표형 데이터는 AI에서 가장 오래되고 가장 실용적인 데이터 형태 중 하나다.
병원 위험 예측, 신약 후보 스크리닝, 소재 물성 예측, 금융 리스크, 기후 관측, 실험실 스프레드시트까지 거의 모든 조직은 결국 행과 열로 된 데이터를 다룬다.
그런데 이미지와 텍스트에서는 foundation model이 기본 인프라가 된 반면, tabular ML에서는 여전히 XGBoost, LightGBM, CatBoost, random forest, AutoML 튜닝이 강한 기본값으로 남아 있다.
Nature에 실린 “Accurate predictions on small data with a tabular foundation model”은 이 균형을 바꾸려는 시도를 정면으로 보여 준다.
논문의 핵심 모델인 Tabular Prior-data Fitted Network, 즉 TabPFN은 개별 데이터셋마다 가중치를 새로 학습하는 대신, 수천만~1억 개 규모의 synthetic tabular task로 transformer를 사전학습해 “학습 알고리즘 자체”를 모델 안에 압축한다.
새 데이터셋이 오면 훈련 샘플과 테스트 샘플을 문맥으로 넣고, 한 번의 forward pass로 예측한다.
내가 보기엔 TabPFN의 의미는 “딥러닝이 드디어 tabular benchmark에서 boosting을 이겼다” 정도가 아니다.
더 흥미로운 지점은 알고리즘 개발 방식의 변화다.
사람이 결측치 처리, 범주형 인코딩, 이상치 대응, 하이퍼파라미터 탐색을 일일이 설계하던 일을, synthetic dataset prior와 in-context learning으로 한 번 크게 학습해 두는 방식으로 바꾸려 한다.
즉 TabPFN은 tabular ML을 모델 선택 문제가 아니라, 사전학습된 prediction runtime을 어떻게 호출하고 운영할 것인가의 문제로 재구성한다.
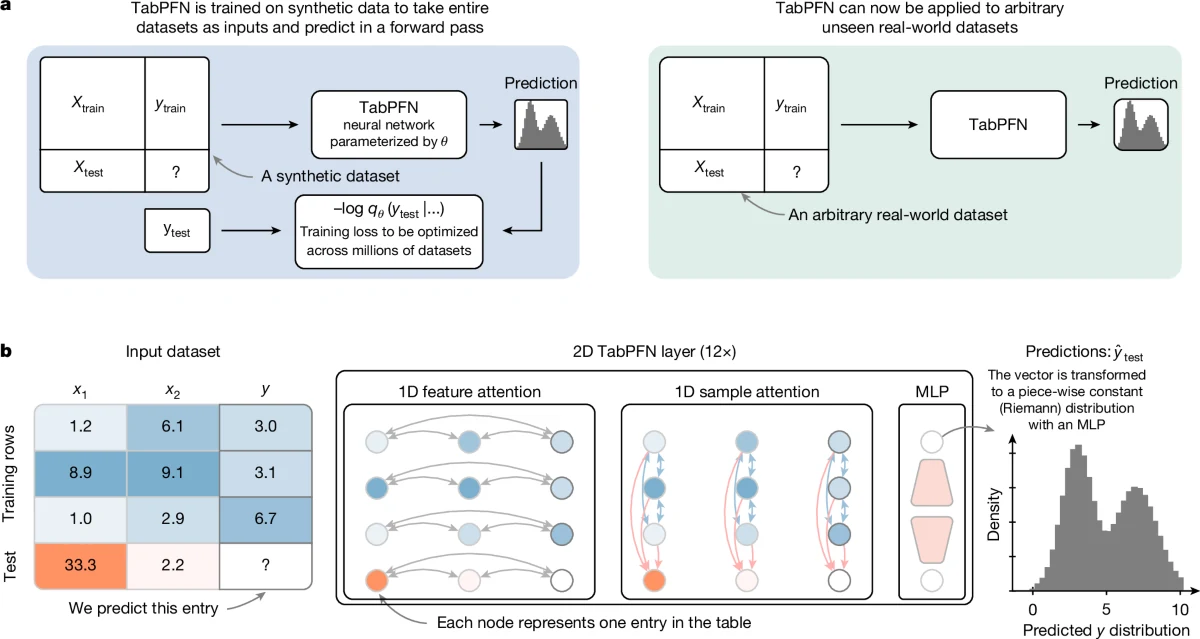
무엇을 해결하려는가
Tabular ML의 병목은 모델 종류가 부족해서 생기는 문제가 아니다.
오히려 반대다.
실무자는 데이터셋마다 결측치 처리, 스케일링, 범주형 처리, feature engineering, 모델 선택, 하이퍼파라미터 탐색, calibration, 해석 가능성 검토를 반복해야 한다.
데이터가 작을수록 overfitting과 split variance가 커지고, 데이터가 중간 규모로 커질수록 튜닝 시간과 운영 복잡도가 늘어난다.
논문은 이 문제를 작은·중간 크기의 독립적인 tabular dataset이 너무 많다는 구조적 특성에서 출발해 설명한다.
OpenML 기준으로 당시 dataset의 76%가 10,000행 미만이라는 관찰도 나온다.
자연어에서는 단어의 의미가 문서 사이에서 어느 정도 공유되지만, 표에서는 같은 숫자라도 drug discovery의 화학적 특성일 수도 있고, 소재과학의 열·전기 특성일 수도 있다.
이 때문에 하나의 거대한 실세계 tabular corpus를 그대로 모아 학습하기 어렵고, 각 도메인마다 작은 데이터셋과 별도 모델이 증식한다.
TabPFN의 답은 synthetic prior다.
실제 표 데이터를 무작정 모으는 대신, structural causal model 기반 생성 절차로 다양한 가짜 tabular task를 만든다.
결측치, 범주형 feature, outlier, 중요하지 않은 feature, smooth/non-smooth 함수, decision-tree형 규칙, 신경망형 비선형 관계를 synthetic task 안에 넣고, 모델이 그 task들을 반복해서 풀게 한다.
이렇게 하면 개인정보·저작권·benchmark contamination 문제를 피하면서도, 실제 표형 데이터에서 자주 보이는 난점을 학습시킬 수 있다.
핵심 아이디어 / 구조 / 동작 방식
TabPFN은 일반적인 supervised deep learning과 적용 단위가 다르다.
보통의 모델은 하나의 데이터셋에서 샘플 단위 mini-batch를 보며 가중치를 업데이트하고, 학습이 끝난 모델을 테스트 샘플에 적용한다.
TabPFN은 사전학습 시점에는 데이터셋 전체를 하나의 task로 보고 학습하며, 추론 시점에는 새로운 데이터셋의 train rows와 test rows를 한 문맥에 넣어 posterior predictive distribution을 바로 근사한다.
구조적으로도 “표를 sequence로 납작하게 넣는 transformer”와 다르다.
논문은 각 cell에 별도 representation을 두고, row 안에서 feature 간 attention을 수행한 뒤 column 방향으로 sample 간 attention을 수행하는 two-way attention 구조를 설명한다.
이 설계는 sample 순서와 feature 순서에 덜 민감하게 만들고, 훈련 때 본 것보다 큰 표에도 더 잘 일반화하도록 돕는다. regression에서는 단일 점 예측이 아니라 piece-wise constant output distribution을 사용해 target의 분포까지 예측한다.
또 하나 중요한 최적화는 train-state caching이다. in-context model은 fit-predict 형태로 반복 호출할 때 train set 계산을 매번 다시 하게 될 수 있다.
TabPFN은 training samples의 key/value 상태를 캐시해 여러 test sample에 재사용하는 경로를 제공한다.
논문은 10,000 training samples와 10 features 조건에서 core inference 기준 CPU 32초를 0.1초로 줄이는 약 300배 speedup, 100 features 조건에서는 CPU 약 800배 speedup을 보고한다.
즉 TabPFN은 “한 번의 forward pass”라는 개념을 실제 fit-predict 인터페이스에 맞추기 위해 inference pipeline도 함께 설계한다.
| 설계 축 | 논문에서 확인되는 내용 | 의미 |
|---|---|---|
| 학습 단위 | 개별 sample이 아니라 synthetic dataset task 전체 | 모델이 데이터셋별 학습 절차를 in-context로 모방 |
| Prior 생성 | structural causal model, neural mapping, decision tree, noise, missingness, quantization | 실제 tabular data의 이질성과 난점을 synthetic task에 주입 |
| Architecture | cell-level representation, feature attention + sample attention + MLP | 표의 2차원 구조를 transformer에 직접 반영 |
| 출력 방식 | classification probability, regression target distribution | 점 예측뿐 아니라 uncertainty와 multimodal target 분포를 표현 |
| 추론 최적화 | train-state / KV caching, flash attention, activation checkpointing | 반복 예측과 더 큰 표에서 계산 비용을 줄이는 운영 장치 |
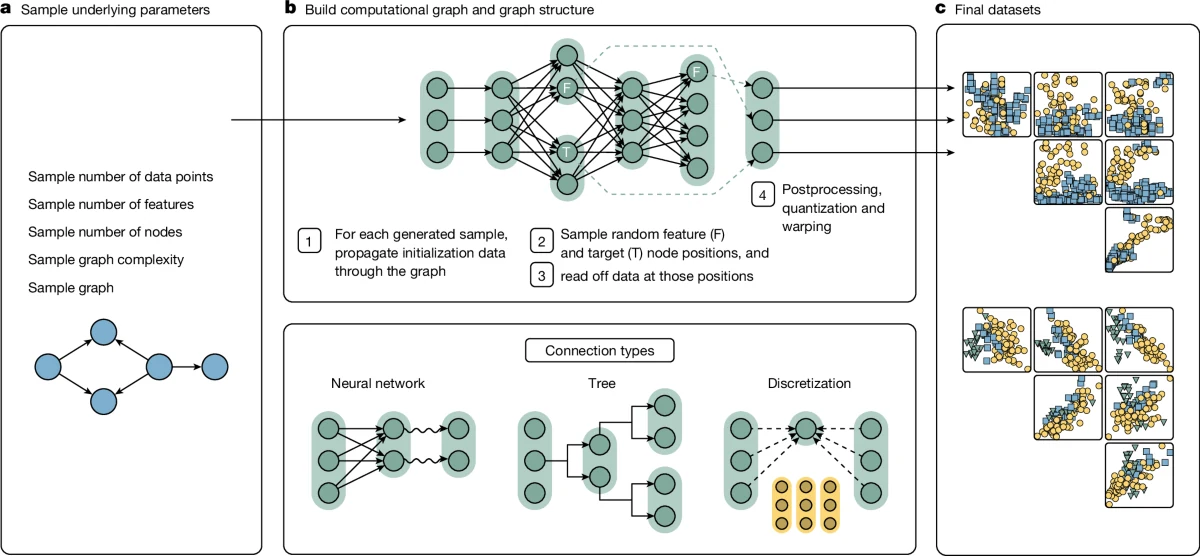
공개된 근거에서 확인되는 점
Nature 논문에서 가장 강한 정량 근거는 10,000 samples, 500 features, 10 classes 이하의 작은·중간 규모 tabular benchmark다.
저자들은 AutoML Benchmark와 OpenML-CTR23에서 29개 classification dataset과 28개 regression dataset을 고르고, 추가로 기존 tabular benchmark와 Kaggle Tabular Playground Series 일부를 평가했다.
비교 대상은 random forest, XGBoost, CatBoost, LightGBM, linear model, SVM, MLP, AutoGluon 등 tabular ML에서 강한 baseline들이다.
핵심 수치는 매우 공격적이다.
논문 기준 default TabPFN은 classification에서 평균 2.8초, regression에서 평균 4.8초가 걸렸고, 4시간 동안 hyperparameter tuning을 허용한 강한 baseline ensemble보다도 높은 성능을 냈다고 보고한다.
저자들은 이를 classification 5,140배, regression 3,000배 speedup으로 표현한다. classification에서는 normalized ROC AUC 기준 default TabPFN 0.939가 default CatBoost 0.752를 넘고, tuned setting에서도 TabPFN 0.952가 CatBoost 0.822를 넘는다. regression에서도 normalized RMSE 기준 default TabPFN 0.923, tuned TabPFN 0.968로 CatBoost 대비 우위를 보인다.
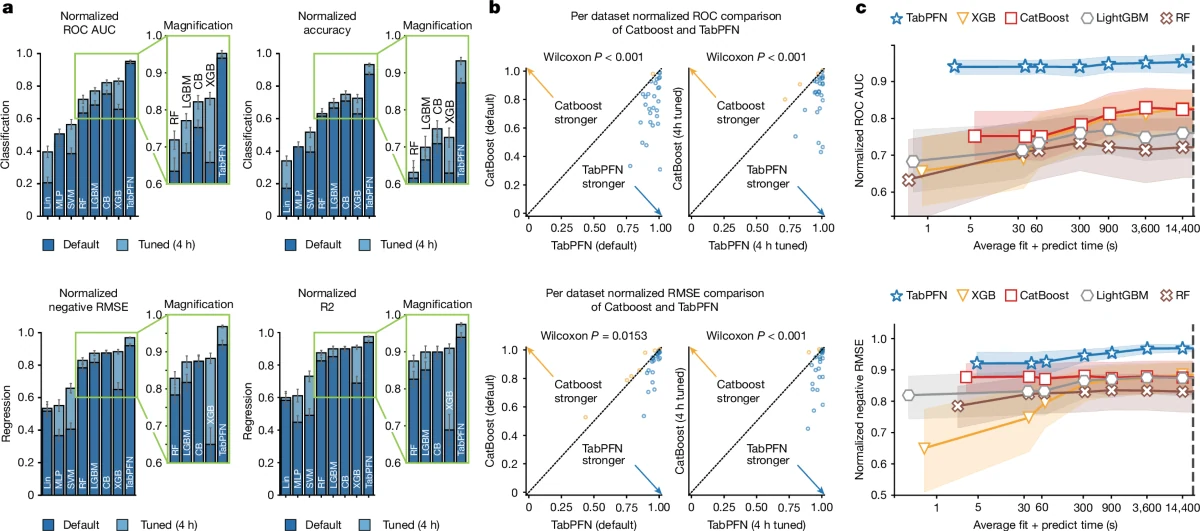
흥미로운 점은 이 성능이 단순히 supervised prediction에만 머물지 않는다는 것이다.
논문은 TabPFN이 density estimation, synthetic data generation, learned embedding extraction, fine-tuning 같은 foundation-model-like ability를 보인다고 주장한다.
German Credit Dataset에서는 feature density와 synthetic sample generation을, mfeat-factors handwritten digit dataset에서는 embedding cluster separation을, sine curve toy task에서는 fine-tuning 후 관련 task로의 transfer를 보여 준다.
이것은 TabPFN을 “빠른 classifier/regressor”가 아니라 tabular data를 위한 reusable representation and generative model로 포지셔닝하려는 시도다.
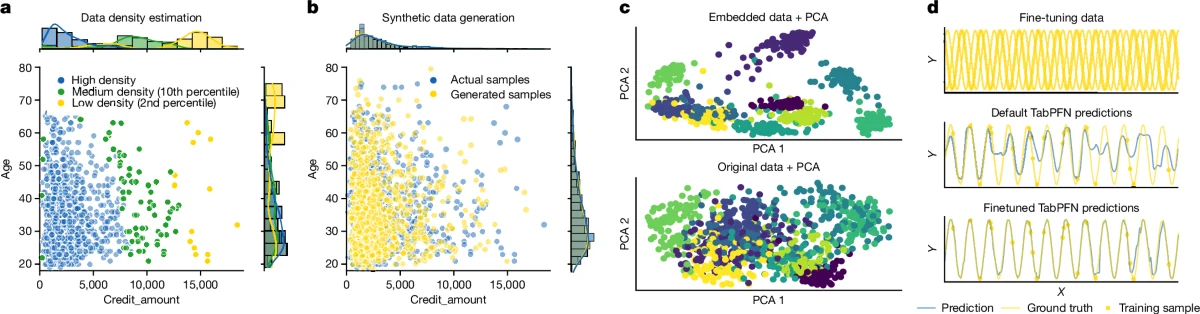
다만 공개 근거는 적용 범위를 함께 읽어야 한다.
논문 자체의 primary evaluation은 10,000 samples와 500 features 이하에 초점을 맞춘다.
Methods의 user guide도 큰 dataset이나 highly non-smooth regression에서는 CatBoost, XGBoost, AutoGluon이 더 나을 수 있다고 명시한다.
실시간 inference에서도 CatBoost가 훨씬 빠른 경우가 있다.
예를 들어 10,000 rows와 10 columns에서 TabPFN은 한 샘플 예측에 GPU 기준 0.2초, GPU 없이 0.6초가 걸리는 반면, default CatBoost는 0.0002초 수준이라고 논문은 설명한다.
| 확인 항목 | 공개 수치 / 사실 | 해석 |
|---|---|---|
| Nature 논문 | 2025-01-08 공개, Nature 637, 319–326, DOI 10.1038/s41586-024-08328-6 |
TabPFN이 연구 아이디어를 넘어 Nature article로 정식화됨 |
| Synthetic task 규모 | final model training run당 약 2,000,000 steps, batch size 64, 약 130M synthetic datasets | 실제 tabular corpus보다 synthetic prior 설계가 중심인 접근 |
| Evaluation 범위 | 최대 10,000 samples, 500 features, 10 classes | 강점이 뚜렷하지만 범위 밖 일반화는 별도 검증 필요 |
| Runtime claim | default TabPFN 2.8초 classification, 4.8초 regression 평균 | 튜닝-heavy AutoML 흐름을 빠른 in-context prediction으로 대체하려는 주장 |
| Baseline 대비 | 4시간 tuned baseline보다 classification 5,140×, regression 3,000× 빠르다고 보고 | 성능과 시간 budget을 함께 봐야 하는 논문 |
| Training cost | 8× RTX 2080 Ti에서 약 2주 pre-training | 거대 GPU 클러스터가 아니라 academic lab scale도 의식한 비용 구조 |
| Code availability | code/Zenodo 공개, synthetic pre-training data generation code는 미공개 | 재사용성은 높지만 prior 재현성에는 제한이 있음 |
논문 이후의 배포 표면도 빠르게 바뀌었다.
현재 GitHub API 기준 PriorLabs/TabPFN 저장소는 stars 7,191, forks 711, latest release v8.0.3이며, PyPI의 tabpfn 최신 버전도 8.0.3이다.
현재 README와 PyPI 설명은 default model을 TabPFN-3로 설명한다.
Hugging Face의 Prior-Labs/tabpfn_3 API는 TabPFN-3 checkpoint 묶음, classifier/regressor 파일, non-commercial 성격의 별도 model-weight license 설명을 노출한다.
즉 Nature 논문이 제시한 원리는 이후 패키지와 모델 버전을 거치며 제품형 prediction stack으로 계속 확장되고 있다.
라이선스는 실무 도입에서 특히 중요하다.
GitHub code와 일부 구성은 Prior Labs License, 즉 Apache 2.0에 attribution 조항을 더한 형태로 설명되지만, TabPFN-2.5, TabPFN-2.6, TabPFN-3 model weights는 별도의 non-commercial license 계열로 안내된다.
Prior Labs는 production use case에는 commercial enterprise license와 high-speed inference engine, support를 별도 경로로 둔다.
따라서 TabPFN은 연구·내부 평가·PoC에는 매우 매력적이지만, 상용 제품에 바로 넣는 “자유로운 오픈 웨이트”로 읽으면 안 된다.
실무 관점에서의 해석
TabPFN의 실무적 가치는 “boosting을 완전히 대체한다”보다 “small-data tabular workflow의 첫 baseline을 바꿀 수 있다”에 가깝다.
작은 표형 데이터셋에서 CatBoost/XGBoost/AutoML을 몇 시간씩 돌리기 전에, TabPFN을 빠른 high-quality prior로 먼저 호출하고, 그 결과를 기준선이나 ensemble component로 삼을 수 있다.
특히 biomedical, materials, climate, finance처럼 dataset 수는 많고 각 dataset은 크지 않은 환경에서는 이 접근이 실험 반복 속도를 크게 바꿀 수 있다.
또 하나의 의미는 tabular ML의 foundation-model화가 텍스트 LLM과 다르게 진행된다는 점이다.
텍스트에서는 웹 규모 corpus를 모아 next-token prediction을 학습하는 방식이 중심이었다면, TabPFN은 synthetic causal prior를 설계하고 그 위에서 “어떤 학습 알고리즘이 좋은가”를 학습한다.
이 차이는 중요하다.
표형 데이터에서는 대규모 공개 데이터 자체보다, 어떤 prior가 현실의 표 문제를 잘 대표하는지가 성능과 신뢰성을 좌우한다.
결국 TabPFN의 장점과 한계는 모델 크기보다 prior 설계의 품질에 걸려 있다.
운영 관점에서는 조심해야 할 부분도 분명하다.
논문은 큰 dataset, 많은 class, real-time low-latency inference에서 한계를 직접 인정한다. pre-training prior generation code가 공개되지 않았다는 점은 연구 재현성 측면의 빈틈이고, 최신 weights의 non-commercial 조건은 상업팀에게 법무 검토를 요구한다.
또한 현재 패키지·문서·모델 버전이 빠르게 바뀌고 있어, 논문 수치와 최신 package default를 혼동하면 안 된다.
Nature article은 TabPFN 접근의 과학적 근거이고, 현재 Prior Labs 생태계는 그 접근을 제품형 stack으로 발전시키는 별도 시간축이다.
그럼에도 TabPFN이 던지는 질문은 꽤 크다.
표형 데이터 문제를 풀 때 앞으로도 매번 모델을 새로 학습하고 튜닝해야 하는가, 아니면 이미 학습된 tabular foundation model을 하나의 예측 런타임처럼 호출하면 되는가.
답은 아직 모든 데이터셋에서 후자로 끝나지 않는다.
하지만 작은 데이터가 많고 iteration speed가 중요한 환경에서는 TabPFN이 이미 충분히 강한 두 번째 기본값이 되기 시작했다. tabular ML에서 foundation model이라는 말이 추상적 구호가 아니라, 실제 예측 스택의 설계 단위가 될 수 있음을 보여 준 사례다.