멀티모달 모델 경쟁은 한동안 “더 큰 VLM이 더 많은 벤치마크를 이긴다”는 방향으로 흘렀다.
하지만 실제 제품 배포 단계로 내려오면 질문이 조금 달라진다.
이미지와 비디오를 이해하는 모델을 서버 GPU가 아니라 휴대폰, 로컬 앱, 경량 엣지 환경에서 돌릴 수 있는가.
고해상도 이미지와 긴 비디오를 다룰 때 prefill 비용과 시각 토큰 수를 어디까지 줄일 수 있는가.
그리고 그 효율화가 단순 데모가 아니라 iOS, Android, HarmonyOS 같은 실제 플랫폼 surface까지 연결되는가.
OpenBMB의 MiniCPM-V 4.6은 이 문제를 정면으로 겨냥한 릴리스다.
Hugging Face 모델 카드 기준 이 모델은 SigLIP2-400M 비전 백본과 Qwen3.5-0.8B LLM을 바탕으로 만든 1.3B급 이미지·비디오 이해 모델이며, MiniCPM-V 계열의 단일 이미지, 멀티 이미지, 비디오 이해 능력을 유지하면서 시각 인코딩 비용을 크게 줄이는 데 초점을 둔다.
모델 카드가 반복해서 강조하는 표현도 “가장 edge-deployment-friendly한 MiniCPM-V”다.
흥미로운 점은 MiniCPM-V 4.6이 단순히 작은 모델 가중치만 공개한 것이 아니라는 점이다.
메인 BF16 모델, Thinking 변형, GGUF·BNB·AWQ·GPTQ 양자화 변형, Transformers/vLLM/SGLang/llama.cpp/Ollama 배포 레시피, 그리고 iOS·Android·HarmonyOS 온디바이스 앱까지 거의 동시에 묶여 있다.
이 글은 MiniCPM-V 4.6이 실제로 무엇을 공개했고, 어떤 효율화 아이디어를 썼으며, 실무적으로 어떤 의미와 한계를 갖는지 정리한다.
무엇을 해결하려는가
MiniCPM-V 4.6이 풀려는 핵심 문제는 “작은 VLM을 하나 더 만든다”가 아니다.
더 정확히는, 이미지·비디오 이해 모델을 실제 엣지 배포 가능한 비용 구조로 끌어내리는 문제다.
VLM은 텍스트 LLM보다 입력 비용이 훨씬 빠르게 불어난다.
고해상도 이미지 하나만 넣어도 시각 토큰 수가 커지고, 멀티 이미지나 비디오로 넘어가면 prefill 지연, KV cache, 디코딩 처리량이 바로 병목이 된다.
이 병목은 특히 모바일에서 더 날카롭게 드러난다.
서버에서는 GPU 메모리와 배치 처리를 통해 어느 정도 감당할 수 있지만, 휴대폰에서는 모델 파일 크기, 메모리 여유, 발열, 앱 패키징, 플랫폼별 네이티브 빌드까지 모두 제약이 된다.
“모델이 작다”는 주장만으로는 부족하고, 실제로 어떤 양자화 파일이 있고, 앱이 어느 플랫폼에서 돌아가며, 얼마만큼의 RAM이 필요한지까지 확인되어야 한다.
MiniCPM-V 4.6은 이 지점을 모델 설계와 릴리스 패키징 양쪽에서 동시에 건드린다.
모델 카드와 공식 GitHub README는 LLaVA-UHD v4의 최신 기법을 바탕으로 시각 인코딩 FLOPs를 50% 이상 줄였고, 4x/16x 혼합 시각 토큰 압축률을 지원한다고 설명한다.
즉 목표는 벤치마크 점수 하나를 키우는 것이 아니라, 정확도와 속도를 전환할 수 있는 멀티모달 입력 경로를 만들고, 이를 실제 모바일 앱과 배포 프레임워크까지 연결하는 것이다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 MiniCPM-V 4.6은 매우 공격적으로 작게 설계된 VLM이다.
Hugging Face 모델 카드와 config를 함께 보면, 전체 safetensors 파라미터는 1,300,428,016개로 표시된다.
비전 쪽은 SigLIP2-400M 계열로 설명되며, 공개 config의 vision_config는 hidden size 1152, 27 layers, patch size 14를 가진 비전 인코더를 노출한다.
텍스트 쪽은 Qwen3.5-0.8B LLM 기반이며, config에는 qwen3_5_text 타입, 24 layers, hidden size 1024, max position embeddings 262,144, 그리고 이미지·비디오 전용 토큰 ID가 포함되어 있다.
핵심 차별점은 시각 토큰 압축이다.
MiniCPM-V 4.6은 4x와 16x compression mode를 모두 지원한다.
기본값인 16x는 속도와 처리량을 우선할 때 유리하고, 4x는 더 많은 시각 토큰을 유지해 세밀한 이미지·문서 이해에 유리하다.
공식 사용 예제에서도 downsample_mode를 apply_chat_template와 generate() 양쪽에 함께 넘기라고 강조한다. placeholder 개수와 실제 비전 인코더 동작이 맞아야 하기 때문이다.
비디오 처리도 같은 철학 위에 있다.
모델 카드는 max_num_frames, stack_frames, use_image_id, max_slice_nums 같은 파라미터를 통해 이미지와 비디오 입력을 세밀하게 조절할 수 있게 한다.
예를 들어 고해상도 이미지는 slice 수를 늘려 디테일을 살리고, 비디오는 프레임 수와 frame stacking을 조절해 시간축 정보를 더 많이 넣을 수 있다.
작은 모델이라고 해서 단일 이미지 QA에만 묶인 것이 아니라, 멀티 이미지·비디오·문서 OCR까지 하나의 입력 포맷으로 다루려는 설계다.
| 구성 축 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| 모델 규모 | HF API 기준 BF16 1.300B parameters | 휴대폰·로컬 배포를 염두에 둔 매우 작은 VLM 체급 |
| 비전 백본 | SigLIP2-400M 기반, config상 27-layer vision encoder | 이미지·문서·비디오 프레임 이해를 담당하는 시각 경로 |
| 텍스트 백본 | Qwen3.5-0.8B 기반, 262K max position embeddings | 작은 LLM 위에 멀티모달 입력을 결합 |
| 시각 압축 | 4x/16x 혼합 visual token compression | 정확도와 속도 사이를 입력별로 조절 가능 |
| 입력 범위 | image, multi-image, video, text | 단순 이미지 캡션보다 넓은 VLM 사용 범위 |
| 배포 표면 | Transformers, vLLM, SGLang, llama.cpp, Ollama, SWIFT, LLaMA-Factory | 연구용 모델 카드가 아니라 실제 배포·튜닝 생태계를 의식한 릴리스 |
공개된 근거에서 확인되는 점
먼저 Hugging Face 배포 상태를 보면, MiniCPM-V 4.6은 단일 모델 카드 이상의 패키지로 공개되어 있다.
메인 모델 repo는 image-text-to-text pipeline과 Apache-2.0 라이선스를 갖고 있으며, model.safetensors, config.json, tokenizer.json, preprocessor_config.json, chat_template.jinja를 포함한다.
API 기준 생성일은 2026-04-13, 마지막 수정은 2026-05-19T14:01:40Z로 표시된다.
현재 Hub API 카운터는 downloads 144,826, likes 809이며, gated 모델이 아니고 config와 chat template도 함께 공개되어 있어 표준 Transformers 경로에서 바로 불러오는 형태를 목표로 한다.
동시에 OpenBMB는 MiniCPM-V 4.6-Thinking, MiniCPM-V 4.6-gguf, MiniCPM-V 4.6-BNB, MiniCPM-V 4.6-AWQ, MiniCPM-V 4.6-GPTQ 및 Thinking 버전의 대응 양자화 repo를 함께 제공한다.
GGUF repo에는 F16, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 같은 파일과 mmproj-model-f16.gguf가 포함된다.
즉 “가중치가 있다”에서 끝나는 릴리스가 아니라, 로컬 추론과 모바일 앱에 필요한 포맷까지 분리해 둔 구조다.
또 하나 달라진 점은 hosted trial surface다.
2026-05-17 공지된 공식 API 문서는 https://api.modelbest.cn/v1 기반 Chat Completions 인터페이스를 공개하고, MiniCPM-V-4.6-Instruct와 MiniCPM-V-4.6-Thinking 모델 ID를 텍스트 및 vision-language 요청에 쓸 수 있다고 설명한다.
공개 문서에는 테스트용 public key가 언급되지만, 운영 관점에서는 키 문자열 자체보다 “온디바이스·로컬 추론에 더해 호스티드 API 경로도 생겼다”는 배포 표면 확장이 더 중요하다.
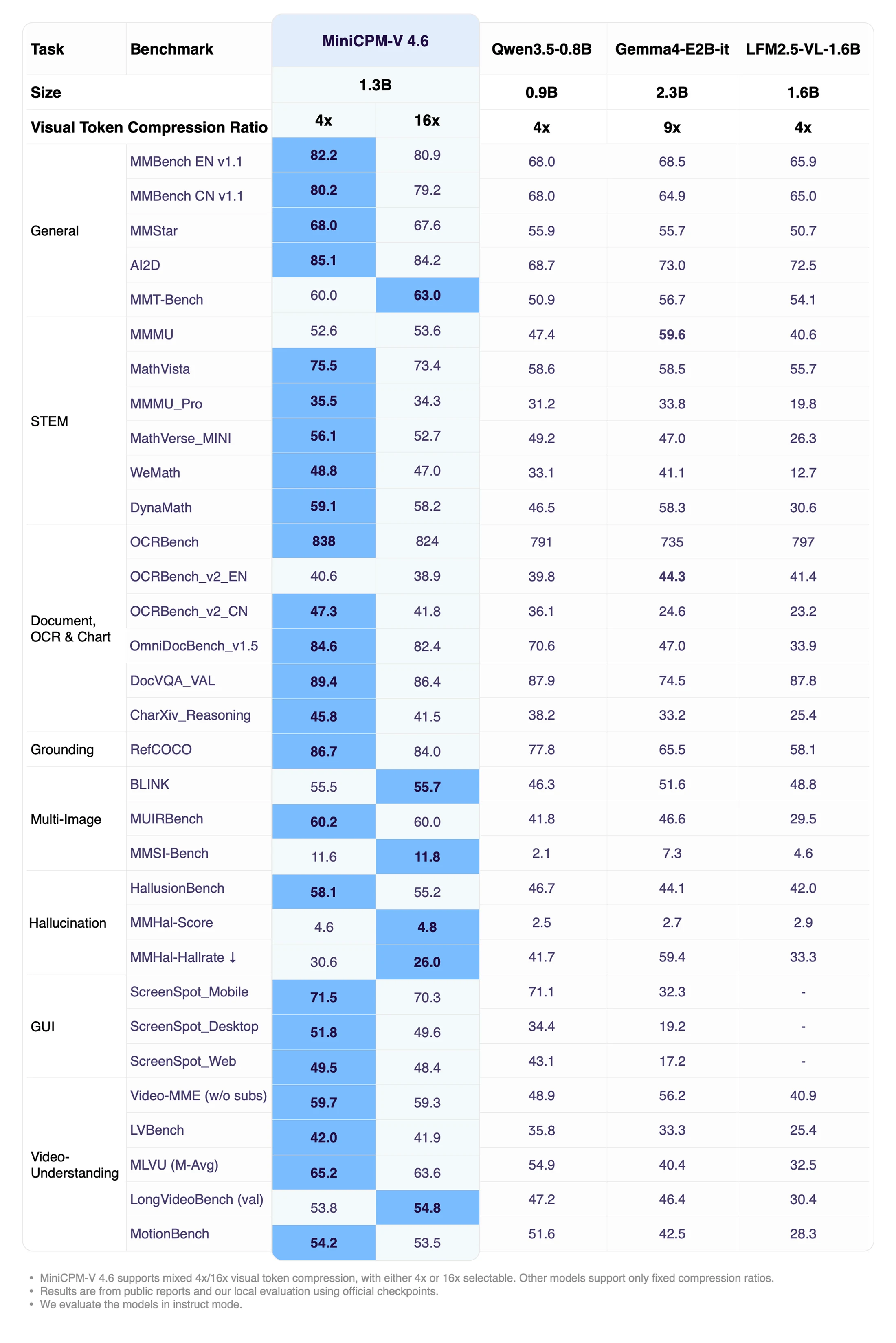
성능표에서 MiniCPM-V 4.6의 가장 강한 메시지는 작은 체급 대비 폭넓은 멀티모달 성능이다.
공식 Instruct 표는 MiniCPM-V 4.6을 Qwen3.5-0.8B, Gemma4-E2B-it, LFM2.5-VL-1.6B와 비교한다.
예를 들어 4x mode 기준 MMBench EN v1.1은 82.2, MMBench CN v1.1은 80.2, AI2D는 85.1, MathVista는 75.5, OCRBench는 838, OmniDocBench_v1.5는 84.6, RefCOCO는 86.7, Video-MME는 59.7로 제시된다.
같은 표에서 Qwen3.5-0.8B는 MMBench EN 68.0, AI2D 68.7, OCRBench 791, OmniDocBench 70.6, Video-MME 48.9로 표시된다.
이 비교만 보면 MiniCPM-V 4.6은 단순히 “0.8B LLM에 비전을 붙인 모델”보다 훨씬 강한 시각 이해 경로를 갖도록 조정된 모델로 읽힌다.
다만 모든 항목에서 절대 우위인 것은 아니다.
같은 Instruct 표에서 MMMU는 Gemma4-E2B-it 59.6이 MiniCPM-V 4.6의 52.6/53.6보다 높고, OCRBench_v2_EN도 Gemma4-E2B-it 44.3이 MiniCPM-V 4.6의 40.6/38.9보다 높다.
LongVideoBench 역시 16x mode의 MiniCPM-V 4.6이 54.8로 강하지만, 이런 세부 항목의 우열은 작업별로 갈린다.
따라서 이 릴리스의 핵심은 “작은 모델이 모든 대형 VLM을 이겼다”가 아니라, 1.3B와 4x/16x 압축이라는 제약 속에서 문서·OCR·grounding·비디오까지 넓게 커버한다는 쪽에 가깝다.
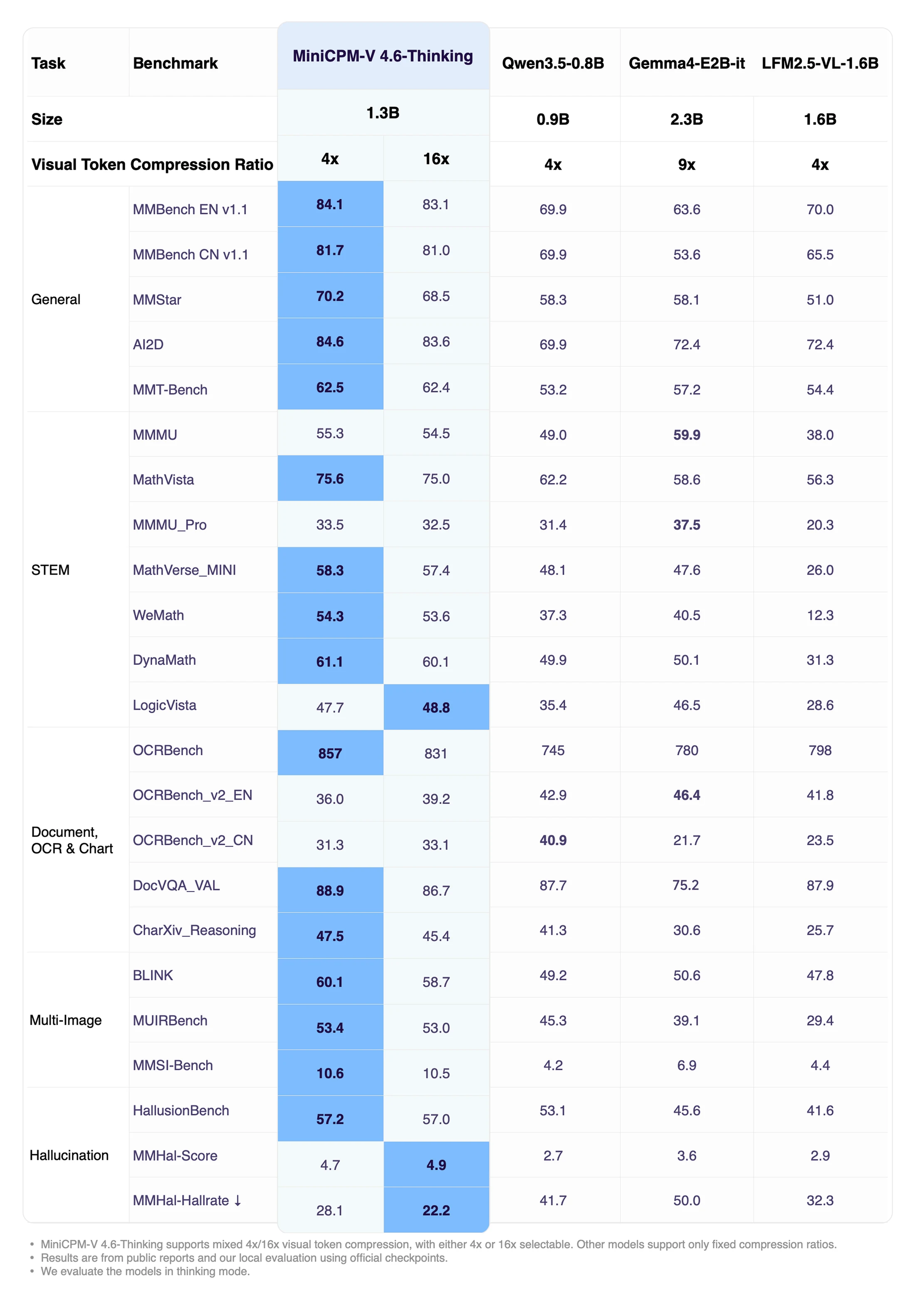
Thinking 버전은 reasoning 성향의 후처리 변형으로 보인다.
공식 Thinking 표에서는 MMBench EN 84.1, MMBench CN 81.7, MMStar 70.2, OCRBench 857, BLINK 60.1, HallusionBench 57.2 같은 수치가 제시되어 Instruct 대비 일부 지표가 올라간다.
하지만 여기서도 MMMU_Pro는 Gemma4-E2B-it 37.5가 MiniCPM-V 4.6-Thinking의 33.5/32.5보다 높고, OCRBench_v2_EN도 Gemma 쪽이 더 높은 편이다.
Thinking 변형은 전반적 reasoning과 OCR 계열 일부를 보강하지만, 모든 벤치마크를 균일하게 끌어올리는 만능 모드로 읽으면 과장이다.
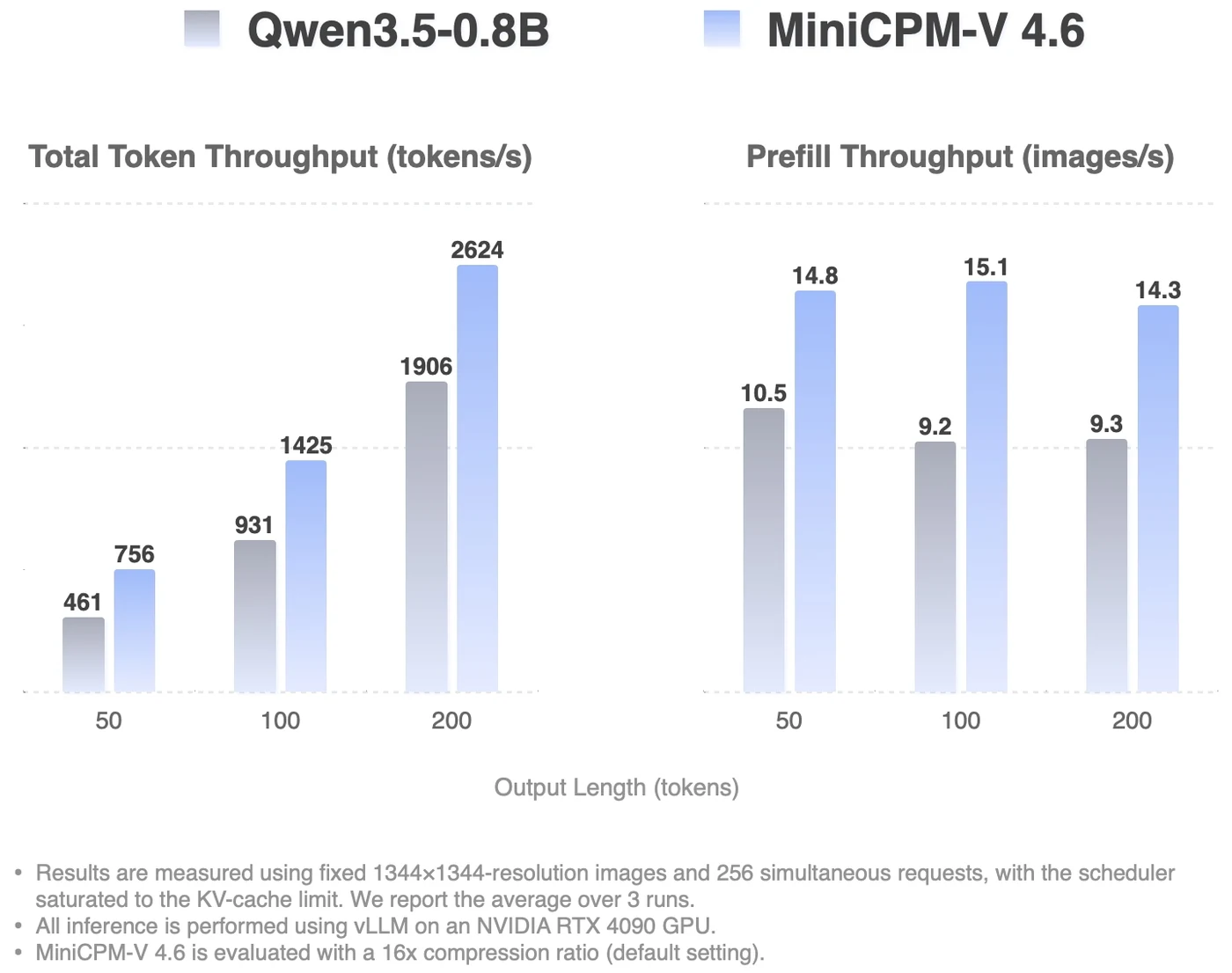
효율성 근거도 흥미롭다.
공식 throughput 그래프는 vLLM, NVIDIA RTX 4090, 1344×1344 해상도 이미지, 256개 동시 요청, KV-cache limit까지 scheduler를 포화시킨 조건에서 측정했다고 적는다.
이 조건에서 총 토큰 처리량은 output length 50/100/200 기준 MiniCPM-V 4.6이 각각 756/1425/2624 tokens/s, Qwen3.5-0.8B가 461/931/1906 tokens/s로 표시된다. prefill throughput도 같은 세 지점에서 MiniCPM-V 4.6이 14.8/15.1/14.3 images/s, Qwen3.5-0.8B가 10.5/9.2/9.3 images/s다.
README의 “약 1.5x token throughput”이라는 표현은 이 그래프의 패턴과 잘 맞는다.
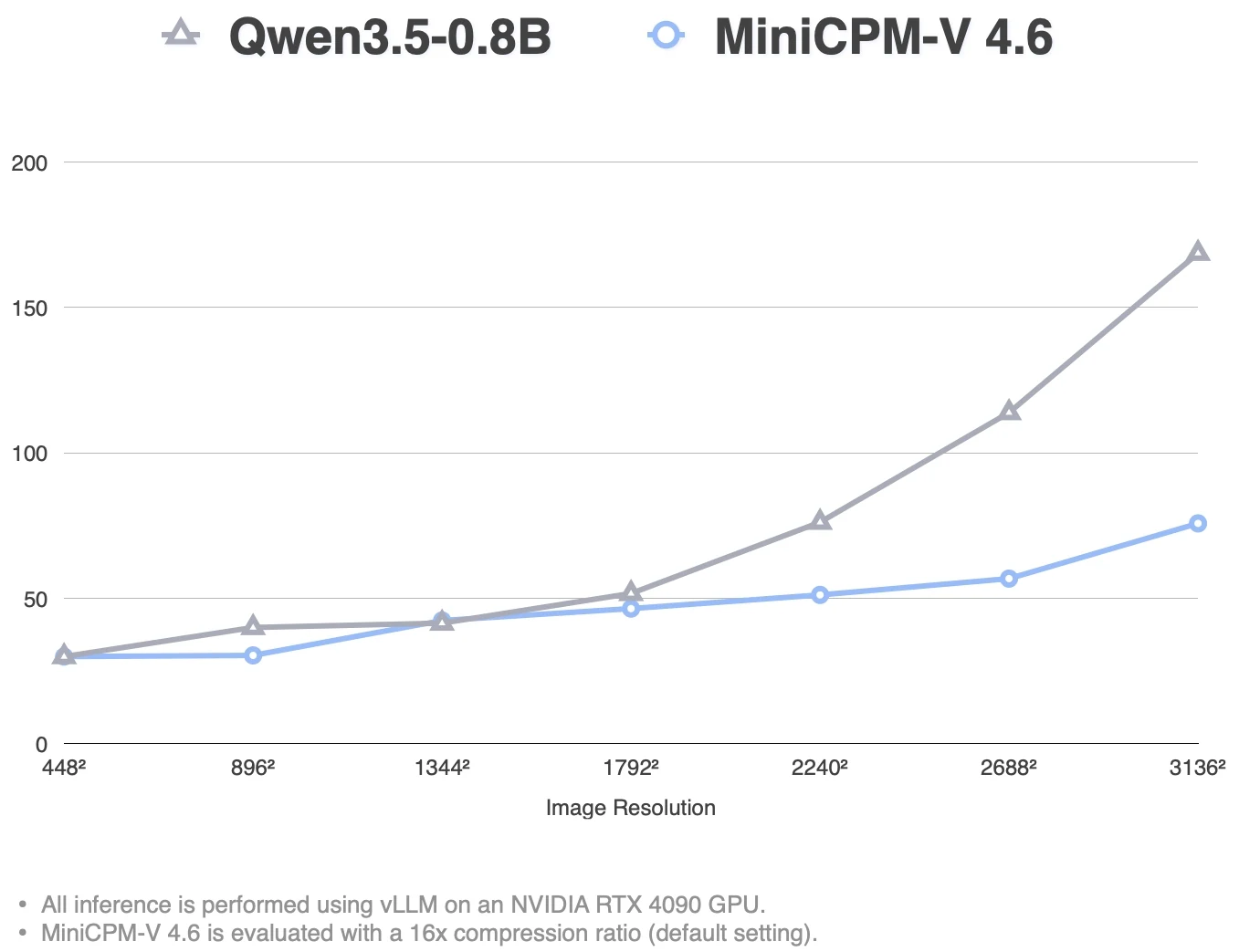
TTFT 그래프는 고해상도로 갈수록 차이가 더 선명해진다.
Qwen3.5-0.8B는 1792² 이후 Time To First Token이 빠르게 증가하는 반면, MiniCPM-V 4.6은 16x compression 기본 설정에서 더 완만하게 증가한다.
그래프상 3136² 지점에서도 MiniCPM-V 4.6의 TTFT는 Qwen3.5-0.8B보다 훨씬 낮게 유지된다.
이 수치는 MiniCPM-V 4.6의 효율화가 디코딩 속도만이 아니라 이미지 prefill과 고해상도 입력에도 걸쳐 있다는 점을 보여준다.
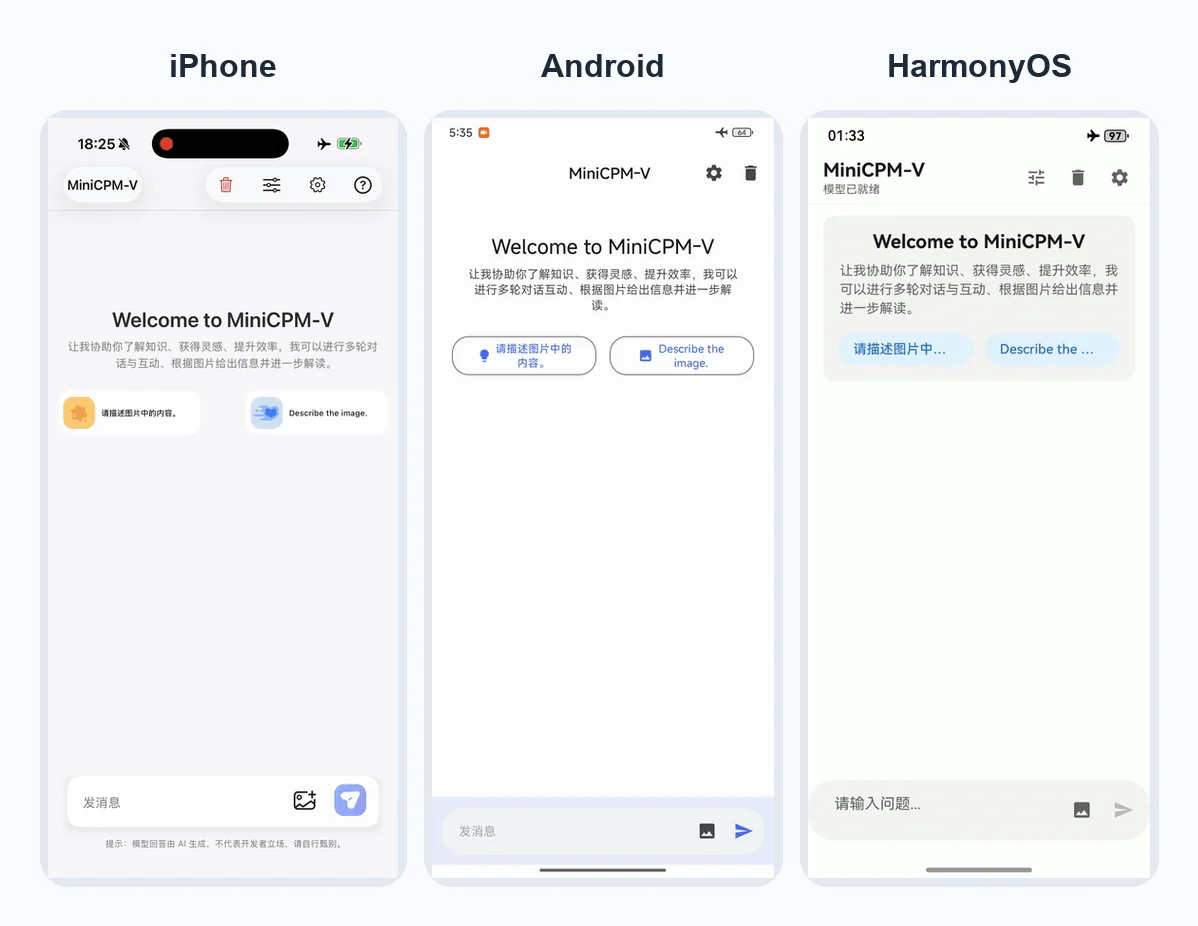
모바일 배포 자료도 별도로 확인된다.
OpenBMB의 MiniCPM-V 앱 repo는 iOS, Android, HarmonyOS NEXT 데모를 모두 llama.cpp 기반 온디바이스 추론으로 제공한다고 설명한다.
다운로드 안내에는 iOS TestFlight, Android v2.0 APK, HarmonyOS v2.0 HAP가 정리되어 있고, 세 플랫폼 모두 64-bit ARM과 권장 RAM 6GB 이상을 전제로 한다.
특히 V 4.6 GGUF 기준 권장 구성은 Q4_K_M LLM 파일 약 0.5GB, f16 mmproj 약 1.1GB, 총 다운로드 약 1.6GB다.
이것은 8B급 VLM이 아니라 실제 휴대폰 앱에 들어갈 수 있는 체급을 목표로 했다는 강한 신호다.
실무 관점에서의 해석
내가 보기에 MiniCPM-V 4.6의 가치는 “작은 VLM이 나왔다”보다 “VLM 릴리스를 배포 가능한 형태까지 같이 깎았다”는 데 있다.
모델 카드, 양자화 repo, Cookbook, 모바일 앱 repo가 맞물려 있기 때문에, 독자는 단순히 성능표를 보는 데서 멈추지 않고 Transformers 서버, vLLM/SGLang 서빙, llama.cpp/GGUF 로컬 추론, iOS·Android·HarmonyOS 앱까지 이어지는 배포 경로를 바로 확인할 수 있다.
작은 모델에서 이 정도로 배포 surface를 넓게 열어 둔 것은 실무적으로 꽤 중요하다.
특히 개인정보나 오프라인성이 중요한 작업에서는 이 방향이 설득력 있다.
영수증·문서 OCR, 화면 이해, 모바일 UI grounding, 현장 사진 질의응답, 짧은 비디오 요약 같은 작업은 굳이 모든 입력을 서버로 보내고 싶지 않은 경우가 많다.
MiniCPM-V 4.6은 이런 작업을 frontier급 폐쇄 모델과 같은 품질로 대체한다기보다, “충분히 작은 모델로 어디까지 로컬 멀티모달 경험을 만들 수 있는가”의 기준선을 올린다.
물론 한계도 분명하다.
공식 표는 OpenBMB의 공개 report와 local evaluation을 섞은 결과이며, 독립 재현이 더 쌓여야 한다.
일부 벤치마크에서는 Gemma4-E2B-it이나 다른 비교 모델이 앞서는 영역도 있고, 복잡한 과학 추론이나 고난도 문서 reasoning에서는 더 큰 VLM이 여전히 유리할 가능성이 높다.
또한 Transformers 사용 경로는 transformers[torch]>=5.7.0과 torchcodec을 요구하며, CUDA 버전 이슈가 있을 때는 PyAV로 바꾸거나 PyTorch CUDA wheel을 맞춰야 한다는 주의사항도 모델 카드에 적혀 있다. hosted API는 빠른 시험에는 편하지만 운영 SLA나 장기 무료 제공 조건을 모델 카드만으로 판단하기 어렵고, 모바일 앱 역시 첫 실행 시 수 GB급 모델 파일 다운로드와 6GB 이상 RAM 전제가 있다.
그럼에도 MiniCPM-V 4.6은 오픈 VLM의 방향성을 잘 보여준다.
오픈 모델 경쟁은 더 이상 대형 GPU 서버에서 점수표를 찍는 것만으로 끝나지 않는다.
앞으로 중요한 축 중 하나는 “시각 토큰을 얼마나 효율적으로 줄이고, 그 결과를 실제 앱과 로컬 런타임에 얼마나 빨리 연결하는가”가 될 것이다.
그런 관점에서 MiniCPM-V 4.6은 모델 크기보다 배포 가능성을 먼저 읽어야 하는 릴리스다.
1.3B라는 숫자는 작지만, 이 모델이 던지는 질문은 꽤 크다.
멀티모달 AI를 서버 API가 아니라 사용자의 손 안에서 얼마나 자연스럽게 돌릴 수 있을 것인가.