VLM의 약점은 단순히 “그림을 잘 못 본다”로 끝나지 않는다.
이미지에는 없는 물체를 언어 prior로 채워 넣고, 실제로 중요한 객체를 빠뜨리며, 공간 관계를 그럴듯한 문장으로 덮어 버리는 문제가 제품 단계에서는 곧바로 신뢰성 문제로 이어진다.
보통 이 문제는 더 많은 image-text pair, 더 정교한 preference data, 혹은 inference-time verifier를 붙이는 방향으로 다뤄졌다.
Feedback-Driven Vision-Language Alignment with Minimal Human Supervision은 이 흐름을 조금 다르게 본다.
저자들이 제안하는 **SVP(Sampling-based Visual Projection)**는 새로운 VLM 아키텍처라기보다, 이미 가진 VLM 안의 latent visual knowledge를 grounding feedback으로 끌어내는 post-training 절차에 가깝다.
핵심 질문은 이렇다.
사람이 문장을 달아준 대규모 paired data 없이도, 모델 자신의 caption과 외부 grounding model의 시각 피드백만으로 더 grounded한 training signal을 만들 수 있을까?
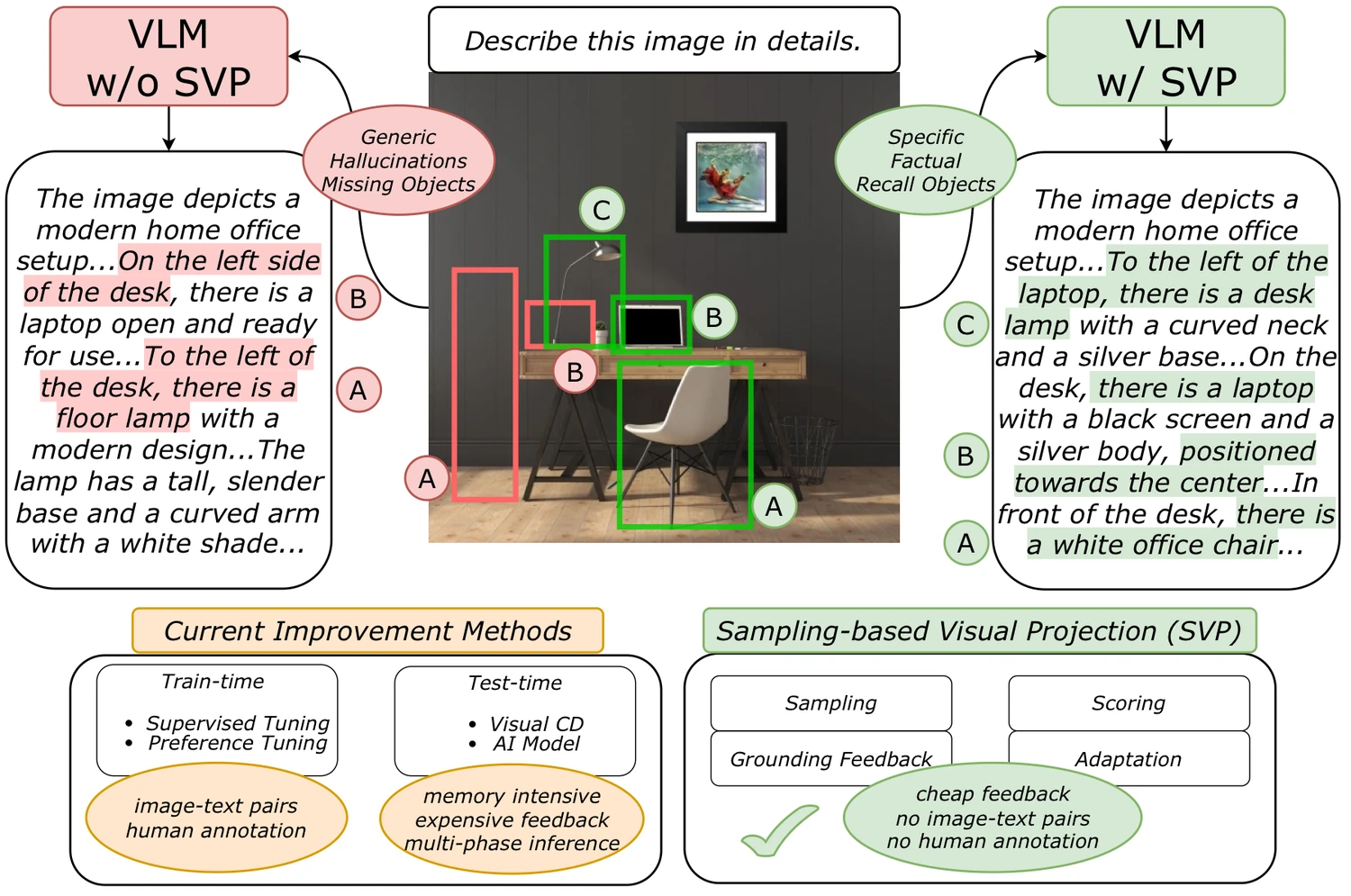
무엇을 해결하려는가
논문이 겨냥하는 병목은 VLM alignment 데이터의 비용과 불안정성이다. supervised fine-tuning은 고품질 이미지-텍스트 쌍을 요구하고, preference-based alignment는 선호쌍이나 reward model을 요구한다. test-time correction은 모델을 바꾸지 않는 장점이 있지만, inference마다 여러 단계의 검증·수정 루프를 돌려야 하므로 비용과 지연이 커진다.
SVP의 문제 정의는 더 좁고 실용적이다.
VLM이 이미 어느 정도 시각 정보를 갖고 있지만, 그 정보를 언어 토큰으로 안정적으로 투사하지 못한다고 가정한다.
그러면 사람이 새 문장을 쓰는 대신, 모델이 스스로 만든 caption을 grounding model로 검사하고, 그 피드백이 실제로 모델의 토큰 분포를 어떻게 바꾸는지 측정해, 학습에 쓸 만한 샘플만 고를 수 있다.
이 접근은 “강한 언어 교사에게 정답 문장을 받는다”기보다 “외부 시각 grounder를 이용해 모델의 말과 이미지 사이의 틈을 드러낸다”에 가깝다.
그래서 논문의 중심은 caption 품질 자체보다 시각 근거가 언어 생성 분포를 어떻게 재정렬하는가에 있다.
핵심 아이디어 / 구조 / 동작 방식
SVP는 inner-loop sampling, scoring, outer-loop adaptation의 세 단계로 구성된다.
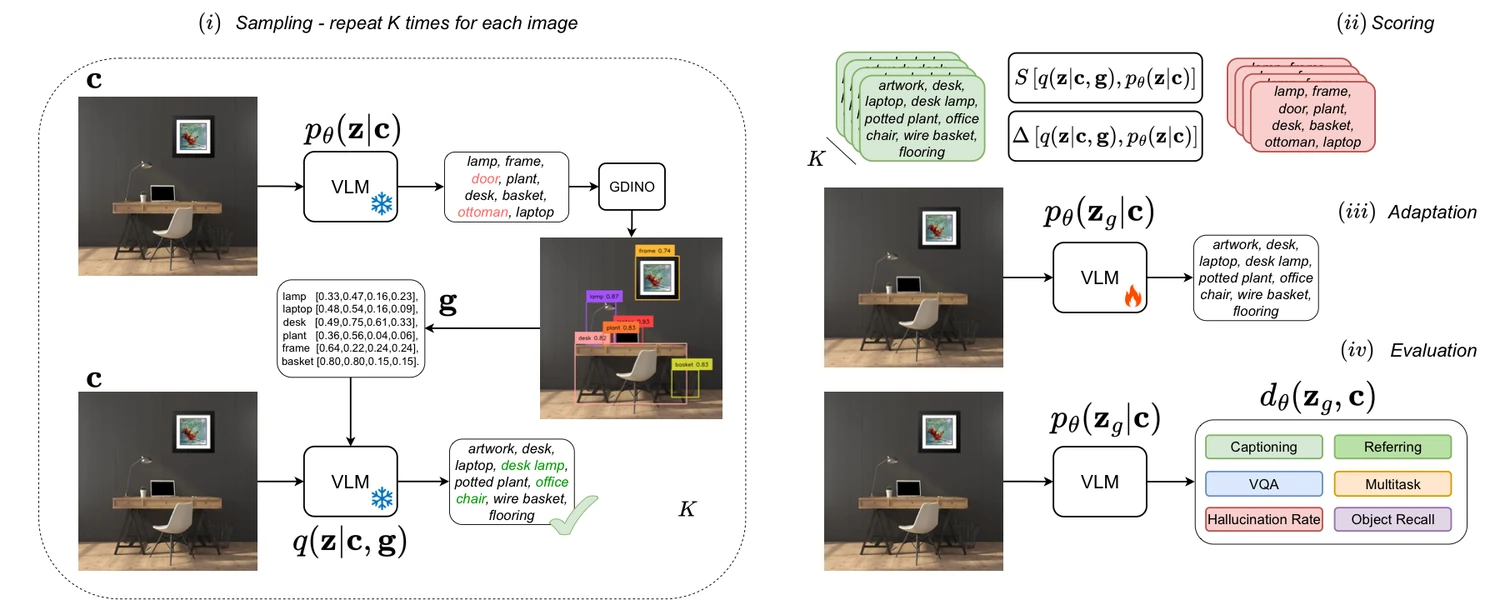
첫째, base VLM이 이미지에 대해 자세한 visual projection, 즉 일반화된 caption을 만든다.
이 caption은 GroundingDINO류 open-set grounding model에 들어가고, grounding 결과는 다시 텍스트 형태의 피드백으로 변환되어 같은 VLM의 다음 sampling 조건에 들어간다.
논문은 grounding box 자체를 최종 supervision으로 쓰기보다, “무엇이 이미지에 실제로 잡혔는가”를 언어 생성 과정의 context로 넣는다.
둘째, SVP는 단순히 grounded caption을 모두 학습하지 않는다. guided distribution q(z | c, g)와 원래 base model distribution pθ(z | c)의 차이를 이용해 샘플을 점수화한다. log-ratio score와 weighted-difference score를 사용해, grounding feedback이 실제로 토큰 선택을 의미 있게 바꾼 샘플을 더 가치 있는 학습 신호로 본다.
단순히 낯선 문장을 고르는 것이 아니라, 시각 grounding 때문에 달라진 문장을 고르려는 설계다.
셋째, 선택된 샘플로 base VLM을 LoRA fine-tuning한다.
실험 설정에서 저자들은 COCO2014 training image 중 C = 1000장을 샘플링하고, 이미지마다 K = 20개 샘플을 생성한다.
본문 implementation detail 기준으로는 top 10% 샘플을 고르며, SVP(C)는 약 4,000개, visual query를 추가한 SVP(CVQ)는 약 8,000개 training pair를 만든다. adaptation은 1 epoch LoRA로 수행되며, 7B 이하 모델에는 r=64, α=16, 13B 모델에는 r=128, α=256 설정을 사용한다.
개요 그림에는 top 20% 선택이 표시되어 있고, 실험 세부 설명에는 top 10%가 적혀 있다.
이 차이는 버전이나 설정 표기의 흔적으로 보이며, 글의 해석에서는 특정 비율 자체보다 “grounding feedback으로 informative sample을 고른 뒤 작은 adaptation set으로 재학습한다”는 구조가 더 중요하다.
| 단계 | SVP에서 하는 일 | 실무적 의미 |
|---|---|---|
| Inner-loop sampling | base VLM caption → grounding model feedback → guided caption 생성 | 사람이 새 라벨을 쓰지 않아도 시각 피드백이 들어간 self-training 후보를 만든다 |
| Scoring | q와 pθ의 log-ratio / weighted difference로 informative sample을 선별 |
단순 self-captioning이 아니라 grounding이 실제로 바꾼 샘플을 우선한다 |
| Outer-loop adaptation | 선별 샘플로 LoRA fine-tuning | 작은 데이터로 VLM의 language projection을 보정한다 |
| Evaluation | captioning, referring, VQA, multitasking, hallucination, object recall을 함께 측정 | hallucination만 줄이고 다른 능력을 잃는지 확인한다 |
공개된 근거에서 확인되는 점
논문은 LLaVA 계열을 중심으로 SVP를 평가한다.
저자들은 LLaVA-1.5, LLaVA-1.6, LLaVA-OV, VILA, InternVL 등 다양한 모델 스케일과 encoder 조합을 언급하지만, 핵심 표는 LLaVA-1.6 7B/13B에서 가장 읽기 쉽다.
평가 범위는 captioning, referring expression, VQA, multitasking, hallucination control, object recall의 6개 영역이며, COCO2017, NoCaps, Flickr30k, RefCOCO variants, ScienceQA, GQA, MMBench, MMMU, POPE 등을 포함한다.
가장 명확한 메시지는 captioning과 referring에서 나온다.
LLaVA-1.6-7B 기준으로 NoCaps CIDEr는 92.60 → 103.95, COCO2017 CIDEr는 109.68 → 115.02, Flickr30k CIDEr는 78.74 → 85.31까지 오른다.
같은 모델의 RefCOCO score는 6.70 → 24.74로 크게 올라간다.
논문 abstract가 말하는 “captioning 평균 14% 개선”과 “poor referring capability가 두 배 이상 개선”이라는 주장은 이 표와 정합적이다.
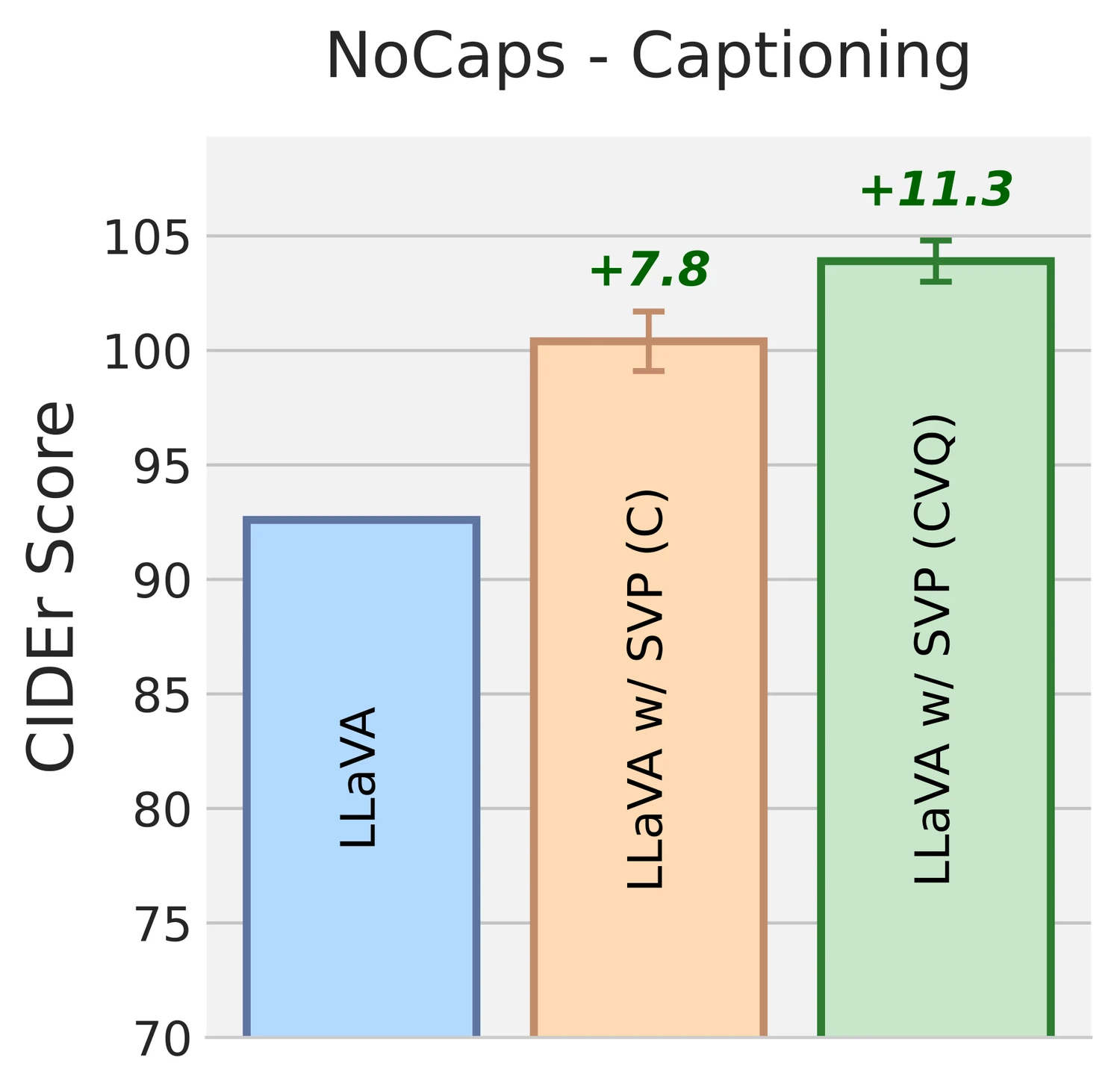
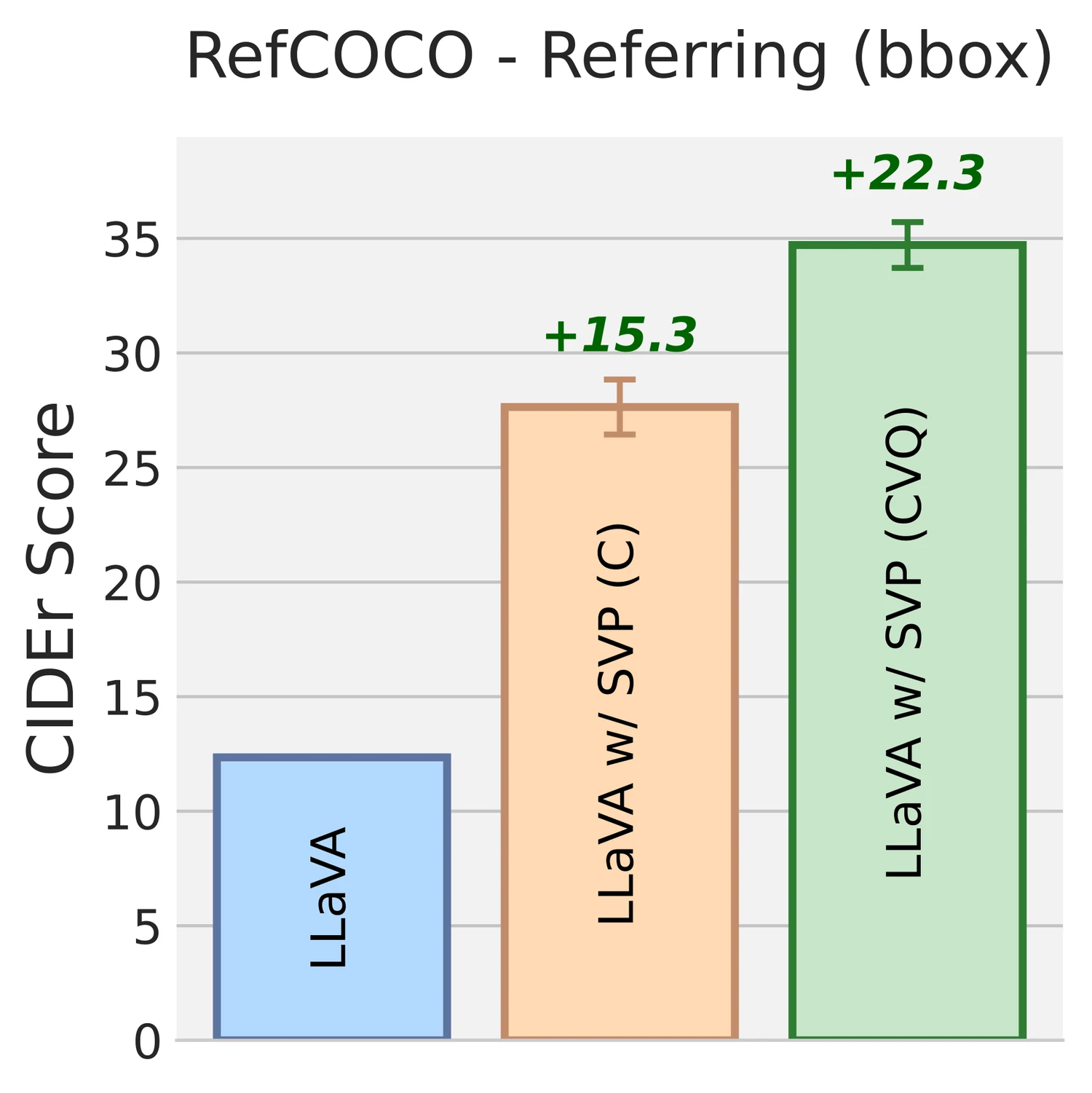
환각 억제에서도 개선이 보인다.
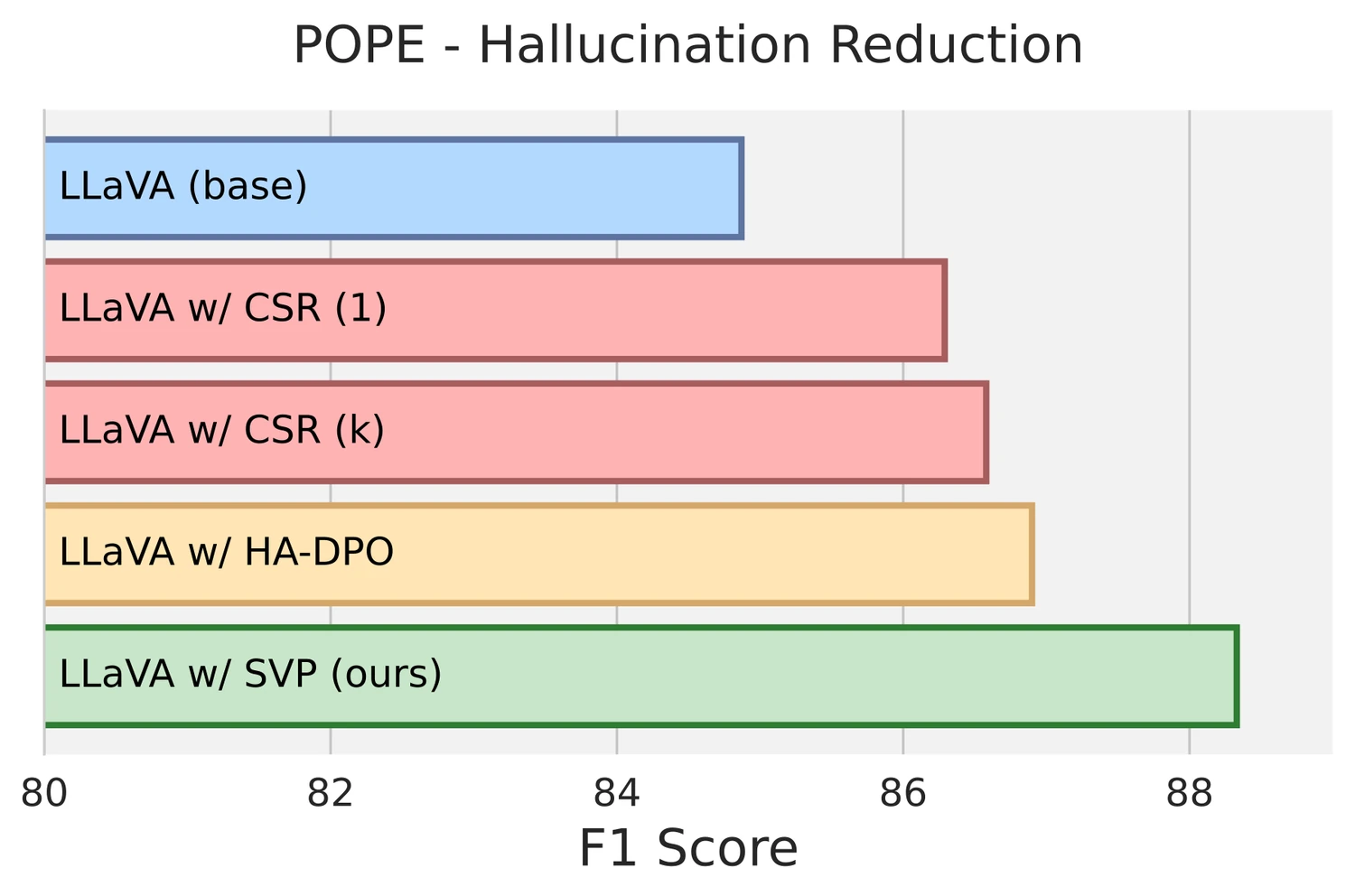
POPE F1 기준 LLaVA-1.6-7B는 86.73 → 88.33, 13B는 86.24 → 87.68로 오른다.
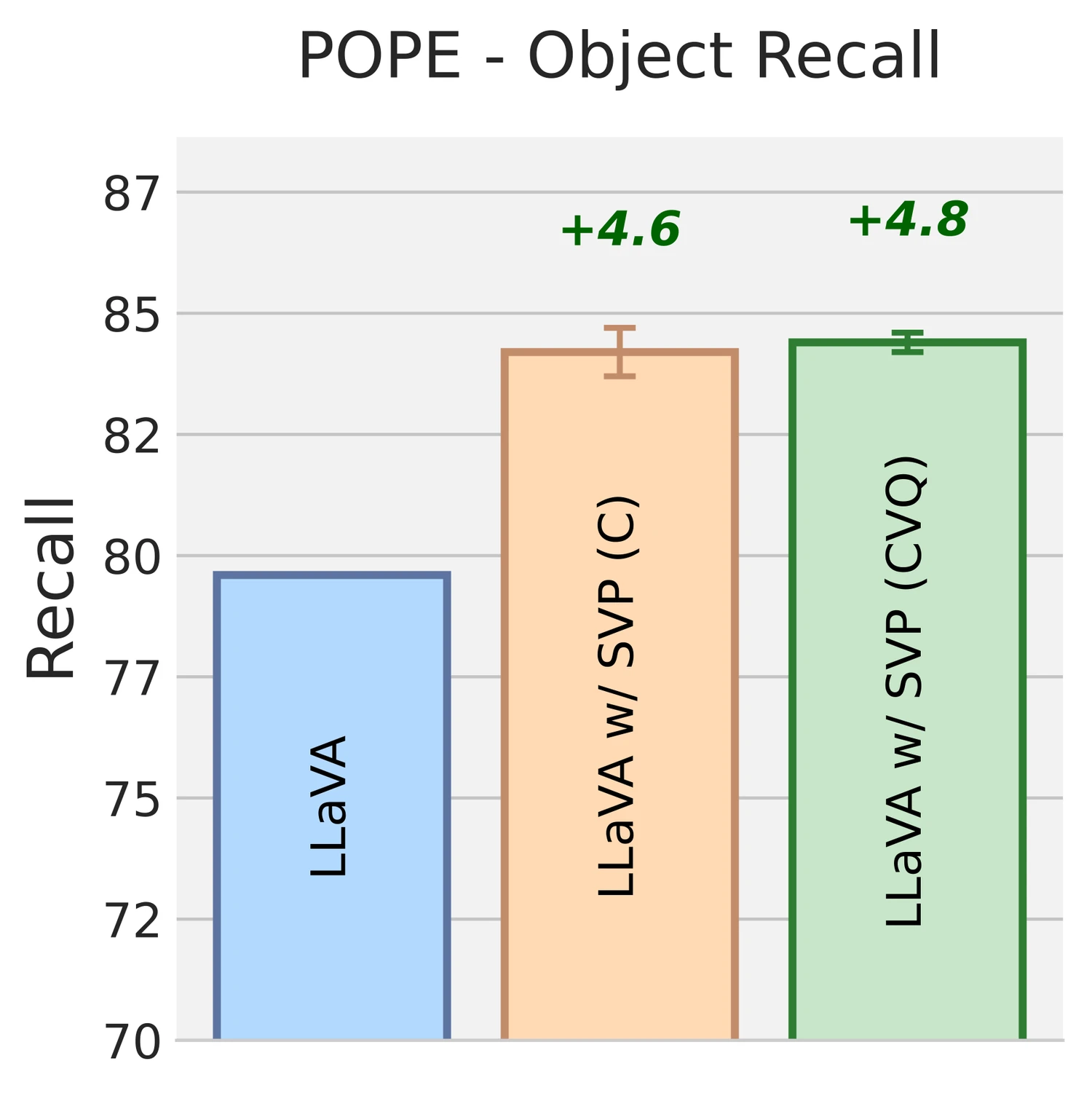
별도 barplot에서도 LLaVA w/ SVP가 base, CSR, HA-DPO 계열보다 높은 F1을 보인다. object recall 역시 7B 실험에서 base 대비 약 +4.6~+4.8p 수준의 개선으로 제시된다.
다만 모든 항목이 일방적으로 좋아지는 것은 아니다.
LLaVA-1.6-7B에서 ScienceQA와 GQA는 SVP(CVQ) 기준으로 baseline과 거의 비슷하거나 약간 낮다.
13B에서도 RefCOCO는 baseline 29.71 대비 SVP(CVQ) 27.20으로 내려가는 설정이 있다.
저자들이 강조하듯 SVP는 새로운 knowledge를 주입하는 방법이라기보다, spatial grounding과 object-level recall이 중요한 영역에서 language projection을 보정하는 방법에 가깝다.
ablation은 이 해석을 더 분명하게 만든다.
LLaVA-1.6-7B 기준으로 단순 self-training에 가까운 w/o SVP는 RefCOCO가 3.01까지 떨어진다. grounding만 넣으면 9.98, grounding과 scoring을 함께 쓰면 18.15, visual query까지 더하면 24.74가 된다.
즉 성능은 “self-caption을 더 만든다”가 아니라, grounding feedback과 sample selection policy가 결합될 때 나온다.
| 설정 | Grounding | Scoring | Visual Query | RefCOCO | Flickr30k | MMMU | POPE |
|---|---|---|---|---|---|---|---|
| LLaVA baseline | - | - | - | 6.70 | 78.74 | 34.11 | 86.73 |
| w/o SVP | ✗ | ✗ | ✗ | 3.01 | 79.03 | 35.55 | 87.21 |
| w/ SVP | ✓ | ✗ | ✗ | 9.98 | 78.67 | 35.77 | 86.92 |
| w/ SVP | ✓ | ✓ | ✗ | 18.15 | 83.49 | 36.44 | 88.33 |
| w/ SVP | ✓ | ✓ | ✓ | 24.74 | 85.31 | 37.44 | 88.25 |
실무 관점에서의 해석
SVP의 실무적 가치는 VLM alignment를 “더 큰 teacher가 더 좋은 문장을 써준다”에서 “외부 perception module이 모델의 언어 투사를 교정한다”로 옮긴 데 있다.
이미지-텍스트 pair를 대량으로 새로 만들기 어려운 팀이라면, 이미 보유한 이미지와 open-set grounding model을 사용해 self-training 후보를 만들고, grounding이 실제로 영향을 준 샘플만 골라 adaptation set을 구성하는 레시피로 읽을 수 있다.
특히 중요한 점은 SVP가 hallucination mitigation을 단독 목표로 삼지 않는다는 것이다.
환각만 줄이려면 모델을 더 보수적으로 만들거나, inference-time verifier로 응답을 깎아낼 수도 있다.
그러나 SVP는 captioning, referring, object recall을 함께 밀어 올리면서 POPE도 개선하려 한다.
즉 “덜 말하게 하는 안전장치”보다, 더 정확히 본 것을 더 잘 말하게 하는 alignment에 가깝다.
그럼에도 배포 관점에서는 한계가 분명하다.
첫째, SVP는 base VLM이 in-context feedback을 어느 정도 활용할 수 있어야 한다.
둘째, 이미지마다 여러 샘플을 생성하고 grounding을 반복해야 하므로 데이터 생성 비용은 작지 않다.
실험도 8×A100 환경의 LoRA adaptation을 사용한다.
셋째, grounding model의 품질에 의존하기 때문에, grounding이 약한 도메인이나 spatial component가 약한 지식형 VQA에서는 이득이 제한될 수 있다.
넷째, arXiv와 Hugging Face Papers 페이지에서는 공식 코드 저장소나 checkpoint 배포를 확인하지 못했다.
따라서 현재로서는 바로 가져다 쓰는 라이브러리라기보다, VLM post-training 파이프라인을 설계할 때 참고할 연구 레시피로 보는 편이 맞다.
내가 보기에 이 논문의 가장 흥미로운 지점은 “minimal human supervision”이라는 표현이 단순히 라벨 비용을 줄인다는 뜻이 아니라는 데 있다.
SVP는 사람이 덜 개입하되, 모델이 스스로 만든 언어 신호를 그대로 믿지 않는다.
대신 grounding model을 통해 시각 세계와 문장 사이의 불일치를 측정하고, 그 불일치가 학습 가치가 있는 경우만 골라낸다.
VLM 정렬에서 앞으로 중요한 것은 더 많은 caption이 아니라, 어떤 feedback channel을 통해 caption을 선별할 것인가일 수 있다.