자동 연구 시스템을 평가할 때 가장 위험한 착시는 “프롬프트를 넣었더니 논문 초안이 나왔다”를 “연구 과정이 통제 가능해졌다”로 착각하는 것이다.
실제 연구는 아이디어, 문헌, 실험 설계, 코드 실행, 실패한 로그, 결과 표, 그림, 리뷰, 수정이 계속 얽힌다.
그래서 자동 연구의 병목은 단순히 글을 길게 쓰는 능력이 아니라, 중간 산출물을 보고 개입하고 되돌리고 다시 이어갈 수 있는 운영 구조에 더 가깝다.
Claw AI Lab: An Autonomous Multi-Agent Research Team은 이 지점을 정면으로 잡는다.
논문과 공개 저장소가 제안하는 Claw AI Lab은 단일 에이전트가 뒤에서 긴 prompt-to-paper 파이프라인을 돌리는 시스템이 아니라, 사용자가 한 프롬프트에서 연구팀을 만들고 대시보드에서 진행 상황과 산출물을 확인하며 rollback/resume으로 조향하는 lab-native multi-agent research platform이다.
흥미로운 점은 이 논문이 AutoResearchClaw 계열의 “완전 자동 연구” 서사를 그대로 밀어붙이기보다, 그것을 더 연구실다운 인터페이스와 실행 harness 문제로 바꾼다는 데 있다.
연구 자동화의 다음 단계는 더 긴 hidden chain이 아니라, 실험 실행과 문서화가 실제 artifact에 묶이고 사람이 고레버리지 지점에 개입할 수 있는 inspectable AI lab이라는 주장이다.
무엇을 해결하려는가
기존 자동 연구 에이전트의 문제는 대개 세 가지로 나타난다.
첫째, 사용자는 초반에 연구 주제를 넣고 마지막에 결과물을 받을 뿐 중간 과정이 잘 보이지 않는다.
둘째, 실험이 일부만 실행됐거나 로그와 표가 어긋나도 마지막 문서는 그럴듯하게 완성될 수 있다.
셋째, 실패한 단계로 되돌아가거나 특정 산출물을 검사한 뒤 이어서 실행하는 조작성이 약하다.
Claw AI Lab은 이 문제를 “더 강한 단일 에이전트”가 아니라 “연구실이라는 시스템 추상화”로 푼다.
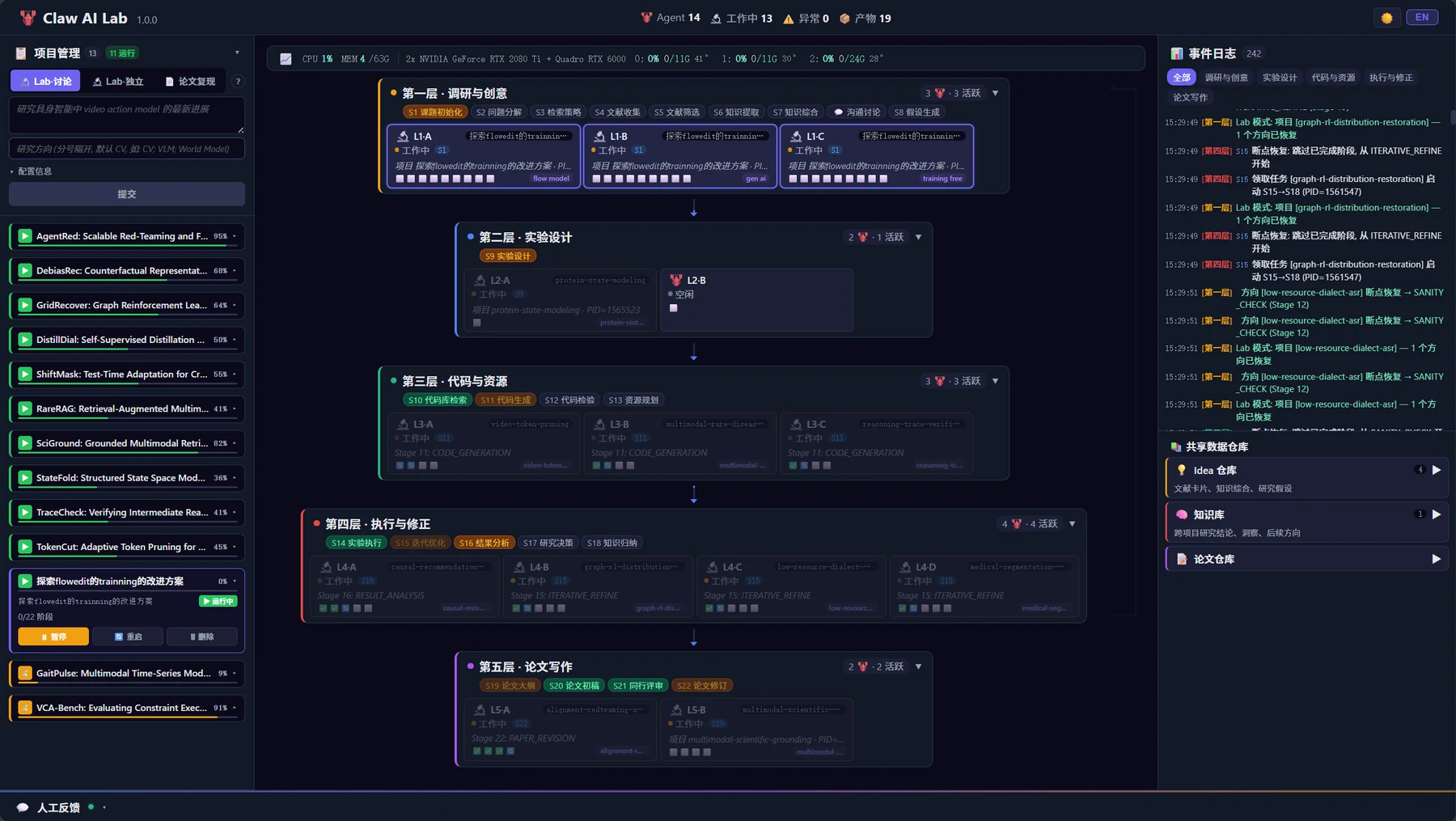
사용자는 하나의 prompt로 연구팀을 만들되, 그 연구팀은 역할이 분리된 여러 에이전트로 구성된다.
플랫폼은 Explore, Discussion, Reproduce 세 가지 모드를 제공하고, 프로젝트 단위의 이벤트 스트림, artifact inspector, rollback/resume, multi-project monitoring을 대시보드에 배치한다.
이 설계에서 중요한 변화는 연구 자동화의 단위가 문서가 아니라 프로젝트 상태가 된다는 점이다.
논문 하나를 생성하는 것이 아니라, 아이디어 후보, 계획, 코드, 실험 로그, 결과 표, figure, draft가 연결된 상태 공간을 만들고, 사용자가 그 상태를 보면서 개입할 수 있게 한다.
연구 자동화가 실제 팀 workflow에 들어오려면 바로 이 조작성과 추적성이 필요하다.
공개 홈페이지와 README도 같은 방향을 강조한다.
Claw AI Lab은 “One dashboard.
An entire research team.”
을 내세우며, dashboard에서 프로젝트를 시작하고 agent를 모니터링하며 모든 artifact를 검사할 수 있다고 설명한다.
즉 이 프로젝트의 핵심 가치는 “AI가 알아서 논문을 쓴다”가 아니라, AI 연구팀을 운영하는 콘솔을 만든다는 데 있다.
핵심 아이디어 / 구조 / 동작 방식
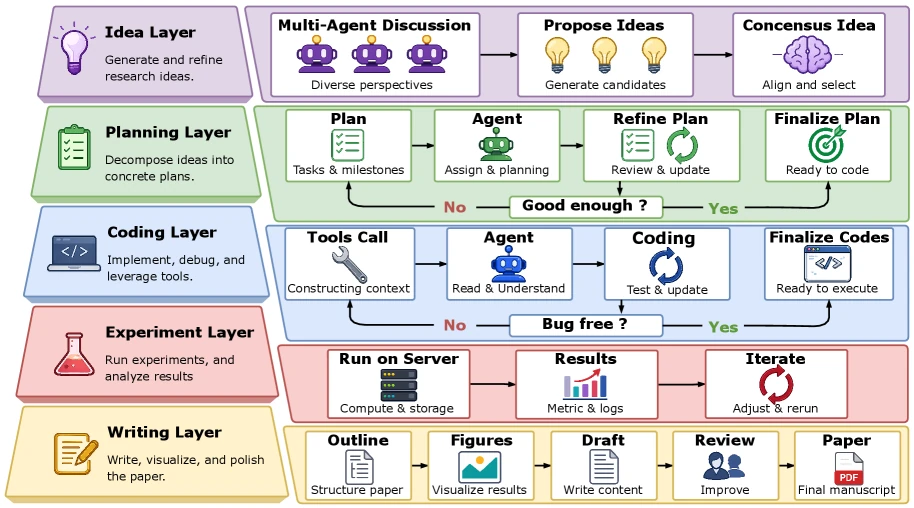
논문은 Claw AI Lab의 연구 과정을 다섯 레이어로 나눈다.
이 구조는 단순한 순서도가 아니라, 각 단계에서 다른 에이전트 역할과 검증 루프를 붙이기 위한 분해다.
| 레이어 | 논문에서의 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| Idea | 여러 에이전트가 후보 아이디어를 제안·토론하고 consensus idea를 만든다 | 단일 LLM의 자기확증 대신 관점 분리를 통해 연구 방향을 만든다 |
| Planning | 선택된 아이디어를 task, dependency, milestone로 나누고 “Good enough?” 루프로 수정한다 | 좋은 아이디어를 바로 코드로 던지지 않고 실행 가능한 계획으로 압축한다 |
| Coding | Claw-Code Harness가 로컬 코드베이스, 데이터셋, 체크포인트를 읽고 runnable code를 작성·수정한다 | 연구 자동화의 병목을 글쓰기에서 실제 코드 실행으로 옮긴다 |
| Experiment | 서버에서 실험을 실행하고 metrics/logs를 모아 반복 개선한다 | 실패와 측정 결과를 다음 계획·아이디어 단계로 되돌리는 feedback loop를 만든다 |
| Writing | outline, figure, draft, review를 거쳐 paper를 만든다 | 마지막 문서가 앞선 실행 artifact와 끊어지지 않도록 한다 |
여기서 가장 중요한 구성요소는 Claw-Code Harness다.
논문은 이 harness가 로컬 코드베이스, 데이터셋, 체크포인트를 읽고, bash/read/write/edit/search 계열 도구를 통해 실험 파일을 만들고 실행한다고 설명한다.
더 구체적으로는 sandboxed workspace, read-only Python controller, time-budget enforcement, metric reporting, result finalization, NaN/Inf detection, smoke test, anti-fabrication check를 결합한다.
이 말은 꽤 중요하다.
자동 연구 시스템의 실패는 보통 “모델이 코드를 못 썼다”보다 더 미묘하다.
코드가 돌아가도 측정값이 NaN일 수 있고, placeholder implementation이 실험인 척할 수 있으며, 로그에는 없는 숫자가 표에 들어갈 수 있다.
Claw-Code Harness는 이 지점에서 실행과 보고 사이의 접점을 강화하려는 장치다.
즉 연구 에이전트를 paper generator가 아니라 실행 artifact를 관리하는 운영체제로 만들려는 시도다.
또 하나의 차별점은 세 가지 연구 모드다.
Explore는 열린 연구 탐색, Discussion은 여러 에이전트의 토론과 합의, Reproduce는 기존 연구의 재현과 분석에 맞춰진다.
같은 “AI 연구 자동화”라도 새 아이디어 탐색과 논문 재현은 실패 양상이 다르기 때문에, 모드별로 workflow를 분리한 점은 실용적이다.
공개된 근거에서 확인되는 점
arXiv 페이지 기준 이 논문은 2026년 5월 21일 제출된 cs.AI v1 논문이며, 프로젝트 페이지와 코드는 Claw-AI-Lab/Claw-AI-Lab 저장소로 연결된다.
공식 README는 Preview v1.1.0이 2026년 4월 2일 Claw-Code Harness 기반으로 공개됐다고 설명한다.
조회 시점의 GitHub API 기준 저장소 기본 브랜치는 preview-v1.1.0, stars는 약 1.4k, forks는 66개이며, 별도 release나 tag는 아직 노출되지 않는다.
README와 LICENSE는 MIT 라이선스, Python 3.11+, Node.js 18+ 요구사항을 표시한다.
논문 실험은 AutoResearchClaw를 baseline으로 두고 네 개 주제를 비교한다.
Topics 1~3은 연구 주제, Topic 4는 PhyCustom on FLUX 재현 주제다.
생성 결과는 ChatGPT 5.4 Thinking과 Gemini 3.1 Pro라는 두 LLM evaluator가 기술 깊이·재현성, 구조와 흐름, novelty와 contribution, 명확성, 논리성, citation/evidence support의 여섯 차원으로 평가했다고 설명한다.
| 평가 항목 | AutoResearchClaw | Claw AI Lab | 차이 |
|---|---|---|---|
| Paper 1 평균 | 65.0 | 81.5 | +16.5 |
| Paper 2 평균 | 56.5 | 72.0 | +15.5 |
| Paper 3 평균 | 67.5 | 84.0 | +16.5 |
| Reproduction Topic 평균 | 73.0 | 78.0 | +5.0 |
표만 보면 Claw AI Lab은 세 개 연구 논문 과제에서 +15.5~+16.5점, 재현 과제에서 +5.0점을 얻는다.
논문은 이 차이를 Claw-Code Harness와 대시보드 중심 artifact workflow가 실험 완결성, 결과 무결성, 논문 표현 품질을 개선한 결과로 해석한다.
다만 이 결과는 강하게 읽되 과장해서 읽으면 안 된다.
평가는 내부 case study와 LLM judge에 기반하고, 사람이 장기간 실제 연구팀으로 사용했을 때의 생산성·재현성·오류율을 보여 주는 외부 benchmark는 아니다.
또한 abstract는 “five AI research case studies”라고 말하지만, 공개 표는 세 개 연구 논문과 한 개 재현 주제를 중심으로 제시된다.
따라서 이 논문의 실험은 “제품이 이미 검증된 연구실 인프라”라는 증거라기보다, 어떤 workflow 요소가 자동 연구 품질을 높일 수 있는지 보여 주는 초기 내부 평가로 보는 편이 안전하다.
공개 저장소도 preview 성격이 강하다.
README에는 설치, ./start.sh, API/model 설정, dashboard, showcase가 비교적 풍부하게 정리되어 있지만, 공식 release/tag는 아직 없다.
설정 예시는 API key, main model, coding model, image model, sandbox python path, dataset/checkpoint/codebase 경로를 직접 지정하도록 요구한다.
즉 “버튼 하나로 누구나 안정적으로 연구실을 띄운다”기보다는, 로컬 실행 환경과 모델 API, 실험 리소스를 잘 연결해야 하는 초기 research platform에 가깝다.
실무 관점에서의 해석
내가 보기에 Claw AI Lab의 핵심 가치는 “자동 연구 성능이 몇 점 올랐다”보다, 자동 연구 제품의 인터페이스를 바꾼다는 데 있다.
지금까지 많은 AI scientist 시스템은 긴 파이프라인을 숨긴 뒤 최종 paper draft를 보여 주는 쪽에 가까웠다.
하지만 실제 조직이 원하는 것은 최종 문서만이 아니다.
어떤 아이디어가 왜 선택됐는지, 어떤 실험이 실패했는지, 결과 표가 어느 로그에서 왔는지, 지금 어느 단계로 되돌아가야 하는지를 알아야 한다.
그런 의미에서 Claw AI Lab은 연구 에이전트의 좋은 평가 기준을 다시 제시한다.
좋은 시스템은 더 많은 agent를 붙인 시스템이 아니라, agent의 중간 판단과 artifact를 사람이 조작 가능한 상태로 만드는 시스템이다.
대시보드, rollback/resume, artifact inspector, multi-project monitoring은 겉보기 UI 기능처럼 보이지만, 실제로는 자동 연구의 책임성과 재현성에 직접 연결된다.
Claw-Code Harness도 같은 맥락이다.
연구 자동화에서 코딩 에이전트가 중요한 이유는 코드를 생성해서가 아니라, 실험 실행의 provenance를 남길 수 있기 때문이다.
어떤 dataset, checkpoint, codebase, metric, log, figure가 어떤 claim에 연결되는지 관리하지 못하면, 마지막 paper는 쉽게 story generation으로 후퇴한다.
Claw AI Lab은 이 문제를 harness와 writing layer 사이의 연결로 풀려고 한다.
반대로 한계도 분명하다.
LLM judge 기반 내부 평가는 실제 peer review나 장기 재현성 검증을 대체하지 않는다.
또한 preview 저장소가 보여 주는 실행 표면은 아직 안정된 제품 release라기보다 빠르게 움직이는 연구용 bundle에 가깝다.
사용자가 API key, 모델, sandbox Python, 데이터·체크포인트 경로를 설정해야 하고, 실험 품질은 결국 연결된 모델과 로컬 리소스, 도메인별 검증식에 크게 의존한다.
그래도 방향성은 꽤 중요하다.
자동 연구의 미래가 있다면, 그것은 “논문 생성 버튼” 하나보다 팀 구성, artifact 추적, 실행 harness, human gate, rollback 가능한 대시보드가 결합된 연구 운영 환경에 가까울 가능성이 높다.
Claw AI Lab은 그 전환을 꽤 노골적으로 보여 주는 사례다.
자동 연구를 더 자율적으로 만들기 전에, 먼저 더 잘 보이고 더 잘 멈출 수 있고 더 정확히 되돌릴 수 있게 만들어야 한다는 점에서 이 논문은 읽을 가치가 있다.