멀티모달 모델에서 긴 비디오는 단순히 “프레임을 더 많이 넣으면 되는” 문제가 아니다.
10초 클립에서는 화면 설명과 객체 인식이 중요하지만, 30분·2시간짜리 영상에서는 필요한 장면을 잃지 않고 찾고, 시간 순서를 유지하고, 중간 사건을 나중 질문에 다시 끌어와야 한다.
프레임 수를 늘리면 KV cache와 attention 비용이 폭발하고, 프레임을 줄이면 결정적 단서가 빠진다.
결국 긴 비디오는 시각 인식 문제이면서 동시에 long-context retrieval / aggregation 문제가 된다.
Kwai Keye-VL-2.0 Technical Report와 Hugging Face 모델 카드가 공개한 Kwai-Keye/Keye-VL-2.0-30B-A3B는 이 문제를 꽤 노골적으로 시스템 문제로 다룬다.
모델은 30B급 Mixture-of-Experts지만 추론 시 약 3B parameter만 활성화한다고 설명하고, Qwen3-30B-A3B-Thinking-2507 계열 language decoder 위에 Keye-VL-1.5 vision encoder, native-resolution visual encoding, GQA에 맞춘 DeepSeek Sparse Attention(DSA)을 결합한다.
포인트는 “큰 VLM 하나”라기보다, 장시간 비디오를 256K context로 유지하면서도 계산비를 통제하는 멀티모달 MoE stack이라는 데 있다.
공개 표면도 논문 하나로 끝나지 않는다.
HF Papers 항목은 arXiv HTML, 모델 카드, checkpoint, Keye GitHub repo, SGLang custom branch, DeepGEMM support branch, EffectiveKernels repo로 이어진다.
확인 시점의 HF API 기준 모델은 Apache-2.0 태그, image-text-to-text pipeline, gated false이며, model.safetensors.index.json의 total size는 약 62.24GB다.
따라서 이 릴리스는 “가볍게 pip install해서 노트북에서 돌리는 데모”라기보다, H800류 GPU와 SGLang/커스텀 커널을 전제로 한 장시간 비디오 추론 패키지에 가깝다.
무엇을 해결하려는가
Keye-VL-2.0이 겨냥하는 병목은 두 개다.
첫째는 긴 비디오의 context scaling이다.
논문은 256K multimodal context를 지원하려면 dense attention만으로는 KV cache와 prefill 비용이 감당되지 않는다고 본다.
특히 비디오는 프레임마다 visual token이 생기고, 장면 간 evidence가 멀리 떨어져 있기 때문에 단순 subsampling은 temporal continuity를 깨기 쉽다.
Keye-VL-2.0은 이 지점을 DSA로 푼다.
모든 과거 token을 똑같이 보지 않고, global indexer가 중요한 token subset을 고른 뒤 GQA group별 sparse aggregation을 수행한다.
둘째는 멀티태스크 post-training에서 생기는 capability conflict다.
비디오 grounding, OCR, STEM, code, tool use, search를 한 모델에 몰아넣으면 한쪽 능력을 올리는 RL이 다른 쪽 reasoning이나 응답 스타일을 망가뜨릴 수 있다.
논문은 이를 “Multimodal Alignment Dilemma”로 부르고, Cross-Modal Multi-Teacher On-Policy Distillation(MOPD)로 해결하려 한다.
핵심은 domain-specific RL teacher를 여러 개 만든 뒤, student가 실제로 생성한 on-policy trajectory 위에서 token-level feedback을 주고, 이를 다시 하나의 MoE backbone에 합치는 것이다.
이 두 병목은 서로 연결되어 있다.
긴 비디오를 잘 보려면 sparse long-context architecture가 필요하고, 그 모델을 실제 agent 환경에서 쓰려면 code/tool/search 같은 비시각 능력도 망가지면 안 된다.
Keye-VL-2.0의 설계는 장시간 비디오 모델과 agent model을 따로 두는 대신, 긴 시각 evidence를 읽고 도구·검색·코드 trajectory까지 이어가는 하나의 multimodal agent backbone을 만들려는 시도로 읽힌다.
핵심 아이디어 / 구조 / 동작 방식
모델 구조는 표준 MLLM 구조를 따르지만 각 부품의 목표가 분명하다. vision encoder는 Keye-VL-1.5-8B에서 이어받은 SigLIP-400M-384-14 기반 ViT이고, language decoder는 Qwen3-30B-A3B-Thinking-2507 기반이다.
둘 사이에는 Stage 0에서 먼저 학습하는 MLP projector가 들어가며, decoder attention에는 GQA-compatible DSA module이 붙는다.
HF config 기준으로 모델은 48 layers, hidden size 2048, 32 attention heads, 4 key-value heads, 128 experts, token당 8 experts를 사용하고, max_position_embeddings는 262,144로 설정되어 있다.
시각 입력 쪽에서는 native-resolution encoding을 강조한다.
고정 해상도 ViT에 맞춰 이미지를 억지로 자르거나 늘리는 대신, adaptive position encoding과 2D RoPE, NaViT-style Patch n’ Pack, FlashAttention을 조합해 다양한 크기와 종횡비를 그대로 처리한다.
비디오도 별도 video encoder를 새로 두기보다, 각 sampled frame을 high-resolution image처럼 인코딩하고 frame 앞에 자연어 timestamp를 붙인다.
시간 정보는 language decoder가 읽을 수 있는 텍스트 anchor로 들어가고, adaptive video pixel budget은 짧은 영상은 더 강하게 압축하고 긴 영상은 더 많은 evidence를 보존한다.

DSA는 이 모델의 가장 중요한 시스템적 선택이다.
논문은 Lightning Indexer가 현재 query와 과거 token의 global index score를 계산하고, Top-k token set을 고른 뒤, GQA group별 sparse attention을 수행한다고 설명한다.
설정상 k=2048을 사용해 attention complexity를 O(L²)에서 O(Lk)로 낮춘다.
중요한 점은 대부분의 DSA가 MLA 기반 구조에서 논의되는 반면, Keye-VL-2.0은 GQA 기반 MLLM backbone에 DSA를 맞췄다고 주장한다는 점이다.
이는 기존 GQA serving stack과 연결할 수 있는 실용적 경로를 노린다.
학습도 곧장 sparse attention으로 밀어붙이지 않는다.
먼저 dense warm-up에서 GQA group들의 attention distribution을 모아 indexer가 dense model의 attention 행동을 덮도록 KL loss로 맞춘다.
그 다음 sparse adaptation에서 Top-k로 잘린 token set 위에서 indexer와 본 모델을 함께 적응시킨다.
이렇게 하면 sparse indexer가 처음부터 빈약한 supervision으로 학습하는 문제를 줄이고, long-context 평가에서 dense model의 능력을 보존하면서 inference overhead를 낮추는 쪽으로 유도할 수 있다.
공개된 근거에서 확인되는 점
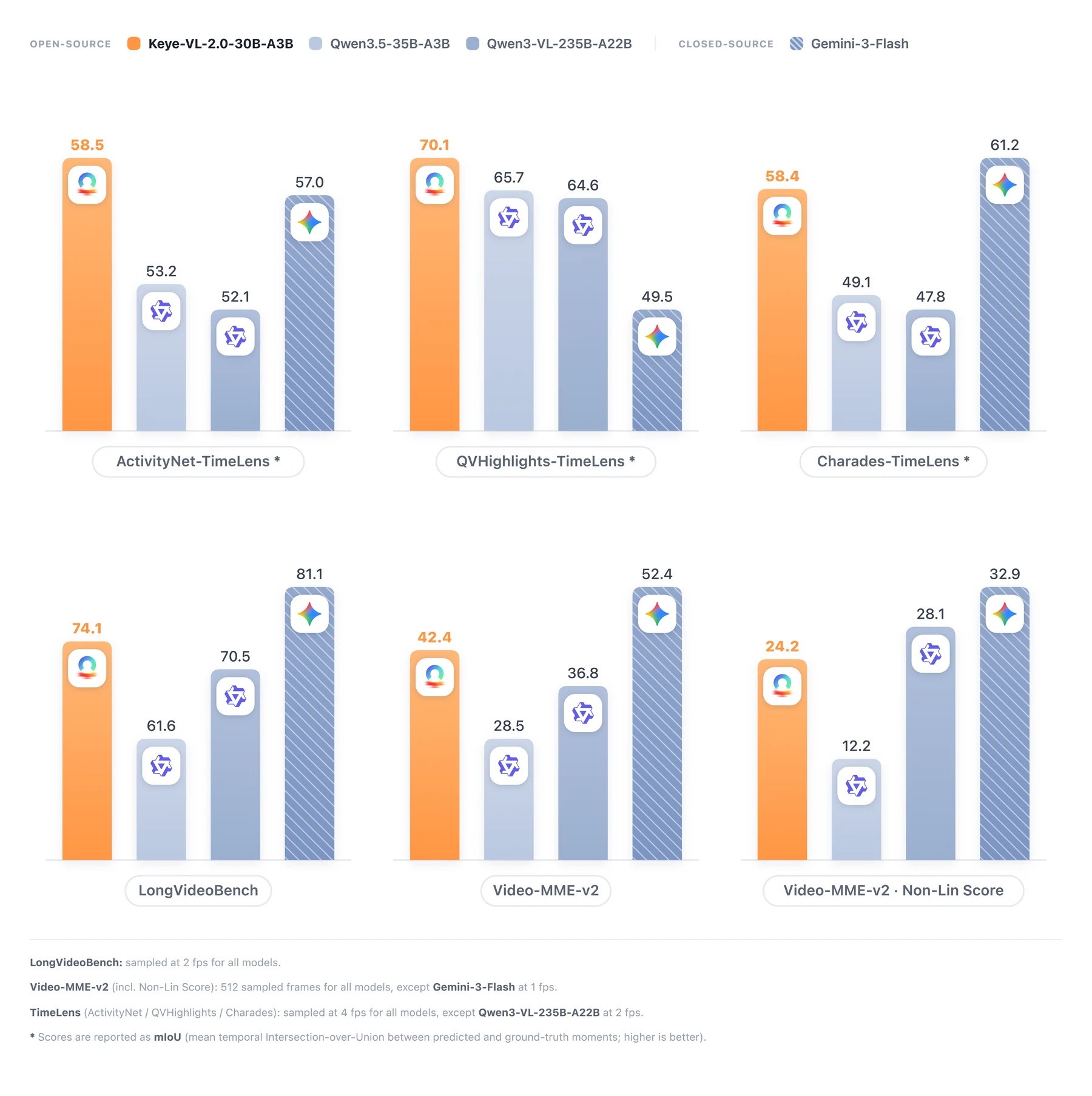
릴리스가 주장하는 성능의 중심은 긴 비디오다.
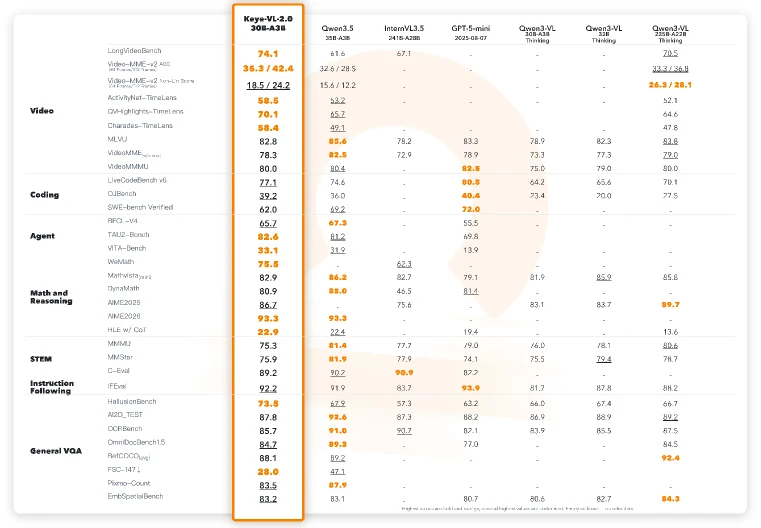
논문 Table 2 기준 Keye-VL-2.0은 LongVideoBench 74.1을 기록해 Qwen3.5-35B-A3B의 61.6보다 12.5점, Qwen3-VL-235B-A22B Thinking의 70.5보다 3.6점 높다.
Video-MME-v2 ACC에서는 64 frames 35.3에서 512 frames 42.4로 올라간다.
같은 표에서 Qwen3.5-35B-A3B는 32.6에서 28.5로 내려가고, Qwen3-VL-235B-A22B는 33.3에서 36.8로 오른다.
즉 Keye-VL-2.0의 headline은 단순 정확도보다 프레임 수가 늘 때 성능이 무너지지 않고 오히려 좋아진다는 쪽에 있다.
Temporal grounding에서도 강하게 포지셔닝한다.
TimeLens 기준 ActivityNet-TimeLens 58.5, QVHighlights-TimeLens 70.1, Charades-TimeLens 58.4를 보고하며, 논문은 세 subset 모두에서 최고 mIoU라고 설명한다.
이 결과는 pretraining의 scene-wise dense caption, 다양한 Temporal Video Grounding(TVG) 데이터, Video RL의 tIoU 중심 reward와 연결되어 있다.
모델이 긴 영상을 “요약”하는 것뿐 아니라, 어떤 구간이 근거인지 찾는 능력을 직접 학습했다는 주장이다.
Agentic capability도 별도로 평가한다.
Code 쪽에서는 LiveCodeBench v6 64.2, OJBench 71.5, SWE-bench Verified 62.0을 보고한다.
Tool-use 쪽에서는 BFCL-V4 65.7, τ²-Bench 82.6, VitaBench 33.1이다.
이 숫자는 “비디오 모델이 코드도 한다”는 홍보 문구라기보다, MOPD와 Agentic RL의 목표가 단순 VQA가 아니라 multi-step environment interaction까지 포함한다는 근거로 보는 편이 맞다. tool-use RL은 150개 이상 simulated API domain에서 상태 전이와 post-condition을 reward로 보고, search RL은 retrieval action과 결과 읽기, final-answer correctness를 묶는다.
| 관찰 축 | 공개 수치 / 상태 | 해석 |
|---|---|---|
| Model size | 30B MoE, 약 3B active parameter | dense 30B처럼 매 token 전체를 쓰는 모델이 아니라 sparse compute를 전제로 한다 |
| Context | 262,144 max position embeddings | 장시간 비디오·긴 문서·agent trajectory를 같은 long-context 문제로 다룬다 |
| HF checkpoint | index metadata 기준 약 62.24GB | 개인 노트북용 경량 모델이 아니라 multi-GPU serving 대상이다 |
| Video-MME-v2 ACC | 35.3 → 42.4, 64→512 frames | denser visual context를 넣었을 때 성능이 +7.1점 오른다 |
| LongVideoBench | 74.1 | 같은 표의 Qwen3.5-35B보다 +12.5점, Qwen3-VL-235B보다 +3.6점 |
| GitHub release surface | Keye repo latest release 404, tag 목록 비어 있음 | 공개 초기 main-branch 중심 artifact로 봐야 한다 |
DSA와 MOPD가 왜 같이 필요한가
DSA만 보면 Keye-VL-2.0은 long-context inference optimization 논문처럼 보인다.
하지만 post-training 절반을 읽으면 그림이 조금 달라진다.
긴 비디오를 잘 보는 모델을 만들었다 해도, 실제 사용자는 “이 영상에서 이상 구간을 찾아 요약하고, 관련 문서를 검색하고, 결과를 표로 정리하고, 필요하면 코드를 실행해 후처리해 줘” 같은 요청을 한다.
그러면 모델은 시각 evidence retrieval, reasoning, tool call, search, code edit를 한 trajectory 안에서 섞어야 한다.
MOPD는 이 혼합에서 생기는 충돌을 줄이려는 장치다.
논문에 따르면 MOPD는 safety, pure-text math, instruction following, code, visual STEM, OCR, grounding, counting, video, tool use 등 13개 RL-trained domain teacher를 유지한다.
각 sample은 modality와 task type에 맞는 teacher로 routing되고, student가 먼저 생성한 on-policy response token들에 대해 teacher가 top-k overlap 기반 feedback을 준다. full vocabulary distillation 대신 teacher와 student가 모두 plausible하다고 보는 token 영역에서 advantage를 계산해 안정성을 높이려는 설계다.
이 접근의 장점은 domain별 response style을 하나로 강제하지 않는다는 데 있다.
예를 들어 reasoning RL을 많이 하면 답변이 지나치게 길어질 수 있고, agent training을 많이 하면 일반 대화에도 tool-call formatting이 묻어날 수 있다.
MOPD는 token-category-aware advantage scaling으로 format token은 낮추고 perception/reasoning token은 올리며, repetition collapse가 생기면 해당 위치 이후만 penalty를 주는 식으로 domain conflict를 국소화한다.
실무적으로는 “여러 전문가 모델을 따로 serving한다”가 아니라, 전문가들의 feedback을 하나의 student MoE에 증류하는 통합 전략이다.
실무 관점에서의 해석
이 모델의 가장 흥미로운 지점은 “오픈소스 VLM도 긴 비디오를 본다”가 아니라, 장시간 비디오 이해를 데이터·커널·serving·post-training이 함께 맞물린 시스템으로 설계했다는 점이다.
ExtraIO로 video decoding과 frame sampling I/O를 분리하고, ViT와 LM을 서로 다른 sharding strategy로 co-locate하며, long-video batch에서 visual-token ratio와 sequence length 불균형을 두 레벨로 load balancing한다.
논문은 이 설계가 end-to-end training throughput을 약 20% 높인다고 설명한다.
추론 쪽도 마찬가지다.
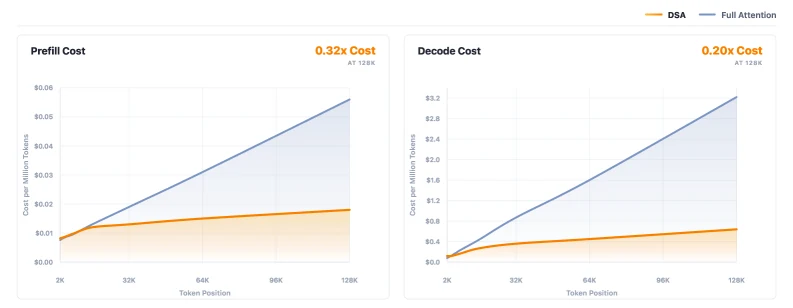
Chunk ViT로 frame을 나눠 처리해 peak memory를 낮추고, DSA sparse attention에서는 인접 query들이 고르는 Top-k KV set이 비슷하다는 점을 이용해 deduplication을 한다.
논문은 128K context에서 top-k=2048일 때 16개 adjacent query가 약 8K effective KV token만 필요하다고 설명한다.
또 prefill cost는 3배 이상, decode cost는 5배 이상 낮춘다고 주장한다.
이런 수치는 모델 품질만이 아니라 실제 긴 영상 처리 비용의 병목을 겨냥한다.
다만 도입 관점에서는 caveat가 분명하다.
HF 모델 자체는 Apache-2.0 tag와 gated false로 공개되어 있지만, Keye 메인 GitHub repo는 확인 시점 기준 license 필드가 없고 latest release와 tag가 없다.
모델 카드의 quickstart도 prebuilt Docker, custom SGLang branch, Keye support DeepGEMM branch, EffectiveKernels 설치를 안내한다.
즉 일반 transformers-only 사용보다는 custom serving stack에 가깝고, 운영 재현성은 checkpoint 공개만으로 충분하지 않다.
또한 논문 표에는 baseline별 미공개 score, evaluation condition 차이, 자체 평가한 TimeLens/Gemini 비교가 섞여 있으므로 leaderboard 숫자는 실사용 데이터로 재검증해야 한다.
그럼에도 Keye-VL-2.0은 2026년 멀티모달 모델의 방향을 잘 보여 준다.
비디오는 점점 더 길어지고, 사용자 요청은 단순 QA에서 agent trajectory로 이동하며, 모델은 OCR·수학·코드·검색·툴을 동시에 잃지 않아야 한다.
Keye-VL-2.0의 답은 dense 거대화만이 아니라 sparse context routing, staged video curriculum, domain-specific RL teacher, on-policy distillation, 그리고 커널/serving 최적화를 한 묶음으로 가져가는 것이다.
장시간 멀티모달 agent를 만들려면, 이제 모델 architecture와 post-training뿐 아니라 I/O와 inference kernel까지 함께 설계해야 한다는 메시지다.
참고 링크
- 요청 소스: Hugging Face Papers 2606.10651
- arXiv: Kwai Keye-VL-2.0 Technical Report / HTML
- Hugging Face model: Kwai-Keye/Keye-VL-2.0-30B-A3B
- Project page: kwai-keye.github.io
- GitHub: Kwai-Keye/Keye
- Serving dependencies: Kwai-Keye/sglang, Kwai-Keye/DeepGEMM, Kwai-Keye/EffectiveKernels