LLM 품질 경쟁은 더 큰 모델을 학습하는 문제만으로 설명되지 않는다.
실제 제품에서는 이미 선택한 모델을 어떻게 호출하고, 언제 여러 번 샘플링하며, 어떤 검증·검색·라우팅 단계를 붙일지가 체감 품질을 크게 바꾼다.
OptiLLM은 이 지점을 “모델을 바꾸지 않고 추론 시간에 더 계산한다”는 문제로 정리한 오픈소스 프록시다.
공식 README 기준 OptiLLM은 OpenAI API 호환 /v1/chat/completions 프록시로 동작한다.
기존 OpenAI 클라이언트의 base_url만 http://localhost:8000/v1로 바꾸고, 모델 이름 앞에 moa-, bon-, cepo- 같은 slug를 붙이면 요청이 여러 inference-time 기법을 통과한다.
핵심은 새로운 foundation model이 아니라, Best-of-N, Mixture of Agents, MCTS, PlanSearch, CePO, MARS, 메모리·프라이버시·MCP 같은 플러그인을 하나의 런타임 계층으로 묶었다는 점이다.
![]()
무엇을 해결하려는가
많은 팀은 모델을 직접 재학습하거나 fine-tuning하지 않고도 reasoning, coding, retrieval, 장문 컨텍스트 성능을 조금 더 끌어올리고 싶어 한다.
하지만 그 방법은 보통 개별 스크립트나 실험 코드로 흩어져 있다. self-consistency는 한쪽에, Mixture of Agents는 다른 harness에, 코드 실행·URL 읽기·MCP 연결은 또 다른 agent runtime에 들어간다.
그러면 실제 서비스에 붙일 때마다 SDK, 인증, 로깅, timeout, 비용 추적, 실패 처리를 다시 설계해야 한다.
OptiLLM이 푸는 문제는 바로 이 “추론 시간 최적화의 운영 표면”이다.
프록시가 OpenAI 호환 API를 유지하면, 기존 애플리케이션은 LLM provider를 직접 바꾸지 않고도 다양한 추론 전략을 시험할 수 있다. moa-gpt-4o-mini처럼 모델 이름 prefix로 기법을 고르거나, extra_body의 optillm_approach 필드, 혹은 <optillm_approach>...</optillm_approach> 태그로 접근 방식을 지정하는 식이다.
이 구조는 특히 두 종류의 팀에 유용하다.
첫째, 작은 모델이나 저렴한 API 호출을 여러 번 조합해 frontier-class 응답에 가까워지는지 실험하려는 팀이다.
둘째, agentic workflow 안에서 “검색하고, 기억하고, 익명화하고, 구조화하고, 여러 후보를 평가하는” 런타임 정책을 일관된 API 뒤에 숨기려는 팀이다.
핵심 아이디어 / 구조 / 동작 방식
OptiLLM의 기본 구조는 단순하다.
사용자의 기존 코드나 도구가 OpenAI 호환 요청을 보내면, OptiLLM 서버가 그 요청을 받아 선택된 approach를 실행하고, 다시 OpenAI·Cerebras·Azure OpenAI·LiteLLM·로컬 Hugging Face 모델 등으로 넘긴다.
공식 sequence diagram도 이 점을 강조한다.
클라이언트 입장에서는 endpoint가 바뀌었을 뿐이고, 중간 프록시가 하나 이상의 base model call을 orchestrate한다.
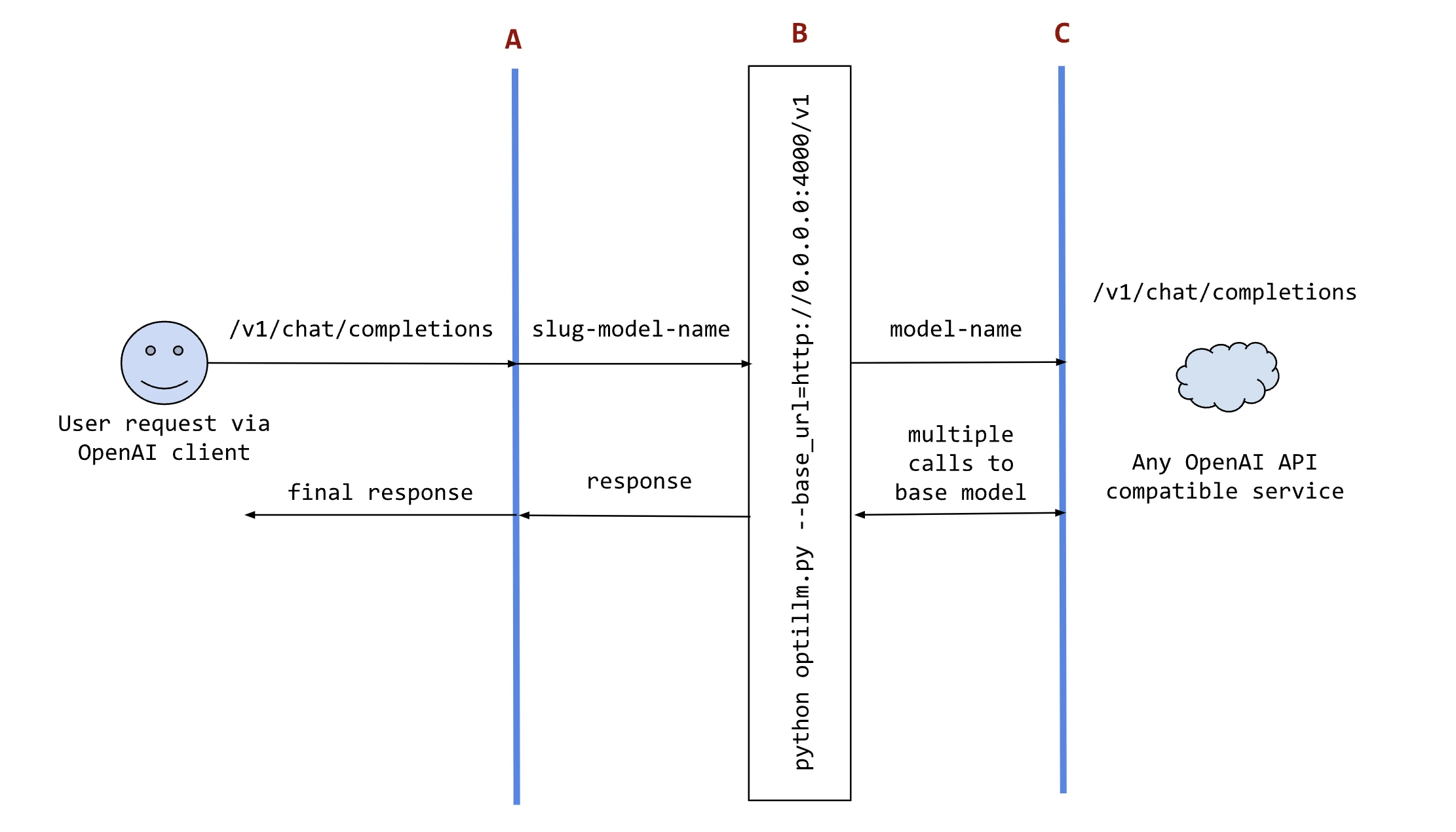
구현상 흥미로운 부분은 approach 조합 방식이다.
단일 prefix만 쓰는 것이 아니라 cot_reflection&moa처럼 &를 쓰면 앞 단계 응답을 다음 단계 입력으로 넘기는 pipeline이 되고, bon|moa|mcts처럼 |를 쓰면 여러 approach를 병렬로 실행해 복수 응답을 돌려주는 구조가 된다.
즉 OptiLLM은 단일 알고리즘 구현체라기보다, 추론 시간 정책을 문자열과 request config로 조립하는 작은 runtime DSL에 가깝다.
공식 README와 코드에서 확인되는 범위는 꽤 넓다.
| 계층 | 대표 기능 | 실무적 의미 |
|---|---|---|
| 샘플링·투표 | Best-of-N, self-consistency, majority voting, Mixture of Agents | 여러 후보를 만들고 검증·집계해 단일 호출의 우연성을 줄인다 |
| 탐색·계획 | MCTS, R*, PlanSearch, CePO, MARS | 수학·코딩·논리 문제처럼 탐색 공간이 있는 task에 더 많은 inference compute를 배정한다 |
| 디코딩·로컬 추론 | CoT decoding, entropy decoding, AutoThink, LoRA 조합 | 로컬 Hugging Face 모델을 직접 띄우거나 token uncertainty 기반 전략을 실험한다 |
| 플러그인 | MCP, memory, privacy, readurls, execute code, JSON, proxy, compact | 모델 호출 전후에 도구·메모리·보안·구조화·라우팅 기능을 붙인다 |
| 운영 표면 | pip, Docker, proxy-only/offline image, optional API key, localhost default | 실험 스크립트가 아니라 프록시 서비스 형태로 배치할 수 있다 |
다만 이 폭넓음은 장점이자 부담이다.
README에는 “20+ optimization techniques”와 “100+ models via LiteLLM”이라는 메시지가 전면에 있지만, 실제 채택 관점에서는 어떤 approach가 어떤 provider에서 동작하는지, 몇 번의 추가 호출을 만드는지, timeout과 비용이 어떻게 증가하는지를 따로 검증해야 한다.
예를 들어 README는 Anthropic API, llama.cpp-server, ollama가 여러 응답 샘플링을 지원하지 않아 일부 approach로 제한된다고 명시한다.
공개된 근거에서 확인되는 점
GitHub API 기준 이 저장소는 algorithmicsuperintelligence/optillm 아래 공개되어 있고, Python 프로젝트이며 Apache-2.0 라이선스를 갖는다.
작성 시점 API 값으로는 약 3.8k stars, 317 forks, 22 open issues가 확인된다.
최신 release와 PyPI 버전은 모두 v0.3.15 / 0.3.15이고, PyPI 메타데이터는 Python >=3.10을 요구한다.
최신 release note에는 ARM64에서 Z3 solver build를 고치는 변경과 자동 context compression용 compact 플러그인이 포함되어 있다.
배포 표면도 단순 README 수준을 넘어선다. pyproject.toml은 optillm=optillm:main console script를 제공하고, Dockerfile은 full, proxy-only, offline 이미지를 구분한다.
Hugging Face에는 Gradio SDK 기반 OptiLLM Space가 있고, router plugin이 사용하는 codelion/optillm-modernbert-large 모델도 Apache-2.0 태그와 함께 공개되어 있다.
즉 “아이디어 문서”라기보다는 pip 패키지, 컨테이너, 데모, 보조 모델을 함께 가진 실행 가능한 프록시 프로젝트로 보는 편이 맞다.
성능 근거는 대부분 공식 README의 자체 benchmark table에 의존한다.
따라서 수치를 그대로 일반화하기보다는 “프로젝트가 보고한 결과”로 읽어야 한다.
그래도 방향성은 분명하다.
README는 MARS가 Gemini 2.5 Flash Lite 기반 AIME 2025에서 43.3%에서 73.3%로 올라갔다고 보고하고, CePO는 Qwen3 32B 기준 AIME 2025 72.9에서 83.3, LiveCodeBench 65.7에서 71.9로 개선됐다고 제시한다.
LongCePO는 8K context로 LongBench/InfiniteBench류 장문 문제에서 full-context baseline과 경쟁하는 결과를 강조한다.
| 공개 근거 | 확인되는 내용 | 해석 |
|---|---|---|
| GitHub README | OpenAI 호환 프록시, 20개 이상 approach, LiteLLM 기반 multi-provider 지원 | 기존 클라이언트와 provider를 최대한 유지하면서 inference policy를 끼워 넣는 설계 |
| GitHub API / release | v0.3.15, Apache-2.0, 최근 compact plugin과 Z3 ARM64 build fix |
활발히 유지되는 Python 서비스형 프로젝트 |
| PyPI | optillm 0.3.15, Python >=3.10, console script 제공 |
로컬 실험보다 쉬운 설치 경로 존재 |
| Hugging Face Space | Gradio 데모, CPU basic runtime, Apache-2.0 card metadata | 프로젝트가 공개 demo surface를 운영 중 |
| README benchmark | MARS, CePO, AutoThink, LongCePO, MOA, PlanSearch 결과 제시 | 일부 task에서 추가 inference compute가 정확도 개선으로 이어질 수 있음을 주장 |
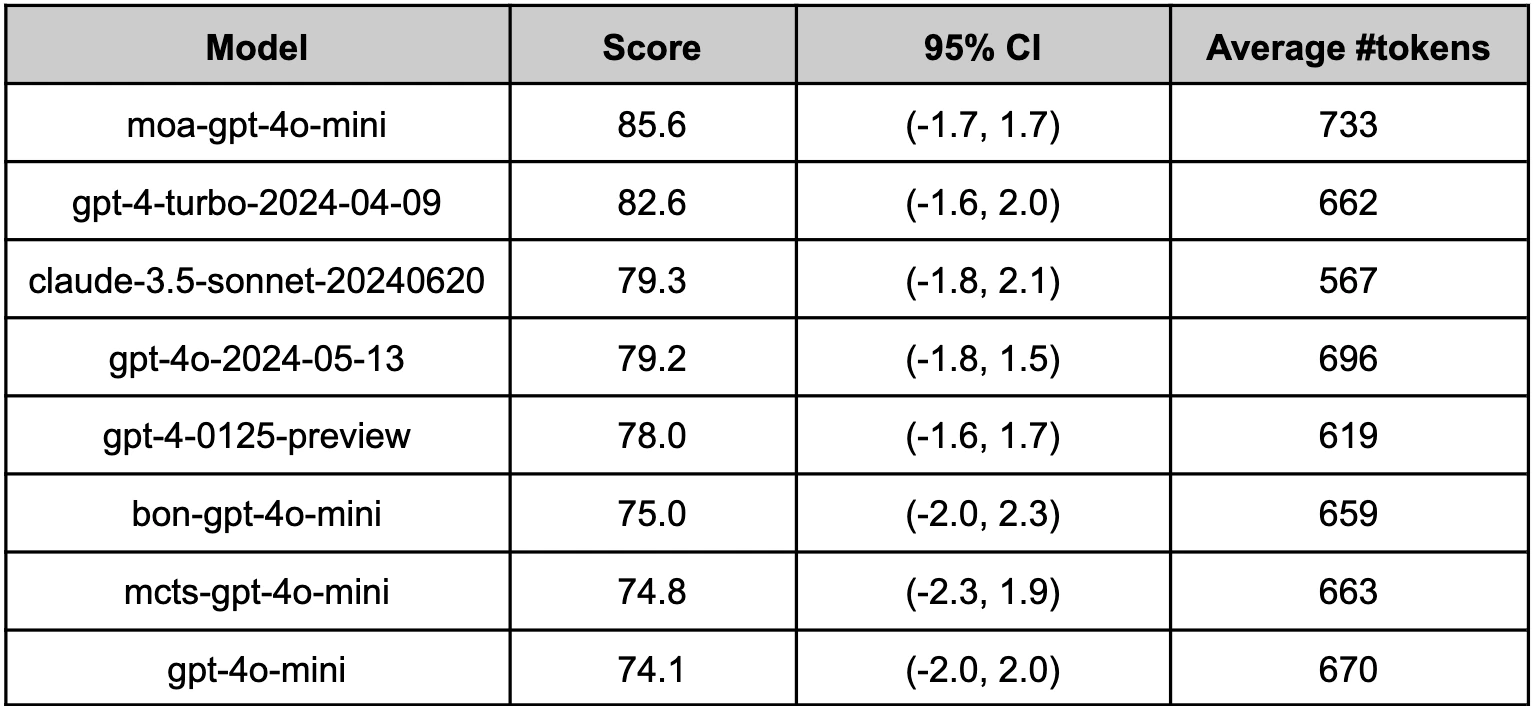
공식 이미지 중에서는 Mixture of Agents 관련 표가 가장 직접적이다.
README는 moa-gpt-4o-mini가 Arena-Hard-Auto에서 gpt-4-turbo-2024-04-09, claude-3.5-sonnet-20240620, gpt-4o-2024-05-13보다 높은 score를 낸 예시를 싣고 있다.
이 수치는 오래된 benchmark snapshot이라는 점을 감안해야 하지만, OptiLLM이 말하는 “작은 모델을 여러 번 조합해 강한 응답을 만든다”는 thesis를 가장 쉽게 보여준다.
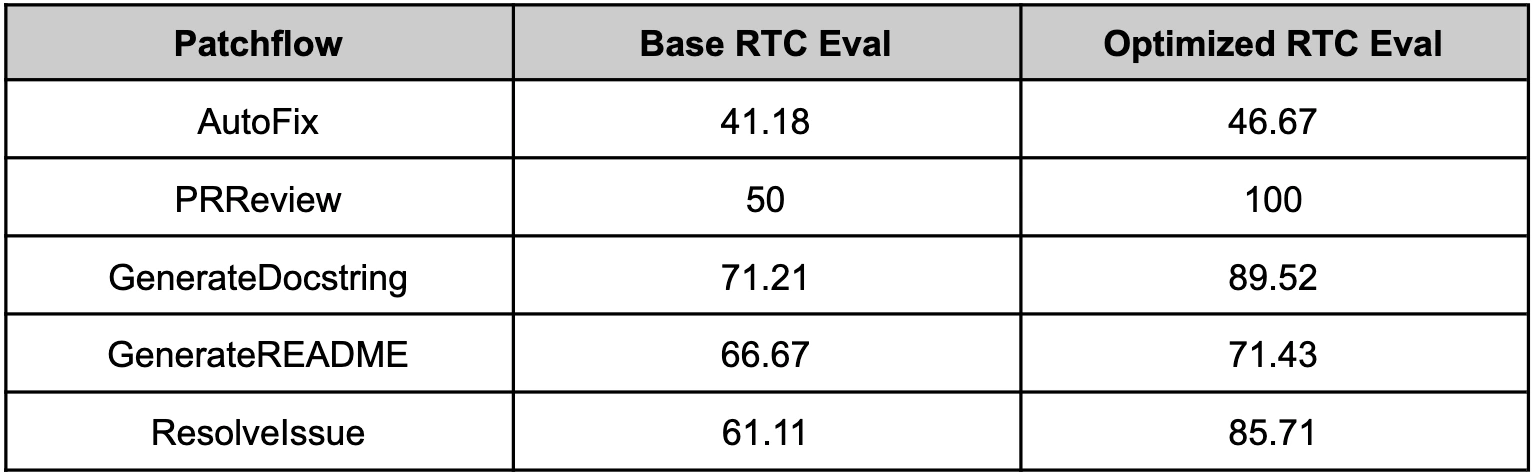
또 다른 이미지는 Patchwork와 결합한 결과다.
AutoFix, PRReview, GenerateDocstring, GenerateREADME, ResolveIssue 같은 software development workflow에서 base RTC eval 대비 optimized RTC eval이 올라간 표를 제공한다.
여기서 중요한 점은 절대 점수보다 적용 범위다.
OptiLLM은 단순 chat benchmark보다, PR review·bug fixing·문서 생성 같은 agentic software workflow에 inference-time 조합을 끼워 넣는 사용 사례를 밀고 있다.
실무 관점에서의 해석
내가 보기에 OptiLLM의 가장 중요한 의미는 “추론 최적화 기법 모음”이 아니라 “추론 정책을 서비스 경계로 끌어올린다”는 데 있다. self-consistency나 MoA 자체는 새로운 아이디어가 아니다.
하지만 이것들을 OpenAI 호환 프록시로 감싸면, 애플리케이션 코드와 실험 정책을 분리할 수 있다.
오늘은 moa- prefix를 붙이고, 내일은 cepo-나 compact&moa-를 시험해도 클라이언트 통합 방식은 거의 그대로 유지된다.
이 접근은 agent 시스템과 잘 맞는다.
Agent는 이미 한 번의 모델 호출보다 여러 번의 관찰·계획·도구 사용·검증 루프에 의존한다.
OptiLLM은 그 루프 중 일부를 application logic이 아니라 inference proxy 레이어로 밀어 넣는다.
특히 MCP, memory, privacy, readurls, execute code, JSON structured output, proxy routing 같은 플러그인이 함께 들어간다는 점은 OptiLLM이 단순 “정확도 향상 wrapper”보다 agent runtime 쪽으로 확장되고 있음을 보여준다.
반대로 운영 리스크도 명확하다.
여러 approach는 본질적으로 추가 모델 호출을 만든다.
정확도가 오르더라도 latency, token cost, rate limit, failure surface가 함께 늘어난다.
또한 readurls, executecode, mcp, web_search, privacy 같은 플러그인은 외부 네트워크, 코드 실행, 민감정보 처리와 맞닿아 있으므로 기본값 그대로 공개망에 노출할 성격의 기능이 아니다.
코드상 기본 host가 127.0.0.1인 점은 안전한 출발점이지만, 외부 접근을 열 때는 --optillm-api-key, reverse proxy, 네트워크 경계, 로그 정책을 별도로 설계해야 한다.
채택 체크리스트는 비교적 분명하다.
| 질문 | OptiLLM이 맞는 경우 | 주의할 경우 |
|---|---|---|
| task가 여러 후보 생성·검증에서 이득을 보나 | 수학, 코드, reasoning, 장문 QA, agentic workflow | 단순 FAQ나 짧은 extraction처럼 추가 호출 이득이 작을 때 |
| 비용·지연을 감당할 수 있나 | 정확도나 안정성이 latency보다 중요할 때 | 실시간 UI, 낮은 단가, 엄격한 rate limit이 우선일 때 |
| provider가 필요한 기능을 지원하나 | OpenAI 호환 endpoint, LiteLLM, 로컬 HF 모델을 쓸 때 | 여러 샘플링을 지원하지 않는 provider에서 일부 approach가 막힐 때 |
| 플러그인 권한을 통제할 수 있나 | 내부 네트워크와 명확한 sandbox/logging이 있을 때 | URL fetch, code execution, MCP tool 접근을 무제한 허용할 때 |
결론적으로 OptiLLM은 “더 똑똑한 모델 하나”가 아니라 “같은 모델을 더 영리하게 호출하는 runtime layer”다.
모든 요청에 켜 두는 만능 가속기라기보다는, 실패 비용이 크고 검증 가능한 task에서 inference-time compute를 선택적으로 쓰는 실험·운영 프록시로 보는 편이 건강하다.
LLM 제품이 점점 agentic workflow와 결합될수록, 이런 프록시형 추론 정책 계층은 모델 serving stack의 중요한 구성요소가 될 가능성이 크다.