작은 언어모델을 에이전트로 만들 때 가장 어려운 지점은 “추론을 길게 한다”보다 “도구를 잘못 부른 뒤에도 학습 신호가 망가지지 않게 한다”에 가깝다.
수학 문제를 풀다가 Python code interpreter를 호출하고, 그 결과를 다시 읽어 다음 step을 이어가는 구조에서는 한 번의 잘못된 tool call이 이후 문맥 전체를 비틀 수 있다.
이 상태에서 큰 teacher 모델의 token-level 분포를 그대로 따라 하게 만들면, teacher supervision은 더 이상 깨끗한 지도가 아니라 잘못된 상태 위에서 나온 불안정한 신호가 된다.
SOD: Step-wise On-policy Distillation for Small Language Model Agents는 이 문제를 온폴리시 증류의 실패 모드로 정의한다.
기존 OPD(On-policy Distillation)는 학생 모델이 직접 만든 trajectory 위에서 teacher의 dense token-level supervision을 제공한다는 점에서 exposure bias를 줄일 수 있다.
하지만 tool-integrated reasoning(TIR)에서는 학생의 오류가 tool observation을 통해 다음 상태에 삽입되고, 그 결과 student-teacher distribution gap이 step을 거치며 커진다.
SOD의 핵심은 간단하다.
모든 step에 같은 증류 가중치를 주지 말고, 학생과 teacher가 얼마나 벌어졌는지를 step 단위로 측정해 distillation loss의 세기를 조절한다.
학생이 teacher와 잘 맞는 상태에서는 dense supervision을 유지하고, tool-induced state drift가 커진 구간에서는 teacher 신호를 약하게 만든다.
논문은 이 방법이 Qwen3 0.6B/1.7B 학생 모델에서 OPD, GRPO, SFT, self-distillation 계열 baseline보다 안정적인 성능 향상을 만든다고 보고한다.
무엇을 해결하려는가
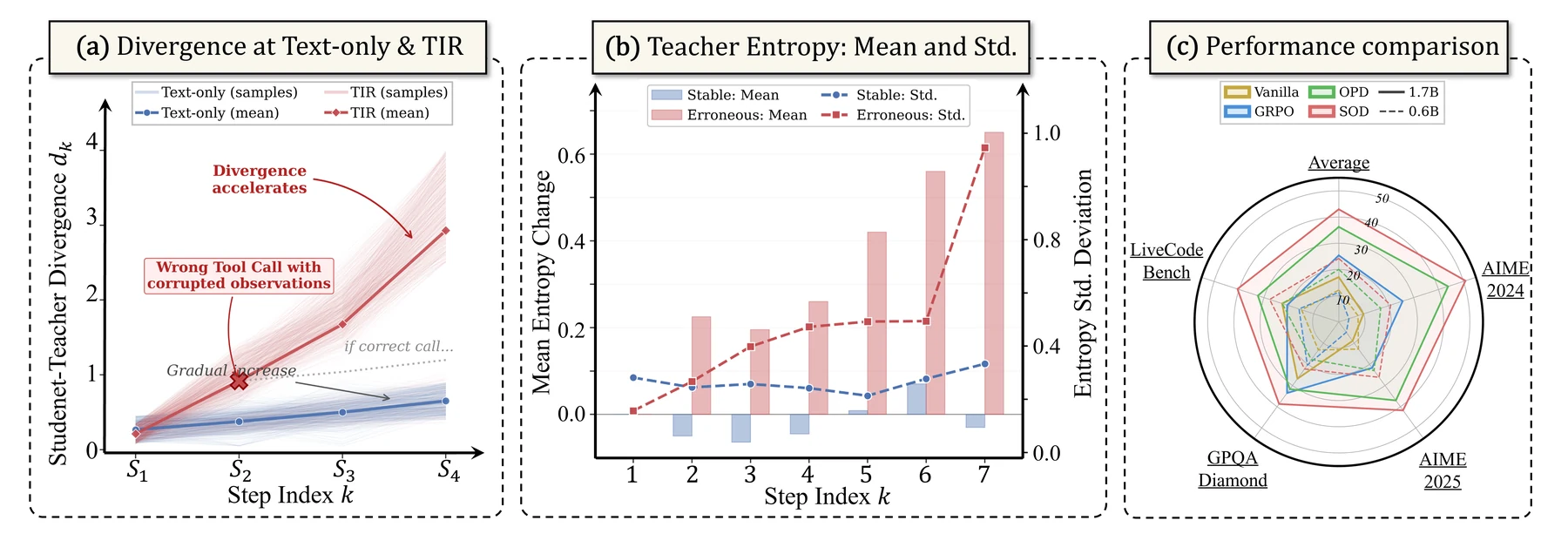
Tool-integrated reasoning은 일반적인 text-only reasoning보다 학습 신호가 더 쉽게 깨진다.
텍스트만 생성하는 경우 학생이 조금 틀려도 다음 token 분포의 drift는 비교적 완만하게 누적된다.
반면 도구 사용 에이전트에서는 잘못된 tool call이 외부 관측값을 문맥에 주입한다.
그 관측값이 틀리면 이후 reasoning step 전체가 teacher가 예상하지 않은 상태로 이동한다.
이때 vanilla OPD의 약점이 드러난다.
OPD는 학생이 만든 trajectory 위에서 teacher distribution과 student distribution의 차이를 줄이도록 학습한다.
평상시에는 좋은 설계다.
학생이 실제 inference 때 겪게 될 상태에서 dense supervision을 받기 때문이다.
하지만 TIR에서는 학생이 이미 깨뜨린 상태에 teacher를 조건부로 붙이는 순간, teacher의 token-level supervision 자체가 “좋은 정답으로 가는 지도”인지 “오염된 상태에서의 사후 대응”인지 불명확해진다.
논문은 이 현상을 두 가지로 설명한다.
- discontinuous divergence amplification: tool error 하나가 긴 observation을 통해 다음 reasoning state를 불연속적으로 바꾸고, 연속된 tool error는 divergence를 super-linear하게 키운다.
- gradient SNR degradation: 학생 분포와 teacher-supported region의 overlap이 낮아지면 OPD gradient의 신호대잡음비가 급격히 나빠진다.
즉 문제는 “작은 모델이 teacher를 충분히 못 따라 한다”만이 아니다.
더 구체적으로는 학생이 만든 잘못된 tool state 위에서 teacher를 무조건 따라 하게 만드는 것이 오히려 해로운 gradient를 키운다는 점이다.
핵심 아이디어 / 구조 / 동작 방식
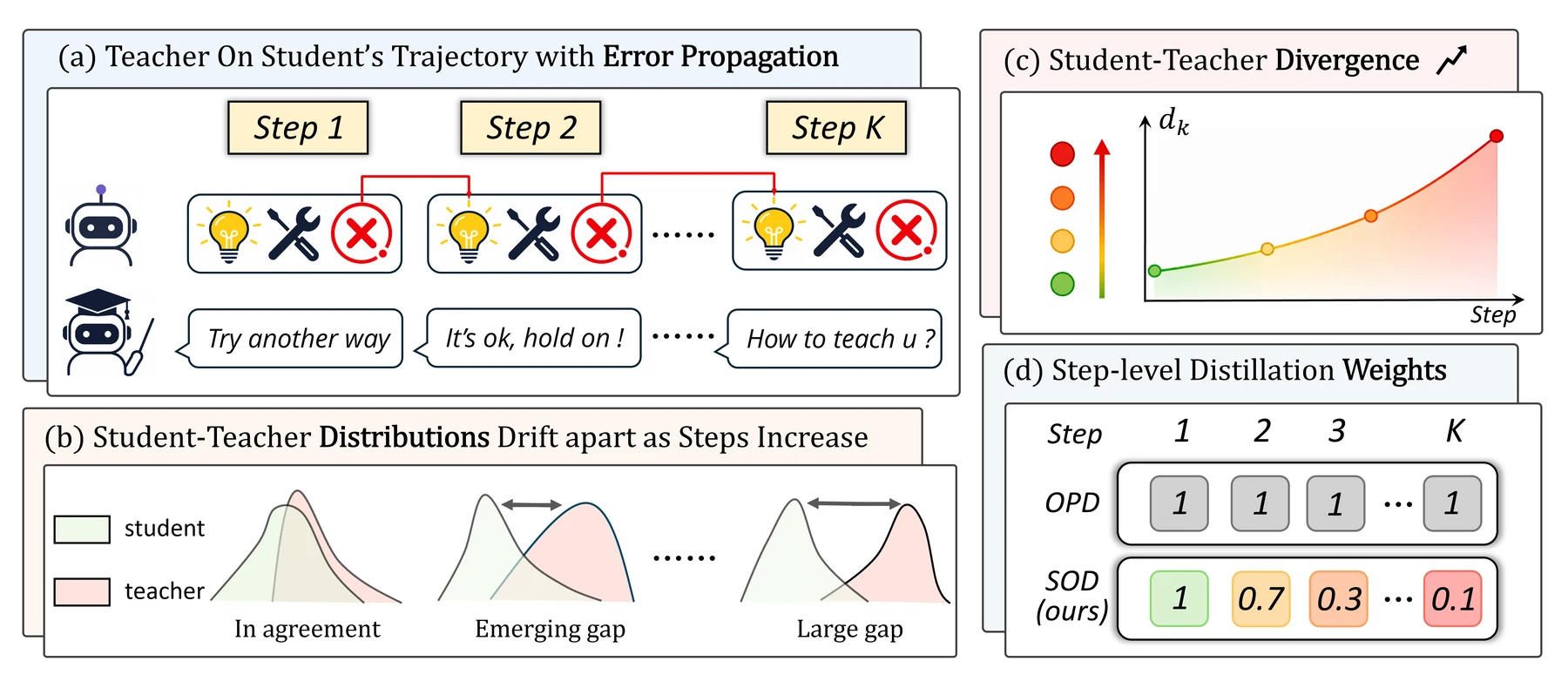
SOD는 trajectory를 여러 reasoning step으로 나눈다.
각 step은 두 tool observation 사이의 모델 응답이거나 최종 답변 구간이다. tool observation 자체는 외부 환경이 만든 token이므로 loss에서 제외하고, 모델이 생성한 token 위치만 step 집합으로 본다.
각 step k에 대해 SOD는 student와 teacher의 log-prob 차이를 평균낸 divergence score d_k를 계산한다.
직관적으로 d_k가 작으면 학생이 teacher와 비슷한 상태에 있고, d_k가 크면 tool call이나 중간 reasoning 오류 때문에 두 분포가 멀어진 상태다.
그 다음 SOD는 step별 distillation weight w_k를 만든다.
- 첫 step은
w_1 = 1로 둔다. - 이후 step은 이전 divergence와 현재 divergence의 비율을 누적해 조절한다.
- divergence가 커지는 구간에서는 weight가 내려가고, 다시 teacher와 가까워지는 recovery 구간에서는 weight가 회복된다.
- 논문 구현에서는
epsilon = 1e-6, upper-bound offsetdelta = 0.2를 사용해w_k <= 1.2로 clipping한다.
이 설계가 중요한 이유는 filtering이 아니라 reweighting이라는 점이다. trajectory 전체를 버리거나, 틀린 이후 모든 step을 masking하는 방식은 너무 거칠다.
실제 agent trajectory에서는 앞부분은 틀렸지만 뒤에서 회복하는 경우도 있고, 반대로 정답 trajectory 안에서도 특정 tool step만 teacher와 크게 벌어질 수 있다.
SOD는 step 단위로 loss를 조절하기 때문에 stable, erroneous, recovery 구간을 다르게 다룰 수 있다.
최종 objective는 GRPO와 step-wise OPD를 합친 형태다.
GRPO는 sequence-level reward로 탐색 방향을 제공하고, step-wise OPD는 token-level supervision을 제공하되 divergence에 따라 신뢰도를 조절한다.
따라서 SOD는 순수 RL 방법이라기보다, outcome-level reward와 dense teacher supervision 사이에 reliability gate를 넣은 post-training recipe로 보는 편이 정확하다.
논문과 공개 README 기준 학습 설정도 비교적 구체적이다.
SFT에는 s1-1k, LeetCode, ReTool에서 온 3K multi-turn reasoning trajectory가 쓰이고, RL/distillation에는 DAPO-Math, Skywork-or1, MegaScience 등을 포함한 약 30K 데이터가 사용된다.
평가 benchmark는 AIME 2024, AIME 2025, GPQA-Diamond, LiveCodeBench이며, temperature 1.0, top_p 0.6에서 문제당 32개 sample을 생성해 average@32를 보고한다.
공개된 근거에서 확인되는 점
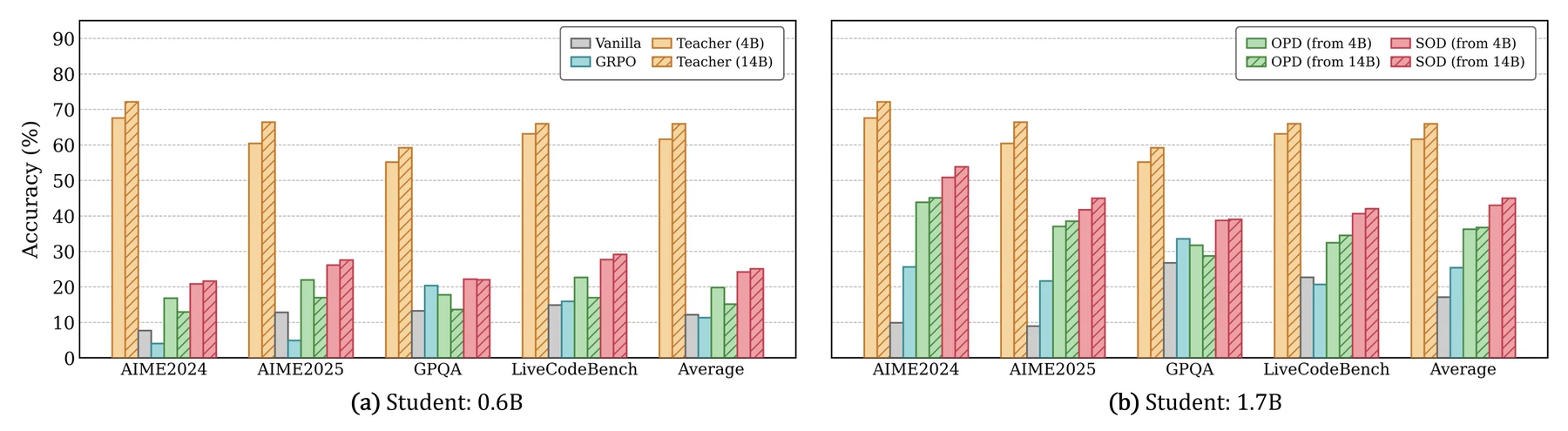
가장 직접적인 결과는 Qwen3 계열 teacher/student 비교다. teacher는 GRPO로 추가 최적화한 Qwen3-4B이고, 학생은 Qwen3-0.6B와 Qwen3-1.7B다.
논문은 모든 결과를 5회 run 평균으로 보고한다.
| 모델 크기 | 비교 기준 | Average@32 | AIME 2025 | LiveCodeBench | 해석 |
|---|---|---|---|---|---|
| 0.6B | Vanilla | 12.16 | 12.81 | 14.89 | 작은 base model의 TIR 성능은 낮음 |
| 0.6B | GRPO | 11.32 | 4.90 | 15.95 | sparse reward만으로는 0.6B에서 불안정 |
| 0.6B | OPD | 20.04 | 22.95 | 22.65 | dense teacher supervision이 큰 폭으로 도움 |
| 0.6B | SOD | 24.22 | 26.13 | 27.72 | OPD 대비 평균 상대 개선 20.86% |
| 1.7B | GRPO | 25.39 | 21.67 | 20.70 | RL baseline은 과학/코딩 일부에서 제한적 |
| 1.7B | OPD | 36.27 | 37.04 | 32.45 | 강한 baseline |
| 1.7B | SOD | 42.98 | 41.72 | 40.63 | OPD 대비 평균 상대 개선 18.50% |
| 4B teacher | GRPO | 61.59 | 60.42 | 63.13 | 학생 모델의 상한 참조점 |
이 표에서 중요한 부분은 SOD가 단순히 “teacher를 더 오래 따라 한” 방법이 아니라는 점이다.
0.6B에서는 SFT와 GRPO가 Vanilla보다 오히려 평균이 낮거나 비슷한 반면, OPD와 SOD는 크게 오른다.
즉 작은 모델에는 dense supervision이 필요하다.
하지만 OPD만으로는 tool-induced drift 구간을 구분하지 못하므로, SOD가 그 위에 step-wise reliability 조절을 얹어 추가 이득을 얻는다.
1.7B 결과도 같은 패턴을 보인다.
논문은 1.7B SOD가 4B teacher 평균 성능의 69.8%를 회복한다고 해석한다.
OPD는 58.9% 수준이다.
완전한 teacher 압축은 아니지만, 1.7B 학생이 더 큰 teacher의 tool-using reasoning 능력을 꽤 많이 흡수한다는 신호다.
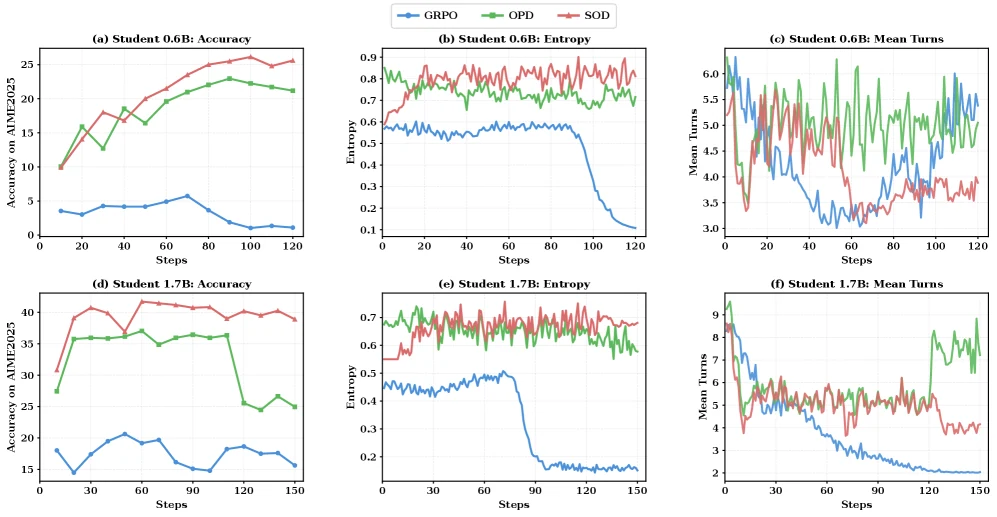
Ablation도 방법론의 핵심을 뒷받침한다.
1.7B 학생에서 full SOD 평균은 42.98이다.
반면 uniform weighting은 34.70, heuristic weighting은 37.14, 틀린 뒤 masking하는 방식은 31.85, weight clipping 제거는 38.10에 그친다.
특히 w/o Step-wise OPD는 사실상 GRPO baseline으로 평균 25.39이며, w/o GRPO도 40.78로 full SOD보다 낮다.
이를 실무적으로 읽으면 다음과 같다.
| 구성 요소 | 결과 패턴 | 의미 |
|---|---|---|
| Uniform weighting | 평균 34.70 | OPD식 균일 증류는 high-divergence step을 과하게 학습할 수 있음 |
| Heuristic weighting | 평균 37.14 | 손으로 만든 rule은 일부 도움되지만 divergence 기반 적응보다 약함 |
| Mask after wrong | 평균 31.85 | 오류 이후를 통째로 버리면 recovery step의 유효 supervision도 잃음 |
| w/o GRPO | 평균 40.78 | step-wise OPD만으로도 강하지만 outcome-level reward가 보완적 역할을 함 |
| Full SOD | 평균 42.98 | step-wise reweighting과 GRPO의 결합이 가장 안정적 |
학습 비용 측면에서도 SOD는 OPD 대비 큰 추가 overhead를 만들지 않는다고 보고된다.
0.6B에서는 OPD가 1090.5초/step, SOD가 1052.3초/step이고, 총 학습 시간은 각각 36.4h와 35.1h다.
1.7B에서는 OPD 1053.6초/step, SOD 1105.4초/step, 총 43.9h와 46.1h다.
GRPO만 쓰는 경우보다 비싸지만, OPD forward pass에서 이미 계산한 log-prob를 재사용하므로 step-wise divergence 계산 자체가 별도 대형 모델 호출을 요구하지는 않는다.
공개 release도 확인할 만하다. arXiv HTML과 README는 공식 GitHub 저장소 YoungZ365/SOD를 연결한다.
GitHub API 기준 이 저장소는 2026년 5월 8일 생성됐고, 조회 시점 stars 113, forks 3, Apache-2.0 license metadata가 확인된다. releases와 tags는 비어 있어 versioned package라기보다는 초기 연구 코드 release에 가깝지만, README에는 환경 설치, SFT, SOD training, SandboxFusion 설정, AIME/GPQA/LiveCodeBench 평가 스크립트가 정리돼 있다.
Hugging Face 쪽도 논문 결과를 재현/검토하는 데 중요한 신호다. youngzhong/sod collection에는 SOD-0.6B, SOD-1.7B, SOD-GRPO_teacher-4B가 공개돼 있고, 모델 API 기준 모두 gated가 아니며 Apache-2.0 license tag와 safetensors 파일을 포함한다.
0.6B와 1.7B 모델은 각각 Qwen3-0.6B, Qwen3-1.7B 기반 fine-tune으로 표시되고, teacher는 Qwen3-4B 기반 GRPO 모델로 표시된다.
현재 API 값으로 downloads는 SOD-0.6B 33, SOD-1.7B 29, teacher 33 수준이라 아직 초기 배포 상태다.
실무 관점에서의 해석
SOD의 가장 실용적인 메시지는 작은 agent model을 만들 때 “정답/오답 trajectory”보다 더 세밀한 단위가 필요하다는 점이다.
도구 사용 에이전트는 하나의 response 안에서도 reliable step과 corrupted step이 섞인다.
전체 trajectory를 성공/실패로만 보거나, 모든 token에 같은 teacher loss를 주면 학습 신호가 너무 거칠어진다.
이 관점은 앞으로 small agent distillation에 꽤 중요해질 수 있다.
대형 reasoning model을 매번 호출하는 대신 작은 모델에 tool-use 능력을 옮기려는 팀은 많다.
하지만 에이전트 distillation은 일반 instruction distillation과 다르다. tool call, observation, intermediate state가 모두 학습 분포를 바꾸며, 작은 학생은 그 중 하나만 틀려도 뒤쪽 step의 supervision quality가 달라진다.
SOD는 이 문제를 “teacher 신호를 더 많이 주자”가 아니라 “어떤 step에서 teacher 신호를 믿을 수 있는지 추정하자”로 재정의한다.
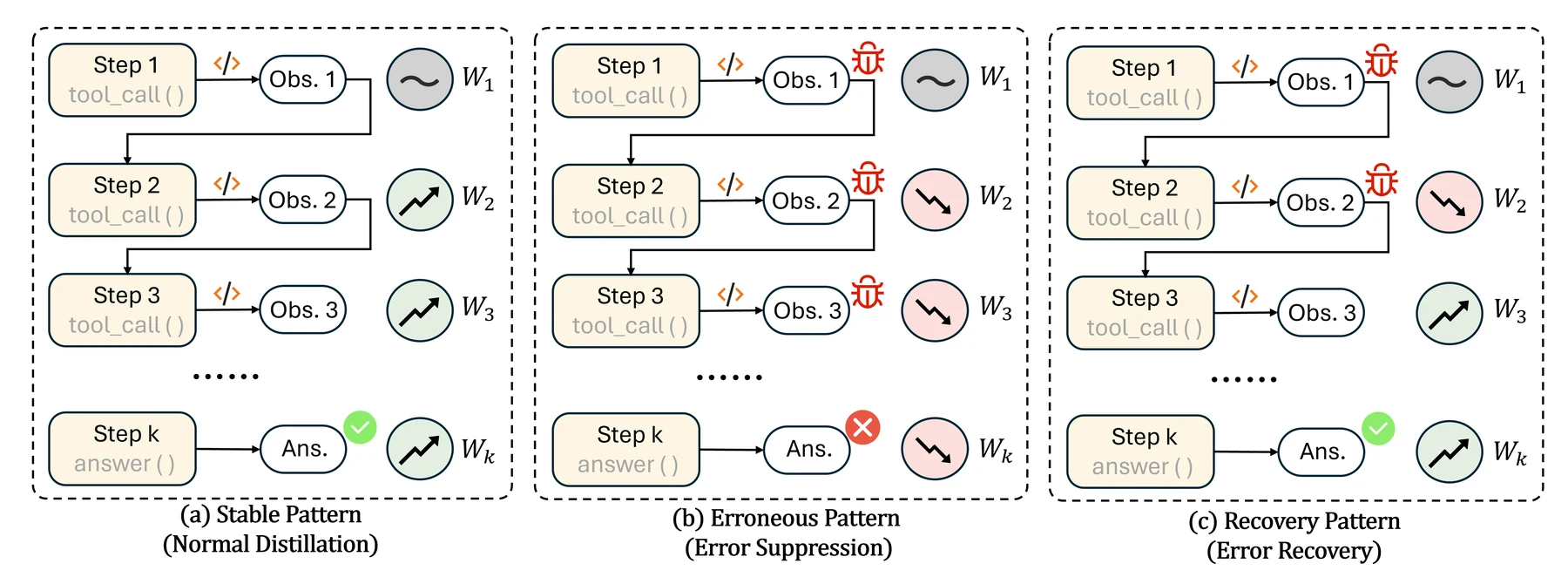
특히 stable, erroneous, recovery pattern을 구분하는 설계가 좋다.
실제 제품 agent에서도 실패는 완전한 binary가 아니다.
잘못된 API call 뒤에 다시 계획을 수정할 수도 있고, 잘못된 계산을 도구로 검증해 회복할 수도 있다.
SOD식 step-level weighting은 이런 회복 가능성을 남겨 둔다.
이는 “실패한 trajectory를 버린다”보다 데이터 효율적이고, “모든 step을 똑같이 학습한다”보다 안정적이다.
다만 한계도 분명하다.
첫째, 실험 도구는 Python code interpreter 중심이다.
웹 브라우징, 장기 API orchestration, 상태ful DB 작업처럼 observation이 더 복잡한 환경에서는 divergence pattern이 다를 수 있다.
둘째, 모든 실험은 Qwen3 계열에서 수행됐다.
Qwen3가 tool reasoning과 long context에서 안정적인 편이라는 점을 고려하면, 다른 model family로 일반화되는지는 추가 검증이 필요하다.
셋째, 평가가 average@32 중심이라는 점도 배포 관점에서는 주의가 필요하다.
많은 실제 시스템은 32개 sample을 생성한 뒤 평균 성능을 보는 방식보다 single-shot latency와 cost를 더 중요하게 본다.
논문 결과는 학습 recipe의 우수성을 보여주지만, 제품에서의 serving 효율까지 곧바로 보장하지는 않는다.
마지막으로, release는 유용하지만 아직 성숙한 library라기보다는 연구 코드와 모델 bundle에 가깝다. releases/tags가 없고, 설치·학습 절차는 8×H20 96GB GPU, SandboxFusion, VeRL/Open-AgentRL 계열 infrastructure를 전제로 한다.
즉 논문을 읽고 방법을 이해하거나 checkpoint를 테스트하기에는 충분히 열려 있지만, 가벼운 pip package처럼 바로 운영에 넣는 형태는 아니다.
그럼에도 SOD는 작은 에이전트 학습에서 꽤 좋은 추상화를 제시한다. teacher의 지식이 항상 유익하다는 가정을 버리고, student가 만든 상태 위에서 teacher supervision의 신뢰도를 계속 재평가한다.
에이전트가 점점 더 많은 도구와 긴 horizon을 다루게 될수록, 이런 step-level reliability control은 단순한 성능 개선 기법을 넘어 agent post-training의 기본 구성요소가 될 가능성이 있다.