Microsoft AI가 Build 2026에서 공개한 MAI 모델 패밀리는 표면적으로는 5개 분야, 7종 모델의 동시 출시다.
이미지 생성·편집, 음성 합성, 전사, 추론, 코딩 모델이 한 번에 발표됐고, Microsoft Foundry, GitHub Copilot, VS Code, PowerPoint, OneDrive, Teams 같은 제품 표면과 함께 제시됐다.
하지만 이번 발표의 핵심은 “모델을 몇 개 더 냈다”가 아니다.
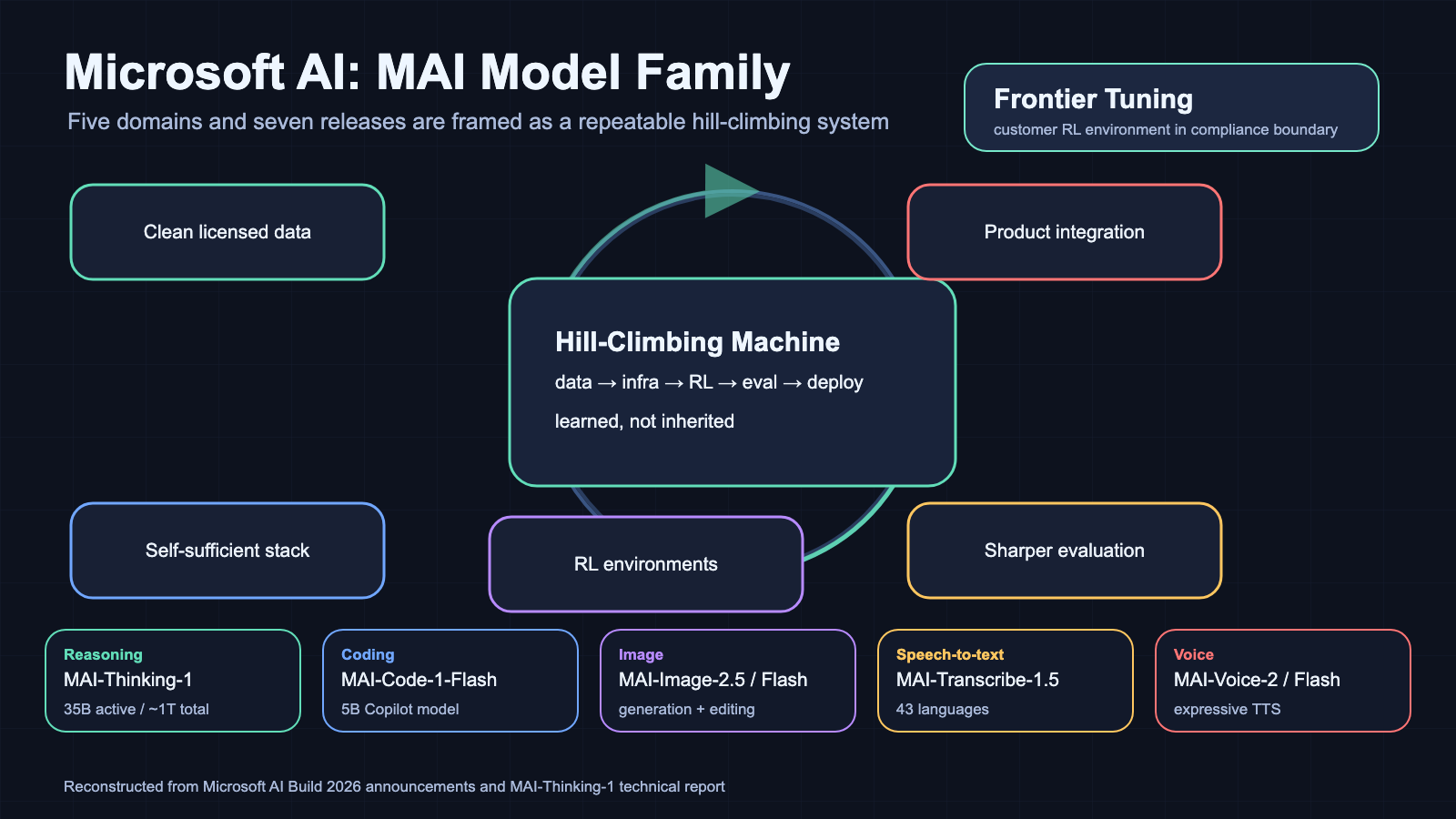
Microsoft AI는 이를 Hill-Climbing Machine, 즉 더 많은 연산, 더 좋은 데이터, 더 날카로운 평가를 반복 투입할수록 능력이 꾸준히 올라가는 모델 개발 시스템으로 설명한다.
특히 MAI-Thinking-1은 제3자 모델 증류 없이, 깨끗하고 상업적으로 라이선스된 데이터로 바닥부터 학습했다고 강조된다.
내가 보기에 이번 릴리스의 의미는 두 겹이다.
첫째, Microsoft가 Phi 같은 소형 모델 실험을 넘어 자체 frontier급 모델·데이터·학습 인프라·가속기·평가 체계를 하나의 수직 통합 스택으로 만들겠다고 선언했다.
둘째, 모델 자체보다 조직별 워크플로우에 맞게 계속 튜닝되는 모델 운영 체계를 전면에 내세웠다.
이 점에서 MAI 발표는 단순한 모델 카드 묶음이 아니라, Microsoft가 AI 경쟁을 “모델 성능 경쟁”에서 “반복 개선 가능한 제품-인프라 시스템 경쟁”으로 옮기려는 시도에 가깝다.
무엇을 해결하려는가
프런티어 모델 경쟁은 점점 두 가지 병목에 부딪히고 있다.
하나는 출처와 통제의 문제다.
모델 성능을 빠르게 올리기 위해 다른 모델의 출력을 증류하면 초기 품질은 좋아질 수 있지만, 교사 모델의 오류와 편향, 설계 선택, 라이선스 불확실성까지 함께 물려받을 수 있다.
기업 제품에 깊게 통합할 모델이라면 “어떤 데이터와 절차로 만들어졌는가”가 성능만큼 중요해진다.
다른 하나는 제품화의 문제다.
오늘날 모델은 독립 API로만 쓰이지 않는다.
코딩 모델은 GitHub Copilot과 VS Code 안에서 저장소를 읽고 테스트를 돌려야 한다.
이미지 모델은 PowerPoint와 OneDrive에서 편집 제어와 비용을 동시에 만족해야 한다.
전사·음성 모델은 Teams, Dynamics 365 Contact Center, 접근성, 고객지원 흐름에서 지연과 품질을 맞춰야 한다.
즉 모델 하나가 좋아도, 제품 하네스·권한·비용·평가·안전성까지 맞물리지 않으면 실제 워크플로우에 들어가기 어렵다.
Microsoft의 답은 “모델 패밀리 + 반복 개선 시스템”이다.
MAI는 reasoning, coding, image, transcription, voice 모델을 같은 데이터 규율과 평가 철학 아래 묶고, 이를 Microsoft 제품군과 개발자 플랫폼에 직접 연결한다.
여기에 Frontier Tuning은 조직별 데이터·도구·평가 신호를 이용해 모델과 하네스를 고객 환경 안에서 조정하는 계층으로 제시된다.
핵심 아이디어 / 구조 / 동작 방식
이번 발표를 하나의 스택으로 보면 네 층이 보인다.
첫째는 from-scratch reasoning model이다.
MAI-Thinking-1은 35B active, 약 1T total parameter의 sparse MoE reasoning model로 공개됐다.
기술 보고서 기준 기반 모델인 MAI-Base-1은 8,000개 GB200 GPU에서 30T token pre-training과 3.55T token mid-training을 거쳤고, 최대 256K context length를 지원한다.
구조적으로는 local/global attention을 주기적으로 섞고, 512 experts 중 8개를 선택하는 LatentMoE 계열 구성을 사용한다.
둘째는 제품 하네스에 맞춘 특화 모델이다.
MAI-Code-1-Flash는 5B 규모의 코딩 모델이지만 GitHub Copilot 생산 환경과 같은 harness에서 학습·평가됐다는 점을 강조한다.
MAI-Image-2.5는 고충실도 생성·정밀 편집, Flash variant는 대규모 프로덕션 비용 효율을 맡는다.
MAI-Transcribe-1.5와 MAI-Voice-2는 각각 전사와 TTS를 Teams, Copilot, Dynamics, Foundry 같은 배포 표면에 맞춘다.
셋째는 Frontier Tuning과 RLE다.
Microsoft는 reinforcement learning environment를 고객 워크플로우의 “훈련장”처럼 설명한다.
조직의 데이터, 도구 사용, 평가 신호, 업무 절차를 compliance boundary 안에 두고 모델·skills·embeddings·orchestration·runtime harness를 함께 조정한다는 구상이다.
단순 fine-tuning보다 “업무가 실제로 진행되는 방식”을 모델이 학습하도록 만드는 방향이다.
넷째는 휴머니스트 초지능이라는 통제 프레임이다.
Mustafa Suleyman의 발표와 Microsoft AI의 설명은 Humanist Superintelligence를 반복한다.
여기서 핵심은 더 강한 AI를 만들되, 사람과 조직을 대체하는 독립 행위자가 아니라 인간의 의도와 감독 아래 있는 도구로 설계하겠다는 것이다.
이 문구는 철학적 선언이기도 하지만, 기업 고객에게는 데이터 통제, 권한 상속, 감사 가능성, compliance boundary를 제품 요구사항으로 번역하는 신호이기도 하다.
| 층 | 공개 자료에서 확인되는 구성 | 실무적으로 읽는 법 |
|---|---|---|
| Base / reasoning | MAI-Thinking-1, 35B active / ~1T total sparse MoE, 256K context, no third-party distillation | Microsoft가 자체 데이터·학습·평가 루프로 frontier급 reasoning model을 만들겠다는 선언 |
| Coding | MAI-Code-1-Flash, 5B, Copilot/VS Code, adaptive solution length control | benchmark solver보다 실제 Copilot harness에서 비용·지연·성공률을 맞추려는 모델 |
| Multimodal media | MAI-Image-2.5 / Flash, MAI-Transcribe-1.5, MAI-Voice-2 / Flash | 이미지·음성·전사를 Microsoft 365와 Foundry 제품 표면에 바로 넣는 배포 전략 |
| Customization | Frontier Tuning, customer-specific RLE, compliance boundary | 모델을 고객별 workflow와 평가 신호에 맞춰 계속 개선하는 운영 계층 |
| Governance frame | Humanist Superintelligence, human control, subordinate tools | 강한 AI를 조직의 권한·감사·책임 구조 안에 묶어 두려는 포지셔닝 |
공개된 7종 모델에서 확인되는 점
이번 발표의 모델별 메시지는 꽤 선명하다.
Microsoft는 각 모델을 독립 연구 결과라기보다, 실제 제품 표면에서 바로 쓰이는 역할 단위로 나눴다.
| 분야 | 모델 | 공개된 핵심 근거 | 해석 |
|---|---|---|---|
| 추론 | MAI-Thinking-1 | 35B active / ~1T total sparse MoE, 256K context, SWE-Bench Pro 52.8%, AIME 2025 97.0%, 기술 보고서 공개 | Microsoft의 자체 foundation/reasoning stack을 대표하는 모델 |
| 코딩 | MAI-Code-1-Flash | 5B, GitHub Copilot individual users in VS Code rollout, SWE-Bench Pro 51.2% vs Claude Haiku 4.5 35.2%, 최대 60% fewer tokens claim | “작고 빠른 agentic coding model”을 Copilot 운영 하네스에 맞춘 사례 |
| 이미지 | MAI-Image-2.5 | Arena Image Edit No. 2, Text-to-Image No. 3, 정밀 편집·identity consistency 강조 | PowerPoint/OneDrive 같은 생산성 제품에 들어갈 고품질 이미지 엔진 |
| 이미지 | MAI-Image-2.5-Flash | 더 낮은 Foundry 가격과 생산 워크로드용 Flash variant | 고충실도 모델과 대량 호출 모델을 분리한 비용 전략 |
| 전사 | MAI-Transcribe-1.5 | 43개 언어, FLEURS WER claim, 1시간 오디오를 15초 이내 전사, keyword biasing | 회의·고객센터·개발자 워크플로우에 맞춘 대규모 batch transcription |
| 음성 | MAI-Voice-2 | 표현형 TTS, 한국어 포함 다국어 지원, 5–60초 reference audio, 72.1% preference over MAI-Voice-1 | 고객지원·접근성·크리에이터용 voice layer |
| 음성 | MAI-Voice-2-Flash | ultra latency-sensitive voice agents용 저지연·고효율 variant | 2026년 voice agent 워크로드를 위한 비용/지연 최적화 |
여기서 주의할 점은 대부분의 성능 수치가 Microsoft가 제시한 조건과 하네스 위에서 보고된다는 것이다.
예를 들어 MAI-Code-1-Flash의 비교는 GitHub Copilot production harness 기준이고, MAI-Thinking-1의 사람 평가도 Microsoft가 설명한 blind side-by-side setting이다.
따라서 이 수치들은 “모든 환경에서 독립 재현된 절대 순위”라기보다, Microsoft가 어떤 사용 환경을 중심으로 모델을 설계하고 있는지 보여 주는 evidence map으로 읽는 편이 안전하다.
Hill-Climbing Machine의 핵심은 모델보다 루프다
MAI 발표에서 가장 중요한 단어는 “family”보다 “machine”일 수 있다.
Microsoft는 모델 개발을 단일 대형 학습 run이 아니라, 데이터·아키텍처·인프라·RL·평가가 반복적으로 개선되는 시스템으로 설명한다.
특히 MAI-Thinking-1 기술 보고서는 scaling ladder, architecture ablation, dropless MoE, Maia 200과의 공동 설계 같은 표현을 통해 “왜 이 구조를 골랐는지”를 실험 루프의 결과로 제시한다.
이 접근은 Google의 TPU/Gemini, Anthropic의 Claude, OpenAI의 productized model stack과 비교해도 흥미롭다.
Microsoft는 클라우드와 생산성 제품, GitHub, Windows/Office 생태계를 이미 갖고 있다.
여기에 자체 모델과 자체 가속기, Foundry, Frontier Tuning을 얹으면 모델 개선 루프가 바로 제품 사용 루프와 연결된다.
Copilot에서 어떤 코딩 task가 실패하는지, Teams transcription에서 어떤 domain term이 틀리는지, PowerPoint 이미지 생성에서 어떤 편집 제어가 필요한지가 다음 학습·평가 표면이 될 수 있다.
물론 이 루프가 실제로 잘 작동하려면 공개 발표보다 훨씬 어려운 문제가 남는다.
고객 데이터는 compliance boundary 안에 있어야 하고, 모델이 접근할 수 있는 도구와 문서는 기존 권한을 상속해야 하며, RL 환경은 실제 production system을 망가뜨리지 않는 sandbox여야 한다.
Frontier Tuning이 말하는 “조직별 모델”은 매력적이지만, 보안·감사·비용·품질 회귀 테스트 없이는 위험한 자동화가 될 수 있다.
실무 관점에서의 해석
실무 팀에게 이번 발표가 주는 가장 큰 신호는, 모델 벤더 경쟁이 점점 base model + product harness + customization loop의 묶음으로 바뀌고 있다는 점이다.
이제 “어느 모델이 benchmark에서 몇 점인가”만으로는 부족하다.
그 모델이 어떤 제품 안에서 실행되는지, 비용 곡선이 어떤지, 조직별 데이터를 어디까지 반영할 수 있는지, 권한과 감사 로그가 어떻게 관리되는지가 함께 중요해진다.
MAI-Thinking-1은 Microsoft가 자체 reasoning model을 독립적으로 확보하려는 의지를 보여 준다.
MAI-Code-1-Flash는 코딩 모델이 단순히 강한 코드 생성기가 아니라 Copilot 같은 실제 agent harness와 함께 학습되어야 한다는 방향을 보여 준다.
MAI-Image, Transcribe, Voice 계열은 모델 family가 Microsoft 365의 다양한 입력·출력 매체를 덮는 방식으로 확장되고 있음을 보여 준다.
반대로 한계도 명확하다.
MAI 모델 대부분은 아직 Microsoft 제품·Foundry·선택된 개발자 플랫폼 중심으로 제공되며, 모든 모델의 가중치가 공개된 open-weight release는 아니다.
“clean and licensed data”, “no distillation”, “Humanist Superintelligence” 같은 표현도 강한 포지셔닝이지만, 외부에서 완전히 검증 가능한 정보는 제한적이다.
특히 Frontier Tuning은 고객별로 성능이 달라질 수밖에 없고, Microsoft가 제시한 Excel·enterprise 사례의 10배 효율 claim은 실제 업무 조합과 평가 방식에 따라 달라진다.
그럼에도 방향성은 중요하다.
Microsoft는 이번 발표를 통해 “우리는 모델을 만들 수 있다”보다 더 큰 메시지를 낸다.
그것은 모델을 만들고, 제품에 넣고, 조직별로 조정하고, 다시 평가해 개선하는 루프를 만들겠다는 것이다.
AI 제품을 만드는 팀이라면 이 발표를 새로운 MAI 모델 목록으로만 볼 것이 아니라, 앞으로 기업용 AI가 어떤 운영 구조를 요구할지 보여 주는 사례로 읽는 편이 더 유익하다.