egocentric video 기반 공간 추론은 겉보기보다 까다롭다.
모델은 방 안을 직접 돌아다니는 것이 아니라, 사람이 들고 움직인 카메라 궤적에 우연히 잡힌 프레임만 본다.
침대 뒤쪽, 책상 아래, 문 반대편처럼 답에 필요한 단서가 카메라 밖에 있으면, MLLM은 실제 3D 구조보다 학습 중 본 장면 priors로 빈칸을 채우기 쉽다.
그 결과 “그럴듯하지만 틀린” 물체 개수, 방향, 거리, route planning 답이 나온다.
Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning은 이 문제를 모델 재학습보다 추론 절차로 푼다.
핵심은 간단하다.
먼저 원본 egocentric video로 잠정 가설을 만들고, 그다음 같은 장면을 3D로 복원해 다른 시점의 video를 합성한 뒤, 처음 가설이 맞는지 다시 확인한다.
논문은 이 두 단계 프레임워크를 ReRe라고 부른다.
공개 자료 기준으로 논문은 ICML 2026에 게재 예정이며, 확인 가능한 companion artifact는 Hugging Face Papers 페이지, arXiv HTML/PDF와 공식 프로젝트 페이지다.
프로젝트 페이지의 Paper 버튼도 현재 arXiv PDF를 연결하며, 별도 공식 GitHub code/model repo 링크는 프로젝트 페이지와 arXiv HTML에서 확인되지 않았다.
한 번 보고 답하는 방식이 왜 흔들리는가
일반적인 video QA는 원본 video + 질문 → 답의 single-turn inference로 모델링된다.
공간 추론에서는 이 가정이 특히 약하다. egocentric video의 시간 순서는 실제 공간 topology와 다르고, 카메라가 움직인 경로 밖의 구조는 부분적으로만 보인다.
모델이 객체 관계를 명시적인 3D world model로 추적하지 않는다면, 보이지 않은 영역을 통계적 상식으로 메우게 된다.
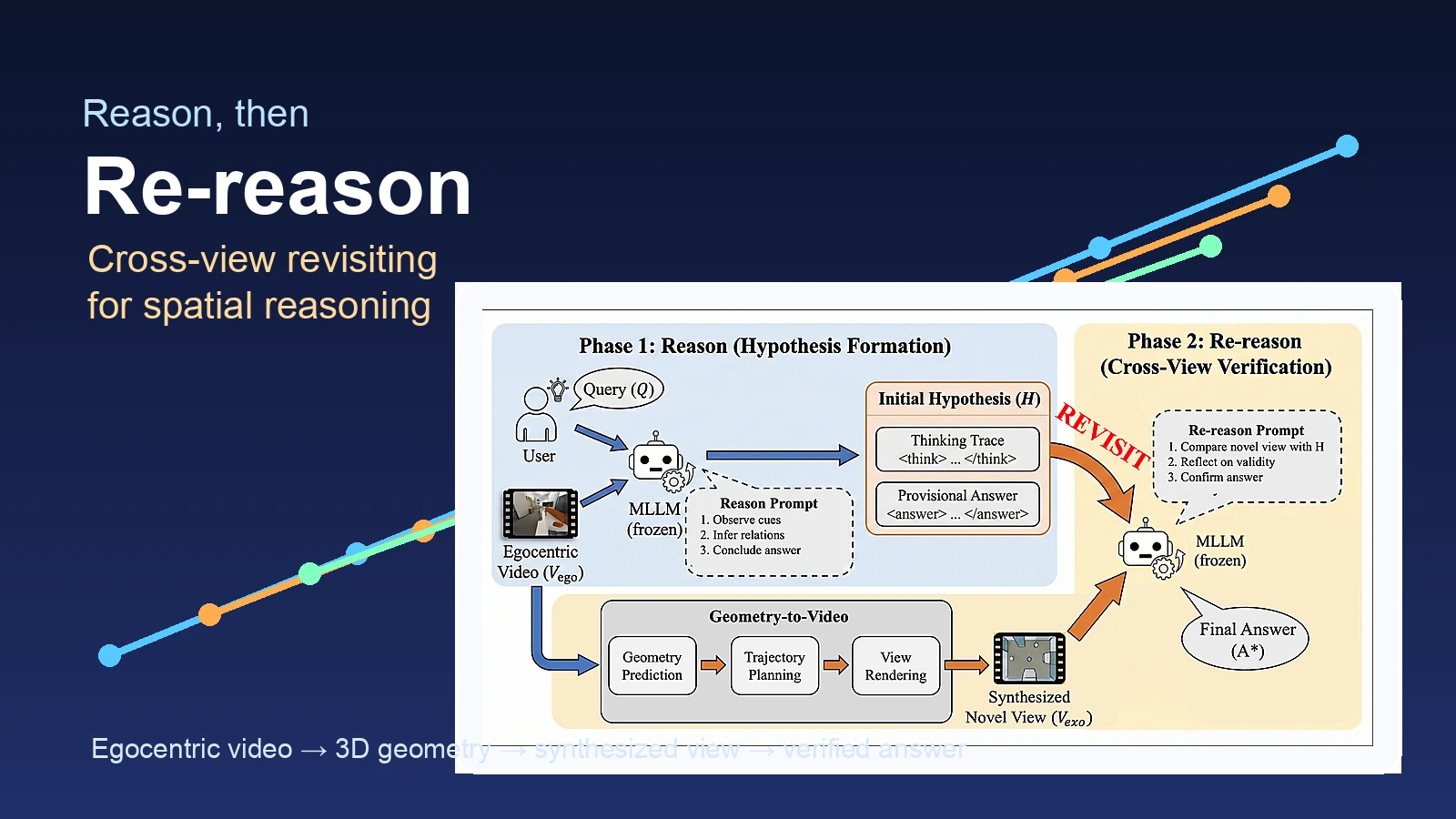
ReRe는 답을 바로 확정하지 않는다.
1단계 Reason Phase에서는 MLLM이 원본 video를 보고 관찰·추론·잠정 답을 만든다.
논문은 이 중간 결과를 H=(T, A~)로 두고, thinking trace T와 provisional answer A~를 분리한다.
2단계 Re-reason Phase에서는 합성된 novel-view video를 보고 처음 reasoning trace의 공간 주장들이 여전히 맞는지 비교한다.
틀렸다면 답을 수정하고, 맞다면 유지한다.
이 framing에서 중요한 점은 “생각을 한 번 더 한다”가 아니다.
새로운 관측을 들고 다시 본다가 핵심이다.
논문 ablation에서도 원본 video를 다시 보는 것만으로는 오히려 baseline보다 나빠진다.
같은 증거 위에서 한 번 더 추론하면 초기 환각을 증폭할 수 있기 때문이다.

ReRe 프레임워크: Reason → Re-reason
ReRe의 전체 흐름은 두 개의 MLLM call과 하나의 geometry-to-video module로 볼 수 있다.
- Reason Phase: 원본 egocentric video
V_ego와 질문Q를 MLLM에 넣어 관찰, 공간 관계 추론, 잠정 답을 만든다. - Geometry-to-Video: 원본 video에서 VGGT로 3D point cloud를 예측하고, 장면 전체를 비스듬히 훑는 camera trajectory를 설계한 뒤, point-based rasterization으로 allocentric video
V_exo를 렌더링한다. - Re-reason Phase:
V_exo와 1단계의 hypothesis를 함께 넣어, 기존 추론과 새 시점의 증거가 충돌하는지 비교하고 최종 답을 확정한다.
여기서 새 시점은 임의로 고르지 않는다.
논문은 geometric complementarity와 native compatibility라는 두 조건을 둔다.
첫째, 새 view는 원본 궤적에서 생긴 occlusion을 줄이고 장면 범위를 넓게 보여야 한다.
둘째, MLLM이 바로 먹을 수 있는 형식이어야 한다. raw point cloud나 depth map을 별도 encoder로 붙이는 대신, 기존 video interface로 들어갈 수 있는 frame sequence를 렌더링하는 이유다.
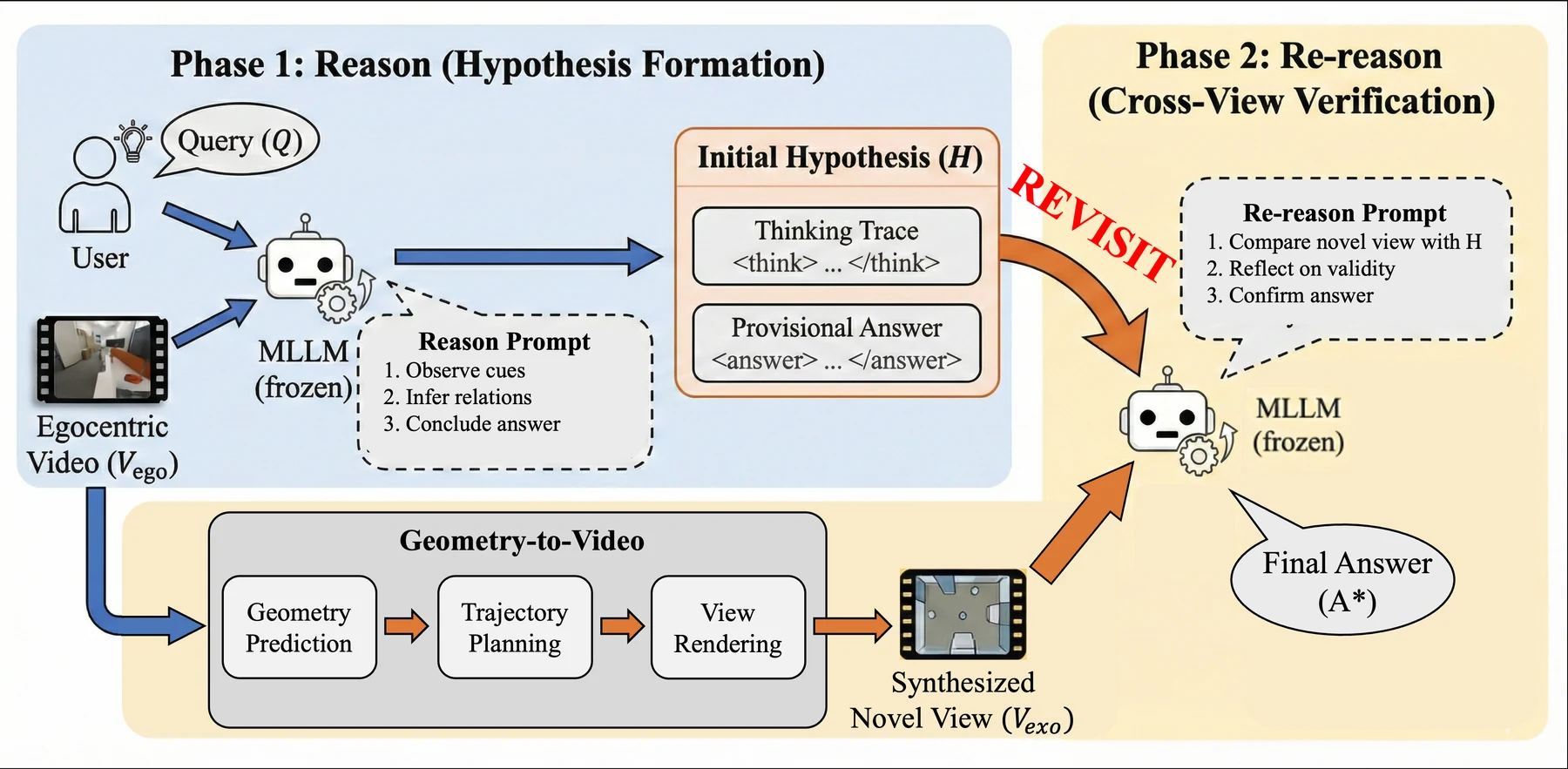
Geometry-to-Video: 3D 구조를 모델이 볼 수 있는 video로 바꾸기
Geometry-to-Video pipeline은 VGGT로 복원한 point cloud P_3D에서 scene center c와 horizontal radius r를 계산한다.
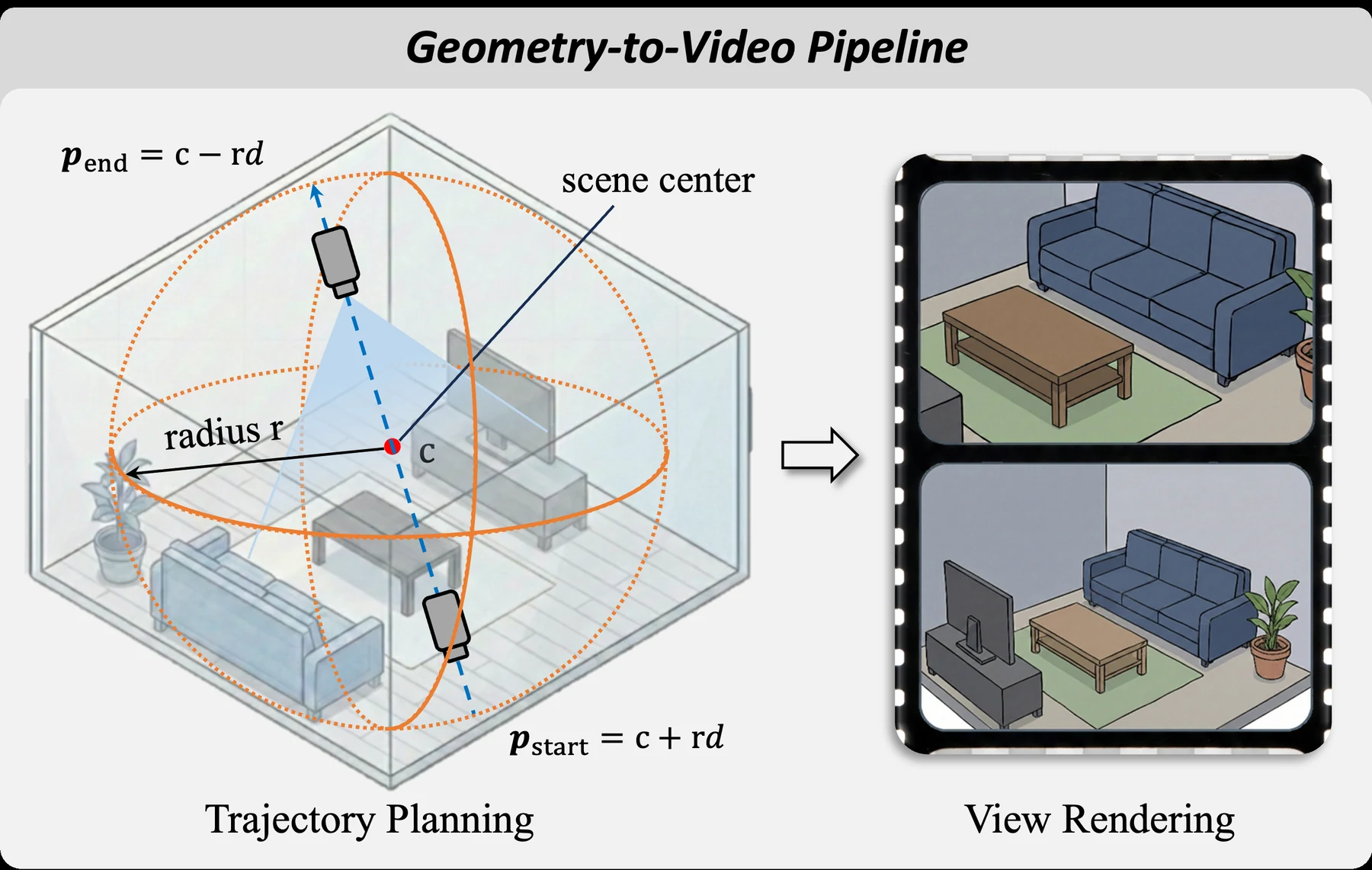
그 다음 camera position을 대각선 방향으로 움직이는 Oblique Sweep trajectory로 둔다.
직관적으로는 방을 위에서 수직으로 찍는 bird’s-eye view가 아니라, 장면 전체를 비스듬히 내려다보며 한쪽 끝에서 반대쪽 끝으로 훑는 움직임이다.
이 선택은 꽤 실용적이다. top-down orbit은 occlusion을 줄일 수 있지만 MLLM pretraining distribution에서 너무 멀어져 객체 인식이 흔들릴 수 있다.
반대로 eye-level traverse는 익숙한 시점이지만 원본 video와 비슷한 occlusion을 다시 겪는다.
Oblique Sweep은 높은 시점으로 가려진 구조를 노출하면서도, 완전한 평면도처럼 낯선 view가 되는 것을 피한다.
렌더링은 복잡한 neural rendering이 아니라 비교적 단순한 point-based rasterization 쪽에 가깝다.
논문은 Z-buffer depth ordering으로 가까운 점이 먼 점을 가리게 만들고, confidence가 낮은 point를 제거하며, per-frame median filtering으로 salt-and-pepper artifact를 줄인다.
중요한 설계 철학은 “완벽한 3D 재구성”이 아니다.
불확실한 영역은 억지로 채우지 않고 blank로 남기고, 원본 egocentric video는 semantic anchor로 유지한다.
합성 view는 새로운 사실을 창조하는 생성 모델이라기보다, 기존 video에서 회수한 coarse geometry를 다른 관측면으로 보여 주는 verification evidence다.
숫자로 보면: open-source MLLM의 약점을 inference-time evidence로 줄인다
VSI-Bench에서 ReRe는 여러 open-source MLLM family에 일관된 향상을 준다.
특히 Qwen 계열의 gain이 크다.
Qwen3-VL-4B는 평균 30.7에서 36.5로 올라 GPT-4o의 34.0을 넘고, Qwen3-VL-8B도 30.5에서 35.8로 오른다.
단일 benchmark의 평균 점수만으로 “proprietary model을 이겼다”고 일반화하면 과하지만, 적어도 이 설정에서는 모델 파라미터를 바꾸지 않고 관측 절차를 바꾸는 것만으로 상당한 차이가 난다는 신호다.
| 모델 / 설정 | VSI-Bench Avg. | 변화 | 읽을 점 |
|---|---|---|---|
| GPT-4o | 34.0 | - | 비교용 proprietary baseline |
| Qwen2.5-VL-7B | 24.8 → 29.5 | +4.7 | ReRe protocol ablation의 기본 backbone |
| Qwen3-VL-2B | 22.5 → 31.0 | +8.5 | 작은 모델에서 큰 gain |
| Qwen3-VL-4B | 30.7 → 36.5 | +5.8 | GPT-4o 평균을 넘는 대표 결과 |
| Qwen3-VL-8B | 30.5 → 35.8 | +5.2 | 더 큰 Qwen3에서도 유지 |
| InternVL2.5-8B | 35.5 → 36.7 | +1.2 | 이미 강한 backbone에서는 gain이 작음 |
| InternVL3-8B | 32.6 → 35.5 | +2.9 | relative direction·absolute distance 등에서 개선 |
STI-Bench Static Understanding subset에서도 비슷한 패턴이 나온다.
Qwen3-VL-2B는 평균 22.2에서 30.2로 +8.0, spatial relation은 31.5에서 50.0으로 크게 오른다.
InternVL2.5-8B는 32.1에서 34.8로 올라 GPT-4o의 31.0보다 높다.
다만 Gemini-2.5-Pro의 37.1에는 미치지 못한다.
따라서 이 결과는 “모든 closed model을 압도”라기보다, 특정 spatial benchmark에서 geometry-backed verification이 open model의 빈틈을 상당히 메운다로 읽는 편이 안전하다.
왜 그냥 두 view를 붙이면 안 되나
가장 흥미로운 ablation은 ReRe가 “view를 하나 더 준다” 이상의 효과를 낸다는 점이다.
논문은 Qwen2.5-VL-7B 기준으로 원본 view와 합성 view를 단순 concatenation하거나 interleaving하는 baseline을 비교한다.
| Reasoning protocol | VSI-Bench Avg. | 해석 |
|---|---|---|
| Baseline: 원본 video single-turn | 24.8 | 기존 방식 |
| Concat: 두 view를 한 video로 붙임 | 25.4 | temporal coherence가 깨져 작은 gain |
| Interleaved: view를 섞어 제시 | 25.6 | 정보는 늘지만 verification objective가 약함 |
| ReRe: 먼저 가설, 그다음 cross-view 검증 | 29.5 | 새 view를 “비판자”로 쓰는 구조가 핵심 |
이 차이는 agentic workflow 관점에서도 익숙하다.
많은 정보를 한 prompt에 넣는 것보다, 먼저 주장을 명시하고 그 주장을 검증하는 별도 단계로 나누면 오류가 더 잘 드러난다.
ReRe는 이를 visual spatial reasoning에 맞게 구현한다.
첫 단계의 trace가 있어야 두 번째 단계에서 “내가 아까 세운 공간 주장 중 무엇이 새 view와 충돌하는가”를 물을 수 있다.
컴포넌트 ablation도 같은 결론을 강화한다.
합성 view V_exo만으로 추론하면 평균 27.3으로 baseline보다 높지만 full ReRe의 29.5에는 못 미친다.
원본 view를 두 번 보는 방식은 23.5로 오히려 낮다.
즉 원본 video는 객체 semantic anchor로 필요하고, 합성 view는 구조적 disambiguation으로 필요하다.
비용: 추가 3D 복원이 병목이다
ReRe는 training-free지만 cost-free는 아니다.
논문은 Qwen3-VL-8B와 single A100 GPU 기준으로 latency를 측정한다.
| 설정 | MLLM 원본 view | VGGT | Render | MLLM 합성 view | Total | VSI Avg. |
|---|---|---|---|---|---|---|
| Single-turn baseline | ~1s | - | - | - | ~1s | 30.5 |
| ReRe, 100 frames | ~1s | ~9s | <1s | ~1s | ~11s | 35.8 |
| ReRe, 20 frames | ~1s | ~2s | <1s | ~1s | ~4s | 33.3 |
병목은 두 번째 MLLM call보다 VGGT reconstruction이다.
이 점은 장단점이 동시에 있다.
단점은 online interactive setting에서 매 sample마다 10초 안팎의 추가 비용이 생긴다는 것이다.
장점은 geometry backbone이 빨라지거나 scene별 geometry를 cache할 수 있으면 ReRe 자체의 reasoning protocol은 그대로 이득을 본다는 점이다.
같은 scene에 여러 질문을 던지는 embodied AI나 indoor assistant라면, geometry를 한 번 복원해 여러 query에 재사용하는 구성이 더 자연스럽다.
qualitative result: 틀린 답이 어떻게 뒤집히나
논문 appendix와 프로젝트 페이지는 ReRe가 답을 바꾸는 사례를 보여 준다.
물체 개수에서는 원본 view에 한 대만 보이던 monitor나 bed가 합성 view에서 두 번째 instance로 드러난다. absolute distance에서는 sofa와 bed 사이의 furniture 배치가 더 잘 보이며, relative direction에서는 window, door, lamp의 상대 위치가 새 view에서 정리되어 오른쪽/왼쪽 예측이 뒤집힌다.

sample-level flip analysis도 이 설명과 맞는다.
Qwen3-VL-8B 기준 ReRe 이후 답이 바뀐 sample은 전체의 15.65%이고, 그중 baseline wrong → ReRe correct가 71.6%, baseline correct → ReRe wrong이 28.4%다.
모든 변경이 좋은 것은 아니지만, positive flip이 negative flip보다 2.52배 많다. monocular 3D reconstruction의 noise가 있어도 coarse structural evidence의 이득이 더 큰 셈이다.
한계와 읽는 법
이 논문을 “MLLM이 이제 3D를 완벽히 이해한다”로 읽으면 곤란하다.
ReRe는 frozen MLLM에 explicit 3D world model을 내장하지 않는다.
대신, 외부 geometry model이 만든 view를 video evidence로 바꿔 보여 준다.
VGGT의 복원 품질, 입력 video의 coverage, scene complexity, 새 view의 artifact에 따라 실패할 수 있다.
논문도 low-confidence point를 blank로 남기고 원본 video를 semantic anchor로 유지하는 식으로 imperfect geometry를 전제로 설계한다.
또 하나의 실무 caveat는 release state다.
확인 가능한 공식 프로젝트 페이지에는 paper PDF와 visual/result summary가 있고, arXiv HTML에는 project page 링크가 있지만, 별도 code repository나 packaged implementation 링크는 보이지 않았다.
따라서 당장 reproducible library라기보다는, arXiv/project page에 공개된 inference-time framework 제안과 benchmark evidence로 보는 편이 맞다.
그래도 아이디어는 넓게 적용 가능하다. spatial QA뿐 아니라 robot navigation, AR/VR assistant, 실내 작업 지원 agent처럼 한 장면에 대해 여러 질문을 반복하는 시스템에서는 “한 번 본 뒤 답하기”보다 “먼저 가설을 세우고, 더 좋은 관측면으로 검증하기”가 자연스럽다.
특히 MLLM이 raw 3D를 직접 처리하지 못하는 현 상태에서는, 3D evidence를 model-native video format으로 바꿔 주는 우회가 꽤 현실적이다.
정리
ReRe의 메시지는 단순하다.
공간 추론에서 모델이 틀리는 이유가 “생각이 짧아서”만은 아니다.
애초에 보이는 증거가 부족할 수 있다.
그러면 해결책도 단순히 더 긴 reasoning prompt가 아니라, 부족한 증거를 다른 시점에서 다시 관측하게 하는 쪽이어야 한다.
이 논문의 기여는 세 가지로 압축된다.
- egocentric video spatial reasoning을 single-turn answer가 아니라 revisitable hypothesis verification으로 재정의한다.
- VGGT 기반 3D 복원과 Oblique Sweep rendering으로 frozen MLLM이 볼 수 있는 allocentric video evidence를 만든다.
- VSI-Bench와 STI-Bench에서 open-source MLLM의 공간 추론 점수를 일관되게 끌어올리며, 단순 view concatenation보다 structured revisiting이 중요하다는 ablation을 보인다.
개인적으로 가장 중요한 takeaway는 ReRe가 “새 모델”보다 “새 관측 절차”라는 점이다. multimodal model이 더 커지는 동안에도, 어떤 evidence를 어떤 순서로 보여 줄 것인가가 여전히 큰 성능 차이를 만들 수 있다.