에이전트 스킬은 이제 단순한 프롬프트 조각이 아니다.SKILL.md가 지침을 담고, scripts·templates·resources가 실행 가능한 작업 절차를 보조하며, Claude Code, Codex CLI, Gemini CLI 같은 도구는 이 패키지를 신뢰하고 호출한다.
문제는 이 신뢰가 상당히 빠르게, 그리고 자주 암묵적으로 부여된다는 점이다.
스킬은 파일을 읽고, 쉘을 실행하고, 네트워크를 호출하고, 때로는 에이전트의 장기 기억이나 출력 경로까지 건드릴 수 있다.
NVIDIA의 SkillSpector는 이 흐름에서 “설치하기 전에 이 스킬을 믿어도 되는가”라는 질문을 도구화하려는 저장소다.
README는 SkillSpector를 AI agent skills용 보안 스캐너로 설명하고, Git 저장소·URL·zip·디렉터리·단일 SKILL.md 파일을 입력으로 받아 취약 패턴, 악성 의도, 공급망 리스크를 점검한다고 밝힌다.
흥미로운 지점은 이것이 일반 코드 보안 스캐너라기보다, 에이전트가 읽는 자연어 지침과 실제 실행 코드 사이의 consent gap을 겨냥한다는 점이다.
배경 숫자도 꽤 강하다.
SkillSpector가 인용하는 Agent Skills in the Wild 논문은 두 주요 마켓플레이스에서 42,447개 스킬을 수집하고 31,132개를 분석한 결과, 26.1%가 적어도 하나의 취약점을 포함했고 5.2%는 악성 의도를 강하게 시사하는 고위험 패턴을 보였다고 보고한다.
특히 실행 스크립트를 포함한 스킬은 instruction-only 스킬보다 취약할 가능성이 2.12배 높았다.
SkillSpector는 이 문제를 “좋은 스킬을 많이 모으자”가 아니라 “스킬을 설치하기 전 검수 가능한 보안 관문을 만들자”로 바꿔 읽는다.
무엇을 해결하려는가
에이전트 스킬의 위험은 전통적인 패키지 보안과 닮았지만, 완전히 같지는 않다.
일반 라이브러리는 주로 코드 실행과 의존성 리스크를 본다.
반면 스킬은 자연어 instruction이 에이전트의 행동 정책 일부가 되고, helper script가 실제 권한을 행사하며, metadata와 trigger가 어떤 상황에서 스킬이 활성화될지를 결정한다.
그래서 악성 스킬은 코드만 숨기는 것이 아니라, 설명·트리거·매개변수 설명·주석·zero-width character·base64 blob 같은 텍스트 표면에도 공격을 넣을 수 있다.
이런 환경에서 “README가 괜찮아 보인다”는 충분하지 않다.
사용자가 승인한 것은 대개 “PDF를 정리해 주는 스킬”이나 “테스트를 자동화하는 스킬” 같은 기능적 설명이다.
하지만 실제 번들 안에는 홈 디렉터리 탐색, 환경 변수 수집, 외부 URL 전송, curl | bash, broad trigger, 자체 설정 변경 같은 행동이 숨어 있을 수 있다.
SkillSpector의 문제의식은 바로 이 간극이다.
스킬이 주장하는 목적과 실제 파일·스크립트·권한·의존성 표면을 함께 봐야 한다.
또 하나 중요한 맥락은 스킬 생태계가 빠르게 marketplace화되고 있다는 점이다.
Anthropic 계열의 SKILL.md, Codex/Cursor/Gemini식 확장 패키지, MCP 도구 메타데이터가 늘어날수록, 개인이나 팀이 수동으로 모든 스킬을 감사하기는 어려워진다.
SkillSpector는 이 병목을 CLI와 CI가 이해할 수 있는 보안 리포트로 바꾸려는 시도다.
핵심 아이디어 / 구조 / 동작 방식
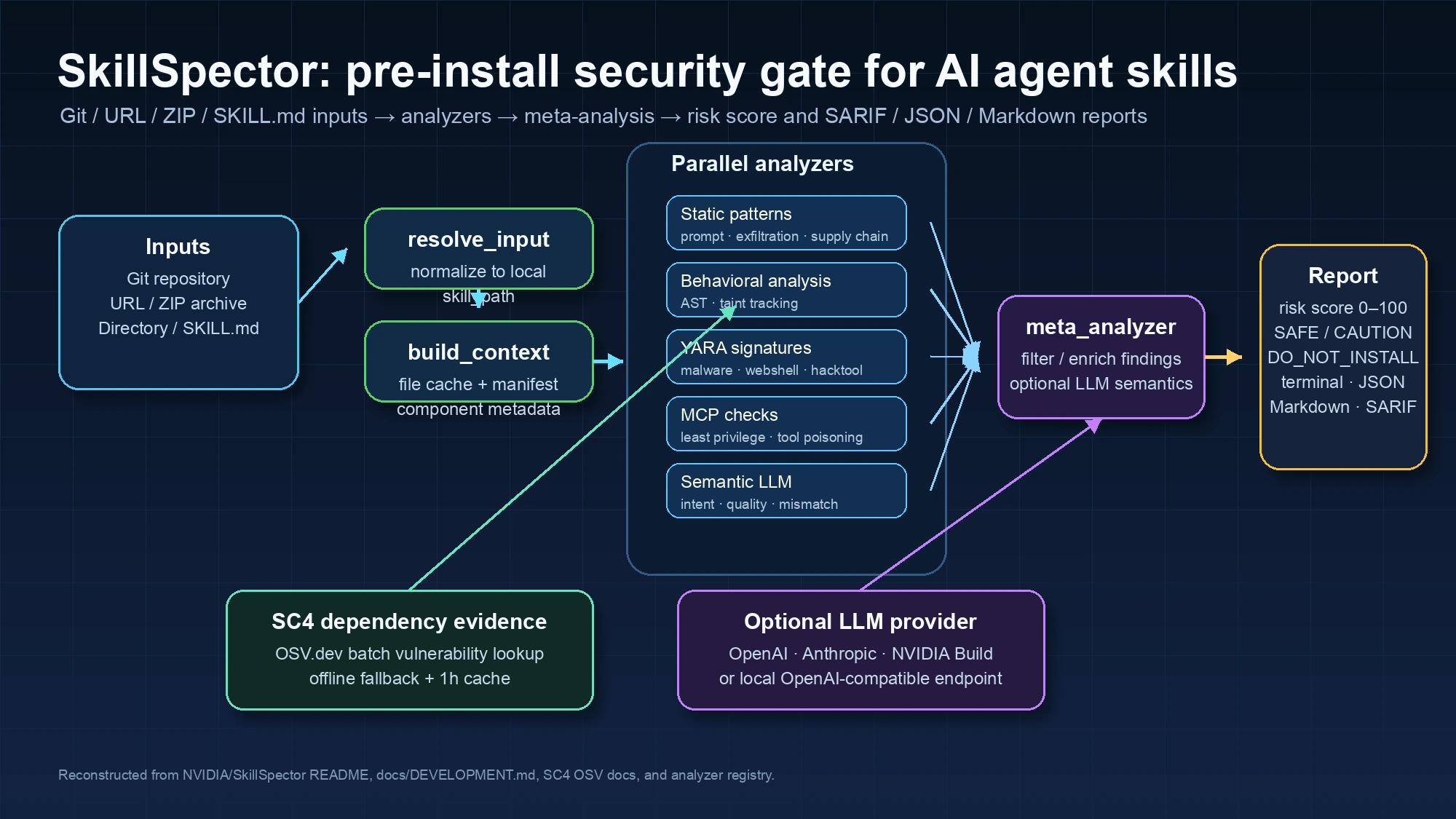
SkillSpector의 구현은 Python 3.12+ 기반 CLI와 LangGraph workflow로 구성된다. skillspector scan <path-or-url> 명령은 먼저 입력을 로컬 분석 대상으로 정규화한다.
공식 development guide 기준 resolve_input 단계는 Git URL, file URL, zip, 단일 .md 파일, 디렉터리를 받아 skill_path로 변환하고, 이후 build_context가 파일 목록, 캐시, manifest, component metadata, executable script 여부를 만든다.
그 다음은 병렬 분석 단계다.
공개 코드의 analyzer registry에는 20개 노드가 등록되어 있고, README는 16개 범주에 걸친 64개 취약 패턴을 제시한다.
범주는 prompt injection, data exfiltration, privilege escalation, supply chain, excessive agency, output handling, system prompt leakage, memory poisoning, tool misuse, rogue agent, trigger abuse, behavioral AST, taint tracking, YARA signatures, MCP least privilege, MCP tool poisoning으로 나뉜다.
분석 방식은 크게 두 층이다.
첫 번째는 빠른 정적 분석이다.
정규식 패턴, Python AST, taint tracking, YARA rule, 의존성 manifest, MCP permission metadata를 통해 명시적 위험 신호를 잡는다.
예를 들어 exec()나 eval(), subprocess, credential file 접근, 외부 전송, unpinned dependency, wildcard permission, description과 실행 capability의 불일치 같은 신호가 여기에 들어간다.
두 번째는 선택적 LLM 의미 분석이다.SKILLSPECTOR_PROVIDER로 OpenAI, Anthropic, NVIDIA build.nvidia.com 계열 provider를 고를 수 있고, 로컬 Ollama·vLLM·llama.cpp처럼 OpenAI-compatible endpoint도 연결할 수 있다.
LLM 단계는 정적 패턴만으로 판단하기 어려운 의도, 설명-행동 불일치, 정책 위반 가능성을 보완한다.
리포트 생성은 보안 제품 관점에서 꽤 중요하다.
SkillSpector는 terminal, JSON, Markdown, SARIF를 출력할 수 있다.
SARIF는 GitHub code scanning이나 IDE security workflow에 붙이기 좋은 표준 포맷이다.
즉 이 도구의 목표는 “터미널에서 경고 몇 줄 보기”에 그치지 않고, 스킬 설치 전 검수 결과를 CI/CD와 팀 리뷰 프로세스에 연결하는 데 있다.
공개된 근거에서 확인되는 점
조회 시점의 GitHub API 기준 NVIDIA/SkillSpector는 공개 저장소이며 Apache-2.0 라이선스를 사용한다.
저장소는 2026년 3월 21일 생성되었고, 최근 push는 2026년 6월 10일, stars는 4,170, forks는 317로 확인된다. pyproject.toml의 패키지 버전은 2.1.3이고 classifier는 Development Status :: 3 - Alpha다.
최신 GitHub release와 tags는 비어 있었고, pip index versions skillspector에서도 배포판은 확인되지 않았다.
따라서 현재 공개 표면은 PyPI에서 안정적으로 설치하는 제품 패키지라기보다, GitHub clone 후 make install로 사용하는 초기 공개 코드베이스에 가깝다.
공식 README의 기능 표면은 꽤 넓다.
| 축 | 공개 문서에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| 입력 | Git repo, URL, zip, directory, single file | 외부 스킬을 설치 전 임시로 가져와 검사하는 흐름에 맞음 |
| 분석 | 64 patterns / 16 categories, static + optional LLM | 명시적 코드 패턴과 의미적 intent risk를 함께 보려는 설계 |
| 의존성 보안 | SC4가 OSV.dev batch API로 PyPI/npm 취약점 조회 | 별도 API key 없이 최신 CVE 데이터와 연결 가능 |
| 출력 | Terminal, JSON, Markdown, SARIF | 사람용 리뷰와 자동화 파이프라인을 동시에 겨냥 |
| 점수화 | 0-100 risk score, severity, install recommendation | 스킬 설치 여부를 정책화하기 쉬움 |
리스크 스코어링도 단순하지만 이해하기 쉽다.
CRITICAL finding은 50점, HIGH는 25점, MEDIUM은 10점, LOW는 5점을 더하고, 실행 스크립트가 있으면 1.3배 multiplier를 적용한다.
최종 점수는 0-20 LOW/SAFE, 21-50 MEDIUM/CAUTION, 51-80 HIGH/DO_NOT_INSTALL, 81-100 CRITICAL/DO_NOT_INSTALL로 해석된다.
이 방식은 정교한 확률 모델이라기보다, 리뷰 큐에서 위험한 스킬을 먼저 보게 만드는 triage score로 보는 편이 맞다.
OSV.dev 연동은 특히 실용적이다. docs/SC4-osv-live-vulnerability-lookups.md는 SC4 rule이 dependency를 OSV batch endpoint로 질의하고, 실패하면 fallback list로 degrade한다고 설명한다. no-key API, batch query, 1시간 in-memory cache는 개인 CLI와 CI 모두에 적합한 절충이다.
다만 네트워크가 없는 환경에서는 정적 fallback에 제한되므로, air-gapped 환경의 결과를 “취약점 없음”으로 읽으면 안 된다.
실무 관점에서의 해석
내가 보기에 SkillSpector의 가장 중요한 의미는 에이전트 스킬을 문서가 아니라 설치 가능한 공급망 artifact로 취급한다는 점이다.
지금까지 많은 스킬 논의는 “좋은 SKILL.md를 어떻게 쓰는가”, “어떤 스킬을 검색해 쓸 것인가”에 집중했다.
SkillSpector는 그 앞단에 “그 스킬이 안전한가”라는 gate를 놓는다.
팀이 공개 스킬을 가져오거나, 사내 스킬 마켓플레이스를 운영하거나, Codex/Claude/Cursor용 패키지를 공유하려면 이 gate는 점점 더 중요해진다.
특히 이 도구가 보는 공격 표면은 에이전트 시대에 특화되어 있다. prompt injection이나 system prompt leakage는 일반 SAST가 자연스럽게 잡는 범주가 아니다. trigger abuse, memory poisoning, MCP tool poisoning, description-behavior mismatch도 마찬가지다.
에이전트 런타임에서는 자연어가 실행 컨텍스트이고, 메타데이터가 라우팅 신호이며, helper script가 실제 권한을 행사한다.
그래서 보안 스캐너도 코드 AST만 보는 것이 아니라 SKILL.md와 metadata, permission, trigger, dependency를 함께 봐야 한다.
동시에 성숙도는 분리해서 봐야 한다. no releases/tags, PyPI 배포 부재, alpha classifier는 운영 환경에 바로 무비판적으로 넣을 단계가 아니라는 신호다.
README의 기능 범위는 넓지만, 실제 도입에서는 어떤 analyzer가 조직의 스킬 포맷과 잘 맞는지, LLM provider를 쓸 때 비용과 데이터 경계가 괜찮은지, SARIF finding을 누가 triage할지, false positive를 어떻게 suppress할지 별도 정책이 필요하다.
즉 SkillSpector는 “스킬 보안 문제를 끝내는 제품”이라기보다, 스킬 보안 리뷰를 자동화 가능한 워크플로로 만드는 출발점에 가깝다.
그럼에도 방향성은 분명하다.
에이전트 스킬이 팀의 운영 자산이 되려면 작성·검색·추천만으로는 부족하다.
설치 전 검수, 권한 선언, 취약 의존성 조회, 악성 자연어 지침 탐지, CI에서의 반복 검사, 리뷰 가능한 리포트가 필요하다.
SkillSpector는 이 요구를 하나의 CLI와 LangGraph pipeline으로 묶어 보여준다.
스킬 생태계가 커질수록 “좋은 스킬을 더 많이 쓰자”보다 먼저 물어야 할 질문은 이것일 수 있다.
이 스킬을 내 에이전트에게 실행 권한과 문맥 권한을 주어도 되는가?