AI 에이전트 논의는 쉽게 “어떤 모델이 더 똑똑한가”로 좁아진다.
하지만 실제 코딩·리서치·운영 작업에서 실패를 가르는 것은 모델 하나가 아니다.
에이전트가 어떤 컨텍스트를 읽는지, 어떤 도구를 쓸 수 있는지, 실패를 누가 판정하는지, 다음 세션으로 상태가 어떻게 넘어가는지, 위험한 행동은 어디에서 멈추는지가 함께 품질을 만든다.
Awesome Harness Engineering은 이 주변부를 정면으로 다루는 큐레이션 저장소다. walkinglabs는 하네스 엔지니어링을 “AI 에이전트가 신뢰성 있게 일할 수 있도록 주변 환경을 빚는 실천”으로 정의한다.
여기서 핵심은 더 강한 프롬프트 문장 하나를 찾는 것이 아니라, 에이전트가 장시간 작업을 수행할 수 있는 작업대, 상태 저장 방식, 검증 루프, 관측성, 제약 조건을 설계하는 것이다.
PyTorchKR 소개 글은 이 저장소를 한국어로 정리하면서 “일반적인 에이전트 도구 목록”과 구분한다.
실제 README도 범위를 꽤 엄격하게 제한한다.
일반 agent tooling은 제외하고, context management, evaluation, runtime control, harness design primitive처럼 신뢰성에 직접 영향을 주는 자료만 다루겠다는 입장이다.
무엇을 해결하려는가
에이전트가 짧은 데모에서는 그럴듯해도 실제 업무에서는 자주 깨지는 이유가 있다.
작업은 한 번의 답변으로 끝나지 않는다.
여러 파일을 바꾸고, 테스트를 돌리고, 실패를 기록하고, 다음 세션에 인계하고, 인간의 승인과 배포 절차를 지나야 한다.
이때 모델이 아무리 강해도 주변 환경이 약하면 같은 문제가 반복된다.
가장 흔한 실패는 세 가지다.
첫째, 컨텍스트가 정리되지 않아 에이전트가 오래된 지시나 잘못된 상태를 믿는다.
둘째, 검증 기준이 약해서 “돌아간 것처럼 보이는 코드”를 완료로 기록한다.
셋째, tool permission, sandbox, 승인 경계가 불명확해 불필요하게 위험한 행동을 하거나 반대로 필요한 실행을 못 한다.
Awesome Harness Engineering은 이런 실패를 “모델 능력 부족”으로만 보지 않는다.
저장소가 모은 OpenAI, Anthropic, LangChain, Martin Fowler, Inngest, HumanLayer 등의 글은 모두 비슷한 결론으로 모인다.
에이전트 품질은 model + harness의 결과이고, 하네스는 instruction file 몇 줄이 아니라 software architecture의 일부다.
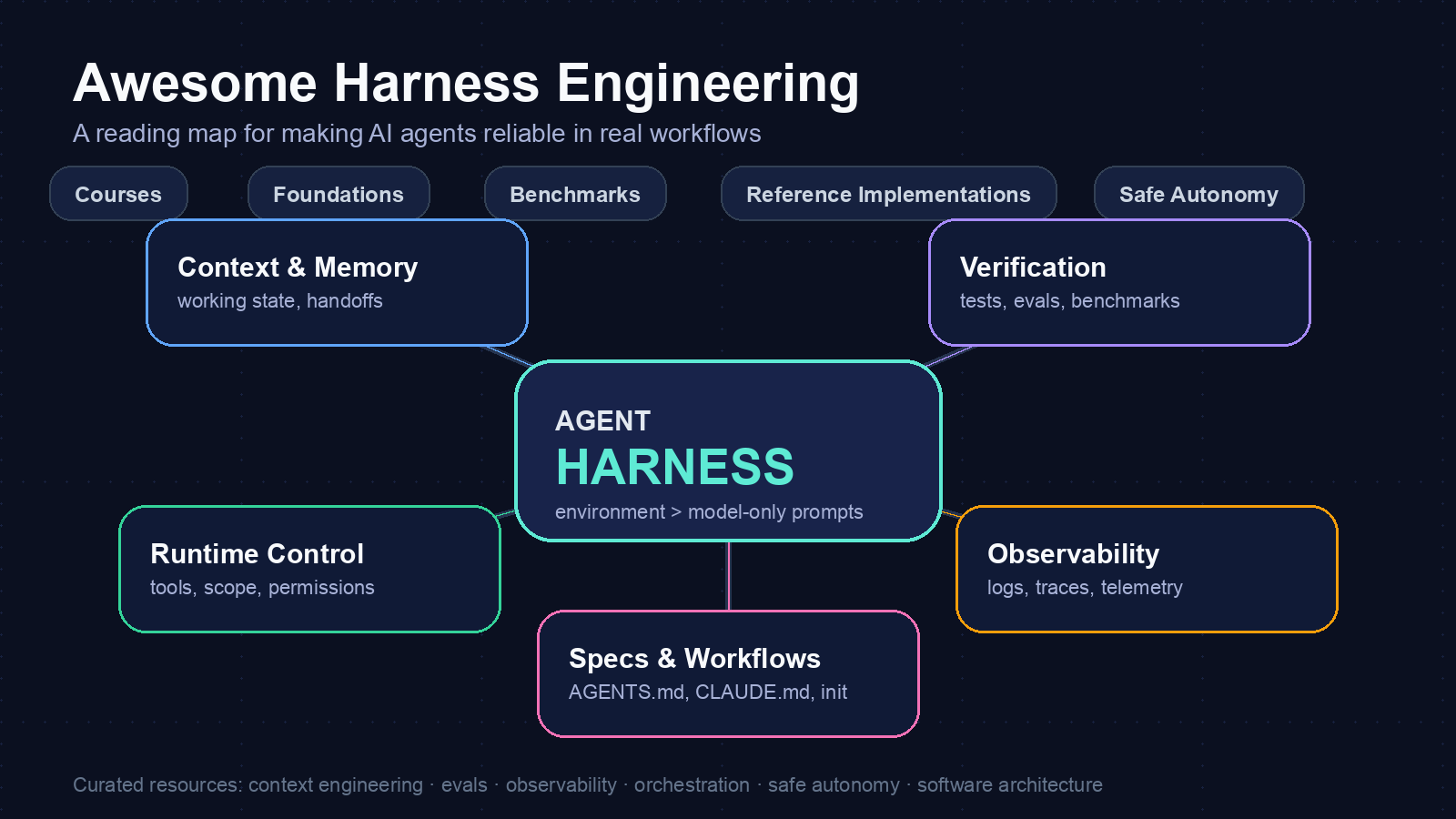
핵심 아이디어: 하네스는 에이전트 주변의 운영 체계다
이 저장소의 좋은 점은 하네스 엔지니어링을 추상 구호가 아니라 여러 설계면으로 나눈다는 데 있다.
PyTorchKR 소개 글 기준으로 저장소는 100개 이상의 자료를 8개 주요 카테고리로 묶는다.
| 분류 | 읽어야 하는 이유 |
|---|---|
| Courses & Learning Resources | Codex와 Claude Code를 실제 프로젝트에서 더 신뢰성 있게 쓰는 실습형 과정 |
| Foundations | 하네스 엔지니어링의 정의, agent-first 개발, model+harness 프레임 |
| Context, Memory & Working State | 제한된 컨텍스트 윈도우를 작업 메모리 예산처럼 관리하는 법 |
| Constraints, Guardrails & Safe Autonomy | sandbox, 승인 정책, prompt injection 완화, tool boundary 설계 |
| Specs, Agent Files & Workflow Design | AGENTS.md, CLAUDE.md, Spec Kit, 12-Factor Agents 같은 명세 기반 운영 |
| Evals & Observability | trace, telemetry, 반복 가능한 eval, 실패 분석 루프 |
| Benchmarks | SWE-bench, Terminal-Bench, OSWorld, WebArena처럼 하네스 품질을 비교하는 표면 |
| Runtimes, Harnesses & Reference Implementations | SWE-agent, Deep Agents, Harbor, AgentKit 같은 구현 사례 |
여기서 중요한 포인트는 “자료가 많다”가 아니라 분류의 중심축이다.
저장소는 에이전트를 잘 쓰는 방법을 prompt template 모음으로 보지 않는다.
대신 컨텍스트, 검증, 관측성, 런타임 제어, 안전한 자율성, 소프트웨어 아키텍처가 만나는 지점으로 본다.
OpenAI의 Codex 하네스 글은 이 관점을 현장 사례로 보여 준다.
대형 애플리케이션을 agent-first 방식으로 만들면서, 거대한 AGENTS.md 대신 저장소 안의 구조화된 문서, worktree별 실행 환경, 브라우저 검증, 로그·메트릭·트레이스 접근성을 강조한다.
핵심은 “Codex에게 1,000쪽짜리 매뉴얼을 넣는 것”이 아니라, 에이전트가 필요한 지식과 검증 신호를 찾을 수 있는 지도와 도구를 제공하는 것이다.
Anthropic의 long-running agents 글도 같은 방향이다.
장기 실행 에이전트는 세션이 끊기고 새 컨텍스트에서 다시 시작한다.
따라서 initializer agent가 feature list, progress log, init.sh, 초기 git 상태를 만들고, 이후 coding agent는 한 번에 한 기능만 구현하고 테스트한 뒤 다음 세션을 위한 상태를 남긴다.
이것은 프롬프트 최적화라기보다 작업 수명주기 설계다.
공개된 근거에서 확인되는 점
GitHub 요약 기준 walkinglabs/awesome-harness-engineering은 CC0-1.0 라이선스의 큐레이션 저장소이며, 확인 시점에 약 3.3k stars, 262 forks, 61 commits로 소개된다.
루트는 단순하다.
핵심 파일은 README.md, CONTRIBUTING.md, LICENSE이고 별도 release는 공개되어 있지 않다.
즉 설치형 프레임워크라기보다, 빠르게 커지는 읽기 지도와 reference index에 가깝다.
함께 연결된 walkinglabs/learn-harness-engineering은 더 실습적인 companion 성격을 가진다.
GitHub 요약은 이 저장소를 “Harness engineering beginner tutorial, from 0 to 1”로 소개하고, Electron 기반 개인 지식 베이스 앱을 실습 소재로 삼는 프로젝트 기반 과정이라고 설명한다.
12개 강의, 6개 프로젝트, 14개 언어 지원, MIT 라이선스, skills/harness-creator/ 같은 reusable skill까지 포함한다는 점에서 Awesome 목록의 “Courses & Learning Resources” 섹션이 단순 링크가 아니라 실제 학습 경로와 연결되어 있음을 보여 준다.
저장소가 특히 명확하게 잡는 선은 “일반 agent 도구”와 “하네스 primitive”의 차이다.
예컨대 benchmark 섹션은 모델 성능표를 나열하기보다, 같은 모델이라도 context handling, tool interface, environment control, verification logic, runtime setting에 따라 결과가 달라진다는 점을 강조한다.
이 관점에서는 SWE-bench나 Terminal-Bench도 단순 leaderboard가 아니라 agent harness의 품질을 드러내는 테스트베드다.
| 확인 항목 | 관찰되는 형태 | 해석 |
|---|---|---|
| 저장소 성격 | README 중심 curated list | 실행 프레임워크보다 신뢰성 설계 자료 지도 |
| 라이선스 | CC0-1.0 | 목록 자체는 재사용·확장하기 쉬운 형태 |
| 릴리스 상태 | 공개 release 없음 | 버전 고정 도구라기보다 살아 있는 index |
| companion course | learn-harness-engineering |
개념을 실제 프로젝트 기반 과정으로 연결 |
| 핵심 범위 | context, evals, observability, orchestration, safe autonomy | model-only 성능 논의에서 운영 하네스 논의로 이동 |
실무 관점에서의 해석
이 저장소의 실무적 가치는 “좋은 링크 모음” 이상이다.
팀이 AI 에이전트를 도입할 때 무엇을 점검해야 하는지에 대한 체크리스트로 쓸 수 있다.
예를 들어 coding agent를 쓰는 팀이라면 단순히 모델과 IDE 확장을 고르는 데서 멈추면 안 된다.
다음 질문을 같이 물어야 한다.
| 질문 | 하네스 관점의 의미 |
|---|---|
| 에이전트가 첫 세션에서 무엇을 반드시 읽는가 | AGENTS.md, architecture docs, feature list의 progressive disclosure |
| 작업 상태는 어디에 남는가 | progress file, git history, issue tracker, handoff note |
| 완료 판정은 누가 하는가 | test, lint, smoke run, benchmark, human review의 조합 |
| 위험한 action은 어디에서 막는가 | sandbox, permission tier, approval gate, credential boundary |
| 실패 원인은 어떻게 재현되는가 | logs, traces, screenshots, eval artifacts, saved trajectories |
| 여러 에이전트가 동시에 일하면 어떻게 합치는가 | worktree, branch policy, reviewer agent, conflict protocol |
이 질문들은 당장 화려하지 않지만, 장기 실행 에이전트에서는 핵심 자산이 된다.
모델은 계속 바뀐다.
하지만 좋은 작업 상태 파일, 검증 스크립트, benchmark adapter, 로그 조회 방식, 권한 모델, 인계 규약은 모델이 바뀌어도 남는다.
더 강한 모델을 붙였을 때 성능이 곱해지는 곳도 바로 이 주변부다.
또 하나의 장점은 이 저장소가 “하네스”를 연구와 제품 사이의 공통 언어로 만든다는 점이다.
OpenAI의 agent-first 개발 사례, Anthropic의 long-running agent pattern, LangChain의 model+harness 해부, Fowler의 context engineering·architectural constraint·garbage collection 프레임은 서로 다른 글이지만 같은 문제를 말한다.
에이전트를 신뢰하려면 모델의 말이 아니라, 에이전트가 놓인 환경과 그 환경이 만들어내는 검증 가능한 증거를 봐야 한다.
한계와 읽는 법
Awesome 계열 저장소의 한계도 분명하다.
큐레이션은 빠르게 좋아질 수 있지만 빠르게 낡을 수도 있다.
항목의 품질과 최신성은 링크마다 다르고, 특정 자료가 “하네스 엔지니어링”이라는 이름을 직접 쓰지 않더라도 실제로는 중요한 primitive를 설명할 수 있다.
따라서 이 저장소를 정답 목록으로 읽기보다, 팀의 현재 agent workflow를 점검하는 출발점으로 읽는 편이 좋다.
특히 실무 팀이라면 목록을 그대로 따라가기보다 자기 환경의 실패 모드에 맞춰 읽는 순서를 정하는 것이 낫다.
에이전트가 자꾸 작업을 잊는다면 Context, Memory & Working State부터 읽고, “성공했다”고 말하지만 결과가 깨진다면 Evals & Observability와 Benchmarks를 먼저 봐야 한다.
위험한 command나 데이터 접근이 문제라면 Constraints, Guardrails & Safe Autonomy가 먼저다.
내가 보기에는 이 저장소의 가장 좋은 문장은 정의 자체다.
하네스 엔지니어링은 “AI 에이전트를 둘러싼 환경을 빚어 신뢰성 있게 일하도록 만드는 실천”이다.
이 정의는 에이전트 도입의 책임을 모델 제공사에만 넘기지 않는다.
팀이 어떤 환경을 만들었는지, 어떤 실패 신호를 수집하는지, 어떤 검증을 강제하는지까지 제품 품질의 일부로 본다.
정리
Awesome Harness Engineering은 지금 AI 에이전트 논의에서 필요한 방향 전환을 잘 포착한다.
에이전트를 잘 쓰는 팀은 더 긴 prompt만 가진 팀이 아니다.
에이전트가 읽을 문서, 유지할 상태, 실행할 도구, 통과해야 할 검증, 사람이 승인해야 할 경계를 설계한 팀이다.
이 저장소는 바로 그 설계면들을 한곳에 모은다.
그래서 단순한 즐겨찾기 목록이 아니라, agent system을 운영 가능한 engineering artifact로 만들기 위한 지도에 가깝다.
앞으로 모델이 더 좋아질수록 하네스의 중요성은 줄어들기보다 커질 가능성이 높다.
모델이 일을 한다면, 하네스는 그 일이 반복 가능하고 관찰 가능하고 되돌릴 수 있는지 결정하기 때문이다.