AI 연구 자동화를 둘러싼 말은 빠르게 과격해진다.
한쪽에서는 “AI scientist”가 곧 과학자를 대체할 것처럼 말하고, 다른 한쪽에서는 LLM의 환각과 재현성 문제 때문에 연구 자동화 자체를 위험한 유행으로 본다.
AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery는 이 논의를 조금 더 차분한 지도 위에 올린다.
핵심은 “AI가 연구를 할 수 있는가”가 아니라, 어느 단계에서 AI가 통제하고, 어느 단계에서 인간이 검증하며, 어떤 도메인에서 자율성이 실제로 닫힐 수 있는가다.
이 논문은 새로운 단일 에이전트나 실행 프레임워크를 제안하는 논문이라기보다 survey이자 taxonomy다.
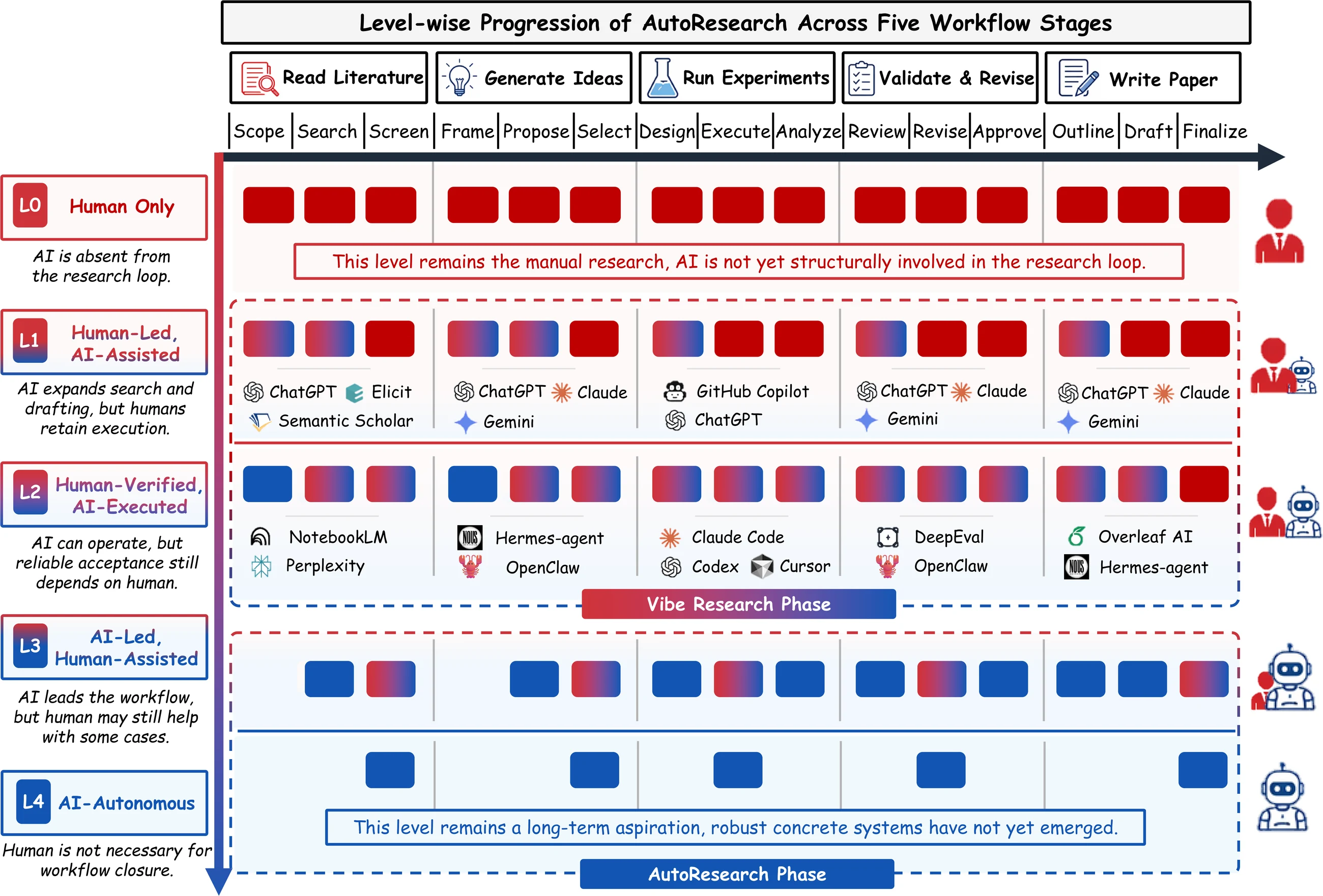
저자들은 AutoResearch를 “AI-powered scientific workflow automation의 developmental spectrum”으로 정의하고, 그 안에서 인간이 프롬프트와 검증으로 조향하는 영역을 Vibe Research라고 부른다.
즉 ChatGPT로 아이디어를 브레인스토밍하는 L1부터, 코드·도구·실험을 AI가 상당 부분 실행하되 인간이 승인하는 L2, 더 나아가 AI가 워크플로를 주도하는 L3/L4까지를 한 축에 놓는다.
중요한 점은 논문이 완전 자율을 쉽게 선언하지 않는다는 것이다. abstract와 본문은 현재 시스템들이 문헌 grounding, hypothesis generation, experimentation, validation, reporting을 점점 넓게 연결하지만, 여전히 evidence preservation, reproducibility, weak-direction rejection, provenance tracking, accountable scientific closure에서 약하다고 본다.
따라서 이 글은 AutoResearch AI를 “AI가 논문을 자동으로 쓴다”는 홍보 문구보다, 연구 워크플로의 권한·증거·검증·책임을 어떻게 재배치할 것인가라는 운영 문제로 읽는 편이 맞다.
무엇을 해결하려는가
AI for Science의 기존 논의는 대개 특정 능력에 집중했다.
AlphaFold류의 예측 모델, 문헌 검색 도구, 논문 요약, 코드 생성, 실험 자동화, 리뷰어 시뮬레이션처럼 각각의 subtask는 빠르게 발전했다.
하지만 실제 과학 연구는 isolated task가 아니라 긴 루프다.
문헌을 읽고, 질문을 만들고, 가설을 세우고, 실험을 설계하고, 코드를 실행하고, 결과를 검증하고, 실패한 방향을 버리고, 마지막으로 글과 artifact로 남긴다.
AutoResearch AI가 풀려는 문제는 바로 이 단위의 전환이다.
논문은 field가 task-level AI for science에서 workflow-level research automation으로 이동하고 있다고 본다.
여기서 중요한 것은 개별 도구의 정확도보다, 도구들이 연결될 때 과학적 주장과 근거가 깨지지 않는지다.
AI가 그럴듯한 hypothesis와 paper draft를 많이 만들 수 있어도, 그것이 진짜 연구가 되려면 실행 기록, 실패 기록, 검증 조건, 출처, 인간 승인, 책임 소재가 남아야 한다.
그래서 논문은 AutoResearch를 단순 capability ladder로 보지 않는다.
L0~L4의 autonomy level은 누가 더 똑똑한가가 아니라, control, execution, validation, accountability가 인간과 AI 사이에서 어떻게 분배되는가를 나타낸다.
같은 시스템도 문헌 검색에서는 L2처럼 보일 수 있지만, clinical validation에서는 여전히 L1에 가까울 수 있다.
즉 자율성은 모델 하나의 속성이 아니라 도메인·도구·검증 환경의 합성 결과다.
| Level | 논문이 보는 핵심 상태 | 실무 해석 |
|---|---|---|
| L0 Human Only | 인간이 연구 루프를 계획·실행·검증 | 전통적 연구, AI는 구조적으로 관여하지 않음 |
| L1 Human-Led, AI-Assisted | 인간 주도, AI는 검색·초안·요약 보조 | 현재 가장 흔한 AI-assisted research |
| L2 Human-Verified, AI-Executed | AI가 의미 있는 작업을 실행, 인간이 검증·승인 | coding agent, 실험 보조, co-scientist 계열의 현실적 frontier |
| L3 AI-Led, Human-Assisted | AI가 워크플로를 주도, 인간은 예외 처리 | 일부 구조화 도메인에서 탐색 중이나 안정적 closure는 제한적 |
| L4 AI-Autonomous | 인간 없이 과학적 closure 달성 | 장기 목표에 가깝고, 현재 robust concrete system은 없다고 보는 편이 안전 |
이 분류에서 흥미로운 표현이 Vibe Research다.
논문은 L1~L2, 그리고 일부 L3 초입을 인간이 계속 조향하고 검증하는 active region으로 본다.
연구자가 프롬프트를 던지고, AI가 literature map을 만들고, agent가 코드를 실행하고, 인간이 최종 claim을 받아들이거나 거절하는 현재의 실무적 형태다.
따라서 Vibe Research는 비하적 표현이라기보다, 아직 과학적 책임과 승인권이 인간에게 남아 있는 현실적 자동화 영역을 가리킨다.
핵심 아이디어 / 구조 / 동작 방식
논문의 프레임은 네 개의 렌즈로 구성된다.
첫째, L0~L4 autonomy spectrum이다.
둘째, 연구 워크플로를 literature and research grounding, hypothesis formation and planning, experimentation and tool use, feedback/validation/review, reporting and knowledge communication의 다섯 조건으로 나눈다.
셋째, AutoResearch 시스템을 novelty, validity, impact, reliability, provenance로 평가해야 한다고 제안한다.
넷째, domain-conditioned autonomy ceilings를 통해 어떤 과학 분야에서 자율성이 더 빨리 올라갈 수 있고 어디서 막히는지를 설명한다.
다섯 워크플로 조건은 연구 자동화를 stage별로 쪼개는 장치다. literature grounding은 검색 결과를 durable evidential state로 바꾸는 일이고, hypothesis formation은 grounded context에서 operationalizable plan을 만드는 일이다. experimentation and tool use는 계획을 코드, API, simulator, 실험 장비에 연결한다. feedback and validation은 실패를 걸러내고 claim이 굳어지기 전에 rejection pressure를 넣는다. reporting은 최종 문서가 claim-evidence alignment를 유지하도록 만드는 단계다.
이 구분이 중요한 이유는 stage마다 실패 양상이 다르기 때문이다.
문헌 요약은 citation provenance가 약하면 위험하고, hypothesis generation은 novelty와 feasibility 판단이 병목이다. experimentation은 코드가 실행되는지만으로 충분하지 않고, 올바른 방법을 구현했는지가 중요하다. validation은 fluent critique보다 실제 오류 탐지와 약한 방향의 폐기가 중요하다. reporting은 문장이 매끄럽더라도 claim과 evidence가 어긋나면 연구 산출물이 아니라 story generation이 된다.
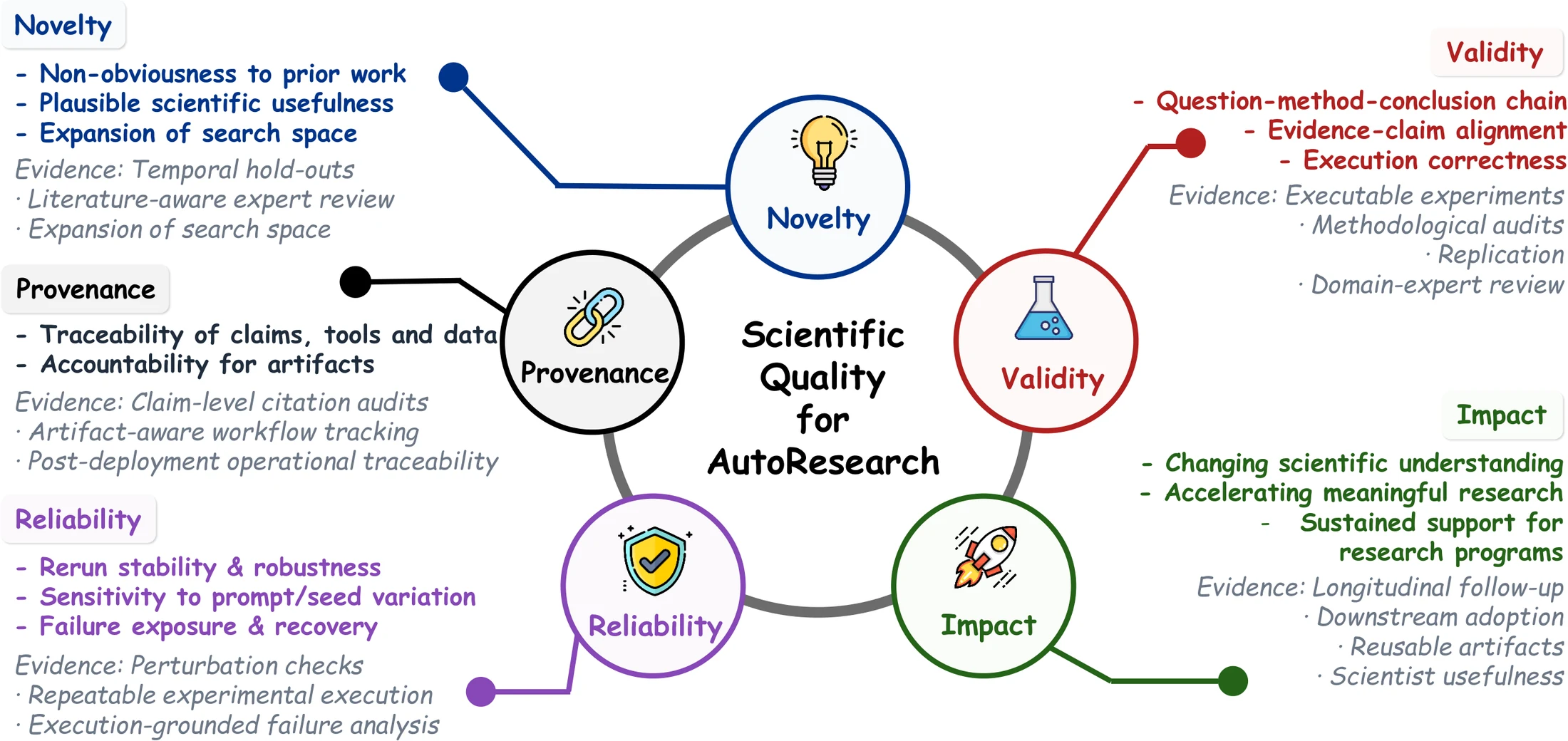
평가 프레임도 실무적으로 유용하다.
논문은 AutoResearch의 품질을 다섯 축으로 본다.
| 평가 차원 | 질문 | 필요한 증거의 예 |
|---|---|---|
| Novelty | 기존 연구 대비 새롭고 유용한가 | temporal hold-out, literature-aware expert review |
| Validity | 질문·방법·결론의 사슬이 맞는가 | 실행 가능한 실험, 방법론 감사, 재현, 전문가 검토 |
| Impact | 의미 있는 연구 프로그램을 가속하는가 | 후속 채택, reusable artifact, longitudinal follow-up |
| Reliability | 반복 실행과 perturbation에 안정적인가 | rerun stability, prompt/seed sensitivity, failure recovery |
| Provenance | claim, data, tool, source가 추적 가능한가 | claim-level citation audit, artifact-aware workflow trace |
이 다섯 축은 AI research agent를 제품으로 만들 때도 좋은 체크리스트가 된다.
단순히 “정답을 잘 냈다”가 아니라, 어떤 근거에서 그 claim이 나왔는지, 실패한 실험을 숨기지 않는지, rerun했을 때 같은 결론을 주는지, 사람이 검증해야 하는 지점이 어디인지까지 봐야 한다는 뜻이다.
공개된 근거에서 확인되는 점
arXiv 페이지 기준 이 논문은 2026년 5월 22일 제출된 49쪽 survey이며, 12개 figure와 10개 table을 포함한다.
제목은 AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery이고, 라이선스는 Creative Commons Attribution 4.0으로 표시된다.
Hugging Face Papers 페이지는 arXiv, PDF, project page, GitHub 링크를 함께 노출한다.
공개 companion source는 두 층으로 나뉜다.Mr-Tieguigui/Survey-of-AutoResearch는 실제 survey framework와 awesome list를 담은 repo다.
조회 시점 기준 GitHub API에서 Apache-2.0 license, 기본 브랜치 main, 2026-04-20 생성, 2026-05-25 push, stars 5로 확인된다.
루트는 Figure/, LICENSE, README.md로 단순하며, README는 논문의 핵심 프레임과 curated AutoResearch reading map을 제공한다.
반면 Mr-Tieguigui/Autoresearch는 독립 정적 project page repository에 가깝고, README도 Survey-of-AutoResearch를 위한 homepage project라고 설명한다.
따라서 실행 가능한 agent framework release가 아니라 survey + resource list + project page asset bundle로 분류하는 것이 정확하다.
README의 awesome list도 논문 성격을 잘 보여 준다.
Survey papers, workflow-level systems and AI scientists, methodological stages, benchmarks/evaluation, domain-specific applications로 나뉘며, STORM, GPT Researcher, OpenScholar, PaperQA2, Open Deep Research, DeerFlow, OpenHands, Aider, SWE-agent, Agent Laboratory 같은 인접 시스템을 연결한다.
이 목록은 구현체라기보다, AutoResearch 생태계를 읽는 index다.
논문이 반복해서 강조하는 결론은 보수적이다. current systems can increasingly generate, execute, analyze, and report, yet robust scientific closure still depends on evidence preservation, provenance, rejection of weak directions, failure recovery, domain-grounded validation, and accountable acceptance.
즉 현재 시스템들은 더 넓은 pipeline을 연결하지만, 완전 자율 과학자로 보기에는 검증·책임의 조건이 부족하다.
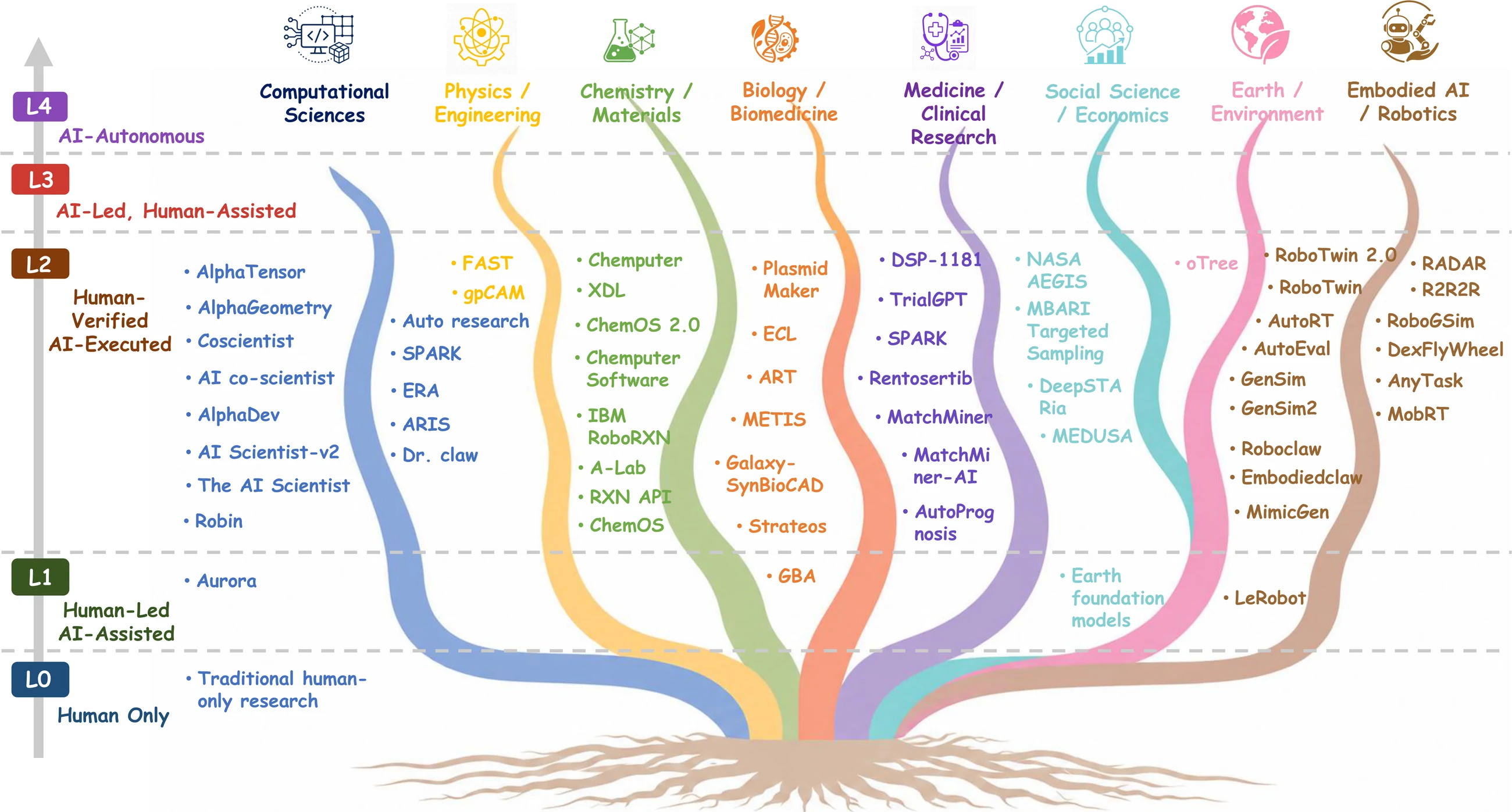
도메인별 해석도 중요하다. computational and formal sciences는 code-native이고 replay 가능한 환경이 많아 상대적으로 높은 자동화 잠재력을 가진다.
물리·화학·생물 영역은 simulator, robotic lab, closed-loop optimization이 붙으면 강해질 수 있지만, 실제 장비와 실험 비용, 관측 지연이 제약이 된다. clinical, social, earth sciences는 validation이 늦고 윤리·규제·제도 책임이 크기 때문에 L2 이상의 자율성을 주장하기 어렵다.
| 도메인 조건 | AutoResearch 가능성이 높은 이유 | 제한이 커지는 이유 |
|---|---|---|
| Computational / formal | 코드 실행, unit test, benchmark, replay가 쉬움 | benchmark gaming과 실제 과학적 novelty의 간극 |
| Chemistry / materials / robotics lab | 장비·실험 계획을 closed-loop로 연결 가능 | 물리 장비, safety, cost, measurement noise |
| Biology / biomedicine | 대규모 데이터와 자동 분석 파이프라인이 풍부 | causal complexity, wet-lab validation, human oversight |
| Clinical / social / earth | 실제 영향이 크고 institutional accountability가 필요 | 지연된 검증, 윤리·규제, 조작 불가능한 대상 |
이 점이 기존 auto-research hype와 가장 다른 부분이다.
논문은 “pipeline이 통합됐다”는 사실을 “과학적 자율성이 달성됐다”로 착각하지 말라고 경고한다.
에이전트가 문헌을 읽고 코드를 쓰고 report를 만들더라도, domain-grounded validation과 accountable acceptance가 없으면 과학적 closure는 여전히 인간·기관·커뮤니티의 책임 안에 남는다.
실무 관점에서의 해석
내가 보기에 AutoResearch AI의 가장 큰 가치는 연구 자동화 논의를 권한 배분표로 바꾼다는 데 있다.
어떤 AI 연구 에이전트를 도입하려는 팀은 이제 “이 시스템이 연구를 자동화한다”는 말 대신 더 구체적인 질문을 할 수 있다.
어느 stage를 자동화하는가?
AI가 실행만 하는가, 계획도 하는가?
인간은 목표 설정자인가, 검증자인가, 예외 처리자인가?
결과 claim은 어떤 provenance를 갖는가?
실패한 방향은 어떻게 폐기되는가?
최종 acceptance는 누가 책임지는가?
이 관점은 사용자의 연구 자동화·에이전트 운영에도 바로 이어진다.
연구 queue, experiment harness, reviewer agent, blog/report generator를 각각 만들 수는 있다.
하지만 그것들이 하나의 AutoResearch system이 되려면, 단순 task handoff보다 더 강한 연결이 필요하다. literature grounding은 나중에 claim audit로 이어져야 하고, experiment execution은 metric owner와 rerun log를 남겨야 하며, reporting은 source trace와 artifact link를 보존해야 한다.
결국 좋은 시스템은 “agent가 알아서 했다”가 아니라, AI가 실행한 부분과 인간이 판단한 부분을 분리해 추적할 수 있는 workflow다.
또 하나의 실무적 메시지는 자율성의 상한을 도메인별로 다르게 잡아야 한다는 점이다.
코드 기반 ML 실험이나 benchmark-driven optimization에서는 L2~L3에 가까운 자동화가 현실적으로 가능할 수 있다.
반대로 임상, 사회과학, 장기 환경 연구처럼 결과 검증이 느리고 책임이 큰 영역에서는 같은 에이전트 구조를 가져와도 자율성 level은 낮게 평가해야 한다.
기술 스택이 같아도 validation substrate가 다르면 자동화 등급이 달라진다.
그래서 이 논문은 실행 가능한 tool release라기보다, 앞으로 AutoResearch 시스템을 평가할 때 쓰는 기준표에 가깝다.
AI scientist, deep research agent, coding agent, paper-writing agent, reviewer agent가 계속 등장하더라도 핵심 질문은 유지된다.
그 시스템은 과학적 품질의 다섯 축을 어떻게 보존하는가.
그리고 인간의 검증·책임·승인은 어디에 남아 있는가.
이 질문을 분명히 해 준다는 점에서 AutoResearch AI는 단순 survey 이상의 실무적 가치가 있다.