자율주행 시뮬레이션에서 가장 어려운 지점은 “예쁜 도로 영상을 만든다”가 아니다.
실제 병목은 정책이 행동을 내면 그 행동이 다음 세계 상태를 바꾸고, 바뀐 세계가 다시 정책의 다음 결정을 바꾸는 **폐루프(closed-loop)**다.
기록된 주행 로그를 재생하거나, 특정 구간을 neural reconstruction으로 복원하는 방식은 photorealism에는 강하지만, 차량이 원래 로그와 다른 방향으로 움직이거나 폭설·강풍·예상 밖 보행자 행동 같은 long-tail 조건을 만들 때 한계가 드러난다.
NVIDIA가 공개한 OmniDreams는 이 병목을 generative world model로 푼다.
공식 페이지와 arXiv 기술보고서 기준 OmniDreams는 NVIDIA Cosmos diffusion model에서 mid-/post-training된 action-conditioned world model이며, 21k hours 규모의 driving scenarios로 학습되어 과거 프레임, 현재 simulator state, 즉시 driving action을 조건으로 다음 camera observation을 생성한다.
핵심은 긴 동영상을 한 번에 뽑는 오프라인 비디오 모델이 아니라, 정책 또는 사람이 매 step마다 조향을 바꿀 수 있는 실시간 반응형 시뮬레이터라는 점이다.
공개 bundle도 단일 데모 페이지보다 넓다.
공식 페이지는 technical report, Hugging Face model, data sample collection, nv-tlabs/omni-dreams 코드, FlashDreams runtime을 함께 연결한다.
즉 이 릴리스는 “월드 모델 논문”인 동시에, 자율주행 정책 평가·후학습·실시간 inference stack을 한 번에 보여 주는 시스템 릴리스에 가깝다.

무엇을 해결하려는가
기존 자율주행 시뮬레이션은 크게 두 축으로 볼 수 있다.
하나는 물리·규칙 기반 simulator이고, 다른 하나는 captured scene을 neural reconstruction으로 복원하는 방식이다.
후자는 실제 주행 데이터에 grounded되어 있어 원래 corridor 주변에서는 현실감이 높다.
하지만 기록된 차량이 직진한 교차로에서 오른쪽으로 꺾어 보거나, 원래 없던 폭설·강풍·매트리스를 싣고 달리는 차량·불규칙한 보행자 움직임을 넣는 순간, reconstruction envelope 밖으로 밀려난다.
OmniDreams의 질문은 여기서 시작한다.
정책을 안전하게 검증하려면 이미 본 장면의 재생만으로는 부족하다.
정책이 낯선 행동을 했을 때 세계가 어떻게 반응하는지, long-tail 상황에서 정책 순위가 어떻게 바뀌는지, 사람이 직접 어려운 상황을 몰아 보며 qualitative debugging을 할 수 있는지가 중요하다.
따라서 simulator는 recorded reality를 보존하면서도, 그 바깥을 생성적으로 확장해야 한다.
이 관점에서 OmniDreams는 “비디오 생성 모델”이라기보다 정책 평가용 sensor generator다.
출력은 긴 precomputed clip이 아니라, 폐루프 runtime과 policy가 다음 결정을 내릴 수 있도록 돌려받는 next-step RGB camera frames다.
정책 행동이 바뀌면 simulator state가 바뀌고, 그 상태가 곧 다음 생성 조건이 된다.
핵심 아이디어 / 구조 / 동작 방식
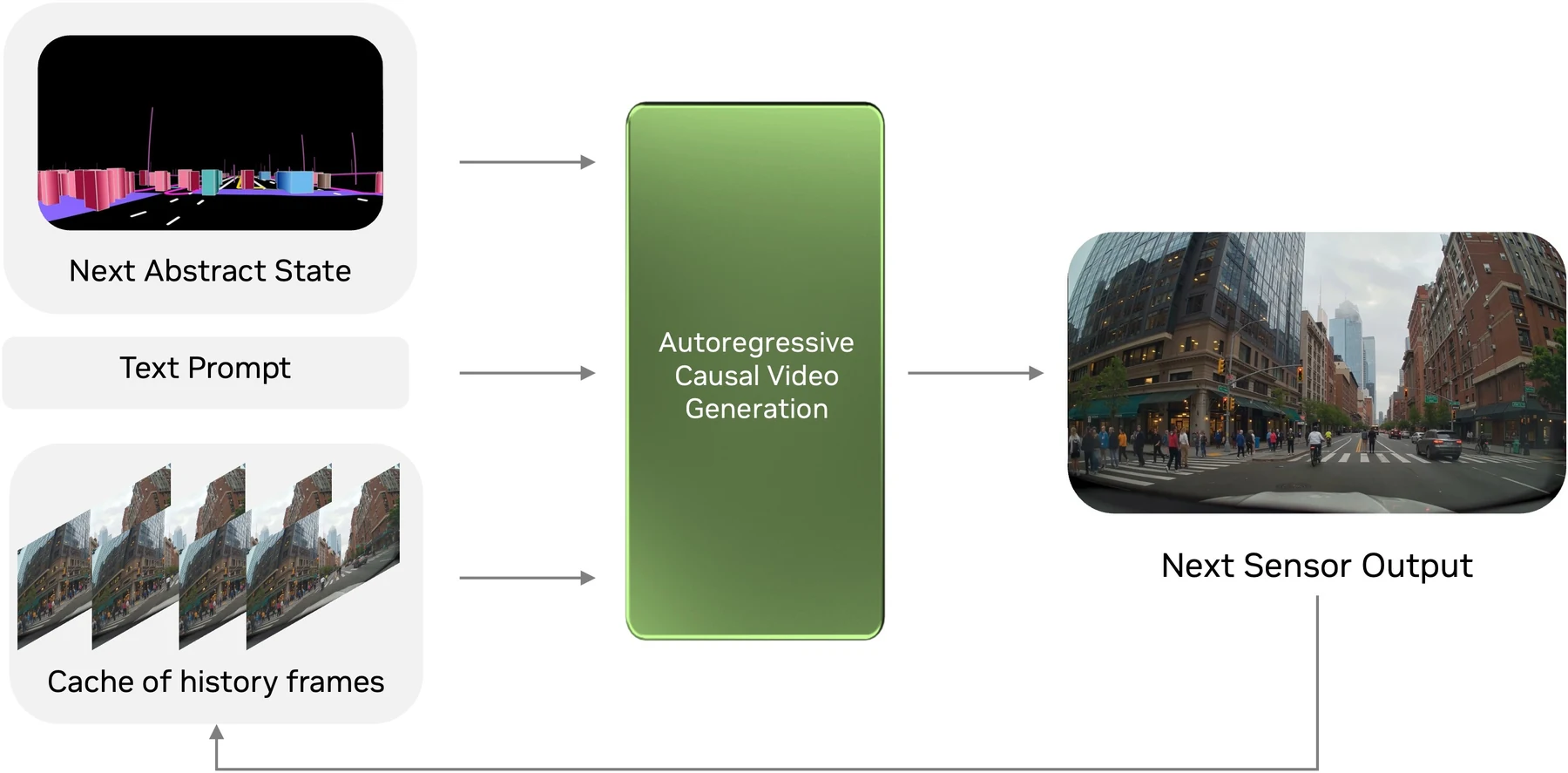
OmniDreams의 폐루프는 세 구성요소로 읽는 편이 가장 쉽다.
첫째, driver 역할을 하는 Alpamayo 1 정책 또는 human driver가 action이나 trajectory를 낸다.
둘째, AlpaSim이 ego vehicle state와 scenario context를 갱신한다.
셋째, OmniDreams가 갱신된 abstract state와 최근 visual history를 받아 다음 sensor frames를 만든다.
공식 설명에 따르면 이 frame은 gRPC API로 runtime에 반환되고, 다시 policy의 관찰이 된다.
모델 입력은 세 축이다.
World scenario는 lane lines와 bounding boxes로 표현되는 다음 simulator state다.
Text prompt는 weather, lighting, time of day 같은 counterfactual variation을 준다.
Memory cache는 이전 frame history를 보존해 rollout이 길어져도 appearance와 temporal consistency가 무너지지 않도록 돕는다.
여기서 중요한 점은 text prompt만으로 장면을 지시하는 것이 아니라, simulator state와 action이 함께 conditioning signal이 된다는 점이다.
생성 방식은 autoregressive step-wise generation이다.
일반적인 offline video generation은 일정 길이의 clip을 한 번에 만들 수 있지만, 폐루프 주행에서는 정책이 매 순간 다른 action을 낼 수 있다.
그래서 OmniDreams는 작은 frame chunk를 만들고, 그 chunk와 cache를 다음 step의 context로 되먹임한다.
공식 페이지는 이를 causal KV-cache 기반 generation으로 설명하며, bidirectional image-to-video denoising과 대비한다.
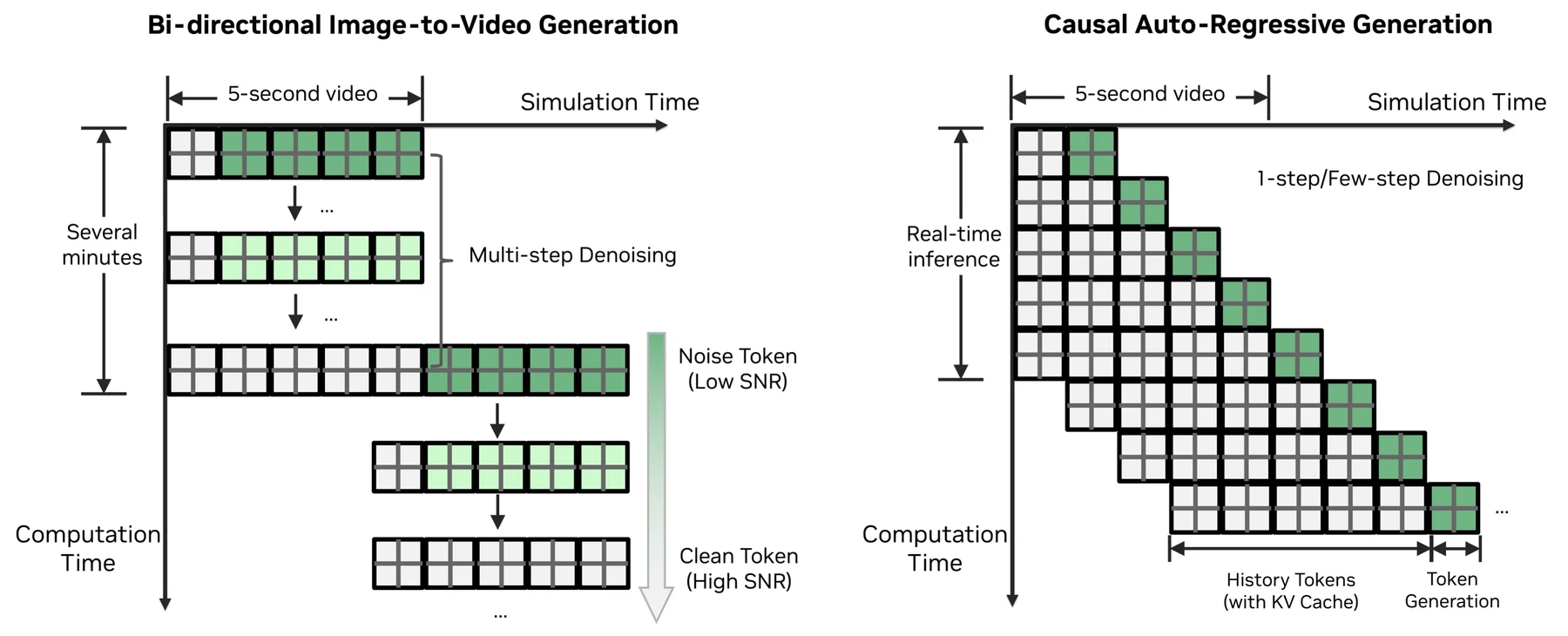
성능 목표도 이 구조에 맞춰져 있다.
공식 페이지는 world scenario renderer를 frame당 1ms 미만으로 최적화했고, few-step denoising, CUDA Graphs, multi-GPU context parallelism을 함께 적용했다고 설명한다.
그 결과 OmniDreams는 16개의 NVIDIA GB300 NVL72 GPU에서 704×1280 해상도 4-camera view를 camera당 105 FPS로 생성한다고 제시한다.
이 수치는 “월드 모델도 실시간 closed-loop control loop 안에 들어갈 수 있는가”라는 질문에 대한 핵심 evidence다.
공개된 근거에서 확인되는 점
기술보고서와 공식 페이지에서 가장 강한 정량 근거는 두 종류다.
하나는 생성 품질과 conditioning fidelity이고, 다른 하나는 simulator로 정책을 비교했을 때 ranking을 유지하는가다.
먼저 생성 품질 비교를 보면, 공식 페이지는 RDS-HQ-1M evaluation split의 1,000 held-out clips에서 single-view model의 세 training stage를 비교한다.
최종 distilled real-time causal model(Self Forcing)은 FVD 24.8로 bidirectional offline model의 26.8보다 낮고, BEVFormer 기반 3D vehicle detection과 LATR lane metric에서도 대부분 가장 좋은 값을 보인다.
즉 “실시간화 때문에 품질이 크게 희생됐다”기보다는, distillation과 causal generation을 거치며 현실감과 conditioning fidelity를 같이 끌어올린 결과로 제시된다.
| 항목 | Bidirectional offline | Causal Diffusion Forcing | Distilled real-time Self Forcing | 해석 |
|---|---|---|---|---|
| FVD ↓ | 26.8 | 31.7 | 24.8 | 최종 실시간 causal model이 가장 낮은 FVD를 보인다 |
| Temporal Sampson ↓ | 1.83 | 1.87 | 1.90 | temporal consistency는 offline이 약간 우세하지만 차이는 작다 |
| BEVFormer LET-AP ↑ | 0.378 | 0.221 | 0.400 | 생성 frame이 3D detection signal을 더 잘 보존한다는 근거 |
| LATR F1 ↑ | 0.823 | 0.775 | 0.828 | lane-line 관련 conditioning fidelity도 유지된다 |
| LATR category accuracy ↑ | 0.957 | 0.941 | 0.961 | 차선 category signal 보존이 개선된다 |
두 번째 결과는 더 흥미롭다.
NVIDIA는 single-view OmniDreams checkpoint 약 2B parameters를 end-to-end policy로 fine-tuning한 World-Action Model(WAM) 결과도 제시한다.
같은 AlpaSim closed-loop stack과 Alpamayo 1.5 evaluation protocol에서, 574-scene subset 20초 rollout 기준 WAM은 Alpamayo 1.5 대비 collision rate를 6.9%에서 4.2%로 낮춘다고 보고한다.
특히 이 비교에서 WAM은 약 2B parameters이고 Alpamayo 1.5는 약 10B로 설명된다.
저자들의 메시지는 “world model backbone이 rendering뿐 아니라 policy architecture의 backbone으로도 쓸 수 있다”는 것이다.
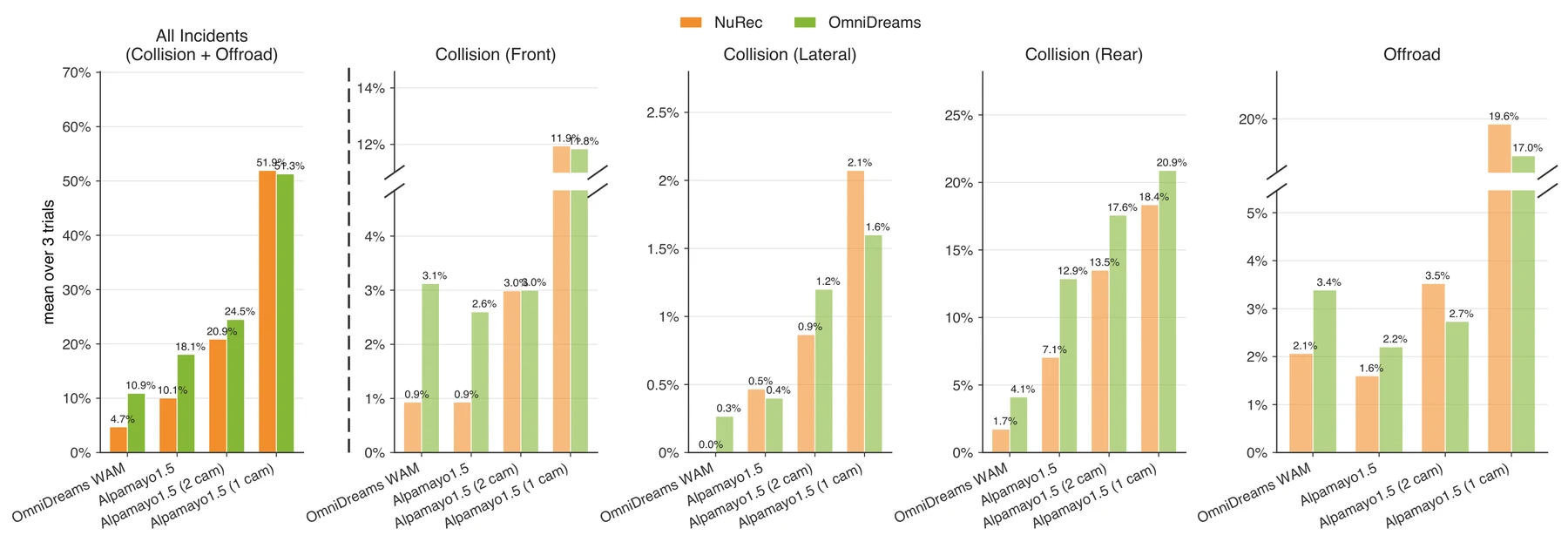
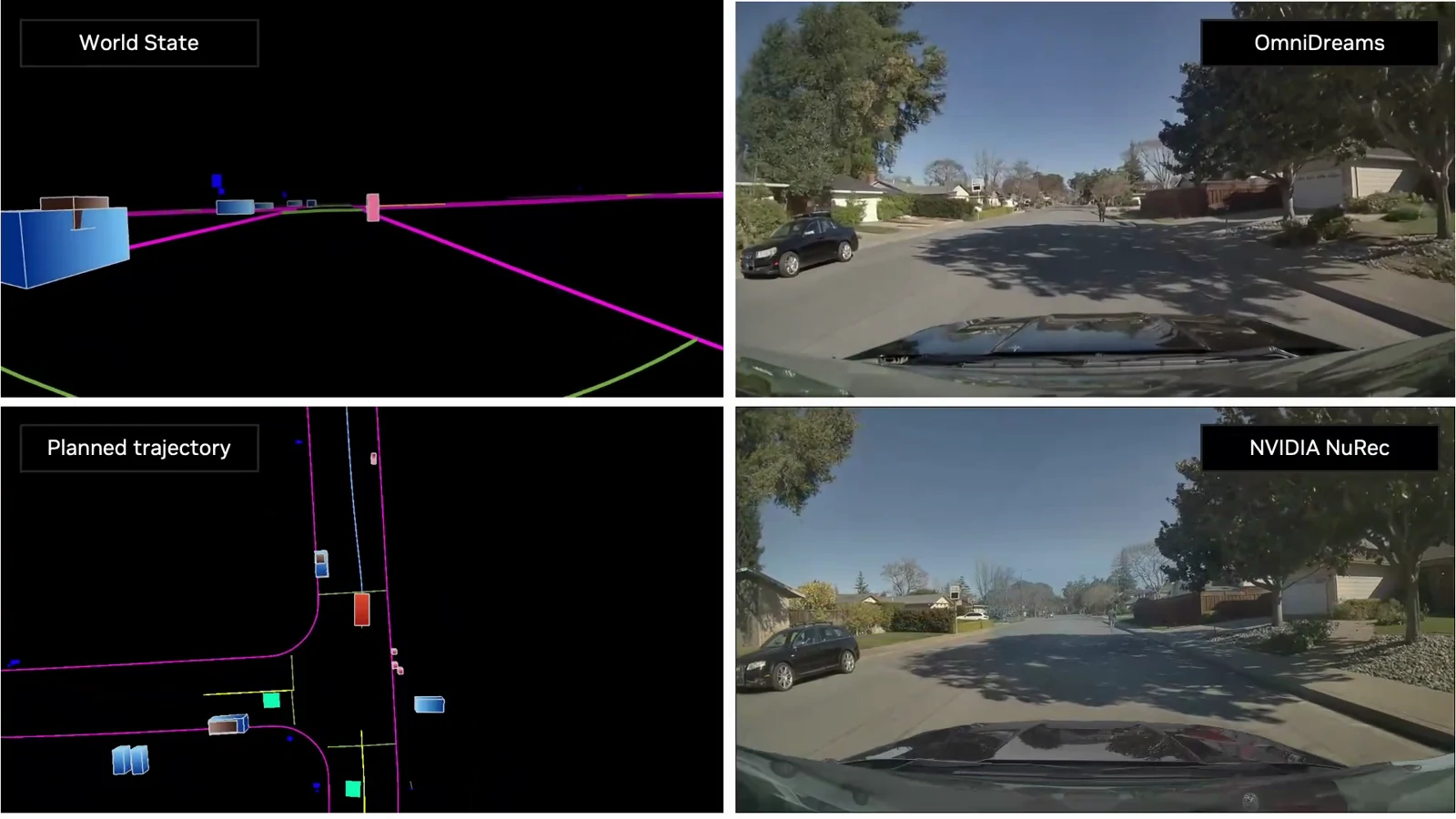
정책 평가 proxy로서의 검증도 있다.
공식 페이지는 NuRec과 OmniDreams만 sensor simulator로 바꾸고, orchestrator·traffic/physics·scene initial state를 고정한 뒤 501-scene subset에서 네 policy class를 비교했다고 설명한다.
결과의 핵심은 OmniDreams가 NuRec과 같은 policy ranking을 보존한다는 점이다.
NuRec은 원래 captured trajectory 근처에서는 강한 reconstruction baseline이므로, 이 ranking preservation은 OmniDreams가 policy comparison용 simulator로 의미가 있다는 근거가 된다.
공개 패키징은 적극적이지만, 실무적으로는 제약도 같이 봐야 한다. nv-tlabs/omni-dreams GitHub 저장소는 OmniDreams post-training sample과 release tree를 담당하고, interactive inference와 live driving demo는 companion project인 NVIDIA/flashdreams 쪽으로 옮겨져 있다.
FlashDreams 문서는 OmniDreams를 HDMap-conditioned driving world model로 설명하고, batch inference와 interactive-drive demo, MJPEG browser streaming, gRPC/WebRTC server 같은 runtime 표면을 제공한다.
Hugging Face 쪽도 단순 모델 카드 하나가 아니다.
공식 collection은 model checkpoint, sample dataset, scene dataset을 함께 묶는다.
다만 모델 저장소는 조건 수락과 contact information 공유를 요구하는 gated access로 표시되며, 모델 카드의 intended use도 simulation purpose이지 vehicle deployment가 아니라고 못박는다.
라이선스는 NVIDIA Open Model License Agreement를 따른다.
따라서 “공개됐다”는 말은 “아무 제약 없이 로컬 제품에 바로 넣는 오픈소스 모델”이 아니라, 연구·시뮬레이션 목적의 조건부 공개 release로 읽어야 한다.
| 공개 표면 | 확인되는 내용 | 실무적 해석 |
|---|---|---|
| NVIDIA 공식 페이지 | 폐루프 workflow, input conditioning, qualitative demos, FVD/perception metrics, policy ranking figure | 논문의 주장을 가장 압축적으로 보여 주는 launch surface |
| arXiv 2606.03159 | 2026-06-02 제출, CC BY 4.0, 21k hours driving scenarios, Cosmos 기반 mid-/post-training | architecture·training·evaluation claim의 중심 근거 |
nv-tlabs/omni-dreams |
post-training sample, release tree, model/data/code links | full product runtime보다는 OmniDreams-specific training/release surface |
NVIDIA/flashdreams |
interactive autoregressive video/world model serving library, OmniDreams interactive-drive demo |
실시간 inference와 browser-driving 경험은 FlashDreams를 통해 보는 편이 맞다 |
| Hugging Face collection/model | checkpoints, sample data, scene data, gated model access, simulation-only intended use | 재현·실험은 가능하되 access terms와 hardware/runtime 조건을 확인해야 한다 |
실무 관점에서의 해석
OmniDreams의 가장 중요한 의미는 자율주행 시뮬레이션을 scene reconstruction 문제에서 policy-interactive world generation 문제로 이동시킨다는 데 있다.
NuRec 같은 reconstruction 계열은 captured reality를 보존하는 데 강하다.
반면 OmniDreams는 policy action과 simulator state를 조건으로 삼기 때문에, 기록된 trajectory 바깥에서 long-tail variation을 만들고 policy가 그 variation 속에서 어떻게 행동하는지 볼 수 있다.
자율주행 개발팀 입장에서는 단순 데이터 증강보다 훨씬 운영적인 질문이다.
“이 정책이 눈보라 속에서 무엇을 볼 것인가”가 아니라, “그 장면에서 정책 행동이 다음 세계를 어떻게 바꾸고, 그 결과 사고 위험이 어떻게 누적되는가”를 묻기 때문이다.
두 번째 의미는 world model과 policy model의 경계가 흐려진다는 점이다.
OmniDreams에서 fine-tuned된 WAM 결과는 아직 preliminary research result로 읽어야 하지만, 방향은 중요하다.
영상 생성을 위해 학습한 backbone이 driving scene dynamics와 action consequence를 충분히 내재화한다면, 그 representation은 rendering뿐 아니라 trajectory policy에도 쓰일 수 있다.
이는 VLA가 모든 것을 language-action reasoning으로 푸는 방향과 달리, 월드 생성 backbone 자체를 action model의 기반으로 쓰는 경로를 보여 준다.
세 번째는 runtime이다.
월드 모델이 폐루프 simulator가 되려면 frame quality만으로는 부족하다. gRPC API, KV cache, few-step denoising, CUDA Graphs, context parallelism, FlashDreams serving stack 같은 시스템 요소가 함께 맞물려야 한다.
공식 자료의 4-camera 105 FPS on 16 GB300 NVL72 수치는 연구실 데모용으로도 매우 큰 hardware footprint를 전제하지만, 동시에 이 방향의 병목이 모델 architecture뿐 아니라 serving system이라는 점을 명확히 보여 준다.
한계도 분명하다.
첫째, 21k hours driving scenarios와 official evaluation은 강한 내부 근거지만, 실제 도시·국가·센서 구성 전반에서 정책 안전성을 보장하는 것은 아니다.
둘째, generated sensor가 photorealistic하다고 해서 물리·사회적 상호작용을 완전히 정확히 예측한다는 뜻은 아니다.
셋째, gated model access, NVIDIA Open Model License, high-end GPU runtime, sample dataset 조건은 실무 도입의 현실적 경계다.
넷째, vehicle deployment용 모델이 아니라 simulation purpose라고 명시되어 있으므로, 안전-critical stack에서는 evaluation proxy로만 취급해야 한다.
그럼에도 OmniDreams는 2026년 world model 릴리스 중 꽤 중요한 기준점을 만든다.
지금까지 많은 월드 모델은 “긴 비디오를 얼마나 잘 그리는가”나 “카메라 trajectory를 얼마나 잘 따라가는가”에 초점을 맞췄다.
OmniDreams는 거기에 정책 행동, simulator state, 실시간 serving, policy ranking preservation을 붙인다.
즉 예쁜 비디오 생성 모델이 아니라, 정책이 안에서 운전할 수 있는 생성형 세계를 만들려는 시도다.
자율주행과 robotics에서 generative simulation을 말하려면, 앞으로는 OmniDreams처럼 model quality, control conditioning, runtime latency, release packaging, safety caveat를 한꺼번에 봐야 할 가능성이 크다.