OCR은 오랫동안 문서 AI 파이프라인의 가장 앞단에 있는 전처리로 취급됐다.
이미지를 텍스트로 바꾸고, 그 다음 단계에서 별도 파서나 LLM이 표, 양식, 필드, 검색용 chunk를 다시 해석하는 식이다.
하지만 RAG와 에이전트가 실제 업무 문서를 읽기 시작하면 이 구분은 금방 무너진다.
중요한 것은 글자를 맞히는 것만이 아니라, 문서의 표 구조와 이미지, 헤더·푸터, 필드 관계를 다음 시스템이 쓸 수 있게 보존하는 일이다.
Mistral OCR 3는 이 문제를 정면으로 겨냥한 Mistral의 새 문서 처리 모델이다.
공식 발표 기준 모델 식별자는 mistral-ocr-2512이며, Mistral AI Studio의 Document AI Playground와 /v1/ocr API에서 사용할 수 있다.
Mistral은 OCR 3가 Mistral OCR 2 대비 forms, scanned documents, complex tables, handwriting 영역에서 전체 74% win rate를 보였고, enterprise document processing 솔루션과 AI-native OCR 솔루션을 모두 앞선다고 주장한다.
이 릴리스에서 흥미로운 점은 “더 좋은 OCR”이라는 말보다, OCR을 문서-to-지식 변환 계층으로 포지셔닝한다는 데 있다.
출력은 단순 plain text가 아니라 Markdown, HTML 기반 table reconstruction, 이미지 bounding box, structured annotation, confidence score까지 확장된다.
즉 OCR 3는 사람이 읽는 텍스트를 만드는 엔진이라기보다, RAG·검색·업무 자동화·에이전트가 읽을 수 있는 문서 객체를 만드는 인프라에 가깝다.

무엇을 해결하려는가
문서 처리의 어려움은 대부분 “깨끗한 텍스트가 있는 PDF” 바깥에서 생긴다.
실제 기업 문서는 스캔 품질이 낮고, 압축 artifact와 기울어짐이 있으며, 표는 병합 셀과 다중 헤더를 갖고, 양식에는 인쇄 텍스트 위에 손글씨가 겹친다.
전통적인 OCR 엔진이 문자 단위로는 그럭저럭 동작해도, 이런 문서를 후속 시스템이 안정적으로 읽게 하려면 구조가 함께 살아 있어야 한다.
Mistral 발표가 반복해서 강조하는 대상도 이 지점이다.
OCR 3는 forms, scanned and complex documents, handwriting, complex tables를 주요 개선 영역으로 제시한다.
특히 table output에서는 Markdown만으로 감당하기 어려운 merged cell, multi-row block, column hierarchy를 보존하기 위해 HTML table tag와 colspan/rowspan을 활용한다고 설명한다.
이것은 문서를 사람이 보기 좋게 옮기는 문제가 아니라, 표 구조를 downstream parser가 다시 사용할 수 있게 만드는 문제다.
문서 AI 제품 관점에서는 이 차이가 크다.
인보이스에서 필드를 뽑거나, 기술 보고서를 검색 가능하게 만들거나, 과거 아카이브를 디지털화하거나, 에이전트가 계약서·보고서·양식을 읽게 하려면 OCR 결과가 단순 문자열이어서는 부족하다.
페이지별 원문, 표, 이미지 위치, 신뢰도, 필요하면 JSON schema 기반 annotation까지 이어져야 검수와 자동화가 가능하다.
핵심 아이디어 / 구조 / 동작 방식
OCR 3의 공개 표면은 세 층으로 나눠 볼 수 있다.
첫째는 mistral-ocr-2512 모델 자체다.
공식 모델 페이지는 OCR 3를 Mistral Document AI stack을 구동하는 OCR service로 설명하며, interleaved text and images 추출을 핵심 기능으로 둔다.
가격은 기본 OCR 기준 1,000페이지당 2달러, Batch API 할인 시 1,000페이지당 1달러로 제시돼 있다.
같은 모델 페이지에는 annotated pages 가격으로 1,000페이지당 3달러도 별도로 표시된다.
둘째는 /v1/ocr API다.
Document AI OCR processor 문서와 API reference를 보면 입력은 PDF·PPTX·DOCX 같은 document_url 또는 PNG/JPEG/AVIF 등 image_url이 될 수 있다.
응답은 page object 배열이며, 각 page에는 Markdown, 추출 이미지, table, hyperlink, page dimension, header/footer, confidence score 등이 들어갈 수 있다. table_format은 null, markdown, html 사이에서 선택할 수 있고, OCR 2512 이후에는 table formatting과 header/footer extraction을 별도 필드로 꺼낼 수 있다.
셋째는 Document AI Playground와 structured annotation 표면이다.
발표 글은 Playground를 PDF나 이미지를 드래그 앤 드롭해 clean text 또는 structured JSON으로 바꾸는 인터페이스로 소개한다.
API 레벨에서는 document_annotation_format, bbox_annotation_format, document_annotation_prompt 같은 옵션을 통해 문서 전체 또는 bounding box 단위의 annotation을 JSON object나 JSON schema 형태로 요구할 수 있다.
이 조합은 OCR을 사람이 직접 보는 결과물에서 끝내지 않고, 업무 시스템에 넣을 수 있는 구조화 출력으로 연결한다.
공개 문서 기준으로 정리하면 다음과 같다.
| 레이어 | 공개 자료에서 확인되는 구성 | 실무적 의미 |
|---|---|---|
| 모델 | mistral-ocr-2512, mistral-ocr-latest 계열 OCR processor |
OCR 3를 API와 Document AI stack의 기본 처리 모델로 사용 |
| 기본 출력 | Page-level Markdown, images, dimensions, hyperlinks | RAG·검색·요약 시스템이 문서 내용을 바로 소비하기 쉬움 |
| 표 복원 | table_format=markdown 또는 table_format=html |
복잡한 table hierarchy를 Markdown/HTML 구조로 분리 가능 |
| 구조화 추출 | document/bbox annotation format, JSON object/schema | 양식·계약서·인보이스에서 업무 필드 추출로 연결 가능 |
| 품질 관리 | page/word confidence score, header/footer extraction | 대량 처리 후 검수·fallback·human review 정책 설계에 필요 |
| 운영 표면 | API, Batch API, Playground, self-hosting option | 실험용 UI부터 대량 처리와 민감 데이터 배포까지 포괄 |
공개된 근거에서 확인되는 점
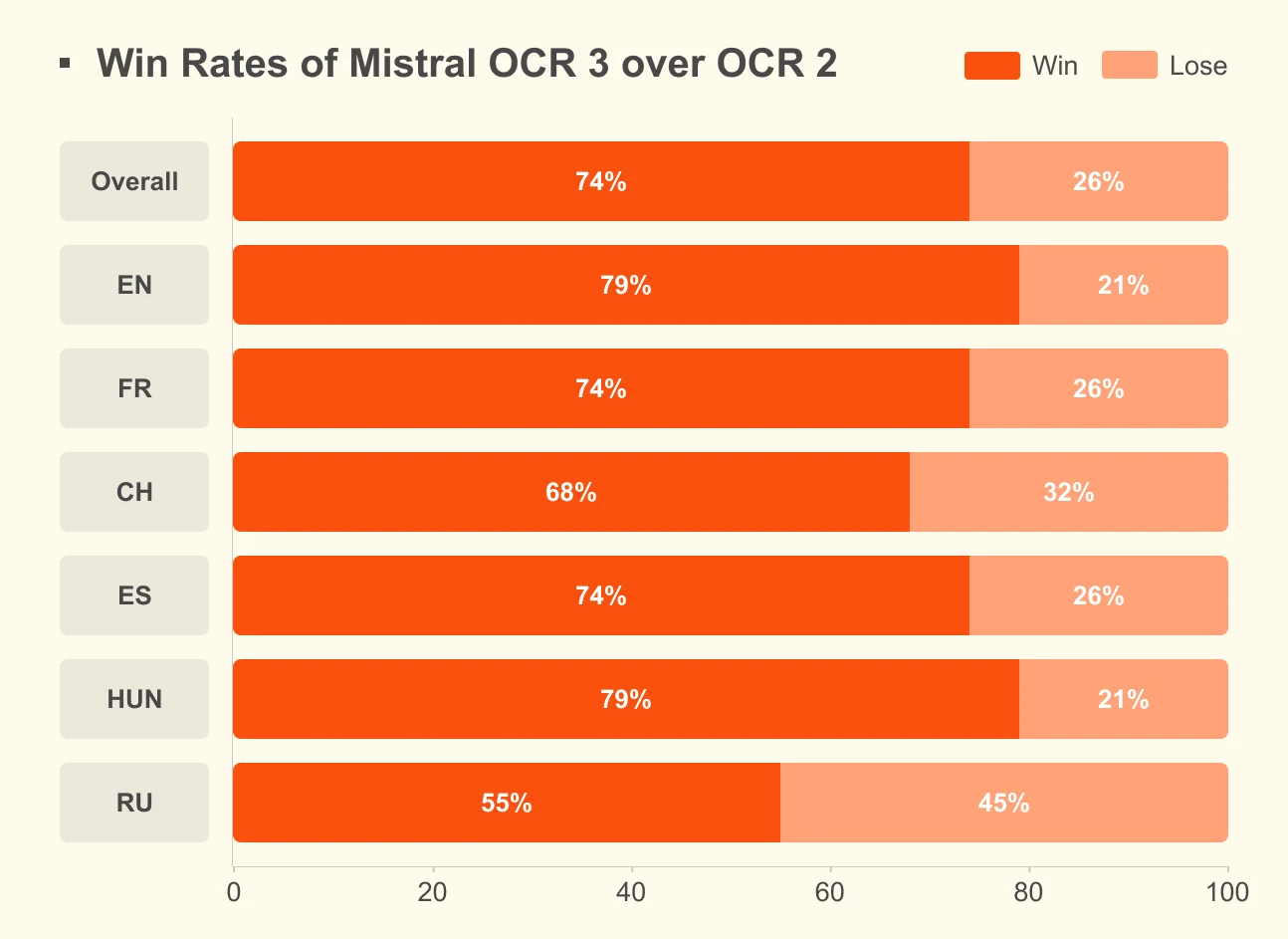
가장 강한 headline 수치는 OCR 2 대비 74% overall win rate다.
Mistral은 고객의 실제 business use-case examples를 기반으로 더 어려운 내부 benchmark를 만들고, 여러 모델 출력을 ground truth와 fuzzy-match metric으로 비교했다고 설명한다.
평가 도메인은 forms, scanned documents, complex tables, handwriting이며, 발표 글은 OCR 3가 전체 언어와 문서 form factor에서 OCR 2보다 유의미하게 개선됐다고 주장한다.
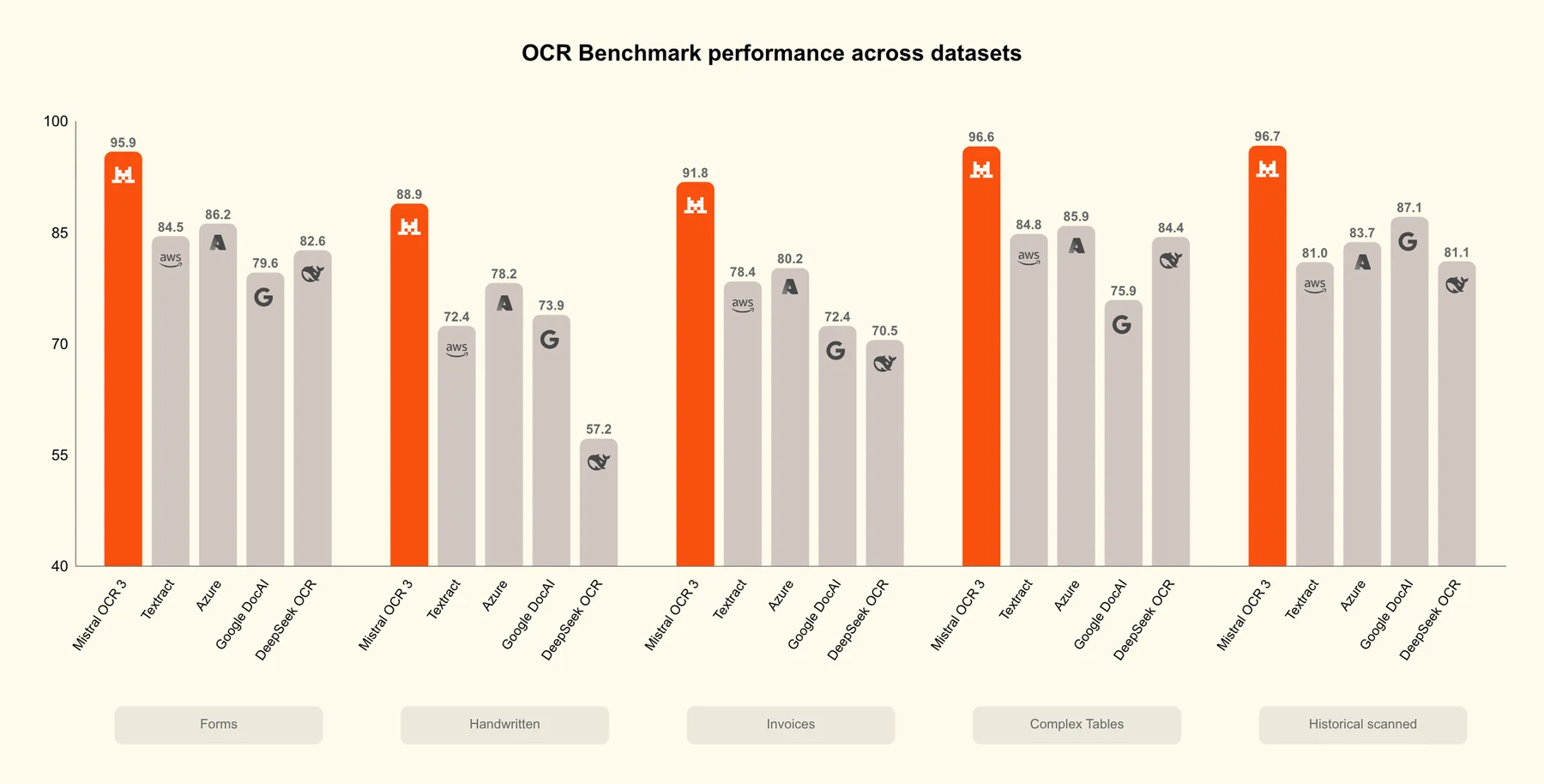
공식 시각 자료는 두 가지 비교 축을 보여 준다.
하나는 OCR 3가 다른 OCR/document model들과 비교해 정확도 경쟁을 한다는 점이고, 다른 하나는 OCR 2 대비 어떤 문서 유형에서 win rate가 높아졌는지를 보여 주는 점이다.
다만 이 benchmark는 공개 데이터셋 리더보드가 아니라 Mistral이 설명한 internal benchmark다.
따라서 수치는 제품 방향과 상대적 개선 신호로 읽는 편이 맞고, 도입 팀은 자기 문서 샘플로 별도 검증해야 한다.
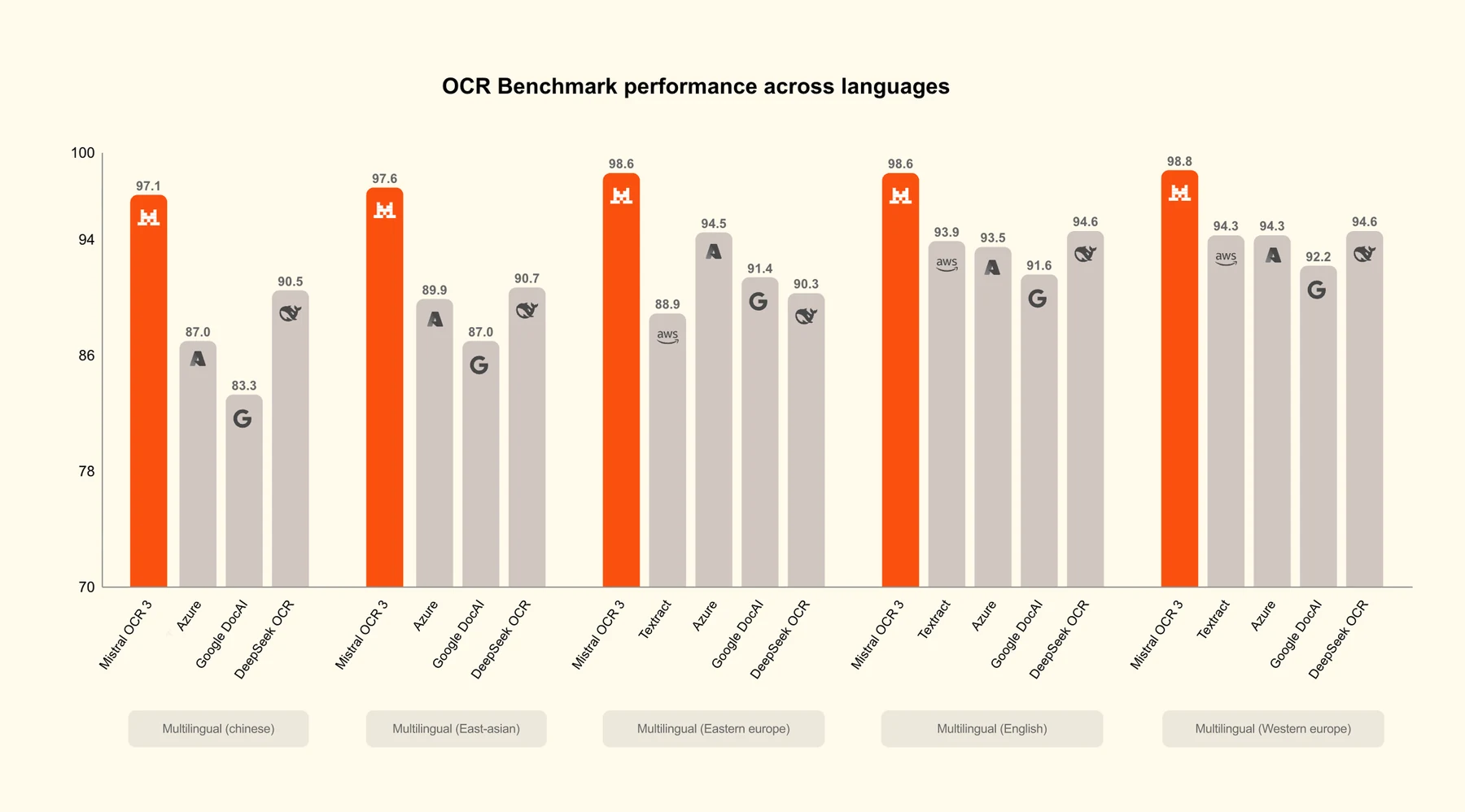
문서 범위도 중요하다.
발표 글은 handwriting에서는 cursive, mixed-content annotation, printed form 위 손글씨를 더 잘 해석한다고 말한다.
Forms에서는 box, label, handwritten entry, dense layout detection을 개선했다고 설명한다.
Scanned and complex documents에서는 compression artifact, skew, distortion, low DPI, background noise에 더 강하다고 한다.
Complex tables에서는 merged cell, multi-row block, column hierarchy를 보존하는 table reconstruction을 강조한다.
문서와 API reference에서 확인되는 운영 기능도 꽤 구체적이다.
OCR processor는 image placeholder와 table placeholder를 Markdown 안에 넣고, 실제 image/table object는 별도 images와 tables 필드로 매핑할 수 있게 한다.
Confidence score는 page 수준 또는 word 수준으로 받을 수 있다.
대량 처리에는 Batch Inference를 권장하며, 발표 글은 민감하거나 규제가 강한 데이터 요구사항을 가진 조직을 위해 self-hosting option도 제공한다고 밝힌다.
| 근거 | 확인되는 내용 | 해석 |
|---|---|---|
| Mistral 발표 글 | 74% win rate over OCR 2, $2/1k pages, Batch $1/1k pages, Playground 제공 | OCR 3의 제품 포지셔닝과 headline 성능 주장 |
| OCR 3 모델 페이지 | mistral-ocr-2512, Premier v25.12, OCR/annotation/BBox/Document QnA 표면 |
단순 OCR API가 아니라 Document AI stack 일부 |
| OCR processor 문서 | Markdown, table formatting, header/footer, confidence score, image/table placeholders | 후속 파이프라인이 소비할 구조화 page object 제공 |
| OCR API reference | /v1/ocr, document/image input, annotation formats, page selection |
대량 처리·부분 처리·schema 기반 추출을 위한 API 설계 |
| Document AI Playground | drag-and-drop UI로 clean text 또는 structured JSON 생성 | 개발자 API와 비개발자 검수/실험 표면을 함께 제공 |
실무 관점에서의 해석
내가 보기에 Mistral OCR 3의 핵심은 OCR 시장의 정확도 경쟁보다, 문서 전처리의 API 경계가 어디까지 올라오는가에 있다.
예전에는 OCR이 문자열을 내보내고, 표 복원·스키마 추출·RAG용 Markdown 정리는 별도 후처리 계층이 담당했다.
OCR 3는 이 경계를 모델/API 쪽으로 끌어올린다.
Markdown과 HTML table, image bbox, confidence score, JSON/schema annotation이 한 endpoint 주변에 모이면, 문서 파이프라인은 훨씬 단순해질 수 있다.
이 방향은 RAG와 에이전트 시스템에 특히 중요하다.
에이전트가 문서를 읽을 때 필요한 것은 “모든 글자를 하나의 긴 문자열로 붙인 결과”가 아니다.
어느 페이지에 어떤 표가 있고, 표의 헤더가 어떻게 계층화돼 있으며, 이미지와 본문이 어떤 관계인지, 추출한 필드의 신뢰도가 어느 정도인지가 필요하다.
OCR 3의 설계는 문서를 LLM에게 그냥 던지는 대신, 문서의 구조와 근거를 보존한 중간 표현을 만들려는 쪽에 가깝다.
가격 구조도 실무적으로 의미가 있다.
1,000페이지당 2달러, Batch 기준 1달러라는 숫자는 대량 문서 변환을 상시 워크로드로 계산하게 만든다.
여기에 self-hosting option이 붙으면 금융, 법무, 정부, 의료처럼 문서 반출이 어려운 조직도 검토할 여지가 생긴다.
물론 self-hosting은 공개 클릭 한 번 배포가 아니라 Mistral과의 별도 협의가 필요한 엔터프라이즈 표면으로 봐야 한다.
동시에 조심할 부분도 있다.
Mistral이 공개한 성능 수치는 강하지만, benchmark 세부 데이터와 ground truth는 공개 리더보드 형태가 아니다.
또한 “state-of-the-art”라는 표현은 OCR 3가 모든 문서 유형에서 곧바로 최선이라는 뜻이 아니라, Mistral이 정의한 고객 기반 내부 benchmark에서의 결과로 읽어야 한다.
실제 도입에서는 자신이 가진 문서군으로 page-level accuracy, table reconstruction quality, field-level extraction error, confidence calibration, human review cost를 따로 측정해야 한다.
그럼에도 OCR 3는 문서 AI 팀에게 분명한 신호를 준다.
이제 OCR은 더 이상 이미지-to-text 유틸리티가 아니라, 기업의 비정형 문서를 검색, 추출, 검증, 에이전트 실행으로 넘기는 문서 지식화 인프라가 되고 있다.
Mistral OCR 3의 진짜 경쟁력은 한 줄 성능 수치보다, 이 인프라 계층을 모델·API·UI·배치·자가호스팅 표면까지 한 제품군 안에 묶으려는 점에 있다.