에이전트 모델의 성능을 이야기할 때 보통은 모델 크기, 추론 예산, tool-use scaffold, benchmark harness를 먼저 본다.
그런데 실제로 공개 연구자가 가장 알기 어려운 부분은 따로 있다.
어떤 task를 모으고, 어떤 teacher로 trajectory를 만들고, 어떤 흔적을 버려야 하는가다.
모델 weight와 평가 점수는 공개되어도, 에이전트 학습 데이터의 레시피는 대부분 “좋은 데이터로 post-training했다” 정도에서 멈춘다.
OpenThoughts-Agent: Data Recipes for Agentic Models는 이 빈칸을 정면으로 다루는 논문이다.
OpenThoughts-Agent, 줄여서 OT-Agent는 agentic language model을 위한 SFT 데이터 파이프라인을 여섯 단계로 쪼개고, 각 단계에서 100개 이상의 controlled ablation을 수행한다.
그 결과물로 100K 규모의 OpenThoughts-Agent-v2 trajectory dataset을 만들고, Qwen3-32B를 OpenThinkerAgent-32B로 fine-tune한다.
요약하면 이 논문은 “새로운 에이전트 아키텍처”보다 에이전트 모델을 강하게 만드는 데이터 공정표에 가깝다.
그래서 실무적으로도 흥미롭다.
Claude Code, Codex, OpenClaw 같은 agentic system을 쓰거나 만들 때 결국 중요한 질문은 “모델이 똑똑한가”뿐 아니라, “어떤 종류의 실패와 회복 과정을 학습 데이터로 보여 줬는가”이기 때문이다.
무엇을 해결하려는가
논문의 문제의식은 단순하다. agentic model은 이제 terminal, repository, browser-like environment, tool call, long-horizon task를 다루지만, 이런 능력을 어떻게 데이터로 학습시키는지는 공개 지식이 적다.
기존 공개 프로젝트인 SWE-Smith, SERA, Nemotron-Terminal, OpenSWE도 중요하지만, 대체로 SWE-Bench나 Terminal-Bench처럼 특정 benchmark 축에 더 강하게 맞춰져 있었다.
OT-Agent가 묻는 질문은 더 넓다.
여러 agentic benchmark에 동시에 일반화되는 모델을 만들려면, task source부터 rollout filtering까지 어떤 데이터 선택이 실제로 성능을 움직이는가?
이를 위해 저자들은 최종 모델만 발표하지 않고, 데이터 파이프라인 자체를 ablation 대상으로 삼는다.
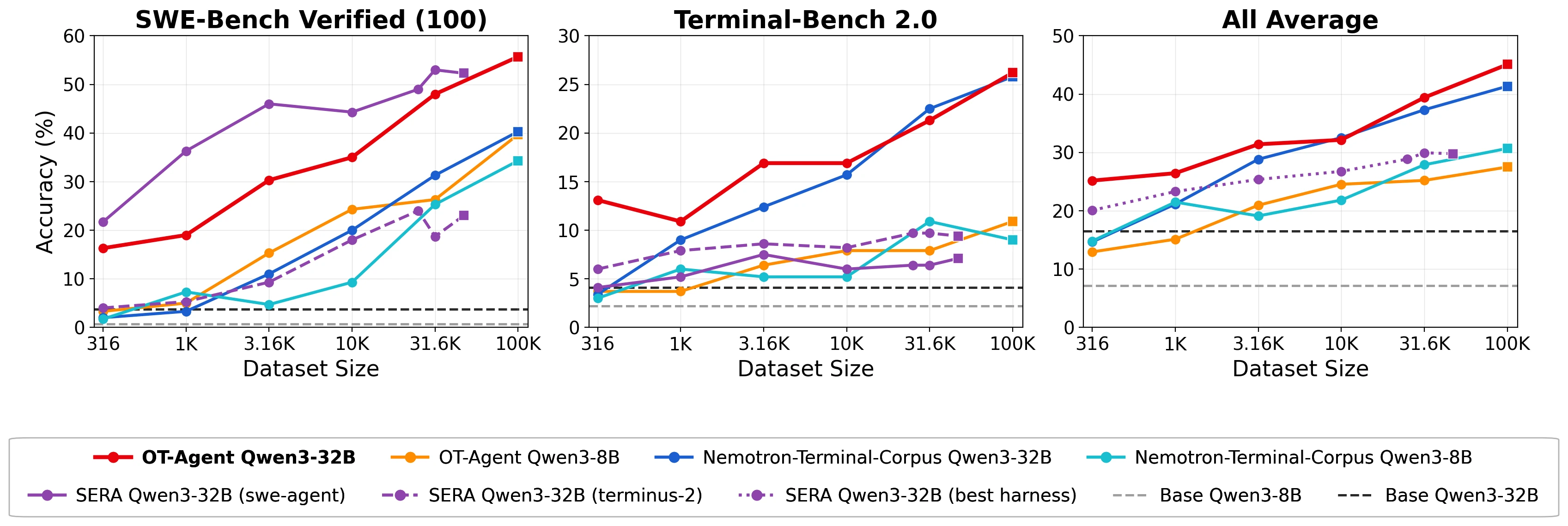
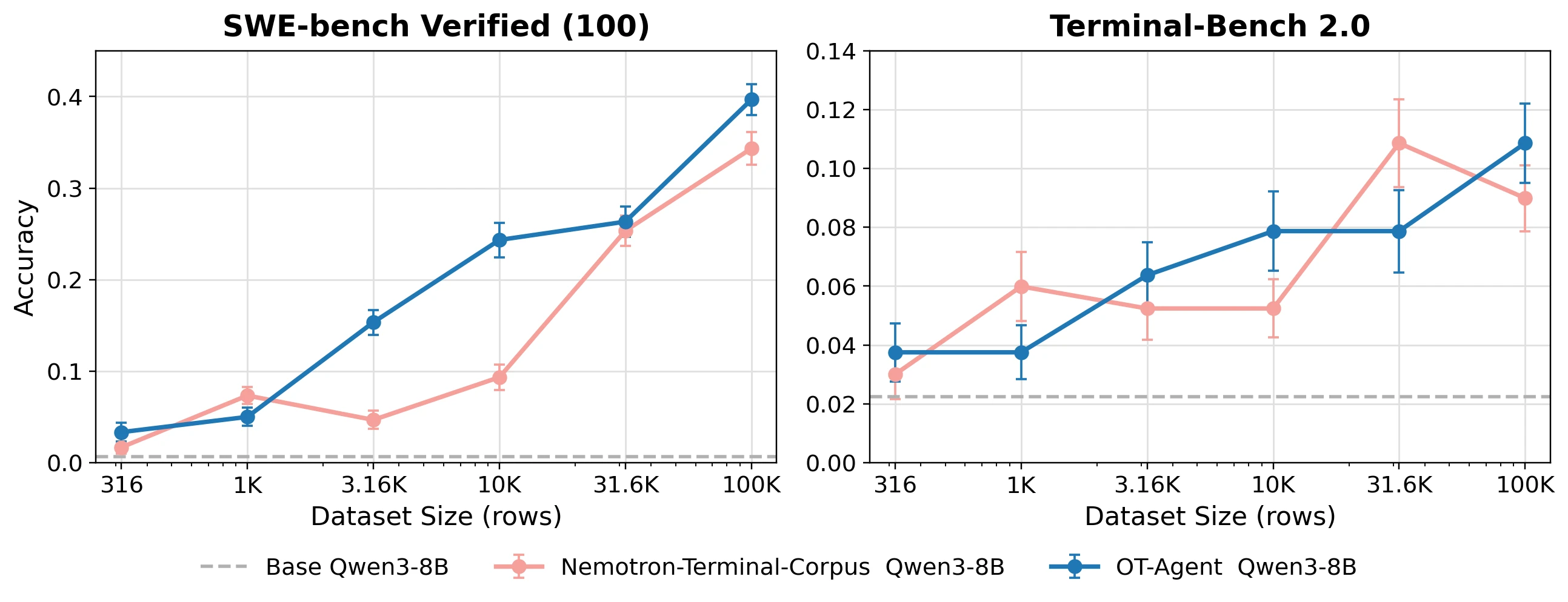
기본 실험은 Qwen3-8B를 base model로 두고 10K trajectory 규모에서 반복하며, 후보 전략을 SWE-Bench Verified-100, OpenThoughts-TBLite, Terminal-Bench 2.0의 평균 z-score로 비교한다.
이후 발견한 recipe를 32B와 100K scale로 올린다.
여섯 단계 SFT 데이터 파이프라인
OT-Agent의 SFT 데이터는 (task, trajectory) 쌍이다.
여기서 task는 agent에게 줄 문제 설명이고, trajectory는 teacher agent가 sandbox 안에서 여러 turn에 걸쳐 문제를 푸는 과정이다.
논문은 이 데이터를 만드는 과정을 여섯 단계로 나눈다.
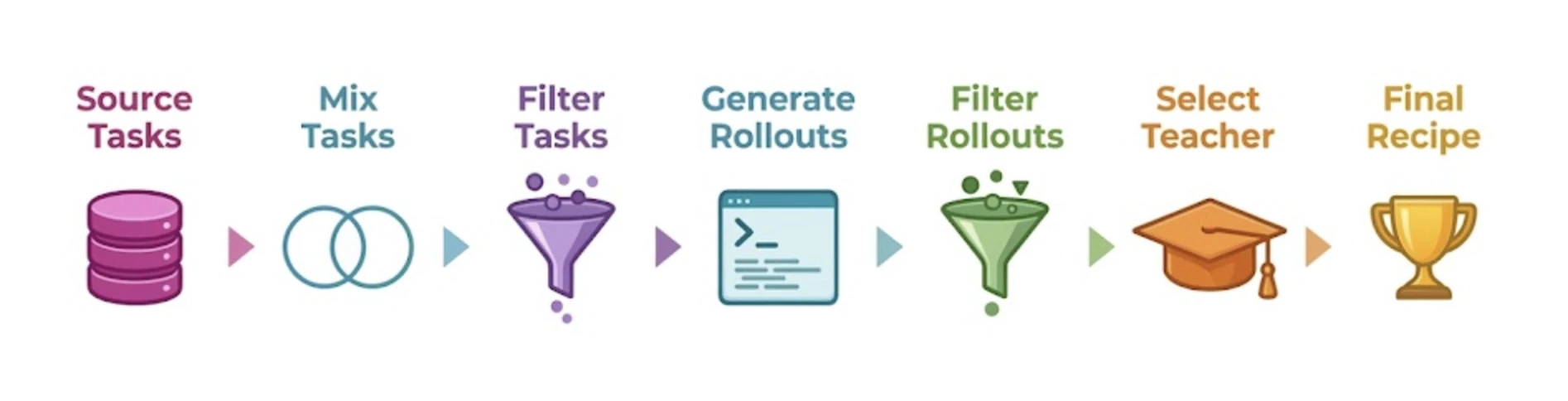
| 단계 | 질문 | 논문에서 확인되는 핵심 신호 |
|---|---|---|
| Source tasks | 어떤 task family를 시작점으로 쓸 것인가 | SWE-Smith, StackExchange SuperUser, StackExchange Tezos, IssueTasks 같은 source 선택이 성능을 크게 흔든다 |
| Mix task sources | 한 source에 집중할 것인가, 섞을 것인가 | Top-4 mix가 Top-1보다 평균적으로 안정적이다 |
| Augment task descriptions | task 설명을 다시 쓰거나 어렵게 만들면 좋아지는가 | 대부분의 단순 augmentation은 baseline을 못 이기지만, 큰 scale에서는 Tezos surface-form 다양화가 병목을 푼다 |
| Filter tasks | 어떤 task 설명을 버릴 것인가 | GPT-5 계열이 더 긴 답을 요구하는 task를 우선하는 filter가 약 3pp 개선 신호를 보인다 |
| Choose teacher | 가장 강한 모델이 최고의 teacher인가 | 아니다. GPT-5.3-Codex보다 GLM-4.7-AWQ teacher가 downstream SFT에 더 좋게 나온다 |
| Filter rollouts | 어떤 trajectory를 남길 것인가 | 5 turn 미만 trace를 제거하는 filter가 timeout/subagent filter보다 강하다 |
여기서 가장 중요한 메시지는 “agentic data quality”가 한 가지 점수로 환원되지 않는다는 것이다.
좋은 source, 좋은 mix, 적절한 다양성, teacher 선택, multi-turn trace의 길이까지 모두 따로 작동한다.
특히 teacher model 결과는 직관과 다르다.
논문 Table 6에서 GPT-5.3-Codex는 benchmark상 강한 모델이지만, teacher로는 GLM-4.7-AWQ보다 나쁜 결과를 냈다.
저자들은 Terminal-Bench 2.0에서 GLM-4.7-AWQ 대비 약 5pp 낮다고 보고한다.
이건 에이전트 데이터셋을 만들 때 꽤 중요한 경고다.
“가장 비싼 모델로 rollout을 뽑으면 된다”가 아니라, learner가 모방하기 좋은 분포, 실패/회복 방식, trajectory 스타일이 따로 있을 수 있다.
다양성 병목: 같은 task를 더 굴리는 것만으로는 부족하다
초기 10K recipe를 100K로 키울 때 가장 쉬운 방법은 같은 task description에 rollout만 더 많이 붙이는 것이다.
그런데 논문은 이 방법이 31.6K에서 100K로 갈 때 plateau에 가까워진다고 본다.
SWE-Bench Verified-100은 약 +3pp, Terminal-Bench 2.0은 -2pp로, 둘 다 standard error 안에 들어가는 수준이다.
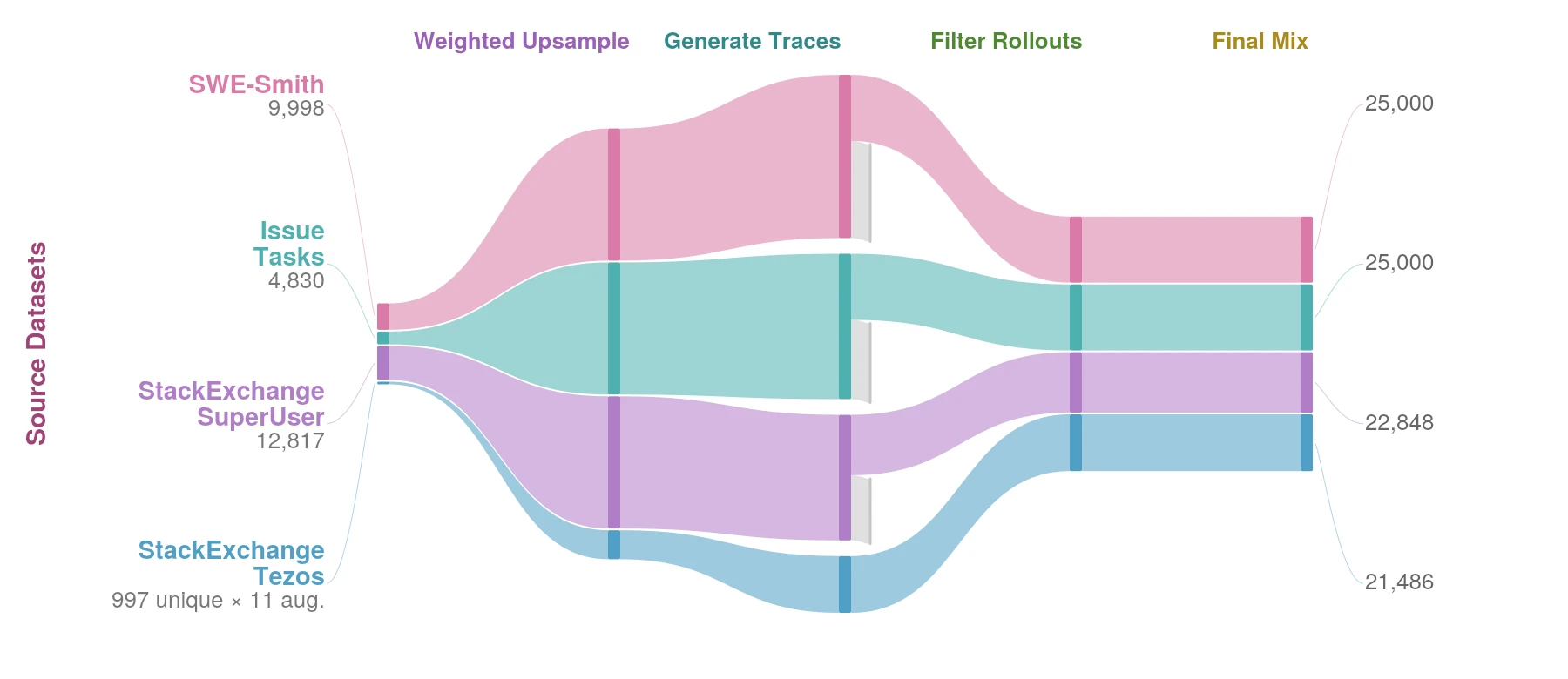
그래서 저자들은 task-description diversity를 병목으로 보고, Top-4 source 중 가장 unique task가 적은 Tezos 쪽을 synthetic augmentation한다.
구체적으로 Tezos는 997개 unique task에 불과했는데, instruction rewriting을 통해 surface form을 21K 이상으로 확장한다.
그리고 GPT-5-nano response-length signal을 hard filter가 아니라 upsampling weight로 써서, 모든 unique task가 최소 한 번은 포함되도록 한다.
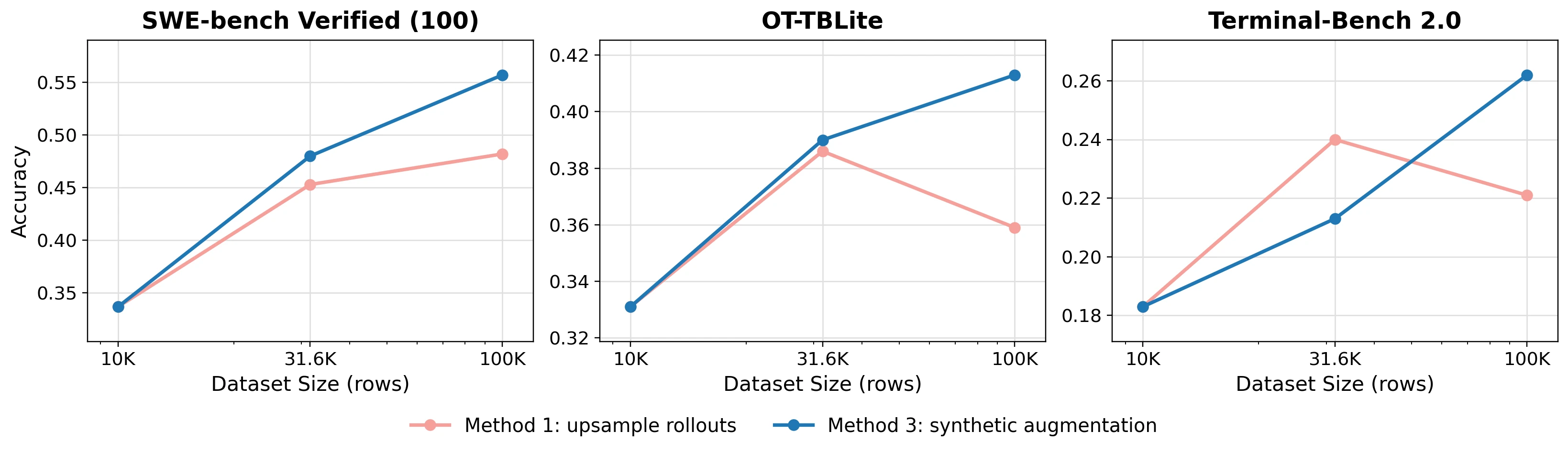
흥미로운 점은 source를 무작정 더 넓히는 것도 답이 아니었다는 것이다.
100K scale에서 Top-4, Top-8, Top-16 source mix를 비교하면 Top-8이 일부 지표에서 높게 보이지만 모든 benchmark에서 안정적으로 이기지는 못하고, Top-16은 오히려 전반적으로 나빠진다.
즉 다양성이 중요하지만, “아무 다양성”이 아니라 task family의 품질과 coverage가 맞는 다양성이 필요하다.
최종 100K dataset인 OpenThoughts-Agent-v2는 Top-4 source에서 출발해 task 반복, Tezos synthetic augmentation, GLM-4.7-AWQ rollout, 5-turn 미만 trace 제거를 결합한다.
OpenThinkerAgent-32B 결과를 어떻게 읽을까
최종 32B 모델은 Qwen/Qwen3-32B를 OpenThoughts-Agent-SFT-100K로 full-parameter SFT한 OpenThinkerAgent-32B다.
논문 Table 1에서 저자들은 Qwen3 family 또는 그 이전 base의 공개 데이터 모델, 32B 이하 규모라는 조건으로 비교한다.
| 지표 | OpenThinkerAgent-32B | Nemotron-Terminal-32B | 해석 |
|---|---|---|---|
| 7개 agentic benchmark 평균 | 44.8 | 40.9 | +3.9pp로 paper의 headline 개선 |
| SWE-Bench Verified | 54.0 | 41.9 | software engineering benchmark에서 큰 차이 |
| Terminal-Bench 2.0 | 26.2 | 25.1 | terminal task에서는 근소하지만 앞선다 |
| Aider Polyglot | 32.4 | 24.9 | OOD coding benchmark에서도 개선 |
| BFCL-Parity | 85.9 | 69.1 | tool/function-calling 계열에서 강한 차이 |
| MedAgentBench | 47.8 | 62.6 | 모든 benchmark를 이긴 것은 아니다 |
| GAIA-127 | 23.6 | 22.3 | 일반 assistant/tool-use 쪽은 작은 차이 |
| FinanceAgent-Terminal | 44.0 | 40.7 | finance terminal task에서도 개선 |
이 표는 두 가지를 동시에 말한다.
첫째, OT-Agent 데이터는 SWE-Bench와 Terminal-Bench만 맞춘 narrow recipe라기보다, Aider, BFCL, GAIA, FinanceAgent-Terminal 같은 OOD benchmark에도 어느 정도 일반화된다.
둘째, MedAgentBench처럼 Nemotron-Terminal-32B가 더 높은 영역도 있으므로 “모든 agentic task를 압도한다”는 식으로 읽으면 과하다.
논문도 비교 설정을 조심스럽게 잡는다.
각 모델은 Terminus-2와 원래 harness 양쪽에서 평가하고, 모델별로 더 높은 accuracy를 보고한다.
따라서 이 결과는 “동일 harness 하나에서 완벽하게 통제한 독립 재현”이라기보다, 공개 모델들을 가능한 강하게 평가한 비교표로 읽는 편이 안전하다.
RL은 별도 이야기: 8B에서만 확인된 compose 가능성
논문은 SFT뿐 아니라 agentic RL 데이터도 본다.
다만 RL은 compute 제약 때문에 8B regime에서만 다룬다.
RLOO 기반 async RL을 사용하고, verifier success에 binary reward를 준다. hero run은 pymethods2test source로, 24×A100 80GB에서 약 46시간 wall-clock으로 학습했다고 보고한다.
RL source ablation도 SFT와 비슷한 결론을 낸다.
데이터 source에 따라 성능 차이가 크다. pymethods2test는 Codeforces, CodeChef, TopCoder 스타일 문제를 single-function Python contract와 unittest로 바꾼 dataset인데, repository navigation이나 multi-file editing은 없지만 재현성, 사용성, 적당한 난이도 ceiling이 좋다.
이 source가 8B RL 실험에서 가장 강하게 나온다.
8B main result는 SFT와 RL이 조합될 수 있음을 보여 주는 초기 신호에 가깝다.
Table 10 기준 OT-Agent-ColdSFT+RL-8B 평균은 27.9, OT-Agent-SFT-8B (100K)는 27.4, Nemotron-Terminal-8B는 26.0이다.
차이가 아주 크지는 않지만, RL을 어디에 얹느냐가 중요하다는 점은 분명하다.
논문 Table 11은 Qwen3-8B base에 바로 RL을 얹는 것보다, 적당히 강한 SFT checkpoint 위에서 RL을 하는 쪽이 낫다고 보고한다.
공개 아티팩트 상태
공개 표면은 꽤 넓다.
| 표면 | 확인한 내용 | 실무적 의미 |
|---|---|---|
| arXiv / HF Papers | arXiv:2606.24855v1, 2026-06-23 제출 |
논문과 figure의 canonical source |
| OpenThoughts site | 프로젝트 홈, agent blog, 모델·데이터·코드 링크 | 독자가 release bundle을 따라가기 가장 쉬운 entry point |
GitHub open-thoughts/OpenThoughts-Agent |
Apache-2.0, “Data recipes and robust infrastructure for training AI agents” | 연구 codebase이며 README가 conventions will change라고 경고한다 |
HF model open-thoughts/OpenThinkerAgent-32B |
public, ungated, Apache-2.0, base model Qwen/Qwen3-32B, dataset OpenThoughts-Agent-SFT-100K |
모델 자체는 Hub에서 접근 가능하지만, 실제 32B serving은 별도 GPU/서빙 비용이 필요하다 |
HF dataset OpenThoughts-Agent-SFT-100K |
public, ungated, Apache-2.0, parquet text dataset | paper의 최종 SFT recipe를 추적할 수 있는 핵심 artifact |
주의할 점도 있다.
GitHub README는 OT-Agent가 research codebase이고, conventions, file layout, workflow가 계속 바뀔 수 있다고 명시한다.
즉 “pip install 후 바로 안정적인 제품 코드처럼 쓰는 패키지”가 아니라, 데이터 생성, SFT, 평가, RL, HPC/cloud launcher를 포함한 연구 인프라로 보는 편이 맞다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 큰 가치는 agentic model training을 좀 더 공학적으로 말할 수 있게 만든다는 점이다.
지금까지 에이전트 성능 논의는 “어떤 foundation model을 썼는가”와 “어떤 benchmark를 몇 점 받았는가”에 치우치기 쉬웠다.
OT-Agent는 그 사이에 있는 데이터 공정을 실제 ablation 대상으로 끌어낸다.
특히 세 가지 메시지가 중요하다.
첫째, task source는 단순한 원재료가 아니라 모델의 행동 분포를 결정한다.
SWE-Smith류 issue-resolution task는 SWE-Bench에 강한 신호를 주고, StackExchange SuperUser 같은 human-written infrastructure question은 Terminal-Bench 쪽을 움직인다. broad agent를 만들려면 한 source를 깊게 파는 것과 여러 source를 섞는 것 사이의 균형을 잡아야 한다.
둘째, trajectory의 “길이”는 비용만이 아니라 품질 신호일 수 있다.
5 turn 미만 trace를 제거했을 때 timeout filter나 subagent trace filter보다 좋은 결과가 나온 것은, 장기 작업에서 모델이 봐야 할 핵심 supervision이 단발 답변보다 multi-turn recovery 과정에 있다는 뜻으로 읽을 수 있다.
에이전트 학습 데이터는 정답뿐 아니라 탐색, 오류, 수정, 검증의 과정을 담아야 한다.
셋째, teacher 선택은 benchmark leaderboard와 다르다.
GPT-5.3-Codex처럼 강한 모델이 learner에게 가장 좋은 teacher가 아닐 수 있다.
생성하는 trajectory가 너무 다른 스타일이거나, learner가 흡수하기 어려운 분포일 수도 있다.
앞으로 agentic distillation을 할 때는 “teacher absolute performance”보다 “teacher trajectory가 target learner와 benchmark mix에 주는 downstream effect”를 봐야 한다.
한계도 분명하다.
최종 SFT 실험은 Qwen3 family 기반이라 base-model choice를 독립적으로 분리하지 않는다.
최대 규모도 100K trajectory라 multi-million trajectory regime까지 extrapolate할 수는 없다.
RL은 8B에서만 검증되었고, 32B에서 같은 recipe가 그대로 작동하는지는 open question이다.
또한 agentic model은 dual-use 위험이 있으므로, 공개 모델을 실사용 환경에 붙일 때는 sandboxing과 human oversight가 필요하다.
그래도 방향은 꽤 설득력 있다.
에이전트 모델을 잘 만들려면 “더 큰 모델”만으로는 부족하다.
좋은 agentic data recipe는 어떤 문제를 시키고, 어떤 teacher에게 풀게 하고, 어떤 multi-turn trace를 남기며, 어떤 다양성 병목을 synthetic augmentation으로 푸는지까지 포함한다.
OpenThoughts-Agent는 그 레시피를 공개 실험의 대상으로 만든다는 점에서, 앞으로 공개 에이전트 연구의 기준선 역할을 할 가능성이 크다.