문서 OCR의 병목은 점점 “글자를 얼마나 잘 맞히는가”에서 “긴 문서를 얼마나 오래, 같은 속도와 메모리로 파싱할 수 있는가”로 이동하고 있다.
한 페이지짜리 스캔 이미지는 이미 여러 VLM·OCR 모델이 다룰 수 있지만, 수십 페이지 PDF를 페이지마다 끊지 않고 하나의 연속된 작업으로 처리하려면 디코더의 KV cache와 출력 길이가 곧바로 병목이 된다.
baidu/Unlimited-OCR은 이 문제를 정면으로 겨냥한 Baidu의 공개 OCR 모델이다.
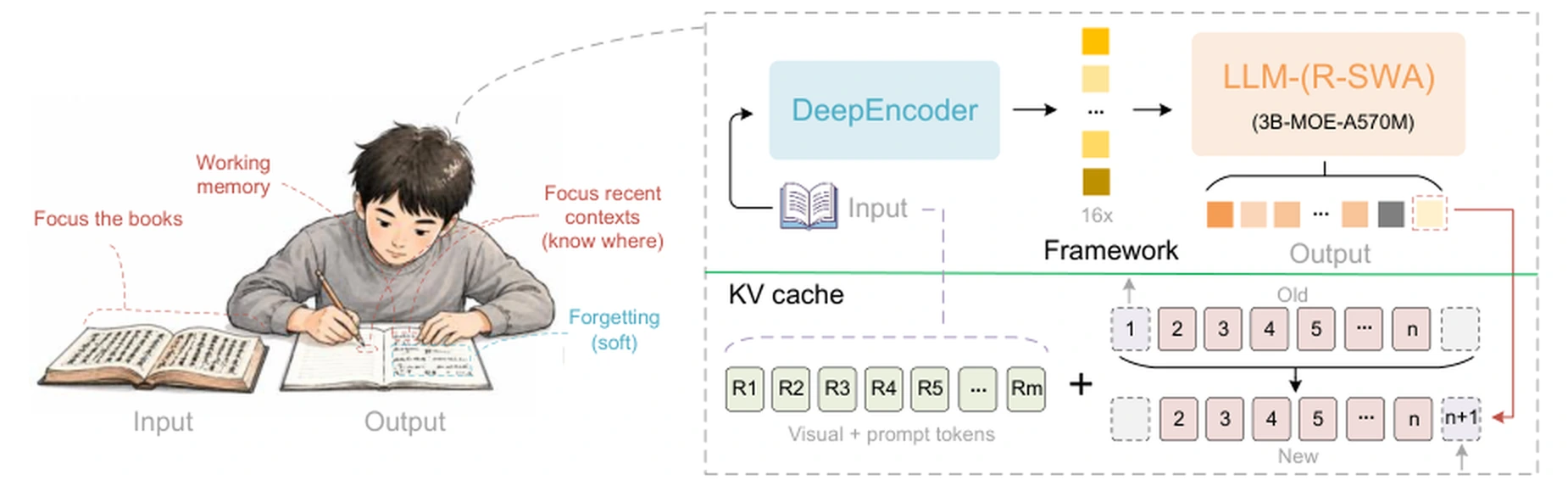
기술보고서의 제목은 Unlimited OCR Works: Welcome the Era of One-shot Long-horizon Parsing이고, 핵심은 DeepSeek-OCR의 고압축 visual encoder를 유지하되 디코더 attention을 Reference Sliding Window Attention, R-SWA로 바꾸는 것이다.
모델은 3B MoE 구조, 약 0.5B activated parameter framing을 유지하면서, 출력이 길어져도 디코드 쪽 KV cache가 계속 커지지 않도록 설계된다.
이 글은 Unlimited-OCR을 “새 OCR 리더보드 모델”이라기보다, 문서 파싱을 long-horizon decoding 문제로 다시 정의한 실험으로 읽는다.
특히 RAG, 문서 ingestion, 에이전트가 다량의 PDF를 읽어야 하는 환경에서는 OCR 품질만큼이나 처리 길이, 메모리, latency 안정성이 중요해지기 때문이다.
무엇을 해결하려는가
기존 OCR 파이프라인은 긴 문서를 보통 페이지 단위로 잘라 처리한다.
각 페이지를 독립적으로 OCR하고, 외부 스케줄러나 후처리 코드가 결과를 다시 합친다.
이 방식은 실용적이지만, 모델 입장에서는 매 페이지마다 문맥이 초기화된다.
문서 전체의 흐름, 페이지 간 이어지는 표기, 반복되는 구조, 방금 출력한 주변 context는 모델 내부에서 자연스럽게 유지되지 않는다.
Unlimited-OCR 보고서는 이 차이를 사람의 필사 작업에 빗댄다.
사람이 책을 베껴 쓸 때 이미 쓴 모든 문장을 다시 보지는 않는다.
원본 문서와 바로 최근에 쓴 부분, 그리고 다음에 쓸 위치만 계속 확인한다.
멀리 있는 출력은 부드럽게 잊고, 원본 reference는 계속 볼 수 있는 형태다.
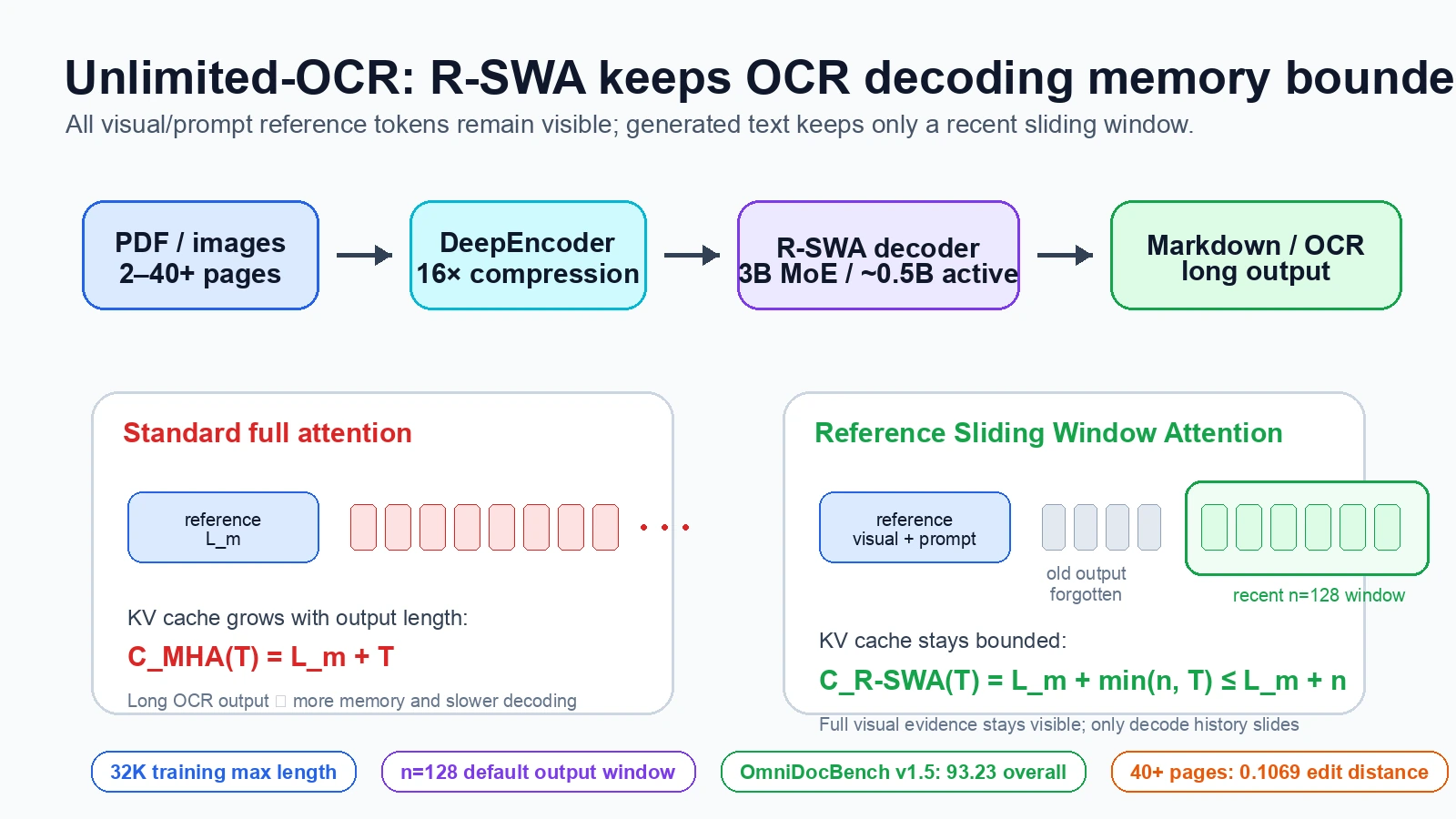
문제는 표준 full attention이 이 작업에 비싸다는 점이다.
출력 길이 T가 늘어날수록 Multi-Head Attention의 KV cache는 L_m + T로 커진다.
여기서 L_m은 visual token과 prompt 같은 prefix/reference 길이다.
긴 PDF를 한 번에 파싱하려면 출력 토큰이 매우 길어지고, 그 결과 메모리와 디코딩 latency가 함께 증가한다.
Unlimited-OCR의 질문은 그래서 단순하다.
문서 reference는 항상 보되, 이미 생성한 출력은 최근 일부만 보면 충분하지 않은가?
핵심 아이디어 / 구조 / 동작 방식
Unlimited-OCR은 DeepSeek-OCR을 baseline으로 삼는다.
입력 쪽에서는 DeepSeek-OCR의 DeepEncoder를 유지한다.
이 encoder는 SAM-ViT와 CLIP-ViT 계열을 결합하고 bridge에서 16× token compression을 적용해, 1024×1024 PDF image를 256 visual token 수준으로 압축할 수 있다고 설명된다.
다중 페이지에서는 Base 1024×1024 모드를, 단일 페이지에서는 dynamic resolution인 Gundam 모드를 유지한다.
디코더 쪽이 핵심 변경점이다.
기존 DeepSeek-OCR의 표준 attention을 모두 R-SWA로 바꾼다.
R-SWA에서 각 생성 토큰은 두 종류의 context를 본다.
| 구간 | R-SWA에서의 처리 | 의미 |
|---|---|---|
| Reference / prefix | visual token과 prompt 전체를 항상 attend | 원본 문서 증거는 끝까지 보존 |
| Decode window | 직전 n개 출력 토큰만 causal sliding window로 attend |
OCR 진행 위치와 최근 문맥만 유지 |
| 기본 window | 보고서 기준 n=128 |
출력이 길어져도 디코드 cache를 고정 |
| KV cache | L_m + min(n, T)로 상한을 둠 |
표준 MHA의 L_m + T 증가를 피함 |
이 구조는 vanilla sliding window attention과도 다르다.
단순 SWA처럼 모든 과거 정보를 sliding state로 흘려보내면 visual token 자체가 반복적인 상태 전이를 거치며 흐려질 수 있다.
R-SWA는 visual/reference token을 고정된 prefix로 남겨 둔다.
즉 “원본 문서 전체는 계속 보고, 내가 방금 쓴 일부만 작업 기억으로 유지하는” 형태에 가깝다.
학습 설정도 이 목적에 맞춰져 있다.
보고서는 약 2M document OCR samples를 구성했고, single-page와 multi-page 비율을 9:1로 둔다. multi-page data는 single-page data를 2~50페이지 단위로 이어 붙여 합성하고, 모든 데이터를 32K token 길이로 packing한다.
학습은 DeepSeek-OCR checkpoint에서 출발해 DeepEncoder는 freeze하고 LLM parameter만 4,000 step 추가 학습한다.
사용 장비는 8 × 16 A800 GPU, global batch size 256, Megatron-LM 기반 pipeline으로 제시된다.
공개된 근거에서 확인되는 점
Hugging Face 모델 페이지 기준 baidu/Unlimited-OCR은 image-text-to-text 계열 OCR/document parsing 모델로 공개돼 있고, 모델 크기는 3B, tensor type은 BF16, safetensors 형식으로 표시된다.
모델 카드는 Transformers, SGLang, vLLM, Docker Model Runner, Colab/Kaggle, 그리고 일부 local/quantized runtime 경로까지 여러 실행 방식을 소개한다.
다만 Transformers 예시는 trust_remote_code=True를 전제로 하고, 테스트 환경도 Python 3.12.3, CUDA 12.9, NVIDIA GPU, 최신 PyTorch/Transformers 조합으로 제시된다.
운영 관점에서는 “가중치가 공개됐다”와 “내 환경에 안전하게 drop-in 배포된다”를 분리해서 봐야 한다.
GitHub 저장소는 Baidu 조직 아래 공개돼 있으며 README.md, Unlimited-OCR.pdf, infer.py, assets/, wheel/을 포함한다.
확인 시점의 저장소는 초기 공개 형태에 가깝다.
GitHub Releases는 없고, citation은 “coming soon”으로 남아 있으며, wheel/에는 SGLang 개발 버전 wheel이 포함돼 있다.
즉 연구·실험을 바로 따라갈 수 있는 표면은 있지만, 성숙한 패키지 릴리스로 보기에는 아직 이른 상태다.
성능 주장의 중심은 OmniDocBench다.
보고서의 Table 1에서 Unlimited-OCR은 OmniDocBench v1.5 기준 overall 93.23을 기록한다고 제시된다.
같은 표에서 DeepSeek-OCR baseline은 87.01이므로, 보고서는 +6.22 overall 개선으로 해석한다.
세부적으로는 text edit distance 0.073 → 0.038, Formula CDM 83.37 → 92.61, Table TEDS 84.97 → 90.93, Table TEDS-S 88.80 → 94.07, reading-order edit 0.086 → 0.045로 제시된다.
OmniDocBench v1.6에서도 보고서는 Unlimited-OCR이 overall 93.92를 기록한다고 적는다.
이 수치는 Qianfan-OCR 93.90, Logics-Parsing-v2 93.33, FireRed-OCR 93.26 같은 비교군과 거의 같은 상위권 범위에 있다.
다만 표의 다른 모델 수치는 OmniDocBench repository에서 가져오고, Unlimited-OCR 결과는 제안 모델의 자체 평가로 제시되는 구조다.
따라서 “공개 보고서 기준 강한 결과”로 읽되, 실제 도입에서는 문서군별 재현 평가가 필요하다.
효율 지표도 이 글의 핵심이다.
보고서는 OmniDocBench에서 Base DeepEncoder mode 기준 Unlimited-OCR이 5580 TPS를 보였고, DeepSeek-OCR의 4951 TPS보다 12.7% 빠르다고 설명한다.
더 중요한 것은 출력 길이가 길어질 때다.
이론적 ceiling 비교에서 DeepSeek-OCR은 output length 256에서 7229 TPS 수준이지만 6144 token에서는 5822 TPS로 내려간다.
반면 Unlimited-OCR은 같은 범위에서 7229 → 7847 TPS 수준으로 유지된다.
보고서는 6000 token 부근에서 R-SWA가 DeepSeek-OCR보다 35% 앞선다고 해석한다.
긴 문서 실험에서는 2, 5, 10, 15, 20, 40+ pages를 한 번에 넣는 in-house benchmark가 제시된다.
Table 3 기준 40+ pages에서도 Distinct-35는 96.90%, edit distance는 0.1069로 보고된다.
저자들은 반복 오류의 상당 부분이 R-SWA가 진행 방향을 잃어서라기보다, multi-page 조건에서 Base 1024×1024 해상도를 쓰면서 작은 글자가 잘 보이지 않는 경우에서 나온다고 설명한다.
실무 관점에서의 해석
Unlimited-OCR의 가장 중요한 메시지는 “OCR 모델이 더 많은 페이지를 읽는다”가 아니라, 문서 파싱의 비용 축을 decoder memory policy로 옮긴다는 데 있다.
DeepEncoder는 페이지를 visual token으로 강하게 압축하고, R-SWA는 reference token을 계속 유지하면서 output-side KV cache만 sliding window로 제한한다.
이 조합은 문서 전체를 외부 for-loop로 쪼개는 대신, 모델 내부의 working memory 정책으로 긴 출력을 다루려는 시도다.
이 관점은 문서 RAG와 에이전트 시스템에 꽤 중요하다.
실제 업무 문서는 한 장짜리 이미지가 아니라 수십 페이지 보고서, 논문, 계약서, 매뉴얼, 스캔본으로 들어온다.
페이지별 OCR 결과를 붙이는 방식은 구현은 쉽지만, 모델이 “나는 지금 문서 전체에서 어디를 베껴 쓰고 있는가”를 내부 상태로 유지하지 못한다.
Unlimited-OCR은 이 문제를 attention 구조 차원에서 다루며, 그 결과 latency와 GPU memory가 출력 길이에 따라 계속 나빠지는 문제를 줄이려 한다.
동시에 이 릴리스를 과대해석하면 안 된다.
이름은 Unlimited지만, 보고서 스스로도 finite context length, 예를 들어 32K에서는 truly unlimited parsing이 아니라고 밝힌다. prefill length는 여전히 페이지 수와 해상도에 따라 길어지고, 더 많은 페이지를 넣으려면 128K 같은 longer context training 또는 prefill pool이 필요하다고 적는다.
즉 현재의 “unlimited”는 수학적으로 무한이라는 뜻이 아니라, 기존 페이지별 for-loop OCR보다 긴 horizon을 한 번의 디코딩 흐름으로 처리하려는 방향에 가깝다.
또 하나의 실무 caveat는 release maturity다.
Hugging Face 모델 카드의 실행 예시는 remote code 신뢰와 특정 GPU/CUDA stack을 요구하고, GitHub 저장소는 초기 공개 상태다.
OCR 품질이 중요한 법무·금융·의료·공공 문서에서는 모델 점수만으로 자동화를 닫기보다, 원문 region 링크, confidence/fallback 정책, human review, 문서 유형별 benchmark를 별도로 설계해야 한다.
그럼에도 Unlimited-OCR은 문서 AI에서 볼 만한 전환 신호다.
OCR이 단순히 “이미지에서 텍스트를 추출하는 전처리”라면 R-SWA 같은 attention 구조는 부차적일 수 있다.
하지만 OCR을 긴 문서 reference를 보며 구조화된 output을 계속 생성하는 decoding system으로 보면, KV cache와 attention window는 제품 품질과 비용을 결정하는 핵심 설계가 된다.
Unlimited-OCR의 가치는 이 질문을 명확하게 드러냈다는 데 있다.