로봇용 Vision-Language-Action(VLA) 모델에서 가장 어려운 지점은 단순히 “모델이 장면을 잘 이해하는가”가 아니다.
드론처럼 빠르게 움직이는 플랫폼에서는 모델이 설명을 잘하는 것과, 다음 제어 업데이트 전에 유효한 guidance를 내는 것이 완전히 다른 요구사항이 된다.
긴 문장 하나를 생성하느라 수백 밀리초를 쓰면 의미론적으로는 좋아 보여도 비행 제어 루프에서는 이미 늦을 수 있다.
LiteVLA-H는 이 문제를 정면으로 시스템 관점에서 다룬다.
이 arXiv 논문은 256M 파라미터의 compact VLA를 NVIDIA Jetson AGX Orin에 올리고, 하나의 멀티모달 백본을 두 개의 속도로 호출한다.
빠른 경로는 짧은 action token을 내는 외부 guidance 루프이고, 느린 경로는 장면 설명, hazard 서술, operator-facing narration 같은 semantic perception 루프다.
핵심 관찰은 꽤 실용적이다.
이 edge regime에서는 디코딩 토큰 몇 개를 줄이는 것보다, 이미지와 프롬프트를 모델 내부 표현으로 넣는 multimodal pre-fill이 훨씬 큰 병목이다.
논문 수치 기준으로 action query latency 50.65ms 중 pre-fill이 47.8ms를 차지한다.
즉 액션 출력이 한 토큰이든 아주 짧은 문장이든, 첫 액션을 빨리 내려면 decode 길이보다 pre-fill 경로와 스케줄링을 먼저 봐야 한다.
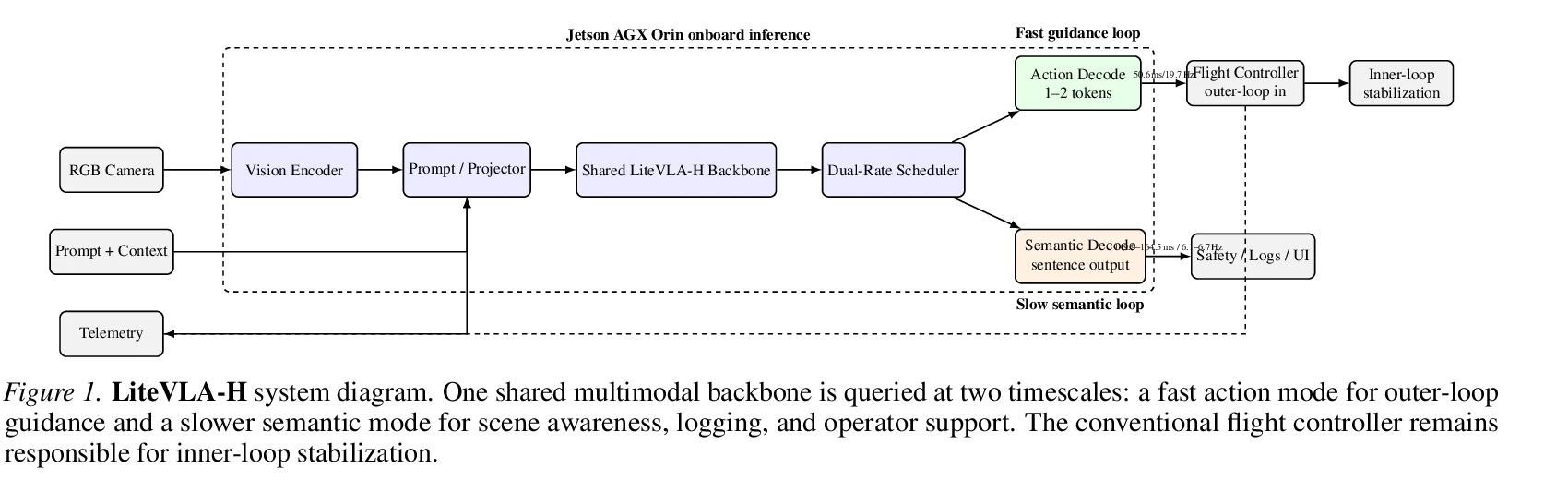
무엇을 해결하려는가
기존 VLA 연구는 manipulation, mobile navigation, semantic grounding에서 강한 성과를 보여 왔지만, 항공 로봇의 요구사항은 더 날카롭다.
드론은 시각 변화가 빠르고, 바람·고도·motion blur·payload 같은 조건 변화가 바로 안전 문제로 연결된다.
따라서 VLA가 모든 것을 한 번에 처리하는 “느린 범용 추론기”가 되면 실제 guidance 루프와 맞지 않는다.
LiteVLA-H가 푸는 문제는 바로 이 속도 불일치다.
액션은 자주 업데이트되어야 하지만, semantic caption이나 hazard narration은 매 프레임 필요하지 않다.
오히려 semantic branch를 매번 강제로 실행하면 전체 시스템이 6Hz대의 느린 의미 출력 속도에 묶인다.
논문은 이 둘을 같은 요청 큐에 넣지 말고, deadline-critical action과 opportunistic semantic service로 나눠야 한다고 주장한다.
여기서 중요한 점은 VLA가 low-level stabilizer를 대체하지 않는다는 것이다.
LiteVLA-H의 action token은 모터 명령이 아니라 velocity, heading, waypoint, mode 수준의 outer-loop guidance로 해석된다.
실제 attitude stabilization, command validation, emergency stop, fallback hover/return-to-home은 기존 flight controller와 안전 계층이 담당해야 한다.
이 분리는 실무적으로 매우 중요하다.
VLA가 불확실하거나 한 박자 늦어도 downstream controller가 위험을 흡수할 여지를 남기기 때문이다.
핵심 아이디어 / 구조 / 동작 방식
구조는 단순하지만 메시지는 분명하다.
RGB camera, prompt/context, telemetry가 prompt/projector를 거쳐 shared LiteVLA-H backbone으로 들어가고, 그 뒤 dual-rate scheduler가 두 종류의 디코딩을 분리한다.
- Fast action mode: 1~2개 action token을 생성해 outer-loop controller로 보낸다.
- Slow semantic mode: sentence-level 설명, log, UI, safety narration을 만든다.
- Conventional flight controller: inner-loop stabilization을 계속 맡는다.
- Deadline-first scheduling: action deadline이 걸려 있으면 semantic job은 skip 또는 delay될 수 있다.
훈련 레시피도 이 설계와 맞춰져 있다.
논문은 reactive action samples 120,000개, aerial semantic samples 45,000개, generic caption/VQA samples 85,000개를 섞고, knowledge-preserving regularizer를 추가한다.
목적은 action classifier로 좁아지지 않으면서도 항공 도메인 guidance를 학습하는 것이다.
손실은 action loss, aerial semantic loss, generic caption/VQA loss, pre-specialized backbone에 대한 KL 기반 knowledge-preserving loss를 합친 형태로 제시된다.

핵심 latency 표를 글로 다시 정리하면 다음과 같다.
| 모드 | 출력 복잡도 | 지연 | 속도 |
|---|---|---|---|
| Reactive guidance | 단일 action token | 50.65ms | 19.74Hz |
| Scene caption | 단일 문장 | 149.90ms | 6.67Hz |
| Guided semantic | 2문장 + action cue | 153.53ms | 6.51Hz |
| Contextual awareness | 3문장 + action cue | 164.57ms | 6.08Hz |
여기서 흥미로운 부분은 긴 semantic 출력이 action보다 느리다는 사실 자체가 아니라, semantic 출력끼리의 차이가 생각보다 작다는 점이다. single sentence가 149.90ms인데 3 sentences + action cue가 164.57ms다.
가장 긴 contextual-awareness 모드가 single caption보다 14.67ms, 약 9.8%만 더 느리다.
이는 추가 토큰의 marginal decode cost보다 fixed image-language fusion cost가 지배적이라는 논문 주장을 뒷받침한다.
논문은 이를 pre-fill fraction으로도 표현한다. pre-fill latency가 47.8ms이고 action latency가 50.65ms이므로, ρ = 47.8 / 50.65 ≈ 0.944다.
즉 첫 액션 지연의 약 94.4%가 유용한 출력 토큰을 만들기 전에 이미 소비된다.
이 수치가 LiteVLA-H의 설계 철학을 거의 설명한다.
“응답을 더 짧게 만들자”보다 “첫 액션 deadline을 보호하는 scheduler와 pre-fill 경로 최적화를 만들자”가 더 중요하다는 것이다.
공개된 근거에서 확인되는 점
실험은 Jetson AGX Orin에서 같은 256M backbone, FP16 execution, context window 2048을 기준으로 진행된다.
논문은 full vehicle reaction time 전체가 아니라, prepared image-prompt input에서 token emission까지의 inference path를 측정한다. camera exposure, sensor transport, actuator dynamics, airframe response 등은 별도 flight-safety case에서 측정되어야 한다고 명시한다.
Ablation에서 가장 눈에 띄는 부분은 data mixture다. action-only fine-tuning은 action success 84.2%로 가장 높지만 retained caption CIDEr가 0.31, aerial semantic F1이 0.42까지 낮아진다.
반대로 full method는 action success 83.1%로 1.1%p 정도만 낮추면서 retained caption CIDEr 0.82, aerial semantic F1 0.80을 유지한다.
즉 “잘 움직이지만 설명 능력이 무너진 모델”이 아니라, action과 semantic awareness를 동시에 유지하는 쪽으로 operating point를 잡는다.
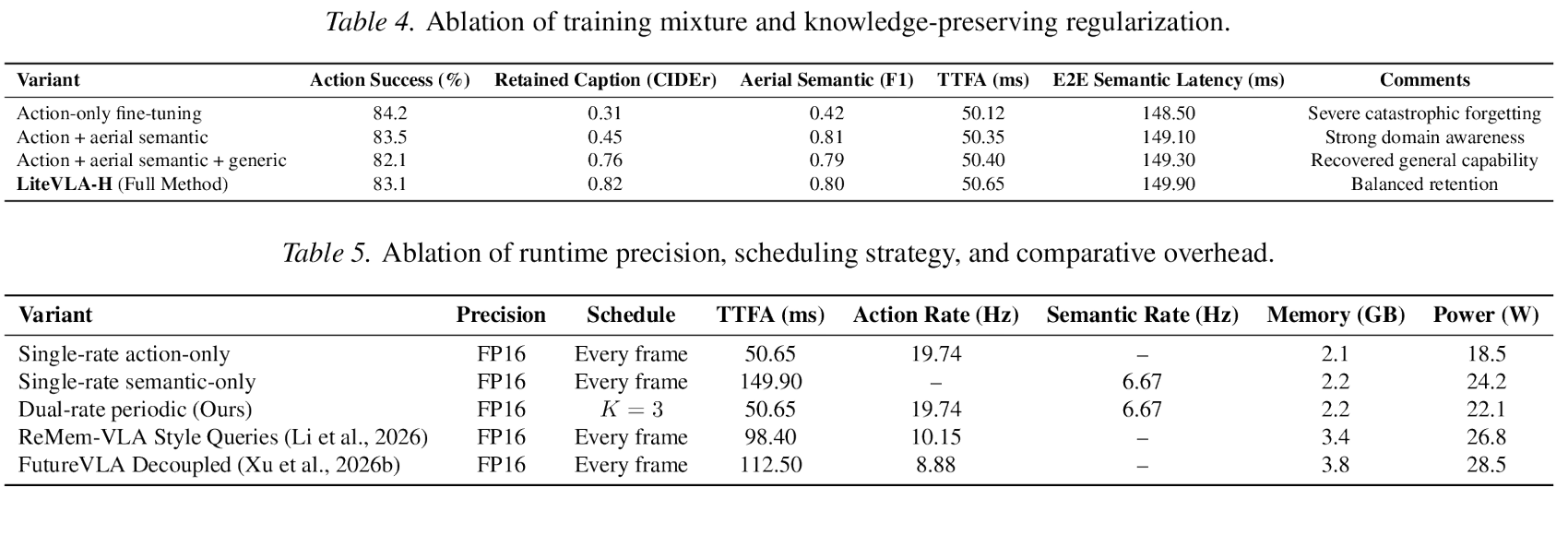
런타임 ablation도 설계 의도를 잘 보여준다.
| 구성 | TTFA | Action rate | Semantic rate | Memory | Power |
|---|---|---|---|---|---|
| Single-rate action-only | 50.65ms | 19.74Hz | - | 2.1GB | 18.5W |
| Single-rate semantic-only | 149.90ms | - | 6.67Hz | 2.2GB | 24.2W |
| Dual-rate periodic, K=3 | 50.65ms | 19.74Hz | 6.67Hz | 2.2GB | 22.1W |
| ReMem-VLA-style queries | 98.40ms | 10.15Hz | - | 3.4GB | 26.8W |
| FutureVLA decoupled | 112.50ms | 8.88Hz | - | 3.8GB | 28.5W |
이 표에서 LiteVLA-H의 주장은 “모든 VLA보다 보편적으로 낫다”가 아니다.
비교 대상마다 hardware, benchmark, embodiment, action representation이 다르기 때문이다.
더 정확한 해석은, 이 논문이 설정한 Jetson AGX Orin 배포 조건에서는 dual-rate scheduler가 action path의 19.74Hz를 보존하면서 semantic path를 6.67Hz로 붙일 수 있다는 것이다.
그리고 이때 추가 memory는 action-only 대비 0.1GB 수준, power 증가는 3.6W로 보고된다.
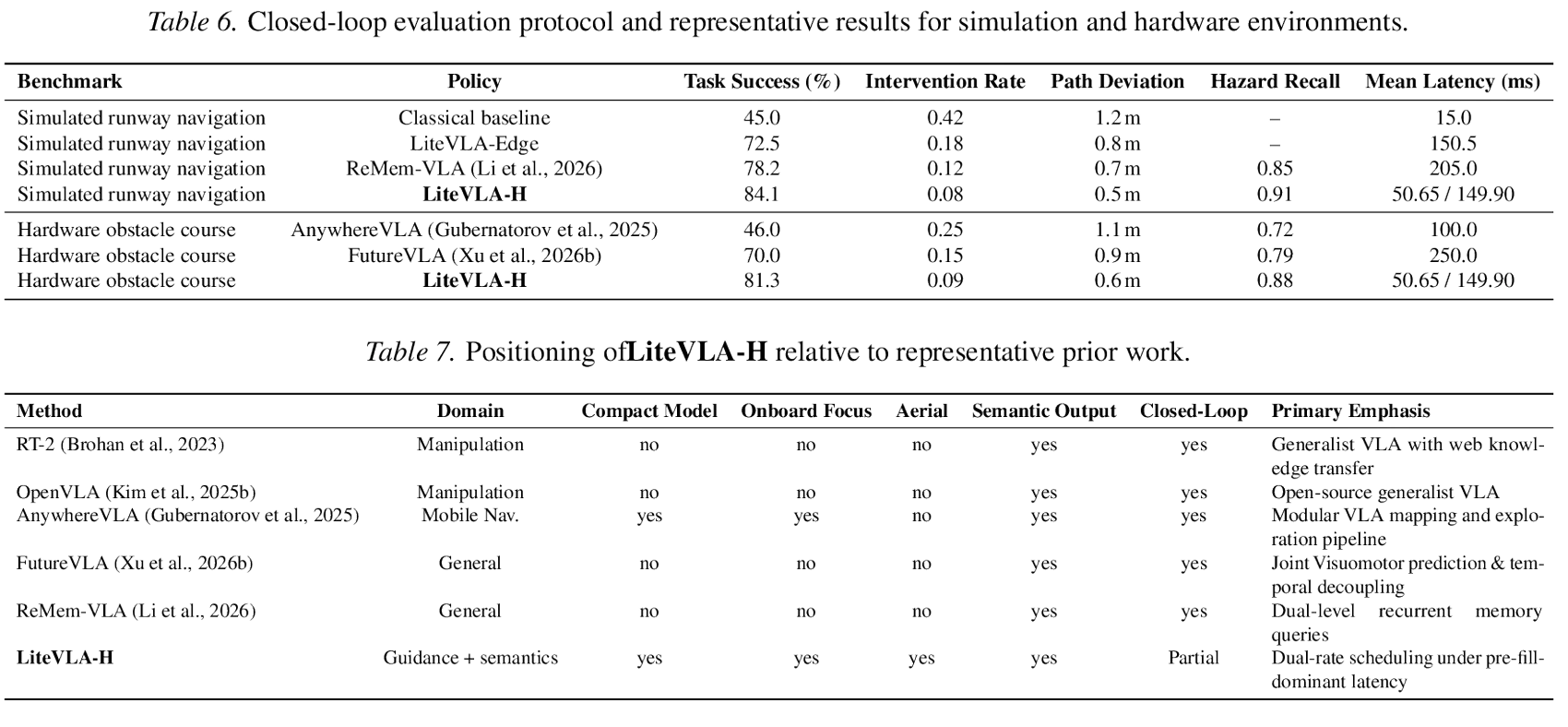
Closed-loop 결과도 같은 방식으로 읽어야 한다.
논문은 simulated runway navigation에서 LiteVLA-H가 task success 84.1%, intervention rate 0.08, path deviation 0.5m, hazard recall 0.91을 기록한다고 제시한다. hardware obstacle course에서는 task success 81.3%, intervention rate 0.09, path deviation 0.6m, hazard recall 0.88이 보고된다.
다만 저자들도 hardware row는 동일 airframe, payload, controller gain, lighting, obstacle layout, battery state가 맞춰지지 않으면 조심해서 해석해야 한다고 적는다.
공개 범위 관점에서는 아직 논문 중심의 artifact에 가깝다. arXiv abstract, PDF, HTML, TeX source는 확인되지만, arXiv HTML의 companion code link, GitHub repository search, Hugging Face model/dataset search에서 공식 code/model release는 확인되지 않았다.
따라서 이 글은 구현체 리뷰라기보다, 논문이 제시한 onboard VLA inference design과 latency evidence를 읽는 쪽에 가깝다.
실무 관점에서의 해석
내가 보기엔 LiteVLA-H의 가장 중요한 포인트는 “작은 VLA를 Jetson에 올렸다”보다, VLA 추론을 control-critical path와 semantic service path로 분리했다는 데 있다.
로봇 시스템에서 모든 추론 결과가 같은 deadline을 갖지는 않는다.
어떤 출력은 지금 당장 필요하고, 어떤 출력은 로그·설명·상태 요약으로 몇 프레임 늦어도 된다.
LiteVLA-H는 이 차이를 모델 구조와 runtime scheduler에 반영한다.
이 관점은 edge multimodal inference 전반에도 꽤 유용하다.
VLM/VLA 최적화는 종종 quantization, pruning, speculative decoding, token compression 같은 모델 중심 기법으로만 논의된다.
하지만 이 논문이 보여주는 병목은 조금 다르다. action latency의 대부분이 pre-fill이라면, 실제 이득은 visual token 수를 줄이거나, prompt 구조를 캐시하거나, projector computation을 단순화하거나, image preprocessing을 이전 control execution과 overlap하는 쪽에서 나올 가능성이 크다.
또 하나의 시사점은 semantic output의 역할을 낮춰 보지 않는다는 점이다.
드론은 semantic caption이 매 50ms마다 필요하지 않을 뿐, obstacle description, runway cue, mission-state summary, human operator용 narration은 여전히 중요하다.
즉 semantic branch는 hard real-time control signal이 아니라 low-rate supervisory signal로 다뤄야 한다.
이 구분이 있으면 VLA의 언어 능력을 버리지 않으면서도 제어 반응성을 유지할 수 있다.
한계도 분명하다.
첫째, 가장 강한 근거는 onboard inference timing이고, 더 넓은 closed-loop flight robustness는 아직 풍부하게 검증됐다고 보기 어렵다.
둘째, 비교 표는 systems-level positioning에 가깝고 완전 통제된 leaderboard가 아니다.
셋째, public implementation이나 checkpoint가 확인되지 않아 재현성과 실전 적용성은 아직 논문 주장에 의존한다.
넷째, action token interface는 outer-loop guidance에 적합한 설계이지 classical stabilization과 safety monitor를 대체하지 않는다.
그럼에도 LiteVLA-H는 실시간 embodied AI에서 꽤 중요한 질문을 던진다.
“모델을 얼마나 빠르게 만들 것인가”가 아니라, “어떤 출력을 어떤 시간축에 올릴 것인가”라는 질문이다.
앞으로의 aerial VLA나 mobile robot VLA는 하나의 거대한 semantic loop로 움직이기보다, 빠른 action path, 느린 semantic path, 상황에 따라 켜지는 memory/prediction module을 조합하는 runtime policy 경쟁으로 갈 가능성이 높다.
LiteVLA-H는 그 방향을 작지만 구체적인 edge deployment 숫자로 보여주는 사례다.