로봇용 Vision-Language-Action(VLA) 모델에서 downstream adaptation은 피할 수 없다.
사전학습 데이터가 아무리 커져도 실제 배치 환경의 물체, 카메라, 조명, 작업 순서를 모두 덮기는 어렵기 때문이다.
문제는 가장 흔한 해법인 full fine-tuning이 pretrained model을 거의 “좋은 초기값”처럼 다룬다는 점이다.
제한된 데모에 맞춰 모든 경로를 업데이트하면 ID 성능은 빠르게 오르지만, 원래 사전학습에서 얻은 넓은 장면 이해와 모터 prior가 좁은 작업 분포 쪽으로 밀릴 수 있다.
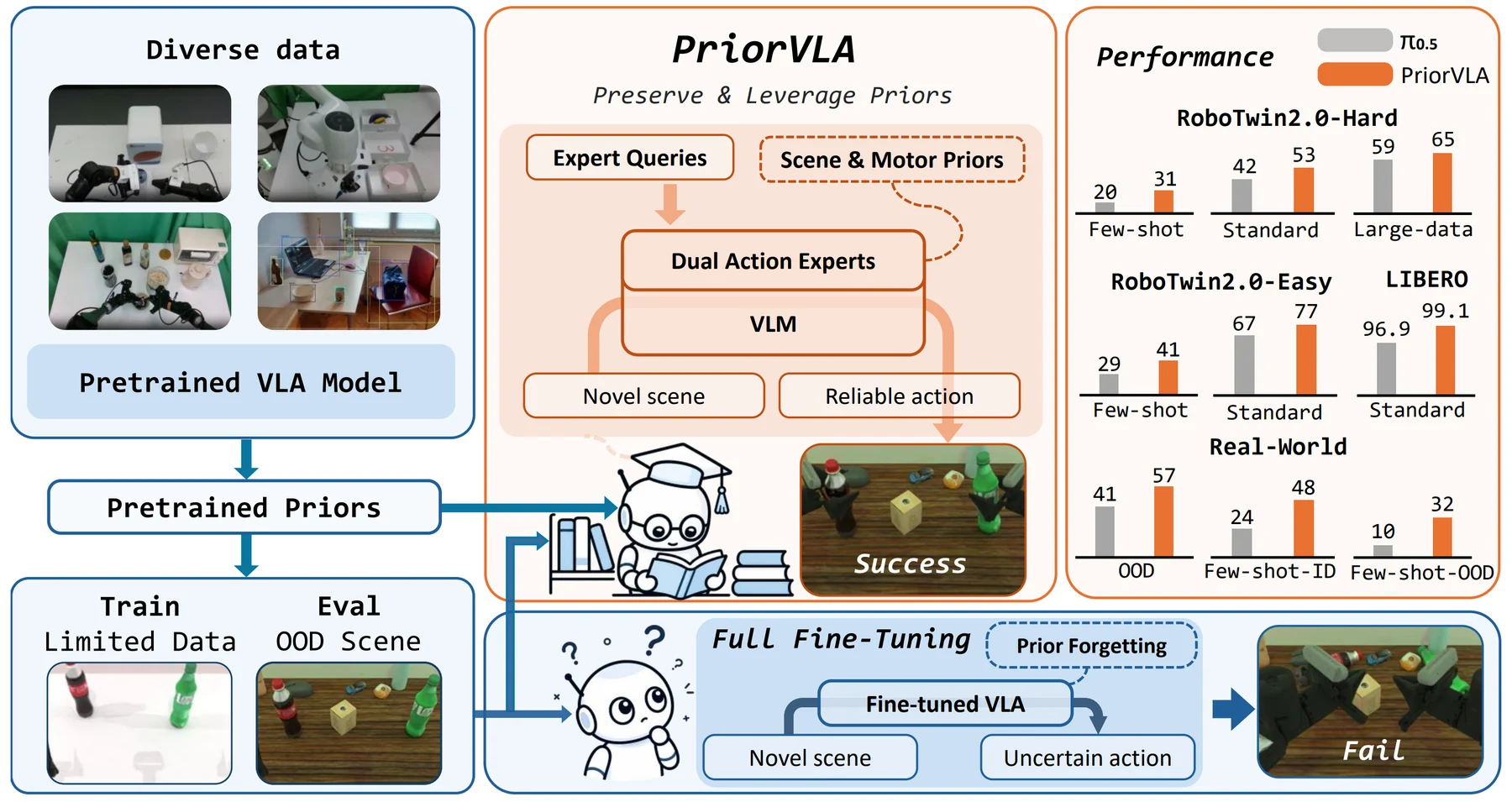
PriorVLA: Prior-Preserving Adaptation for Vision-Language-Action Models는 이 병목을 정면으로 다룬다.
논문의 핵심 주장은 단순하다.
큰 VLA의 사전학습은 초기화 값이 아니라, 적응 중에도 보존하고 참조해야 하는 read-only prior source라는 것이다.
PriorVLA는 기존 pretrained action expert를 얼려 둔 Prior Expert로 남기고, 별도의 Adaptation Expert만 downstream task에 맞게 학습한다.
그리고 Scene Query, Motor Query, Action Query라는 세 종류의 learnable interface가 frozen prior를 읽어와 적응 경로 안에 통합한다.
무엇을 해결하려는가
VLA adaptation의 어려움은 “새 작업을 잘 맞추는 것”과 “사전학습의 범용성을 잃지 않는 것”이 동시에 필요하다는 데 있다.
로봇 manipulation에서는 학습 데모가 대개 좁다.
같은 컵을 같은 조명에서 같은 위치 근처에 두고 반복 수집한 데이터는 특정 작업을 빠르게 학습시키지만, 배경이 바뀌거나 물체 위치가 흔들리거나 카메라 시야가 달라지는 순간 일반화가 약해질 수 있다.
기존 full fine-tuning은 이 trade-off를 구조적으로 피하기 어렵다. pretrained VLM과 action expert 전체가 downstream loss를 따라 움직이기 때문에, 모델 내부의 장면 prior와 모터 prior가 downstream data의 우연한 패턴에 과적합될 수 있다.
LoRA나 부분 fine-tuning은 업데이트 범위를 줄일 수는 있지만, pretrained forward-pass representation 자체를 별도 prior source로 보존하고 활용하는 구조는 아니다.
PriorVLA가 푸는 문제는 그래서 parameter efficiency만이 아니다.
논문은 적응을 “더 적은 파라미터를 업데이트하는 일”보다, 보존된 prior를 downstream policy가 어떻게 읽어 쓰게 만들 것인가로 재정의한다.
이 관점은 few-shot과 OOD 평가에서 특히 중요하다.
데이터가 부족하거나 평가 장면이 흔들릴수록, downstream 데모만으로는 일반화에 필요한 구조를 다시 학습하기 어렵기 때문이다.
핵심 아이디어 / 구조 / 동작 방식
PriorVLA의 구조는 두 개의 action expert와 세 종류의 query interface로 요약할 수 있다.
출발점은 flow-matching 기반 VLA다.
VLM은 observation과 instruction을 처리하고, action expert는 noisy action chunk를 denoising하면서 최종 action chunk를 만든다.
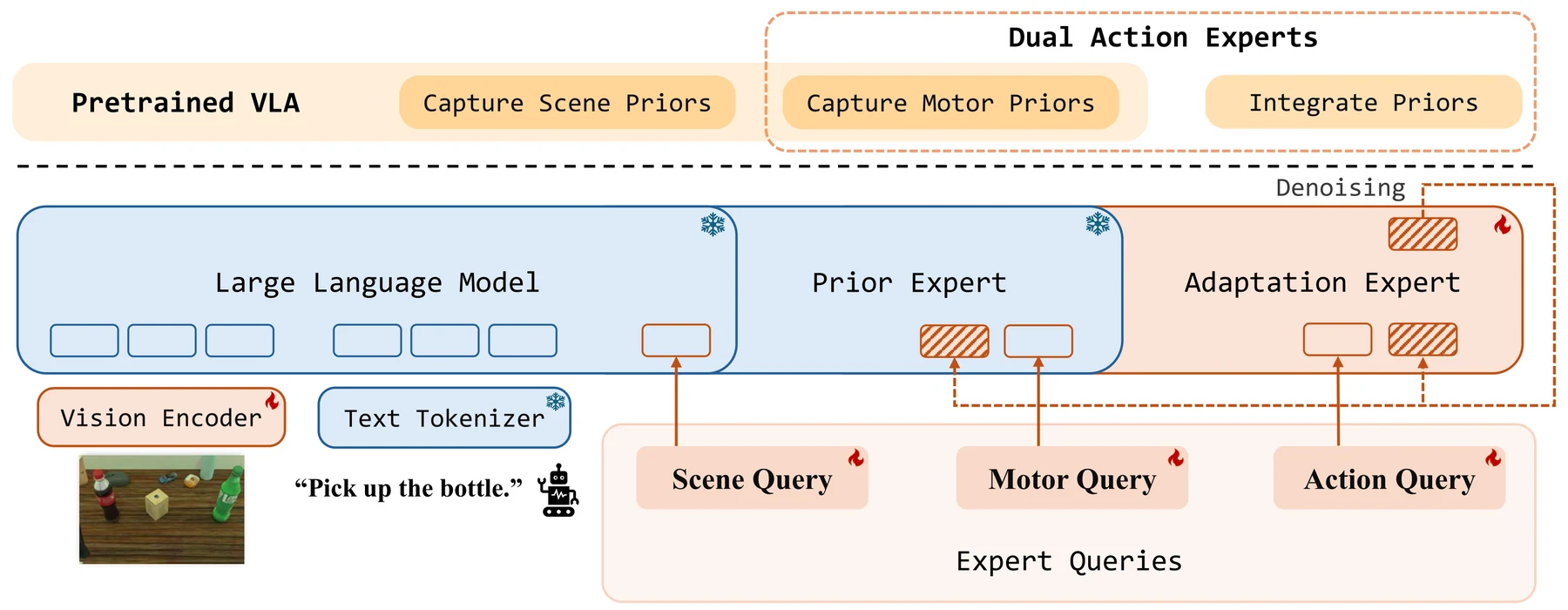
첫 번째 모듈은 Dual Action Experts다. pretrained action expert를 두 갈래로 복제한 뒤, 하나는 frozen Prior Expert로 유지하고 다른 하나는 trainable Adaptation Expert로 둔다.
두 expert는 같은 noisy action trajectory를 따라 실행되지만, 최종 action update에는 Adaptation Expert의 출력만 쓰인다.
Prior Expert의 denoising output은 버리고, 내부 representation만 motor prior로 읽는다.
즉 Prior Expert는 행동을 직접 결정하는 branch가 아니라, 사전학습된 action-generation dynamics를 보존한 read-only feature source다.
두 번째 모듈은 Expert Queries다.
| Query | 읽는 prior | 역할 |
|---|---|---|
| Scene Queries | pretrained VLM의 scene representation | downstream 장면에서 task-relevant visual prior를 압축 |
| Motor Queries | frozen Prior Expert의 denoising representation | 사전학습된 motor/action prior를 읽는 인터페이스 |
| Action Queries | Adaptation Expert 내부 경로 | scene prior와 motor prior를 action denoising에 통합 |
이 query들은 단순히 토큰을 더 붙이는 수준이 아니라 attention mask로 정보 흐름을 제한한다.
Prior Expert의 원래 action path는 query 때문에 오염되지 않도록 보존되고, Motor Query는 Prior Expert의 noisy action token을 읽되 VLM prefix에 직접 휩쓸리지 않게 설계된다.
Adaptation Expert는 Scene Query와 Motor Query의 key-value cache를 받아 action generation에 통합하지만, Prior Expert의 raw noisy-action state를 직접 복사하지 않는다.
논문은 이 우회가 안정성과 prior 활용에 중요하다고 설명한다.
훈련에서는 Adaptation Expert, 세 종류의 Expert Queries, VLM vision encoder만 업데이트하고, Prior Expert와 나머지 VLM 파라미터는 동결한다.
전체적으로 PriorVLA는 full fine-tuning이 업데이트하는 파라미터의 약 25%만 업데이트한다.
하지만 objective는 별도의 auxiliary loss가 아니라 표준 flow-matching MSE다.
Prior Expert나 query에 직접 supervision을 주는 것이 아니라, downstream action loss만으로 보존된 prior를 읽어 쓰는 경로를 학습한다.
공개된 근거에서 확인되는 점
실험 범위는 꽤 넓다.
논문은 RoboTwin 2.0의 13개 task subset, LIBERO 네 suite, 그리고 Franka single-arm과 AC-One dual-arm을 포함한 real-world 8개 task를 사용한다.
평가도 ID/Easy와 OOD/Hard, standard data와 few-shot, simulation과 real robot을 나눠 본다.

핵심 평균 성능만 정리하면 다음과 같다.
| 평가 설정 | PriorVLA | 주요 비교점 | 해석 |
|---|---|---|---|
| RoboTwin 2.0 standard Easy | 77% | π0.5 67% | ID에서도 +10p |
| RoboTwin 2.0 standard Hard | 53% | π0.5 42% | OOD에서 +11p |
| LIBERO 평균 | 99.1% | OpenVLA-OFT 97.1%, π0.5 96.9% | 포화된 benchmark에서도 소폭 개선 |
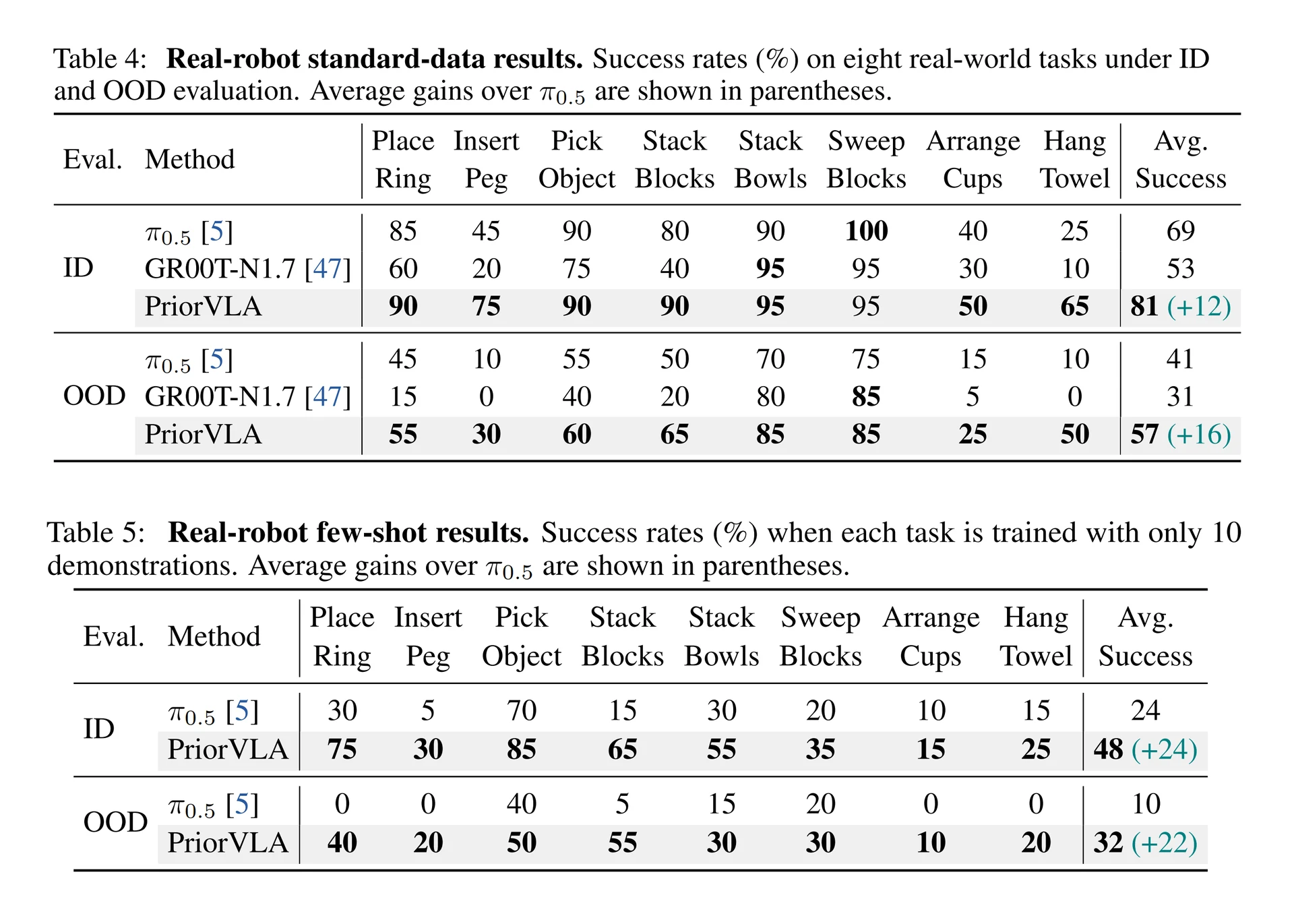
| Real robot standard ID / OOD | 81% / 57% | π0.5 69% / 41% | 실제 로봇에서 +12p / +16p |
| Real robot few-shot ID / OOD | 48% / 32% | π0.5 24% / 10% | 10 demos/task에서 +24p / +22p |
RoboTwin 2.0의 data scale 실험이 특히 중요하다. few-shot에서는 PriorVLA가 Easy 41%, Hard 31%로 π0.5의 29%, 20%를 앞선다. standard data에서도 77%, 53%로 π0.5의 67%, 42%를 넘는다. large-data에서는 Easy가 88%로 π0.5의 89%보다 1p 낮지만, Hard는 65%로 π0.5의 59%보다 높다.
즉 데이터가 충분해질수록 ID advantage는 줄어들 수 있지만, OOD advantage는 남는다는 메시지다.

LIBERO 결과는 이미 강한 baseline들이 많은 포화 영역에서 PriorVLA가 99.1% 평균을 기록했다는 점이 포인트다.
다만 여기서는 OOD robustness보다 standard benchmark의 상한에 가까운 개선으로 읽는 편이 맞다.
더 강한 신호는 real robot과 few-shot 쪽이다. standard-data real-world 실험에서 PriorVLA는 ID 81%, OOD 57%를 기록하고, 10 demonstrations per task few-shot에서는 ID 48%, OOD 32%를 기록한다.
OOD perturbation은 조명, background distractor, object position, table height 변화를 함께 적용한 설정이다.
Ablation도 논문의 주장을 비교적 잘 뒷받침한다.
RoboTwin 2.0 여섯 task subset에서 full PriorVLA는 Easy 77%, Hard 49%다.
Prior Expert를 제거하면 Hard가 42%로 내려가고, random frozen Prior Expert는 43%에 그친다.
Prior Expert를 trainable하게 만들어도 44%로 full보다 낮다.
이는 단순히 branch를 하나 더 붙이거나 파라미터 수를 줄인 효과가 아니라, pretrained prior를 frozen source로 보존하는 것이 중요하다는 근거다.

Expert Query 쪽도 같은 메시지를 낸다.
Scene/Motor/Action Query를 모두 제거하면 Easy 61%, Hard 28%까지 떨어진다.
개별 query 제거 중에서는 Scene Query 제거가 Hard 성능을 크게 낮추고, Motor Query나 Action Query 제거도 OOD 성능을 약화시킨다.
Frozen Prior Expert를 보존하는 것만으로는 충분하지 않고, 보존된 prior를 Adaptation Expert가 읽어 쓸 수 있는 learnable interface가 필요하다는 뜻이다.
공개 범위는 아직 연구 artifact에 가깝다.
프로젝트 페이지에는 Code (Soon) 링크가 있고, 공식 GitHub 저장소는 확인되지만 현재 README에는 “Code will be released soon”만 있다.
GitHub API 기준 저장소는 2026년 5월 11일 생성, stars 7, forks 0, release/tag 없음, license 필드 없음 상태다.
Hugging Face model/dataset 검색에서도 명확한 PriorVLA 배포는 확인되지 않았다.
따라서 현재는 논문·프로젝트 페이지·공식 이미지·초기 README가 중심 근거이며, 바로 재현 가능한 구현체 릴리스로 보기는 이르다.
실무 관점에서의 해석
PriorVLA의 가장 흥미로운 점은 로봇 VLA adaptation을 “얼마나 업데이트할 것인가”가 아니라 “무엇을 얼려 두고 어떻게 참조할 것인가”로 바꾼다는 데 있다. full fine-tuning은 단순하고 강력하지만, 제한된 데모가 pretrained representation을 좁힐 위험이 있다.
PriorVLA는 이 위험을 architecture 수준에서 분리한다.
하나의 branch는 계속 과거의 prior를 보존하고, 다른 branch만 현재 task를 배운다.
이 패턴은 로봇뿐 아니라 foundation model adaptation 전반에도 유용한 질문을 던진다.
실무에서는 종종 “adapter를 붙일까, full fine-tuning을 할까”를 업데이트 비용 관점에서만 고른다.
하지만 PriorVLA식 해석을 적용하면 더 중요한 질문은 “사전학습 모델의 어떤 forward-pass 정보를 read-only prior로 남겨 둘 것인가”가 된다.
특히 few-shot, domain shift, safety-critical control처럼 downstream data가 좁고 실패 비용이 큰 영역에서는 이 구분이 성능보다 운영 안정성에 더 큰 영향을 줄 수 있다.
물론 비용도 있다.
PriorVLA는 frozen Prior Expert를 denoising 중 함께 실행하므로 inference computation이 늘어난다.
논문은 action chunking control에서는 관리 가능한 overhead라고 설명하지만, latency budget이 빡빡한 로봇에서는 cached prior readout, lighter prior branch, selective invocation 같은 시스템 최적화가 필요할 수 있다.
또한 RoboTwin 2.0은 전체 50 task가 아니라 13 task subset이고, real-world OOD는 여러 perturbation을 함께 적용하기 때문에 각 요인의 독립 효과는 분리되지 않는다.
그래도 이 논문은 VLA adaptation 연구에서 좋은 방향을 제시한다.
앞으로 로봇 foundation model을 실전에 맞출 때 중요한 것은 pretrained model을 얼마나 강하게 덮어쓰느냐가 아니라, 사전학습이 만든 scene/motor prior를 얼마나 안정적으로 보존하고, downstream policy가 그것을 얼마나 잘 꺼내 쓰게 하느냐다.
PriorVLA는 그 원리를 Dual Action Experts와 Expert Queries라는 비교적 명확한 구조로 구현하고, OOD와 few-shot 결과로 설득력을 더한 사례다.