검색 에이전트가 단순히 웹 페이지 몇 개를 찾아오는 단계에서 벗어나고 있다.
이제 중요한 질문은 “정답 후보를 어디서 찾는가”가 아니라, 긴 탐색 과정에서 증거를 모으고, 출처를 붙이고, 최종 보고서로 합성하는 에이전트를 어떻게 훈련할 것인가다.
OpenAI Deep Research, Gemini Deep Research, Claude Research 같은 강한 시스템은 이미 이 방향을 보여줬지만, 대체로 폐쇄형 제품에 가깝다.
OSU NLP Group의 QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks는 이 빈칸을 정면으로 겨냥한다.
QUEST는 2B부터 35B까지의 공개 deep research agent 패밀리이며, fact seeking, citation grounding, report synthesis를 함께 다루도록 설계됐다.
논문과 프로젝트 페이지의 핵심 주장은 꽤 공격적이다.
사람 손으로 만든 annotation 없이, 8K 합성 과제와 rubric-tree 기반 reward만으로 최근 공개형 research agent 중 가장 강한 축에 드는 성능을 만들 수 있다는 것이다.
여기서 중요한 점은 QUEST가 단순 모델 체크포인트 하나가 아니라는 데 있다.
공개 번들은 arXiv 논문, 프로젝트 페이지, GitHub 코드, Hugging Face 모델·데이터 컬렉션, 데모 Space까지 포함한다.
즉 “딥리서치 에이전트의 성능표”라기보다, 합성 과제 생성 → context 관리 → MT/SFT/RL 훈련 → 평가/배포까지 이어지는 공개형 훈련 레시피로 읽는 편이 맞다.
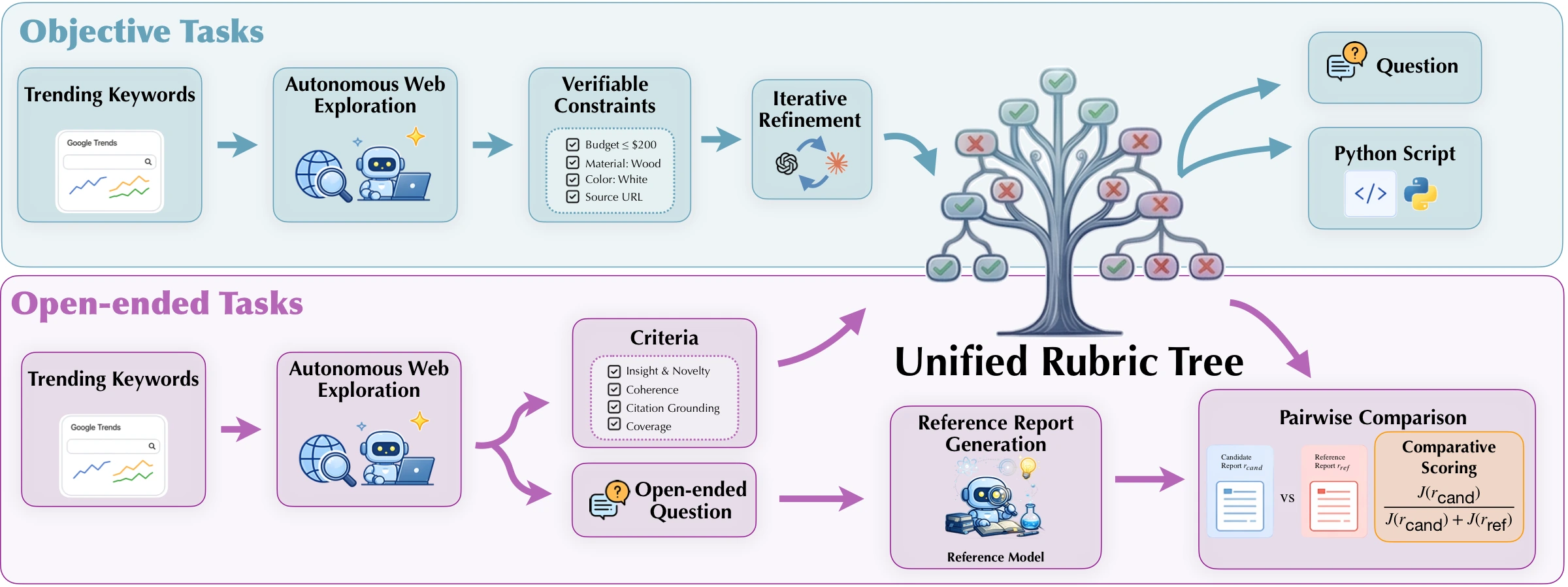
무엇을 해결하려는가
딥리서치 에이전트는 기존 검색/RAG보다 더 긴 작업을 수행한다.
질문을 하위 문제로 나누고, 웹을 탐색하고, 페이지를 읽고, 중간 증거를 요약하고, 출처를 붙이고, 마지막에는 읽을 만한 보고서 형태로 합성해야 한다.
이 과정에서 필요한 능력은 크게 세 가지다.
| 능력 | 의미 | QUEST가 겨냥하는 평가 표면 |
|---|---|---|
| Fact seeking | 여러 검색·방문을 거쳐 정확한 사실을 찾는 능력 | BrowseComp, HLE, GAIA, WideSearch |
| Citation grounding | 주장마다 검증 가능한 URL과 출처를 붙이는 능력 | Mind2Web 2 등 |
| Report synthesis | 여러 자료를 긴 문서로 조직화하는 능력 | DeepResearch Bench, LiveResearchBench |
문제는 이 세 능력을 동시에 잘 훈련하기가 어렵다는 점이다.
기존 공개 에이전트는 특정 benchmark나 특정 작업 유형에 과적합되기 쉽고, 강한 상용 시스템은 훈련 데이터와 recipe가 닫혀 있다.
더구나 deep research는 단답 QA처럼 “정답 문자열 하나”로 보상하기 어렵다.
보고서 품질, 인용의 적절성, coverage, coherence 같은 요소는 더 구조화된 평가 기준이 필요하다.
QUEST의 답은 합성 과제 자체를 평가 가능하게 만드는 것이다. objective task에는 예산, 재료, 출처 URL 같은 verifiable constraints를 붙이고, open-ended task에는 insight, novelty, coherence, citation grounding, coverage 같은 criteria를 붙인다.
이 기준을 tree 형태로 만든 뒤, 생성·정제·검증 과정을 거쳐 훈련 데이터와 reward signal로 사용한다.
핵심 아이디어 / 구조 / 동작 방식
QUEST의 중심에는 세 가지 구성 요소가 있다.
첫째는 rubric-tree 기반 합성 데이터 생성이다.
프로젝트 페이지와 README는 objective task와 open-ended task를 나눠 설명한다. objective task는 trending keyword와 autonomous web exploration에서 출발해 verifiable constraints를 만들고, 이후 질문과 verifier script로 바뀐다. open-ended task는 criteria와 reference report를 만들고, candidate report와 reference report를 비교하는 방식으로 평가 신호를 만든다.
논문은 이 전체 묶음을 QUEST-8K로 부르며, 8K 합성 과제만으로 훈련했다고 설명한다.
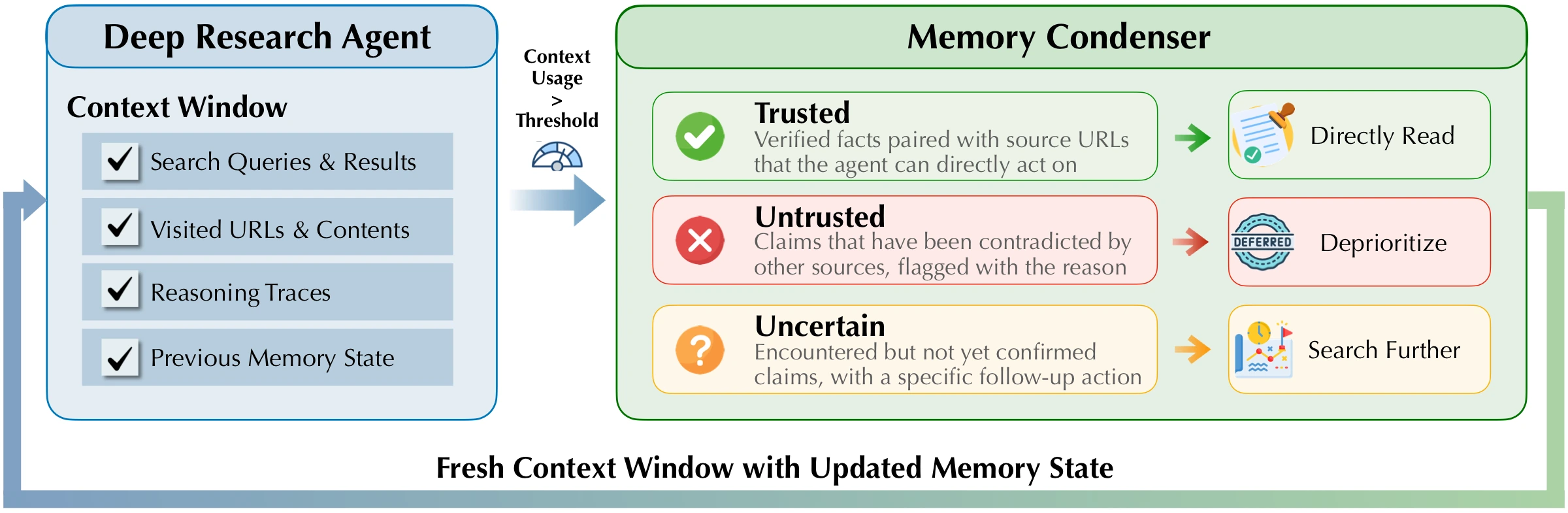
둘째는 context management다.
딥리서치 에이전트는 여러 turn 동안 검색 결과, 페이지 내용, 중간 요약, 도구 호출을 계속 누적한다.
모든 tool result를 그대로 들고 가면 context가 폭발하고, 반대로 무작정 버리면 나중에 출처와 세부 사실을 잃는다.
QUEST는 condenser 중심의 context strategy를 기본값으로 두고, vanilla, discard-all, hide-tool-result 같은 전략과 비교한다.
데모 설정에도 max turns, context strategy, temperature 같은 값이 노출돼 있어, 이 시스템이 단순 chat model이 아니라 long-horizon agent runtime을 전제로 한다는 점이 드러난다.
셋째는 MT → SFT → RL 훈련 파이프라인이다.
README 기준으로 SFT 계열은 LlamaFactory backend를 사용하고, RL backend는 VERL과 Megatron 기반의 fully async deepresearch recipe를 제공한다.
RL 쪽에는 search, scholar, visit, Python, memory 관련 tool implementation과 reward routing이 포함된다.
다시 말해 QUEST는 모델만 공개한 것이 아니라, 연구 에이전트 훈련을 재현하려는 팀이 어떤 서비스, 데이터, 평가 노드를 준비해야 하는지까지 꽤 구체적으로 드러낸다.
공개된 근거에서 확인되는 점
공개 번들은 꽤 넓다.
GitHub 저장소 OSU-NLP-Group/QUEST는 MIT license로 공개돼 있고, 조회 시점 기준 Python 중심 코드와 inference/, evaluation/, task/, training_scripts/ 디렉터리를 포함한다.
README는 benchmark replication, mid-training/SFT, RL backend, objective/open-ended task generation, evaluation script 위치를 나눠 안내한다.
Hugging Face collection은 15개 항목으로 구성돼 있다.
Space와 paper 외에도 35B/30B/9B/4B/2B 모델, RL 데이터, SFT objective 데이터, SFT open-ended 데이터가 올라와 있다.
모델 카드 태그 기준 라이선스는 Apache-2.0이고, 데이터셋 태그 기준 라이선스는 MIT다.
다만 README는 cached databases와 mid-training data는 법적 검토 중이라 아직 공개하지 않았다고 명시한다.
따라서 “모든 것이 완전히 즉시 재현 가능하다”기보다는, 모델·데이터·코드의 큰 골격은 공개됐지만 일부 캐시/중간 데이터는 보류 중인 release로 보는 편이 정확하다.
| 공개 항목 | 확인된 표면 | 해석 |
|---|---|---|
| 모델 | QUEST-35B-RL, QUEST-35B-SFT, QUEST-35B-MT, QUEST-35B-MT-Plus-SFT, 30B/9B/4B/2B variants |
단일 체크포인트가 아니라 크기·훈련 단계별 family release |
| 데이터 | QUEST-RL-Data, QUEST-SFT-Data-Objective, QUEST-SFT-Data-Open-ended |
objective/open-ended와 RL 데이터를 분리 공개 |
| 코드 | GitHub inference/, evaluation/, task/, training_scripts/ |
추론·평가·과제 생성·훈련 script를 한 저장소에 묶음 |
| 데모 | Hugging Face Space osunlp/QUEST |
실제 질의형 research agent surface 제공 |
| 보류 | cached databases, mid-training data | 법적 검토 후 공개 예정이라고 명시 |
성능 측면에서 논문은 QUEST-35B가 여덟 개 benchmark에서 frontier closed-source agent에 접근하거나 일부 지표에서 넘는다고 주장한다.
PDF 요약 기준 Table 3에서 QUEST-35B는 Mind2Web 2에서 30.7로 OpenAI-DR의 28.0을 넘고, DeepResearch Bench에서 48.2로 OpenAI-DR의 47.0을 넘으며, GAIA에서는 80.8로 GPT-5의 76.4보다 높게 보고된다.
BrowseComp와 BrowseComp-Plus는 discard-all strategy를 사용한 수치가 함께 제시된다.
이 숫자는 closed-source frontier 전체를 압도했다기보다는, 공개형 35B research agent가 일부 축에서는 proprietary deep research 계열과 같은 테이블에 올라왔다는 신호로 읽는 것이 안전하다.
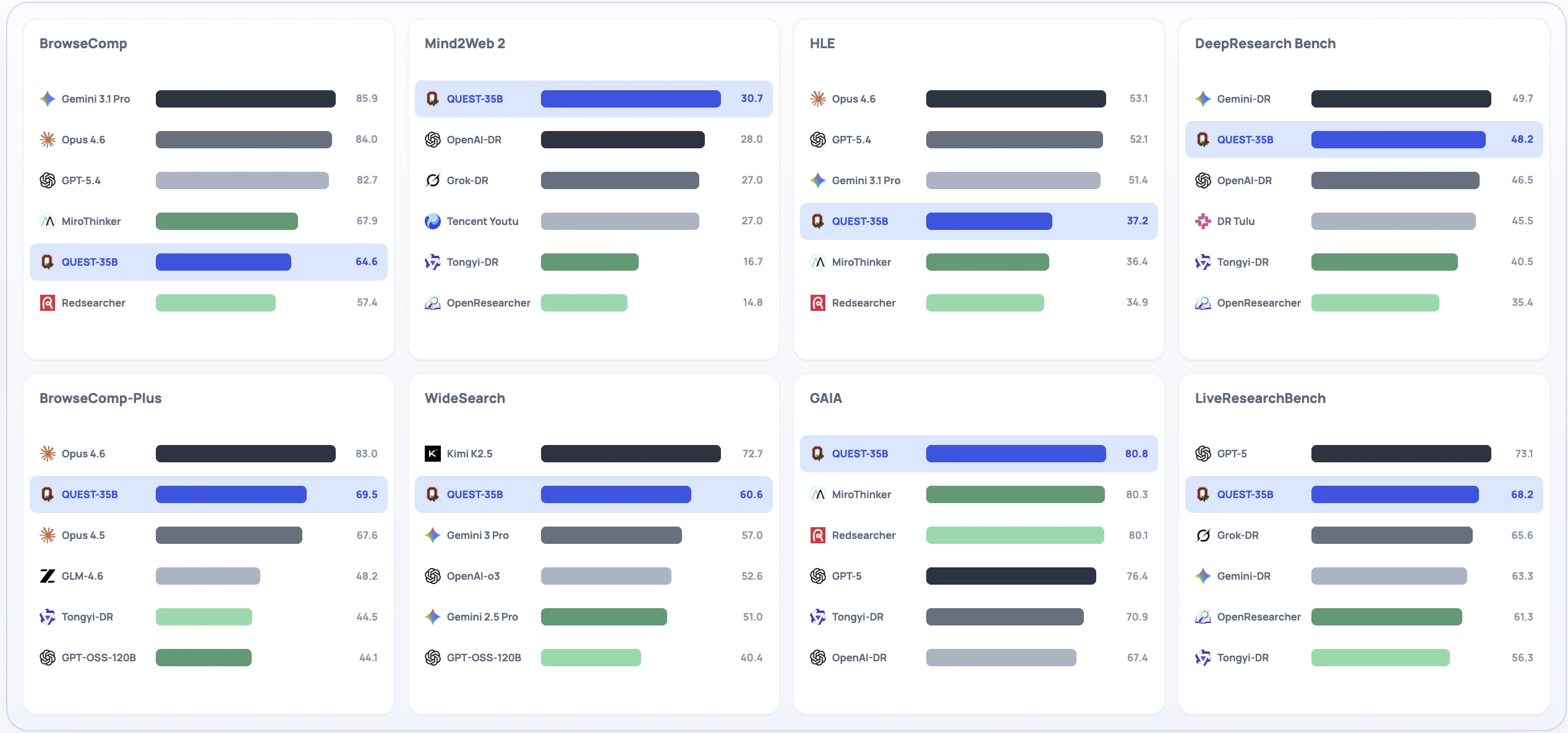
비교표도 흥미롭다.
프로젝트 페이지는 Tongyi-DR, DR Tulu, OpenResearcher, REDSearcher와 QUEST를 비교하면서 capability, task synthesis, verification, context management, training pipeline, open-sourced data, synthesis script, training code를 나눈다.
이 표에서 QUEST는 2B~35B scale, fact seeking/report synthesis/citation grounding, task synthesis, rubric tree verification, context management, MT→SFT→RL, data/script/training code 공개를 모두 체크한 시스템으로 제시된다.
실무 관점에서의 해석
QUEST의 가치는 “더 큰 모델이 검색을 잘한다”가 아니다.
오히려 핵심은 딥리서치 에이전트를 훈련 가능한 데이터·보상·런타임 문제로 재정의했다는 데 있다.
지금까지 research agent 글들은 데모 UI, agent loop, browser/search tool 연결에 집중하는 경우가 많았다.
QUEST는 한 단계 아래로 내려가서, 어떤 synthetic task가 long-horizon research를 가르칠 수 있고, 어떤 rubric이 reward로 쓸 수 있으며, 어떤 context strategy가 긴 궤적에서 정보를 유지하는지 묻는다.
이 관점은 내부 연구 자동화 시스템에도 바로 연결된다.
예를 들어 사내 research agent나 lab assistant를 만들 때 단순히 “검색하고 요약하라”는 prompt를 강화하는 것만으로는 한계가 있다.
좋은 training/evaluation surface를 만들려면 objective task, open-ended task, citation check, reference report, pairwise comparison 같은 구조가 필요하다.
QUEST의 rubric tree는 바로 그 구조를 공개형 recipe로 제시한다.
동시에 운영 난도도 낮지 않다.
README의 runtime configuration만 봐도 search, visit, OpenAI/Azure-compatible endpoint, memory condensation, reward/eval LLM, citation eval LLM, service-node routing 같은 구성 요소가 나온다.
RL backend는 별도 search/scholar service와 FAISS index, Python service까지 요구한다.
따라서 QUEST는 “pip install 후 바로 쓰는 앱”이라기보다, 딥리서치 에이전트 훈련 스택을 연구·재현하려는 팀을 위한 공개 scaffold에 가깝다.
가장 현실적인 활용 순서는 세 단계일 것이다.
첫째, Hugging Face Space와 공개 체크포인트로 capability profile을 확인한다.
둘째, inference/와 evaluation/으로 benchmark replication surface를 읽는다.
셋째, task generation과 RL backend를 참고해 자기 조직의 research task에 맞는 rubric과 reward를 설계한다.
특히 공개 데이터에 raw website content를 넣지 않았고, 저작권·라이선스 문제가 있는 샘플은 제거하겠다고 밝힌 disclaimer는, 실제 연구 데이터 파이프라인을 만들 때 반드시 따라가야 할 경계선이다.
내가 보기에 QUEST는 open deep research agent 생태계에서 중요한 기준점이 될 가능성이 크다.
성능 수치 하나보다 더 중요한 것은 공개 단위다.
모델만 공개하는 release, benchmark만 공개하는 release, 데모만 공개하는 release가 아니라, 합성 과제 생성과 훈련·평가 코드까지 함께 공개한 release이기 때문이다.
앞으로 “open deep research agent”를 말할 때는 모델 점수뿐 아니라 task synthesis, context management, reward design, data/legal release boundary까지 함께 비교하게 될 것이다.