Geoffrey Hinton의 The Forward-Forward Algorithm: Some Preliminary Investigations는 제목 그대로 “예비 조사”에 가깝다.
이 논문은 새로운 SOTA 학습 레시피를 제안한다기보다, 역전파가 너무 강력해서 거의 당연하게 받아들여지는 현재의 학습 패러다임을 한 번 비틀어 본다.
핵심 질문은 단순하다. forward pass와 backward pass를 쓰는 대신, 같은 forward computation을 두 번 실행해 학습할 수 있는가?
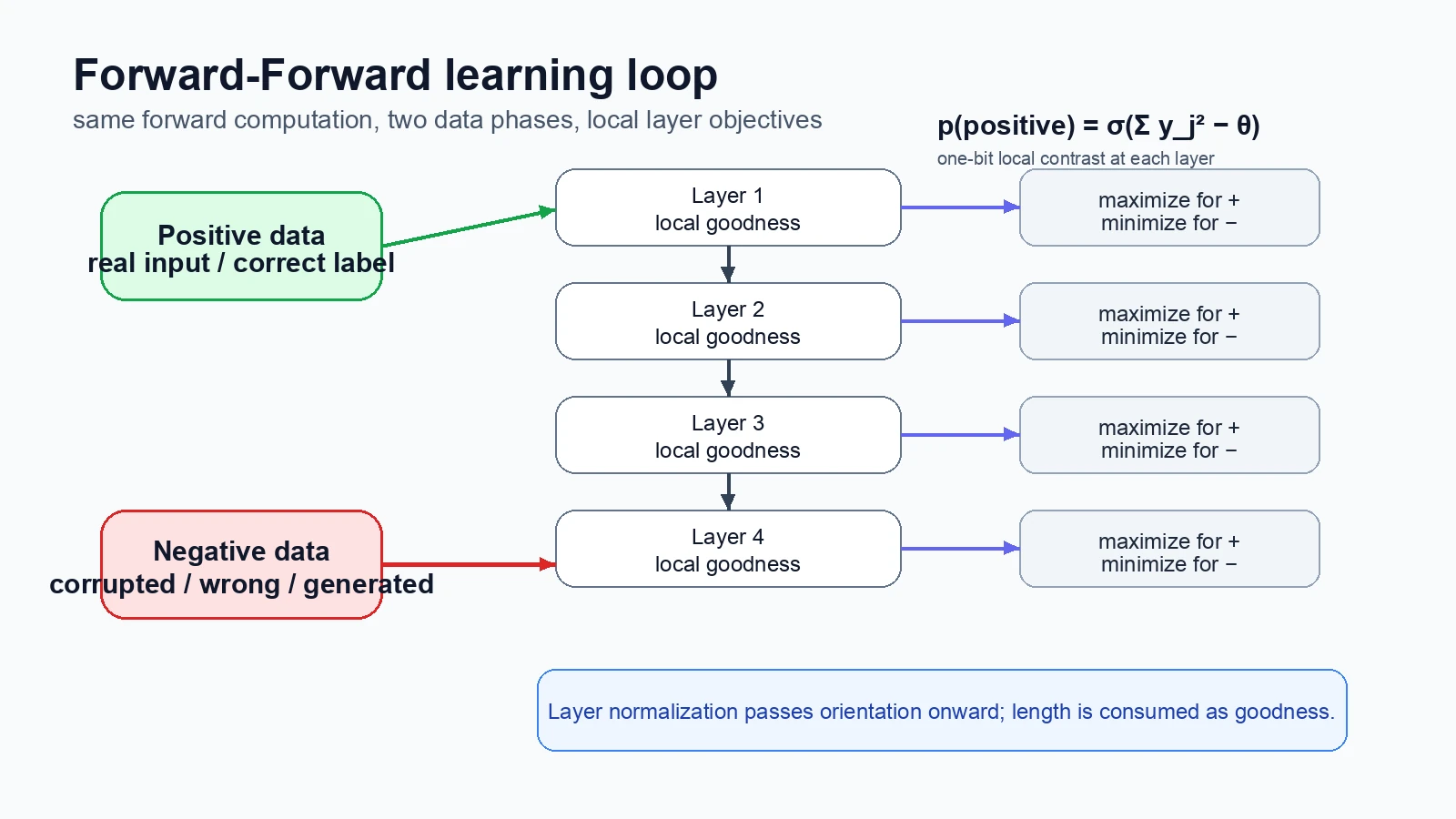
Forward-Forward, 줄여서 FF는 positive data와 negative data를 각각 한 번씩 통과시킨다. positive pass에서는 각 layer의 goodness가 높아지도록, negative pass에서는 낮아지도록 가중치를 바꾼다.
여기서 goodness는 가장 단순하게는 해당 layer의 pre-normalization activation 제곱합이다.
즉 모델 전체의 loss를 끝에서부터 역전파하는 대신, 각 layer가 자기 자리에서 “이 입력은 진짜인가, 가짜인가”를 구분하는 local objective를 갖는다.
이 아이디어가 중요한 이유는 성능표만으로는 잘 보이지 않는다.
Hinton도 논문 안에서 FF가 backprop보다 약간 느리고 여러 toy problem에서 일반화도 조금 떨어진다고 선을 긋는다.
그럼에도 FF가 흥미로운 이유는, cortex의 학습 모델, unknown non-linearity가 섞인 black-box hardware, 그리고 저전력 analog computation 같은 영역에서는 “정확한 backward derivative를 계산할 수 있는가”보다 “local forward-only update가 가능한가”가 더 본질적인 질문이기 때문이다.
무엇을 해결하려는가
Backpropagation은 현재 딥러닝의 사실상 표준이다.
많은 파라미터와 많은 데이터에서 stochastic gradient descent가 작동한다는 사실은 지난 10여 년의 foundation model scaling이 반복해서 보여줬다.
문제는 backprop이 계산적으로는 강력하지만 구조적으로는 꽤 엄격한 가정을 요구한다는 점이다.
첫째, forward pass에서 어떤 계산이 일어났는지 완벽히 알아야 한다.
중간에 unknown black box가 들어가면 그 black box의 미분 가능한 모델을 배우지 않는 한 정확한 derivative를 전달할 수 없다.
둘째, backward pass를 위해 activation을 저장하거나 재계산해야 한다.
시퀀스 데이터를 실시간으로 파이프라인 처리해야 하는 시스템, 특히 뇌를 학습 모델로 생각할 때는 이 점이 부자연스럽다.
셋째, analog hardware에서는 행렬곱 자체는 전압과 conductance로 매우 효율적으로 구현할 수 있어도, 정확한 digital gradient computation과 A/D conversion이 병목이 될 수 있다.
강화학습식 perturbation으로 우회할 수도 있지만, 논문은 이 길도 비싸다고 본다.
많은 변수에 동시에 perturbation을 주면 variance가 커지고, noise를 평균내기 위해 learning rate를 변수 수에 반비례해서 줄여야 한다.
대규모 네트워크에서는 이 방식이 backprop과 경쟁하기 어렵다.
FF가 겨냥하는 틈은 여기다.
모델이 모든 연산의 derivative를 알지 못해도, 각 layer가 positive와 negative를 local하게 구분할 수 있다면 학습이 가능할 수 있다.
또한 positive phase와 negative phase를 시간적으로 분리할 수 있다면, positive data는 온라인으로 흘려보내고 negative data는 offline으로 처리하는 구조도 상상할 수 있다.
논문은 이것을 cortex 학습, sleep-like negative phase, low-power analog hardware, mortal computation과 연결한다.
핵심 아이디어 / 구조 / 동작 방식
FF의 기본 형태는 greedy multi-layer learning procedure다. positive pass와 negative pass는 동일한 forward computation을 사용하지만 objective의 부호가 반대다. positive data는 실제 입력 또는 정답 label과 결합된 입력이고, negative data는 corrupted input, 잘못된 label과 결합된 입력, 혹은 미래에는 네트워크가 스스로 생성한 입력일 수 있다.
가장 단순한 goodness는 layer의 ReLU activation을 y_j라고 할 때 다음처럼 정의된다.
p(positive) = σ(Σ_j y_j² - θ)
여기서 θ는 threshold다. positive data에서는 Σ_j y_j²가 threshold보다 충분히 커지기를 원하고, negative data에서는 충분히 작아지기를 원한다.
이 objective는 layer마다 따로 존재한다.
마지막 출력 loss를 역전파하는 것이 아니라, layer-local binary classification 문제를 여러 개 푸는 셈이다.
그런데 단순히 첫 번째 hidden layer의 activation 길이를 다음 layer에 넘기면 문제가 생긴다.
다음 layer는 새로운 feature를 배우지 않고도 “이전 layer activation vector가 길다/짧다”만 보고 positive와 negative를 구분할 수 있다.
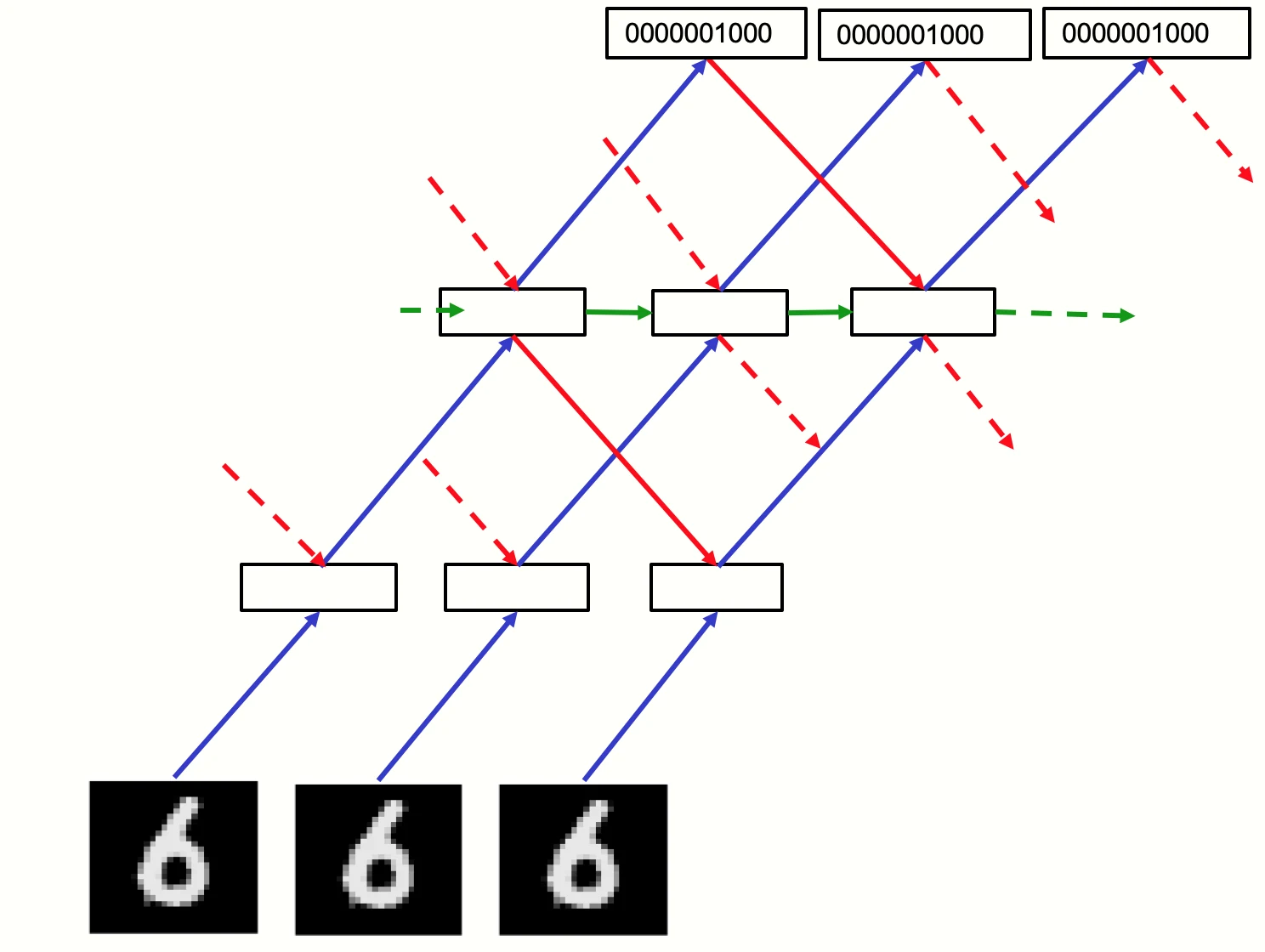
논문은 이를 막기 위해 hidden vector를 다음 layer로 넘기기 전에 length normalization을 적용한다.
직관적으로 말하면, activation의 길이는 그 layer의 goodness로 소비하고, 다음 layer에는 orientation만 넘긴다.
| 구성 요소 | FF에서의 역할 | 해석 |
|---|---|---|
| Positive data | 실제 데이터, 정답 label이 붙은 입력 | goodness를 높여야 하는 입력 |
| Negative data | corrupted data, 오답 label, 혹은 generated sample | goodness를 낮춰야 하는 입력 |
| Goodness | 주로 pre-normalization activation 제곱합 | layer-local real/fake score |
| Layer normalization | goodness에 쓰인 길이 정보를 제거 | 다음 layer가 새 feature를 배우도록 강제 |
Threshold θ |
positive 확률의 기준점 | local binary objective의 margin 역할 |
supervised MNIST 예시는 특히 직관적이다.
이미지의 검은 border 중 첫 10개 pixel을 label의 one-hot representation으로 바꾼다. positive example은 이미지와 정답 label의 조합이고, negative example은 이미지와 오답 label의 조합이다.
학습된 모델은 테스트 때 각 label을 입력에 넣어보고 여러 hidden layer의 goodness를 누적한 뒤, goodness가 가장 높은 label을 고를 수 있다.
더 빠르지만 덜 좋은 방식으로는 neutral label을 넣어 한 번 forward pass를 한 뒤 softmax classifier를 쓰는 방법도 있다.
비지도 설정에서는 negative data를 손으로 만든다.
논문은 두 MNIST digit image를 큰 mask로 섞어 short-range statistics는 비슷하지만 long-range shape correlation은 깨지는 hybrid image를 만든다.
이 방식은 FF가 단순한 pixel-level 차이가 아니라 shape를 설명하는 장거리 상관을 보도록 유도한다.

논문 후반부는 FF를 단순 feed-forward network에만 묶어두지 않는다. static image를 “지루한 video”로 보고 recurrent network를 돌리면, 한 layer의 activity가 아래 layer와 위 layer의 이전 time-step activity를 함께 받아 결정된다.
이 구조에서는 top-down input이 spatial context나 category-level expectation처럼 작동하고, bottom-up input과의 agreement가 goodness가 된다.
목적 함수 부호를 반대로 잡으면 positive data에서 top-down input이 bottom-up input을 cancel하도록 학습할 수도 있는데, Hinton은 이를 predictive coding과 닮은 형태로 해석한다.
공개된 근거에서 확인되는 점
논문의 실험은 의도적으로 작다.
대부분은 MNIST이고, CIFAR-10도 weight-sharing 없는 local receptive field network에서 비교한다.
따라서 이 논문을 modern foundation model training recipe처럼 읽으면 안 된다.
대신 “backprop 없이도 작은 네트워크가 실제로 의미 있는 표현을 배우는가”를 확인하는 proof-of-concept로 보는 편이 맞다.
MNIST에서 먼저 보는 것은 손으로 만든 negative data를 쓰는 비지도 표현 학습이다.
4개의 hidden layer, layer당 2000 ReLU를 100 epoch 학습한 뒤, 마지막 세 hidden layer의 normalized activity를 linear classifier에 넣으면 test error 1.37%가 나온다. weight-sharing 없는 local receptive field architecture를 쓰면 60 epoch 후 1.16%까지 내려간다.
논문이 제시한 permutation-invariant MNIST의 전형적 backprop baseline이 약 1.4%라는 점을 감안하면, 작은 문제에서는 꽤 설득력 있는 신호다.
supervised FF에서는 label을 입력에 직접 포함한다.
4개의 fully-connected hidden layer, layer당 2000 ReLU network는 60 epoch 후 MNIST test error 1.36%를 기록한다.
학습 속도는 backprop보다 느리다.
논문은 backprop이 비슷한 성능에 약 20 epoch 정도면 도달한다고 적는다. data augmentation으로 이미지를 최대 2 pixel jittering하고 500 epoch 학습하면 test error 0.64%가 나오며, 이는 backprop으로 학습한 convolutional network와 비슷한 수준이라고 설명한다.

CIFAR-10 결과는 더 차갑게 봐야 한다.
논문은 convolutional weight-sharing이 아니라 local receptive field를 쓰는 backprop network와 FF를 비교한다.
FF는 backprop보다 test error가 높고, training error도 훨씬 높게 남는다.
다만 gap이 layer 수 증가와 함께 크게 벌어지지는 않고, label별 goodness를 계산하는 방식이 one-pass softmax보다 낫다.
| 실험 축 | 설정 | 논문에서 보고한 핵심 수치 | 읽을 포인트 |
|---|---|---|---|
| MNIST 비지도 FF | 4 hidden layers, 2000 ReLUs, hybrid negative data | 1.37% test error | hand-crafted negative data만으로도 표현 학습 가능 |
| MNIST local receptive fields | weight-sharing 없는 local architecture | 1.16% test error | fully-connected보다 spatial locality가 도움 |
| MNIST supervised FF | label을 입력 첫 10 pixel에 삽입 | 1.36% test error after 60 epochs | backprop보다 느리지만 같은 범위 성능 |
| MNIST supervised + jitter | 25 shifts augmentation, 500 epochs | 0.64% test error | CNN backprop과 비슷한 수준까지 접근 |
| Recurrent static-MNIST | 8 recurrent iterations, label별 goodness | 1.31% test error | top-down/bottom-up agreement 실험 |
| CIFAR-10 FF vs BP | local receptive field, 2-3 hidden layers | BP 37-39%, FF best 41% test error | FF가 뒤지지만 toy comparison은 성립 |
CIFAR-10 table을 조금 더 자세히 보면, 2 hidden layer backprop은 training error 0%, test error 37%다.
FF에서 sum-squared activity를 positive에서 낮추는 min ssq 버전으로 label별 goodness를 계산하면 training error 20%, test error 41%다.
같은 2 hidden layer에서 one-pass softmax를 쓰면 test error는 45%로 나빠진다.
3 hidden layer에서도 backprop은 test error 39%, FF의 best case는 41% 수준이다.
즉 FF가 SOTA가 아니라는 점은 명확하지만, “local goodness만으로 전혀 학습이 안 된다”는 결과도 아니다.
논문에서 가장 중요한 negative result는 sleep section에 있다.
Hinton은 초기 draft에서 positive update 여러 번과 network-generated negative update 여러 번을 시간적으로 분리해도 성능 손실이 작다고 보고했지만, 나중에 이를 재현하지 못했고 bug였을 가능성이 있다고 적는다.
현재 형태의 FF에서 positive phase와 negative phase를 길게 분리하는 것은 낮은 learning rate와 매우 높은 momentum이 아니면 잘 되지 않았다.
이는 FF가 biological sleep model로 설득력을 얻기 위해 해결해야 할 가장 큰 open question으로 남는다.
공개 아티팩트 관점에서도 조심해야 한다. arXiv 논문과 Hinton의 Toronto PDF, arXiv source bundle은 확인할 수 있지만, Hugging Face Papers 페이지 기준으로 이 논문을 직접 연결한 model, dataset, Space는 0개로 표시된다.
검색되는 PyTorch reimplementation들은 유용한 참고 자료일 수 있지만, 이 글에서는 논문의 primary artifact와 별개의 third-party 구현으로 보는 것이 안전하다.
즉 현재 공개 근거의 중심은 code release가 아니라 paper와 source figures다.
실무 관점에서의 해석
FF를 실무 학습 파이프라인에 바로 넣는 것은 아직 무리다.
실험 규모는 MNIST와 CIFAR-10 수준이고, negative data를 어떻게 만들 것인지가 핵심 병목으로 남아 있다. supervised setting에서는 label을 입력에 넣고 모든 label에 대해 goodness를 계산하는 방식이 정확도에는 좋지만, label 수가 커지면 inference 비용이 커질 수 있다. one-pass softmax는 빠르지만 논문 결과에서는 성능이 떨어진다.
그럼에도 FF는 몇 가지 실용적 질문을 선명하게 만든다.
첫째, layer-local objective는 여전히 매력적이다. modern deep learning에서는 end-to-end backprop이 당연하지만, distributed system, neuromorphic device, black-box module, privacy boundary가 있는 pipeline에서는 전체 graph를 미분 가능하게 연결하기 어려울 수 있다.
이때 각 block이 positive/negative evidence를 local하게 구분하는 방식은 하나의 설계 공간을 연다.
둘째, negative data 설계가 학습의 본체가 된다.
FF는 self-supervised contrastive learning과 마찬가지로 “무엇을 negative로 볼 것인가”에 크게 의존한다.
MNIST hybrid image처럼 short-range statistics를 유지하면서 long-range structure만 깨뜨리는 negative는 좋은 inductive bias를 준다.
하지만 자연 이미지, 언어, multimodal stream에서 이런 negative를 어떻게 만들지는 훨씬 어렵다. network가 스스로 negative data를 생성할 수 있어야 FF의 큰 그림이 완성되지만, 논문은 이 부분을 아직 open question으로 남겨둔다.
셋째, analog hardware와 mortal computation 논의는 지금 다시 읽어도 흥미롭다.
Hinton은 software와 hardware를 분리해 같은 weight를 여러 장치에 복사하는 “immortal computation” 대신, 각 physical hardware instance의 unknown property에 맞춰 parameter가 학습되고 그 하드웨어와 함께 죽는 “mortal computation”을 말한다.
이 세계에서는 완벽히 동일한 digital model copy를 전제하는 backprop보다, hardware-specific non-linearity를 그대로 품고 forward-only로 학습하는 절차가 더 자연스러울 수 있다.
| 관점 | FF가 주는 가능성 | 아직 남은 문제 |
|---|---|---|
| 생물학적 plausibility | error derivative 대신 neural activity phase만 사용 | positive/negative phase 분리와 sleep-like 학습은 미해결 |
| Black-box module | unknown transformation을 사이에 넣어도 layer-local FF는 가능 | 전체 system objective를 어떻게 안정적으로 맞출지 불명확 |
| Analog hardware | backward derivative/A-D converter 의존을 줄일 수 있음 | 실제 large-scale analog implementation 증거는 없음 |
| 표현 학습 | negative data만 잘 만들면 local feature 학습 가능 | negative generation이 domain별로 어려움 |
| 현대 ML 적용 | local contrastive objective와 modular training 연구에 힌트 | foundation model 규모에서 scaling evidence 부족 |
내가 보기에 이 논문의 가치는 “backprop을 대체했다”가 아니라 “backprop이 너무 당연해서 보이지 않던 제약을 드러냈다”는 데 있다.
대형 모델 학습은 당분간 계속 backprop 위에 있을 가능성이 높다.
Hinton도 power가 문제되지 않는 application에서는 FF가 backprop을 대체할 가능성이 낮다고 쓴다.
그러나 에너지, 물리적 하드웨어, online learning, local objective, biologically plausible learning을 함께 놓고 보면 FF는 여전히 좋은 사고 실험이다.
특히 최근의 AI 시스템은 점점 더 heterogeneous해지고 있다. differentiable neural network만 있는 것이 아니라 retrieval index, simulator, tool call, non-differentiable environment, specialized accelerator, privacy boundary가 섞인다.
이런 시스템에서 “모든 것을 하나의 graph로 묶어 끝에서부터 미분하자”는 사고는 점점 비싸질 수 있다.
FF가 바로 답은 아니지만, layer나 module이 자기 위치에서 local evidence를 축적하고, positive/negative phase로 학습하는 방향은 앞으로도 반복해서 돌아올 연구 주제처럼 보인다.