오픈 웨이트 코딩 모델 경쟁에서 다음 흥미로운 지점은 단순히 “벤치마크 점수가 높다”가 아니다.
실제 에이전트 런타임 안에서 파일을 읽고, 수정하고, 테스트를 실행하고, 그 결과를 다시 반영하는 도구 사용 분포를 얼마나 잘 따라가느냐가 점점 중요해지고 있다.
lordx64/Qwable-v1은 이 문제를 정면으로 건드리는 커뮤니티 모델이다.
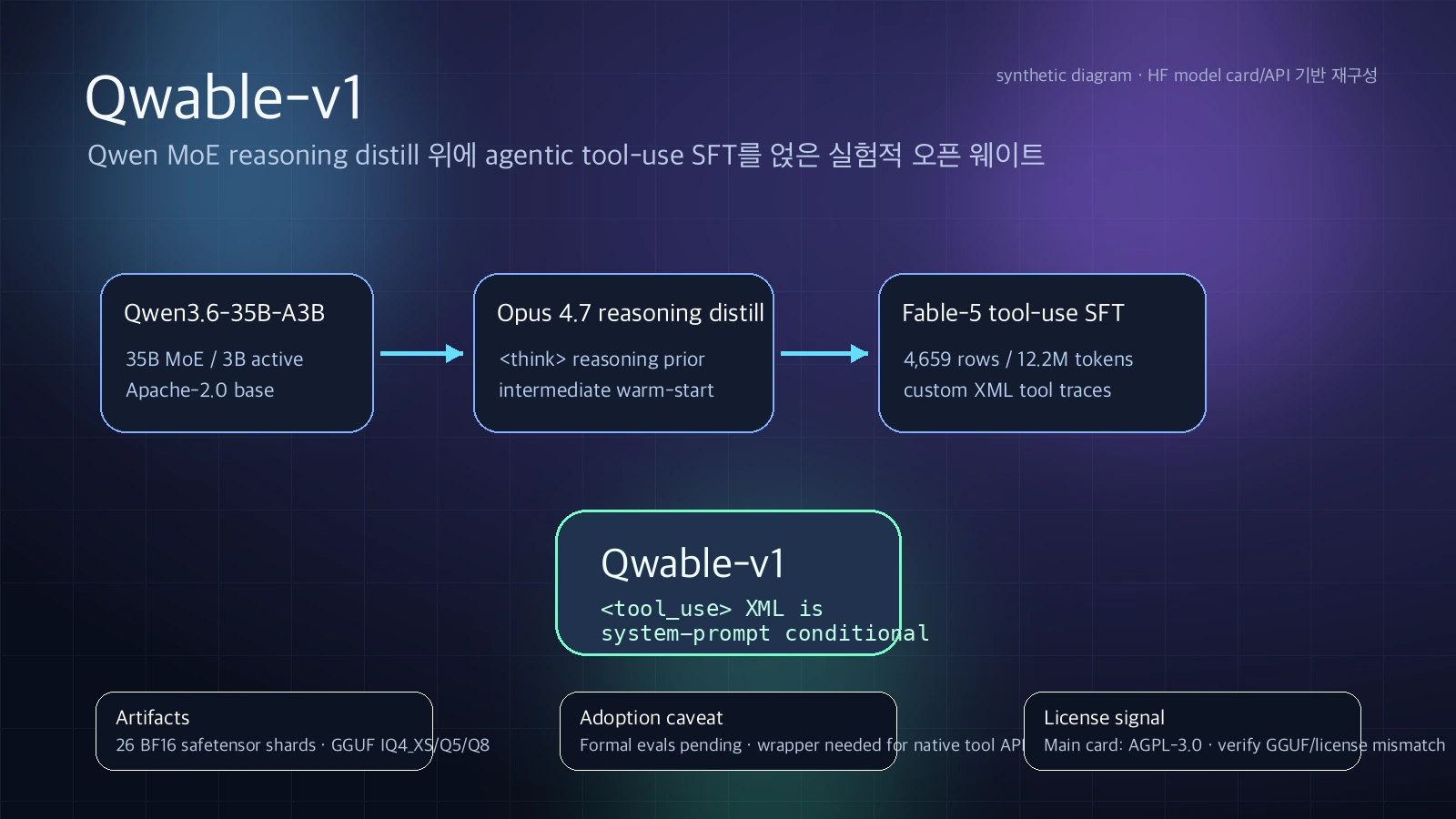
Hugging Face 모델 카드 기준으로 Qwable-v1은 Qwen3.6-35B-A3B 계열의 reasoning distill 위에 Claude Fable-5 스타일의 agentic tool-use trace를 한 번 더 SFT한 35B급 MoE 모델이다.
저자는 이를 “Qwen + Fable”로 설명한다.
즉 새로운 베이스 아키텍처를 만든다기보다, 기존 Qwen 계열 모델에 Claude-Code식 작업 궤적을 덧씌워 코딩 에이전트처럼 행동하는 오픈 웨이트를 만들려는 시도에 가깝다.
다만 이 모델은 아직 “성능이 검증된 공개 코딩 에이전트 백본”이라기보다 “흥미로운 post-training 실험”에 가깝다.
모델 카드가 공개한 학습 레시피와 배포 아티팩트는 꽤 구체적이지만, 정식 벤치마크 수치는 아직 pending 상태이고, 데이터 provenance와 라이선스 해석도 실사용 전에 따져봐야 한다.
무엇을 해결하려는가
Qwable-v1이 겨냥하는 문제는 “오픈 모델이 코딩 답안을 잘 쓰는가”보다 좁고 실전적이다.
코딩 에이전트에서는 모델이 한 번에 정답 코드를 출력하는 것보다, 파일 시스템과 shell, 테스트 runner, 검색 도구를 오가며 여러 턴에 걸쳐 작업을 완수하는 능력이 중요하다.
이때 모델은 단순 자연어 답변이 아니라, 런타임이 파싱할 수 있는 도구 호출 형식을 안정적으로 내야 한다.
기존 오픈 웨이트 모델도 코딩 답변은 잘할 수 있지만, Claude Code류의 작업 분포와 완전히 같지는 않다.
Qwable-v1의 아이디어는 여기에 있다.
순수 reasoning 능력은 이미 Qwen3.6-35B-A3B의 Claude Opus 4.7 reasoning distill에서 가져오고, 그 위에 Fable-5 trace 기반 SFT를 더해 <tool_use> XML을 내는 agentic 행동을 학습시키는 것이다.
흥미로운 점은 모델 카드가 이 범위를 꽤 솔직하게 제한한다는 것이다.
저자는 Qwable-v1이 pure reasoning benchmark에서 중간 베이스를 이길 것으로 보지 않는다.
새로 추가된 축은 “더 똑똑한 수학 모델”이 아니라, agent system prompt가 있을 때 도구 호출을 더 agentic하게 내는 행동이다.
핵심 아이디어 / 구조 / 동작 방식
모델 카드가 설명하는 lineage는 세 단계다.
Qwen3.6-35B-A3B
→ Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled
→ Qwable-v1
Hugging Face API 기준 Qwable-v1은 qwen3_5_moe 계열 Qwen3_5MoeForConditionalGeneration 아키텍처로 등록돼 있고, safetensors 메타데이터는 BF16 파라미터 35,951,822,704개를 보고한다.
모델 카드의 설명은 이를 35B total / 3B active MoE로 정리한다.
저장소에는 26개 safetensor shard, config.json, tokenizer.json, chat_template.jinja가 올라와 있고, Hub API의 pipeline_tag는 text-generation이다.
학습 레시피도 비교적 자세하다.
카드에 따르면 SFT 데이터셋은 lordx64/agentic-distill-fable-5-sft이며, 4,659 rows, 약 12.2M Qwen tokens 규모다.
Unsloth FastLanguageModel과 TRL SFTTrainer를 사용했고, LoRA는 attention projection(q_proj, k_proj, v_proj, o_proj)에 r=16, alpha=16으로 적용됐다. sequence length는 4096, epoch는 2, effective batch size는 16으로 적혀 있다.
핵심은 tool-use 포맷이다.
Qwable-v1의 Fable-5 SFT 데이터는 Qwen native <tool_call> JSON 포맷이 아니라, 다음과 같은 custom XML envelope를 사용한다.
<tool_use name="Read" id="toolu_01...">
{
"file_path": "/tmp/server.py"
}
</tool_use>
모델 카드의 smoke check에 따르면 이 포맷은 system-prompt-conditional이다.
일반 프롬프트에서는 모델이 markdown 코드 블록이나 설명형 답변으로 돌아가고, agent system prompt가 <tool_use> XML을 요구하거나 이전 턴에 <tool_result>가 주어지면 XML tool call을 이어간다.
따라서 Qwable-v1을 그냥 chat model처럼 부르는 것과, tool registry를 가진 agent harness 안에 넣는 것은 전혀 다른 사용법이다.
| 축 | 공개 자료에서 확인되는 내용 | 해석 |
|---|---|---|
| 베이스 | Qwen3.6-35B-A3B 계열 reasoning distill | pure reasoning은 중간 베이스의 성격을 많이 유지 |
| 추가 SFT | Fable-5 agentic trace 기반 4,659 rows / 약 12.2M tokens | 범용 코딩 지식보다 도구 사용 분포를 주입하려는 목적 |
| 모델 크기 | API 기준 35.95B BF16 params, 카드 기준 35B total / 3B active MoE | self-host 가능한 대형 MoE지만 full bf16은 여전히 서버급 |
| 도구 포맷 | custom <tool_use> / <tool_result> XML |
native Qwen/vLLM tool calling과 바로 호환되지는 않음 |
| 배포 아티팩트 | full safetensors + GGUF quants | 서버 추론과 로컬 추론을 모두 염두에 둔 패키징 |
공개된 근거에서 확인되는 점
가장 긍정적인 신호는 release packaging이다.
메인 모델 저장소는 공개 상태이고 gated가 아니며, 확인 시점의 Hub API는 downloads 10, likes 43을 보고했다.
별도 Qwable-v1-GGUF 저장소도 공개돼 있고, IQ4_XS, Q4_K_M, Q5_K_M, Q8_0 파일을 제공한다.
GGUF 카드 기준으로 IQ4_XS는 약 18.9GB로 24GB급 consumer GPU, Q5_K_M은 약 24.7GB로 32–48GB 워크스테이션, Q8_0은 약 36.9GB로 재현성 확인용에 가깝게 포지셔닝된다.
또 하나 확인할 수 있는 점은 학습 데이터의 성격이다. agentic-distill-fable-5-sft 데이터셋 카드와 API는 AGPL-3.0 license, text-generation task, parquet format, 1K<n<10K 규모 태그를 노출한다.
모델 카드 설명에 따르면 4,659 rows 중 3,793 rows, 즉 81%가 tool call로 끝나고, 나머지 866 rows는 pure text response다.
이는 Qwable-v1이 왜 일반 assistant 모델보다 agentic coding harness 안에서의 행동을 목표로 하는지 잘 보여 준다.
반대로 성능 근거는 아직 얇다.
모델 카드의 Evaluation 섹션은 GSM8K, MMLU-Pro, GPQA Diamond, MATH-500, AIME, HumanEval/MBPP, SWE-bench Lite 같은 항목을 나열하지만 점수는 모두 _pending_으로 남겨 둔다.
카드에 적힌 원칙도 “verified될 때까지 수치를 채우지 않는다”에 가깝다.
따라서 지금 Qwable-v1을 소개할 때는 “어떤 benchmark를 이겼다”가 아니라, “어떤 학습 분포와 도구 포맷을 공개했는가”를 중심으로 읽는 편이 안전하다.
출시 성숙도 측면의 작은 caveat도 있다.
모델 카드가 언급하는 adapter-only variant URL은 확인 시점에 public API 접근이 401로 막혔고, source repo로 연결된 github.com/lordx64/distillation도 GitHub API에서는 404를 반환했다.
메인 모델, GGUF, 데이터셋은 공개적으로 확인되지만, 학습 코드와 adapter 조합을 독립적으로 검토하려면 공개 상태가 더 명확해질 필요가 있다.
실무 관점에서의 해석
내가 보기엔 Qwable-v1의 가장 흥미로운 지점은 “오픈 웨이트 모델에 agent runtime behavior를 어떻게 이식할 것인가”라는 질문이다.
지금까지 많은 공개 코딩 모델은 HumanEval류 completion이나 SWE-bench류 repair 성능을 중심으로 설명됐다.
Qwable-v1은 다른 축을 보여 준다.
모델이 파일을 읽고, 편집하고, shell을 호출하는 trajectory를 학습하면, open model도 Claude Code 같은 harness 안에서 더 자연스럽게 행동할 수 있느냐는 실험이다.
하지만 이 모델을 바로 production coding agent의 기본값으로 삼기에는 확인할 것이 많다.
첫째, custom XML tool-use는 장점이자 통합 비용이다. regex parser로 처리하기는 쉽지만, vLLM이나 Qwen native tool calling으로 바로 연결하려면 wrapper가 필요하다.
둘째, 데이터 분포가 좁다.
모델 카드가 스스로 말하듯 web/game development, Three.js, Express, transformer training script 같은 특정 세션에 편향돼 있다면 DevOps, 보안, 데이터 엔지니어링, 대규모 monorepo 유지보수에서 같은 안정성이 나올지는 별도 검증이 필요하다.
셋째, 라이선스 해석이 중요하다.
메인 모델과 SFT 데이터셋은 AGPL-3.0으로 표시돼 있고, 모델 카드는 네트워크 서비스 사용 시 AGPL §13 source disclosure 의무를 언급한다.
반면 GGUF 저장소의 cardData는 Apache-2.0을 표시한다.
베이스 모델이 Apache-2.0이라도 Fable-5 데이터에서 온 AGPL 표시가 메인 릴리스에 붙어 있으므로, 실사용자는 GGUF 저장소의 license tag만 보고 판단하지 말고 메인 모델/데이터셋의 조건을 함께 검토해야 한다.
정리하면 Qwable-v1은 “검증된 최고 성능 공개 코딩 모델”이라기보다, agentic trace distillation이 오픈 모델 생태계에서 어떤 형태로 패키징될 수 있는지 보여 주는 사례다.
정식 benchmark가 채워지고, adapter/source repo 접근성이 정리되고, native tool API 변환 layer가 안정화된다면 꽤 흥미로운 실험 플랫폼이 될 수 있다.
지금 단계에서는 모델 하나의 점수보다, 공개 웨이트·GGUF·데이터셋·도구 호출 포맷을 함께 내놓았다는 release shape 자체가 더 중요한 신호다.