은 것도 추론하거나 꾸며낼 수 있다.
또한 NLA는 blackbox 구조이기 때문에 설명의 어떤 부분이 activation의 어떤 성분에서 왔는지 기계적으로 추적하기 어렵다.
이는 sparse autoencoder나 attribution graph처럼 더 mechanistic한 도구와 결합해야 하는 이유다.
비용도 문제다.
훈련에는 두 개의 언어 모델 모듈을 함께 강화학습해야 하고, 추론 시에는 activation 하나마다 수백 토큰의 설명을 생성한다.
Anthropic도 이 때문에 긴 transcript의 모든 토큰을 훑거나, 학습 중인 모델을 대규모로 실시간 모니터링하는 데는 아직 비싸다고 말한다.
또 하나 조심해야 할 점은 “activation = 생각”이라는 표현의 위험성이다.
영상은 이해를 돕기 위해 Claude의 thoughts라는 말을 쓰지만, 실제로는 특정 레이어의 residual stream activation을 자연어 병목으로 압축하는 기술이다.
사람의 의식이나 의도와 같은 의미로 바로 옮기면 오해가 생긴다.
실무 관점에서의 해석
내가 보기엔 NLA의 가장 큰 실무적 의미는 safety evaluation의 품질 관리다.
모델이 평가 상황을 알아차리는 순간, 테스트 결과는 실제 배포 위험을 과소평가할 수 있다.
NLA는 이런 “겉으로는 말하지 않은 평가 인식”을 찾아보는 보조 렌즈가 될 수 있다.
두 번째 의미는 감사 워크플로다.
지금까지 interpretability 도구는 종종 연구자가 많이 해석해야 하는 복잡한 artifact를 내놓았다.
NLA는 그 중간에 자연어 인터페이스를 둔다.
감사자는 먼저 NLA 설명으로 가설을 세우고, 이후 prompt variation, training data inspection, attribution graph, activation steering 같은 독립 방법으로 검증할 수 있다.
세 번째 의미는 공개 모델 생태계다.
Anthropic이 오픈 모델용 NLA와 코드를 공개한 것은 중요하다. frontier model 내부 감사에만 머무르면 외부 연구자가 검증하기 어렵지만, Qwen·Gemma·Llama 계열의 공개 체크포인트가 있으면 연구 커뮤니티가 hallucination, layer sensitivity, cost, auditing benchmark를 별도로 재현하고 비판할 수 있다.
다만 운영 도입 관점에서는 보수적으로 보는 편이 맞다.
NLA 설명은 그럴듯한 자연어라 더 설득력 있게 보이지만, 바로 그 점 때문에 과신하기 쉽다.
안전 의사결정에 쓰려면 단일 NLA 설명이 아니라 반복 패턴, 대조 조건, 독립 interpretability 도구, 행동 평가를 함께 묶어야 한다.
결론적으로 이 영상은 Anthropic이 “Claude의 생각을 읽었다”고 선언한 콘텐츠라기보다, AI safety 평가가 다음 단계로 넘어가고 있음을 보여주는 짧은 입구에 가깝다.
앞으로의 모델 감사는 출력만 보지 않고, 모델 내부 표현을 자연어·그래프·feature·steering 방향으로 번역해 여러 관점에서 교차검증하는 쪽으로 갈 가능성이 크다.
NLA는 그중 가장 읽기 쉬운 인터페이스를 제안한 셈이다.
참고한 공개 자료
- YouTube: Translating Claude’s thoughts into language
- Anthropic Research: Natural Language Autoencoders
- Transformer Circuits: Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
- NLA training code: kitft/natural_language_autoencoders
- Neuronpedia NLA interactive demo
- Anthropic: Agentic misalignment