AI 에이전트가 실패하는 이유를 아직도 “프롬프트가 덜 정교해서”라고만 보면, 실제 제품에서 가장 자주 터지는 병목을 놓치기 쉽다.
에이전트는 한 번 답하고 끝나는 챗봇이 아니라, 도구를 호출하고, trace를 읽고, 중간 결과를 남기고, 사용자의 후속 질문을 따라가며, 스스로 만든 데이터까지 다시 분석한다.
이 과정에서 context window는 단순한 토큰 제한이 아니라 제품 경험 전체를 흔드는 운영 자원이 된다.
AI Engineer 채널의 발표 **“Hierarchical Memory: Context Management in Agents”**는 이 문제를 Arize의 AI engineering agent인 Alyx를 만든 경험으로 설명한다.
발표자인 Sally-Ann DeLucia는 Arize의 product leader이자 Alyx core contributor로, “context engineering이 prompt engineering보다 중요해지는 순간”을 제품 팀의 실패와 수정 과정으로 풀어낸다.
이 글의 핵심 해석은 간단하다.
Alyx의 사례에서 context management는 요약을 잘하는 문제가 아니었다.
무엇을 context에 남기고, 무엇을 memory store에 보내고, 어떤 작업을 sub-agent로 분리하고, 그 전략이 긴 세션에서 실제로 유지되는지 평가하는 아키텍처 문제였다.
무엇을 다루는 영상인가
이 영상은 약 16분짜리 컨퍼런스 발표다.
공식 챕터와 영어 자막이 제공되며, 설명란은 발표자 LinkedIn만 링크하지만, 같은 주제의 Arize 공식 블로그 **“Managing Memory in AI Agents: Beyond the Context Window”**가 핵심 companion source 역할을 한다.
이 블로그는 Alyx 2.0을 만들며 얻은 context management 전략을 더 구체적인 설계 단위로 정리한다.
발표 흐름은 꽤 압축적이다.
처음에는 Alyx가 무엇인지와 context engineering 문제를 소개하고, 중반에는 truncation과 summarization이 왜 실패했는지 설명한다.
후반에는 ID 기반 memory store, long-session evals, sub-agent 분리, 그리고 아직 해결되지 않은 long-term memory와 context quality metric 문제로 넘어간다.
문제 정의: 에이전트가 자기 trace에 잡아먹히는 순간
Alyx는 Arize의 observability platform 위에서 동작한다.
따라서 사용자의 질문만 보는 것이 아니라, AI application의 trace, span, prompt, metadata, tool call, 사용자와 Alyx의 상호작용 기록까지 함께 다룬다.
한 trace만 봐도 데이터가 크고, 사용자가 trace 집합 전체의 패턴을 묻는 순간 context pressure는 빠르게 커진다.
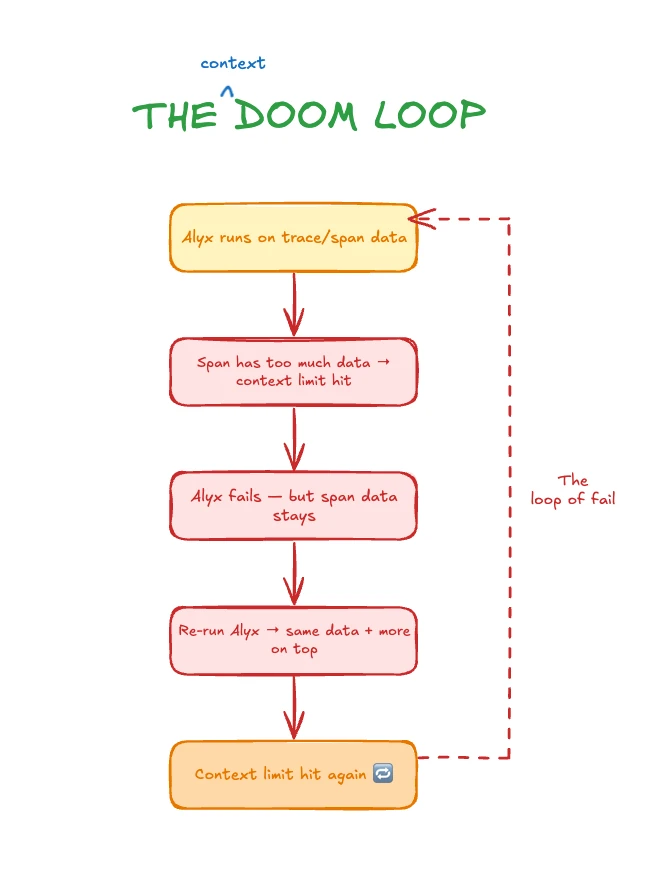
발표에서 가장 좋은 비유는 “vicious loop”다.
Alyx가 trace와 span 데이터를 분석한다.
분석 중 span이 커진다. context limit에 닿아 실패한다.
그런데 그 실패와 데이터도 다시 session에 남는다.
다시 시도하면 더 큰 context가 쌓이고, 다시 실패한다.
즉 시스템이 분석하려는 데이터가 시스템 자체의 context 한계를 악화시키는 구조가 된다.
이 지점에서 발표자가 강조하는 문장이 중요하다. context management는 단순히 “window 안에 맞추는 일”이 아니다.
모델이 무엇을 보게 할지 전략적으로 선택하는 일이다.
그리고 product 관점에서는 이것이 UX 문제다. agent가 필요한 context를 못 보면 답이 나빠지고, 답이 나쁘면 사용자는 제품을 신뢰하지 않는다.
실패한 두 가지 쉬운 답: 자르기와 요약
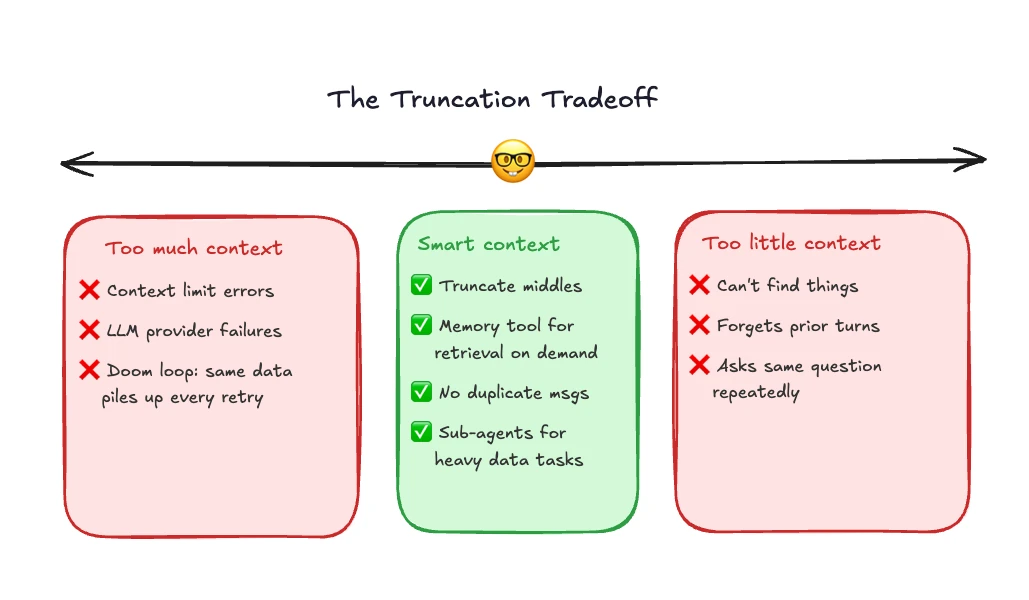
첫 번째로 시도한 것은 naive truncation이었다.
긴 blob의 앞부분 일부만 남기고 나머지를 버리는 방식이다.
단순하고 빠르지만, 발표에 따르면 follow-up 질문에서 바로 문제가 드러났다.
사용자가 “아까 말한 input B를 더 설명해 달라”고 물으면, Alyx는 이전 대화의 참조를 잃고 새 대화처럼 반응했다.
두 번째로 시도한 것은 LLM summarization이었다.
긴 대화나 도구 결과를 모델에게 요약시켜 더 짧은 context로 바꾸자는 접근이다.
직관적으로는 그럴듯하다.
하지만 Arize가 얻은 결론은 꽤 냉정하다.
무엇이 나중에 중요해질지 LLM에게 맡기면, 요약은 매끄러워 보여도 중요한 세부가 빠질 수 있다.
더 나쁜 점은 누락이 즉시 보이지 않고, 몇 턴 뒤 사용자가 특정 내용을 다시 참조할 때 깨진다는 것이다.
이 대목은 실무적으로 꽤 중요하다. summarization은 비용을 줄이고 context를 압축하는 가장 쉬운 기본값처럼 보이지만, agent product에서는 “그럴듯하게 압축된 history”가 오히려 디버깅하기 어려운 실패를 만든다.
요약이 틀렸는지, retrieval이 틀렸는지, tool call이 틀렸는지, 사용자 intent를 놓쳤는지 구분하기 어려워지기 때문이다.
실제로 버틴 해법: head/tail preview와 ID 기반 memory store
Alyx가 실제로 채택한 방향은 구조적이다.
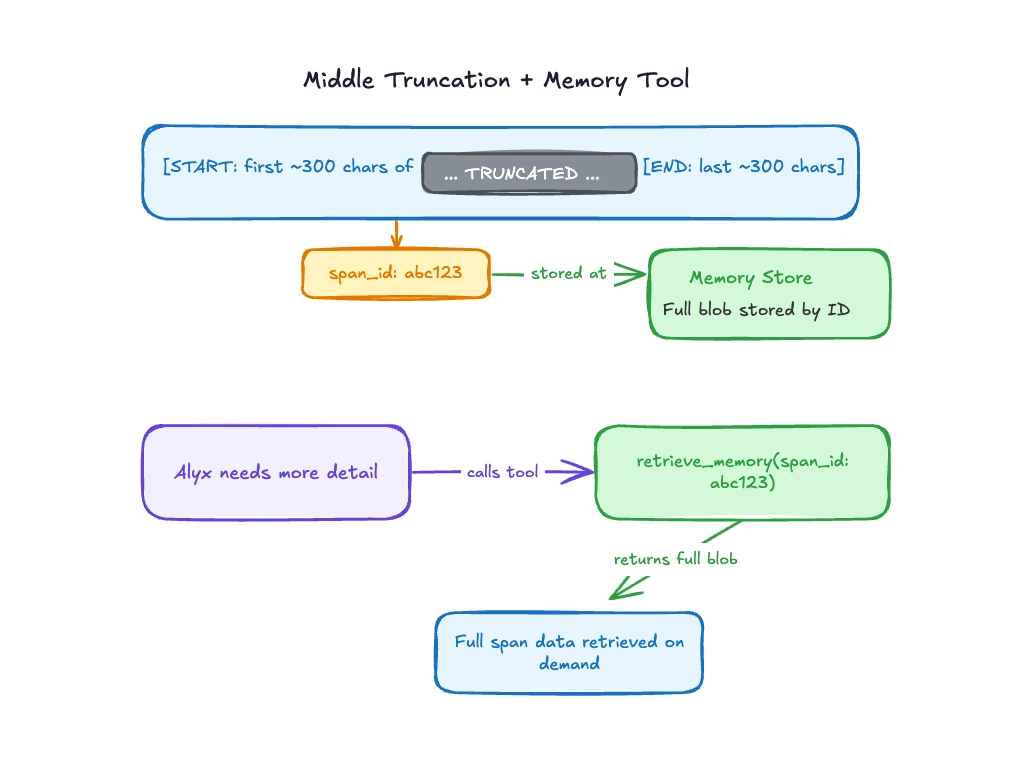
큰 blob 전체를 context에 넣지 않는다.
대신 시작과 끝의 의미 있는 preview를 남기고, 전체 원문은 ID와 함께 memory store에 보관한다. agent는 preview를 보고 이 데이터가 어떤 종류인지 판단하고, 더 깊이 봐야 할 때 ID로 원문 일부를 다시 가져온다.
발표 transcript에서는 이를 “head와 tail은 유지하고 middle은 truncate하되, 필요한 경우 다시 가져올 수 있게 한다”는 식으로 설명한다.
Arize 공식 블로그는 이를 더 구체적으로 middle truncation with IDs라고 부른다.
중요한 차이는 middle을 삭제하는 것이 아니라, context window 밖으로 옮기고 안정적인 handle을 부여한다는 점이다.
이 구조에서 context와 memory는 역할이 다르다.
발표자는 “context decides what the model sees, memory decides what survives”라고 정리한다.
즉 context는 현재 추론에 필요한 작업 공간이고, memory는 지금 당장 보이지 않아도 세션 전체에서 살아남아야 하는 데이터 저장소다.
Arize 블로그는 이 memory layer를 더 명확히 설명한다.
대형 JSON이나 trace/span 결과를 LargeJSON 같은 abstraction으로 저장하고, 모델에게는 preview와 json_id를 준다.
이후 agent는 jq나 grep 같은 단순하고 조합 가능한 querying layer로 필요한 slice만 가져온다.
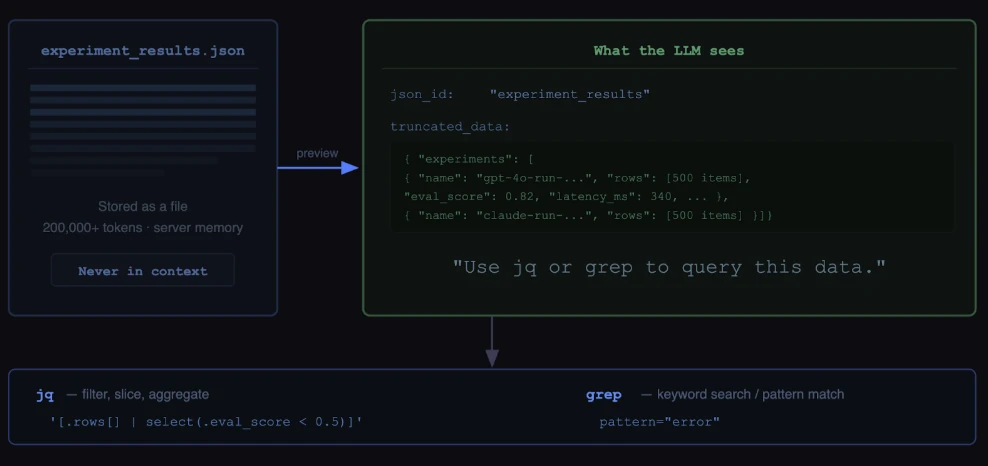
이 설계는 Cursor나 Claude Code 같은 coding agent의 파일 시스템 사용 방식과 닮았다. agent는 모든 파일 내용을 한 번에 들고 있지 않는다.
파일 경로, preview, grep 결과, line range를 오가며 필요한 순간에 필요한 조각을 읽는다.
Alyx는 trace와 span 데이터를 비슷한 방식으로 다루려는 것이다.
긴 세션은 별도 평가 대상이다
context strategy가 짧은 demo에서 잘 보인다고 해서 실제 제품에서도 안정적이라는 뜻은 아니다.
사용자는 대화를 잘 끊지 않는다.
특히 분석 도구 안의 agent라면 페이지를 이동하고, 질문을 바꾸고, 이전 이슈를 다시 참조하면서 한 세션을 길게 끌고 간다.
Alyx 팀이 발견한 문제도 여기 있었다.
짧은 세션에서는 smart truncation이 잘 작동해 보였지만, 긴 conversation에서는 뒤늦게 기억 상실이나 follow-up 실패가 나타났다.
그래서 Arize는 long-running session eval을 만들었다.
예를 들어 10턴의 대화를 preload한 뒤 11번째 턴에서 평가하는 식으로, context management bug가 실제로 드러나는 압력을 테스트한다.

이 부분은 agent eval 설계에서 자주 빠진다.
많은 평가는 single-turn correctness나 task completion만 본다.
하지만 실제 agent product의 실패는 1턴이 아니라 7턴, 11턴, 20턴에서 생긴다.
따라서 context management를 평가하려면 “대화가 누적된 상태에서 여전히 필요한 참조를 유지하는가”를 별도 축으로 봐야 한다.
Sub-agent는 context isolation 장치다
발표 후반의 가장 큰 아키텍처 전환은 sub-agent다.
Arize가 얻은 결론은 “모든 context가 같은 agent에 들어갈 필요는 없다”는 것이다.
예를 들어 Alyx가 Arize 데이터 안에서 search를 수행할 때, 수백 개 span, 여러 query, 중간 reasoning, relevance 판단이 한 context에 계속 쌓이면 main conversation이 무거워진다.
해결책은 heavy data task를 sub-agent로 넘기는 것이다. main agent는 사용자 대화와 light context만 들고 있고, search sub-agent가 별도 context에서 대량 데이터를 읽고, 여러 query를 실행하고, 마지막에 요약된 결과만 main conversation으로 돌려준다. sub-agent가 끝나면 그 context는 main thread에 누적되지 않는다.
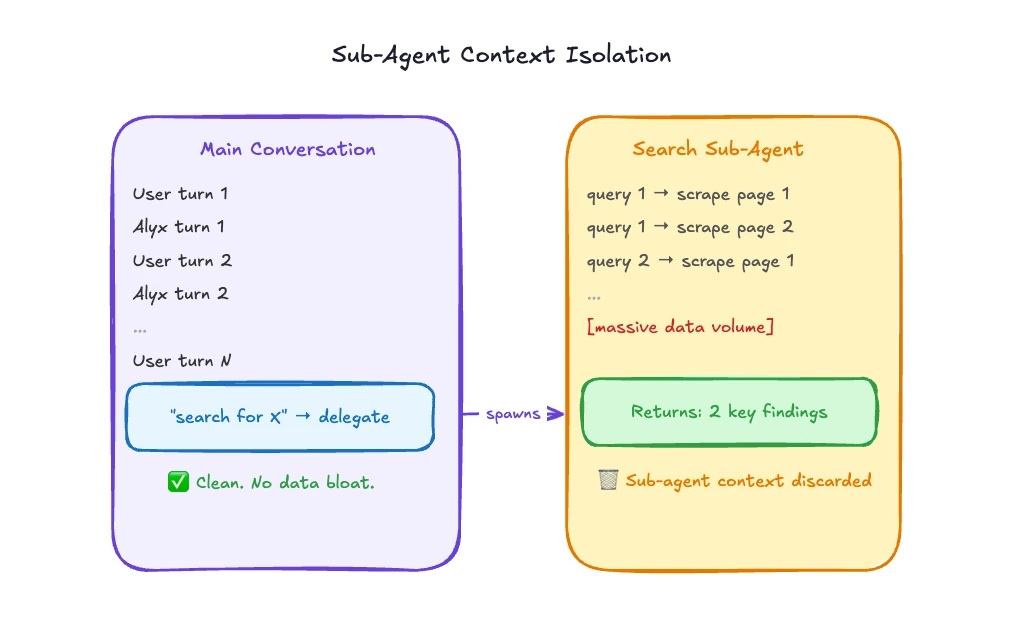
이 접근은 단순한 병렬화가 아니다. context lifecycle을 분리하는 설계다. main thread는 사용자와의 연속성을 보존해야 하므로 오래 살아야 한다.
반면 search, classification, scraping, trace inspection처럼 입력과 출력이 명확한 작업은 별도 context에서 크게 부풀었다가 사라지는 편이 낫다.
이 관점은 최근 agent system 설계와 잘 맞는다.
좋은 agent architecture는 하나의 거대한 context에 모든 것을 넣는 방식이 아니라, long-lived conversation context, retrievable memory, task-local scratchpad, disposable sub-agent context를 분리한다.
Arize의 Alyx 사례는 이를 실제 제품에서 겪은 context pressure로 설명한다는 점에서 설득력이 있다.
타임라인으로 보는 핵심 구간
| 구간 | 영상 흐름 | 관찰 포인트 |
|---|---|---|
| 00:00–01:02 | 발표자 소개와 주제 설정 | Sally-Ann DeLucia가 Alyx core contributor로서 context window와 context management 경험을 공유한다고 소개한다. |
| 01:02–01:29 | Alyx 개요 | Alyx를 AI application 구축을 돕는 AI harness로 설명하고, planning, skills, prompt optimization, data generation, annotation을 언급한다. |
| 01:29–04:06 | context engineering 문제 정의 | prompt engineering보다 context engineering이 agent 실패와 성공을 좌우한다는 관점으로 전환한다. |
| 04:06–05:16 | vicious loop | Alyx가 trace/span data를 분석하다가 context limit에 닿고, 실패 기록이 다시 context를 키우는 loop를 설명한다. |
| 05:16–06:14 | naive truncation 실패 | 앞부분만 남기는 방식은 follow-up에서 이전 참조를 잃게 만들어 reasoning을 깨뜨렸다. |
| 06:14–06:46 | summarization 실패 | LLM에게 무엇이 중요한지 맡긴 요약은 일관성이 낮고, 나중에 필요한 세부를 예측하기 어렵다고 설명한다. |
| 06:46–08:02 | smart truncation + memory | head/tail preview와 memory store를 결합해, 필요한 경우 agent가 원문을 다시 가져올 수 있게 한다. |
| 08:02–09:23 | long-session evals | 실제 사용자는 한 chat을 오래 끌고 가므로, 10턴 preload 후 11번째 턴을 테스트하는 방식으로 bug를 재현 가능하게 만든다. |
| 09:23–11:19 | sub-agent 분리 | search 같은 heavy task를 main conversation 밖으로 옮겨, main agent context를 작게 유지한다. |
| 11:19–13:44 | 남은 문제 | huge prompt/provider limit, real long-term memory, context selection heuristic, context quality metric이 여전히 해결 과제라고 말한다. |
| 13:44–끝 | takeaways와 Q&A | context engineering, memory, evaluation이 핵심이며, Q&A에서는 Claude Code식 cache invalidation 고민과 long-term memory 우선순위를 언급한다. |
영상과 연결 자료에서 확인되는 점
공식 Arize 블로그는 발표 내용을 더 제품 설계 문서에 가깝게 정리한다.
블로그의 TL;DR은 네 가지 전략을 제시한다.
ID가 있는 middle truncation, Alyx가 참조할 수 있는 emulated file system memory, deduplication과 message hygiene, 그리고 high-volume data task를 격리하는 sub-agent다.
반대로 LLM summarization으로 message history를 압축하는 접근은 실제로 잘 버티지 못했다고 말한다.
정리하면 다음과 같다.
| 전략 | 발표/블로그에서의 역할 | 실무적 의미 |
|---|---|---|
| Naive truncation | 초기에 시도했지만 follow-up과 continuity를 깨뜨림 | token limit만 맞추면 reasoning context가 사라질 수 있음 |
| LLM summarization | 직관적이지만 손실이 예측 불가능함 | 요약은 매끄럽지만 나중에 필요한 세부를 누락할 수 있음 |
| Middle truncation + ID | preview는 context에, 전체 데이터는 memory store에 보관 | context pressure를 줄이면서 원문 접근 가능성을 유지 |
jq / grep query layer |
LargeJSON 같은 큰 데이터를 targeted retrieval로 접근 | agent가 “모든 것을 들고 있기”보다 “필요할 때 찾기”로 이동 |
| Long-session evals | 10턴 preload 후 11번째 턴 테스트 | context bug를 실제 사용 압력에서 재현 가능하게 만듦 |
| Sub-agent isolation | search/classification 같은 heavy task를 별도 context로 분리 | main conversation의 장기 기억과 task-local scratchpad를 분리 |
흥미로운 점은 이 접근이 retrieval-augmented generation과도 닮았지만, 일반적인 RAG와는 문제 위치가 조금 다르다는 점이다.
여기서 memory store는 외부 지식베이스라기보다 agent가 방금 만든 중간 산출물과 trace data를 context window 밖에 보존하는 계층이다.
즉 “세상 지식 검색”보다 “agent session 내부의 working memory 관리”에 가깝다.
또 하나 중요한 차이는 evaluation이다.
Arize는 context strategy를 정적 규칙으로 끝내지 않고, long-session eval로 실제 품질을 확인하려 한다.
이는 agent observability 회사다운 접근이기도 하다. agent memory 설계는 추상적인 UX 철학이 아니라, trace와 session replay, regression eval로 관리해야 하는 운영 대상이라는 메시지다.
실무 관점에서의 해석
내가 보기에 이 발표의 가장 큰 가치는 “context window를 크게 만들면 해결된다”는 단순한 기대를 깨는 데 있다. context limit이 늘어나도 agent는 여전히 무엇을 먼저 볼지, 무엇을 나중에 다시 찾을 수 있게 보관할지, 어느 작업을 다른 context로 분리할지 결정해야 한다.
큰 window는 완충재일 뿐, context architecture를 대체하지 않는다.
특히 제품 팀이 가져갈 수 있는 교훈은 세 가지다.
첫째, context management는 backend optimization이 아니라 product reliability 문제다.
사용자가 이전 질문을 참조할 때 agent가 잊으면, 그 실패는 latency나 비용 문제가 아니라 신뢰 문제로 느껴진다.
둘째, memory는 “대화 요약” 하나로 끝나지 않는다.
Alyx의 사례는 memory를 stable ID, preview, targeted retrieval, tool interface의 조합으로 본다.
이는 agent memory를 데이터 구조와 도구 설계 문제로 끌어내린다는 점에서 실용적이다.
셋째, sub-agent는 기능 분해뿐 아니라 context 수명 관리 방식이다.
오래 살아야 하는 main conversation과, 크게 부풀어도 바로 버릴 수 있는 task-local context를 분리하면, agent가 장기 대화와 데이터 집약 작업을 동시에 처리하기 쉬워진다.
물론 아직 미완성인 부분도 분명하다.
발표자는 Alyx의 context selection이 여전히 heuristic이며, 어떤 turn을 보존하고 어떤 turn을 compact할지에 대한 원칙적 budget이나 metric이 충분히 정립된 것은 아니라고 말한다. long-term memory도 아직 진행 중이다.
사용자가 새 chat에서 이전 이슈를 다시 참조하는 경험까지 자연스럽게 만들려면, session memory와 persistent memory를 어떻게 나눌지 더 많은 설계가 필요하다.
그래도 방향성은 명확하다.
에이전트는 prompt 하나로 움직이는 함수가 아니라, context, memory, tool, eval, sub-agent가 결합된 장기 실행 시스템이다.
Arize Alyx의 사례는 그 시스템에서 가장 먼저 망가지는 부분이 어디인지 잘 보여 준다.
발표의 마지막 메시지처럼, agent는 종종 prompt 때문에 실패하는 것이 아니라 context 때문에 실패한다.
참고한 공개 자료
- YouTube: Hierarchical Memory: Context Management in Agents — Sally-Ann Delucia, Arize
- Arize Blog: Managing Memory in AI Agents: Beyond the Context Window
- Arize: AI Agents & Assistants Handbook
- Product Talk: Building Alyx — How Arize AI Dogfooded Its Way to an Agentic Future
- Speaker LinkedIn: Sally-Ann DeLucia