LLM 에이전트의 장기 메모리를 이야기할 때 우리는 보통 “무엇을 검색할 것인가”를 먼저 떠올린다.
벡터 DB에 대화 기록을 넣고, 중요한 fact를 추출하고, 질문이 오면 관련 chunk를 찾아 컨텍스트에 넣는 식이다.
그런데 장기 실행 에이전트에서는 검색보다 더 먼저 터지는 병목이 있다.
새로운 대화가 계속 들어올 때 그 내용을 언제, 어떤 비용으로, 어떤 시간 구조를 보존한 채 메모리에 반영할 것인가다.
MemForest: An Efficient Agent Memory System with Hierarchical Temporal Indexing는 이 문제를 데이터 시스템 관점으로 다시 정리한다.
논문의 핵심 주장은 장기 메모리가 단순한 RAG store가 아니라, 지속적으로 들어오는 interaction stream을 받아 업데이트되는 write-heavy temporal data management system이라는 것이다.
따라서 좋은 메모리 시스템은 검색 정확도만 높이면 안 된다.
새 evidence를 빠르게 반영하고, 기존 상태 전체를 매번 다시 쓰지 않으며, 과거 상태와 전이를 잃지 않아야 한다.
MemForest가 제안하는 해법은 canonical fact와 MemTree다.
새 세션을 병렬 chunk extraction으로 처리하고, 나온 정보를 시간 anchor가 있는 canonical fact로 정규화한 뒤, session·entity·scene 범위의 시간 순서 tree에 넣는다.
내부 node는 연속 구간을 요약하고, leaf는 시간-local evidence를 보존한다.
업데이트는 전체 profile rewrite가 아니라 영향을 받은 tree path만 dirty로 표시해 refresh한다.
무엇을 해결하려는가
MemForest가 비판하는 기존 agent memory 구조는 크게 두 가지다.
하나는 fact나 chunk를 독립적으로 저장하고 embedding similarity로 찾는 방식이다.
이 방식은 local evidence를 잘 보존하지만, 시간 순서와 전이를 직접 표현하지 않는다.
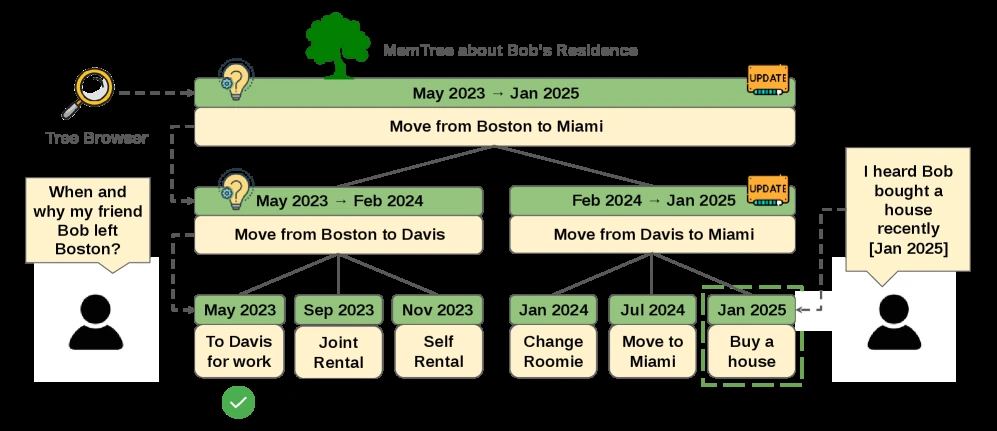
사용자가 Boston에서 Davis로, 다시 Miami로 이사했다면 “Miami로 이사하기 전 어디에 살았나?”
라는 질문에는 Davis가 필요하다.
하지만 단순 semantic retrieval은 더 최근의 Miami나 더 비슷한 Boston record를 가져올 수 있다.
다른 하나는 profile, global summary, core memory document처럼 compact mutable state를 유지하는 방식이다.
이 방식은 현재 상태 질문에는 좋을 수 있지만, 작은 업데이트에도 기존 요약을 다시 읽고 다시 써야 한다.
메모리가 커질수록 update prompt가 길어지고, 압축을 강하게 하면 중간 상태가 사라진다.
논문은 이것을 growing-or-compressing dilemma로 본다.
크게 보존하면 느려지고, 짧게 압축하면 시간적 fidelity를 잃는다.
MemForest는 이 두 실패가 실제 benchmark에서도 중요하다고 본다.
논문은 LongMemEval-S에서 knowledge-update 질문이 15.6%, temporal-reasoning 질문이 26.6%, multi-session 질문이 26.6%를 차지한다고 정리한다.
LoCoMo에서도 temporal question이 42.3%, multi-hop question이 16.2%다.
즉 장기 메모리의 어려움은 “비슷한 문서를 찾기”가 아니라, 바뀐 상태와 과거 전이를 올바른 시간 위치에서 다시 찾는 문제에 가깝다.
| 기존 설계 | 강점 | 구조적 한계 |
|---|---|---|
| 독립 fact / vector store | local evidence 보존, 구현 단순 | 시간 순서·predecessor·supersession 관계가 약해 wrong-time retrieval 발생 가능 |
| mutable profile / summary | 현재 상태 lookup이 쉬움 | 작은 update에도 전체 상태 rewrite가 필요하고 중간 상태가 압축될 수 있음 |
| MemForest / MemTree | 시간 순서 evidence와 interval summary를 함께 유지 | 별도 tree construction, summary refresh, model-serving endpoint가 필요 |
핵심 구조: canonical fact와 MemTree
MemForest의 write path는 “대화 → 한 번에 큰 요약”이 아니다.
새 session은 짧은 extraction chunk로 나뉘고, 각 chunk는 병렬로 처리된다.
논문은 기본 chunk size로 두 turn을 사용한다고 설명한다.
이렇게 하면 긴 session 전체를 하나의 LLM call에 묶지 않고, bounded local context에서 fact 후보를 뽑을 수 있다.
그 다음 단계가 canonicalization이다.
병렬 extraction은 속도를 주지만 중복과 fragmentation을 만든다.
MemForest는 entity mention, topical signal, source reference, temporal anchor가 있는 canonical fact를 stable write unit으로 만든다.
이 fact는 곧바로 global profile에 덮어써지는 것이 아니라, 어떤 temporal scope에 속하는지 routing된다.
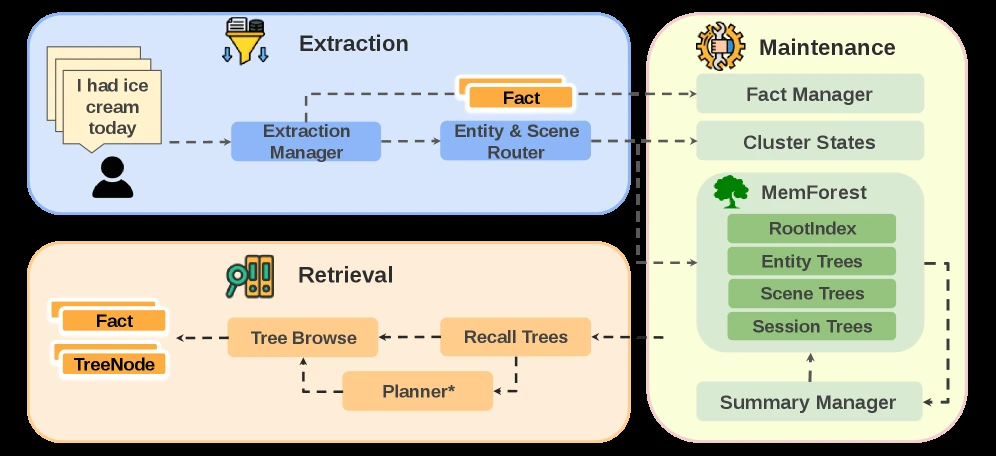
MemTree는 하나의 temporal scope를 위한 balanced temporal hierarchy다. leaf는 시간 순서의 evidence를 보존하고, internal node는 contiguous interval을 요약한다. root는 coarse recall을 위한 representation으로 쓰인다.
이 구조 덕분에 최신 summary만 남기는 것이 아니라, 이전 상태와 중간 전이를 leaf 또는 interval summary로 계속 추적할 수 있다.
논문은 세 종류의 tree view를 둔다.
| Tree family | 역할 | 실무적 의미 |
|---|---|---|
| Session tree | 하나의 source session chronology 보존 | 원문 interaction 순서로 되돌아가는 fallback view |
| Entity tree | 사람, 프로젝트, 선호, 상태-bearing object 중심 evidence 그룹화 | “이 사용자/프로젝트의 상태가 어떻게 바뀌었나”를 추적 |
| Scene tree | 여러 entity가 함께 등장하는 topic·situation 그룹화 | 단일 entity로 환원되지 않는 multi-entity context 보존 |
이 세 view는 같은 memory를 중복 저장하는 장식이 아니라, query가 요구하는 시간 범위와 granularity가 다를 때 서로 다른 접근 경로를 제공한다.
현재 상태, 이전 상태, 특정 세션, 반복 scene을 한 가지 flat index에서 모두 처리하려고 하지 않는다는 점이 중요하다.
왜 write path가 중요한가
장기 메모리 시스템은 query time에만 비용을 내지 않는다.
사용자가 새 대화를 할 때마다 extraction과 maintenance 비용을 계속 낸다.
실제 제품에서는 이것이 latency, freshness, 운영 비용으로 바로 드러난다.
메모리 update가 느리면 방금 말한 사실이 다음 턴에서 검색되지 않거나, background consolidation queue가 계속 밀리거나, long-running agent가 점점 무거워진다.
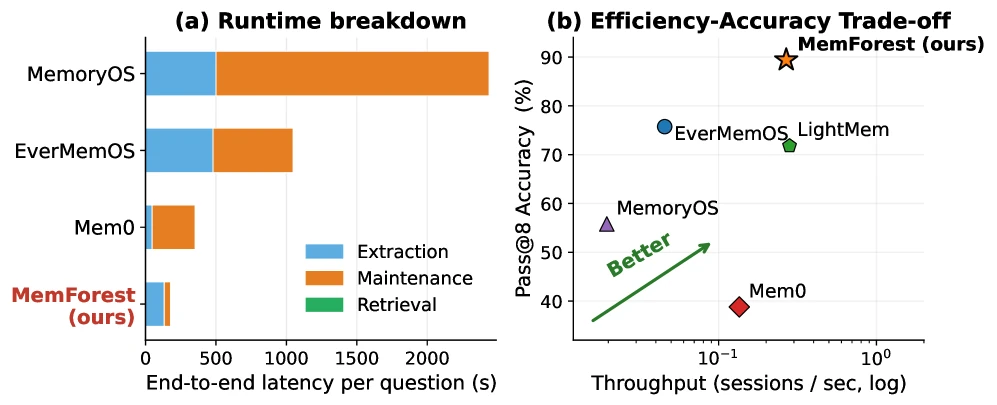
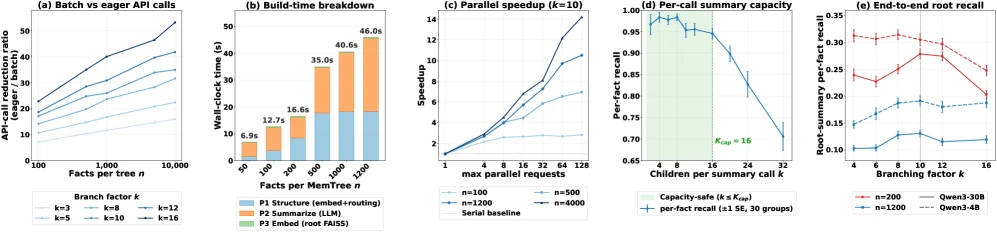
논문 Table 1은 write critical path를 이 관점으로 비교한다.
Mem0와 EverMemOS는 incoming evidence 수 M에 따라 sequential LLM update가 생기고, MemoryOS와 LightMem은 기존 상태 크기 N까지 영향을 받는 path를 갖는다.
반면 MemForest는 parallel extraction 이후 MemTree update의 의존 깊이를 tree height, 즉 대략 O(log N)로 제한한다고 설명한다.
물론 총 작업량은 touched path와 dirty node 수에 따라 늘 수 있지만, 중요한 차이는 기존 전체 상태 rewrite를 매번 critical path에 올리지 않는다는 점이다.
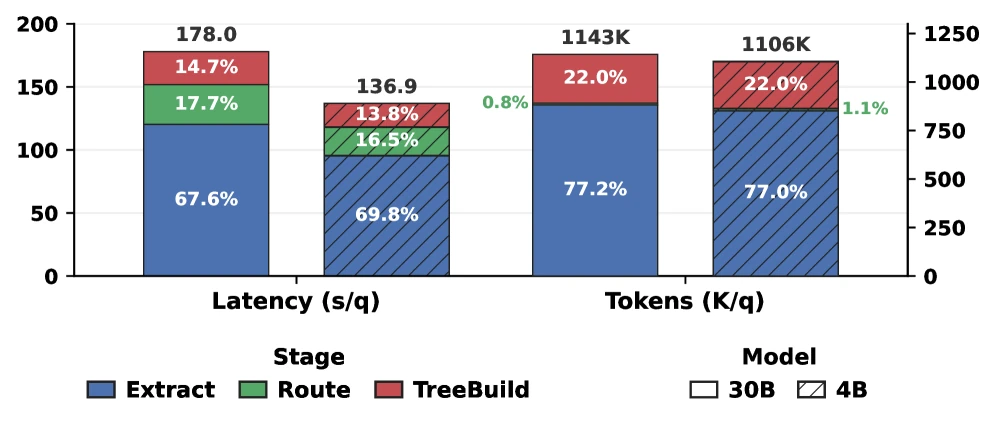
실험 수치도 이 메시지를 뒷받침한다.
LongMemEval write-path latency에서 Qwen3-30B 설정 기준 MemForest는 178.0초, EverMemOS는 1048.8초, MemoryOS는 2439.9초로 보고된다.
4B 설정에서도 MemForest는 136.9초, EverMemOS는 790.9초, MemoryOS는 1695.1초다.
| Method | 30B Time | 30B Tokens | 30B Speedup | 4B Time | 4B Tokens | 4B Speedup |
|---|---|---|---|---|---|---|
| MemForest | 178.0s | 1.143M | 13.7× | 136.9s | 1.106M | 12.4× |
| Mem0 | 353.2s | 294.1K | 6.9× | 314.9s | 289.6K | 5.4× |
| EverMemOS | 1048.8s | 1.455M | 2.3× | 790.9s | 1.466M | 2.1× |
| MemoryOS | 2439.9s | 527.8K | 1.0× | 1695.1s | 524.5K | 1.0× |
여기서 흥미로운 점은 MemForest가 token을 가장 적게 쓰는 방법은 아니라는 것이다.
30B 기준 Mem0의 token 수는 294.1K로 더 작다.
하지만 MemForest는 병렬 extraction과 localized maintenance로 wall-clock write path를 크게 줄인다.
즉 이 논문의 최적화 대상은 “토큰을 무조건 줄이기”보다, 새 memory가 queryable해지기까지의 critical path를 줄이기에 가깝다.
공개된 결과에서 확인되는 점
정확도에서는 LongMemEval-S가 MemForest의 가장 강한 장면이다.
Qwen3-30B-A3B-Instruct-2507 설정에서 MemForest는 overall pass@1 79.8을 기록하고, MemForest(emb)는 78.4를 기록한다.
같은 표에서 EverMemOS는 66.2, LightMem은 67.0, MemoryOS는 50.0, Mem0는 40.2다.
특히 temporal-reasoning에서는 MemForest가 79.7, MemForest(emb)가 81.2로 높게 나온다.
| LongMemEval pass@1, 30B | Overall | K-Upd. | Multi-Session | Temp. |
|---|---|---|---|---|
| MemForest | 79.8 | 75.6 | 73.7 | 79.7 |
| MemForest (emb) | 78.4 | 76.9 | 69.9 | 81.2 |
| EverMemOS | 66.2 | 86.7 | 62.1 | 52.5 |
| LightMem | 67.0 | 73.1 | 64.7 | 65.4 |
| MemoryOS | 50.0 | 55.1 | 34.6 | 36.8 |
| Mem0 | 40.2 | 44.9 | 41.4 | 27.8 |
4B 설정에서도 비슷한 방향이 나온다.
MemForest는 overall 70.4, EverMemOS는 56.2, LightMem은 60.4다.
Qwen3-4B 같은 작은 모델에서도 memory substrate 자체의 temporal organization이 성능 차이를 만든다는 해석이 가능하다.
LoCoMo 결과는 더 혼합적이다.
Qwen3-30B 설정에서 MemForest overall은 68.4이고 EverMemOS는 69.6이다.
Temporal subset에서는 MemForest 83.1, EverMemOS 88.1로 EverMemOS가 높고, multi-hop에서는 EverMemOS 86.6이 MemForest 67.3보다 크다.
반대로 MemForest는 single-hop과 open-ended에서 강하고, LightMem·MemoryOS·Mem0보다는 전반적으로 높다.
| LoCoMo pass@1, 30B | Overall | Single-Hop | Multi-Hop | Open-Ended | Temporal |
|---|---|---|---|---|---|
| MemForest | 68.4 | 78.0 | 67.3 | 65.6 | 83.1 |
| MemForest (emb) | 66.9 | 75.2 | 62.3 | 61.5 | 84.4 |
| EverMemOS | 69.6 | 76.2 | 86.6 | 62.5 | 88.1 |
| LightMem | 36.2 | 34.8 | 32.7 | 30.2 | 50.3 |
| MemoryOS | 50.9 | 41.1 | 29.9 | 40.6 | 66.5 |
| Mem0 | 18.6 | 16.7 | 9.0 | 30.2 | 23.3 |
이 부분은 블로그 독자에게 특히 중요하다.
MemForest를 “모든 장기 메모리 benchmark에서 완승”으로 읽으면 과장이다.
논문 자체도 LoCoMo에서는 broader multi-hop compositional reasoning에서 broader-context baseline이 여전히 도움이 될 수 있다고 설명한다.
더 정확한 해석은 이렇다.
MemForest는 시간 구조가 강한 long-context memory와 write-heavy deployment에서 뚜렷한 장점을 보이고, 모든 multi-hop reasoning 문제를 자동으로 해결하는 universal memory layer는 아니다.
구현과 릴리스 상태
공식 GitHub 저장소 Concyclics/MemForest는 논문에 연결된 reference implementation이다.
README는 이 저장소를 VLDB 2027 submission의 supplementary artifact로 설명하며, source code, supplementary appendix, configuration file, prompt template, LongMemEval-S·LoCoMo per-question benchmark output, judge result CSV를 포함한다고 밝힌다.
저장소 구조도 연구 재현성 중심이다. src/forest/memforest.py가 public API와 multi-user coordination을 담당하고, src/extraction/pipeline.py는 parallel extraction pipeline, src/build/tree_builder.py는 MemTree construction and refresh, src/query/pipeline.py는 recall·browse·rerank·answer workflow를 담당한다. runtime artifact는 user별로 SQLite fact store, FAISS index, serialized tree, logs로 나뉘어 저장된다.
Quick start도 별도 서버보다 Python API 형태다.
사용자는 MemForest("data/memforest", config=config)를 만들고, register_user, ingest_session, query, save를 호출한다.
병렬 multi-user ingestion/query도 API로 제공된다.
요구 조건은 Python 3.10+, FAISS, OpenAI-compatible chat completion endpoint, OpenAI-compatible embedding endpoint다.
논문 실험은 Qwen3 instruction model, Qwen3-Embedding-0.6B, DeepSeek-V3.2 judge, vLLM/FlashAttention serving을 사용했다고 설명한다.
릴리스 성숙도는 “논문 결과를 검증하기 위한 연구 artifact”에 가깝다.
조회 시점 기준 GitHub API는 public Python repo, stars 20, forks 1, open issues 0, default branch main으로 표시한다. tags와 releases는 비어 있다.
체크인된 LICENSE 파일은 MIT License지만, GitHub API license classification은 Other / NOASSERTION으로 잡힌다.
README도 full rerun에는 원본 benchmark data와 model-serving infrastructure가 필요하며, lightweight verification은 released CSV로 pass@1/pass@8을 재계산하는 방식이라고 명시한다.
실무 관점에서의 해석
내가 보기에 MemForest의 가장 중요한 메시지는 “에이전트 메모리의 병목은 검색 엔진 선택만으로 해결되지 않는다”는 것이다.
장기 실행 에이전트를 운영하면 retrieval quality보다 먼저 update lifecycle이 문제가 된다.
어떤 사실을 언제 memory로 승격할지, 기존 summary를 얼마나 자주 다시 쓸지, 새 session이 다음 query에 반영되는 데 얼마나 걸릴지, 과거 상태를 지우지 않고 어떻게 압축할지가 제품 품질을 좌우한다.
MemForest는 이 문제를 database indexing 언어로 번역한다. canonical fact는 write unit이고, MemTree는 temporal index이며, summary와 embedding은 source of truth가 아니라 derived artifact다.
이 분리가 실무적으로 중요하다. derived artifact를 source of truth로 삼으면 나중에 정책이 바뀌거나 오류가 발견됐을 때 전체 history를 다시 처리해야 한다.
반대로 persistent fact와 tree structure를 유지하면 필요한 path만 다시 요약하거나 embedding을 재생성할 수 있다.
또 하나의 포인트는 “좋은 메모리”가 하나의 최신 profile이 아니라 여러 시간 view의 조합이라는 점이다.
실제 assistant는 현재 선호만 알아도 되는 질문과, 과거 변경 이력을 알아야 하는 질문을 모두 받는다.
“지금 어디 살지?”
와 “그 전에 어디 있었지?”
는 같은 residence scope를 보지만 필요한 temporal interval이 다르다.
MemTree는 이 차이를 index 구조에 직접 넣는다.
다만 MemForest를 바로 production drop-in memory로 보는 것은 조심해야 한다. full rerun에는 model serving과 benchmark data가 필요하고, 현재 release는 tags/releases가 없는 연구 artifact다.
또한 query-time latency를 보면 MemForest는 Mem0처럼 단순한 retrieval보다 무겁다.
Table 3에서 Qwen3-30B 기준 MemForest total query latency는 4.60초, MemForest(emb)는 2.19초, Mem0는 0.22초다.
따라서 짧은 챗봇이나 단순 preference memory에는 과할 수 있다.
반대로 장기 세션, 다중 사용자, temporal update, memory freshness, auditability가 중요한 에이전트 시스템이라면 이 논문은 매우 실용적인 설계 기준을 준다.
결국 MemForest는 “더 긴 컨텍스트를 넣자”도 아니고 “더 좋은 벡터 검색을 쓰자”도 아니다.
장기 메모리를 계속 쓰이고 갱신되는 시간 인덱스로 보자는 제안이다.
에이전트가 며칠, 몇 주, 몇 달 동안 살아 있는 제품이 된다면, 이 write path와 temporal fidelity의 문제가 검색 모델만큼 중요해질 가능성이 높다.