에이전트 성능을 이야기할 때 우리는 자주 모델 이름부터 본다.
Sonnet인지, GPT인지, Qwen인지, 컨텍스트 창이 얼마나 큰지, tool calling이 얼마나 안정적인지 같은 질문이다.
하지만 실제 장기 실행 에이전트의 행동은 모델 하나로 결정되지 않는다.
어떤 system prompt를 받는지, 어떤 tool을 어떤 권한으로 호출하는지, 실패한 tool call을 어떻게 복구하는지, 어떤 memory와 trace를 남기는지, verifier가 무엇을 성공으로 인정하는지가 함께 성능을 만든다.
HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry는 이 주변 실행층을 정면으로 다룬다.
논문의 메시지는 단순하다.
에이전트 진보는 모델 스케일링만의 문제가 아니라, 모델을 감싸는 runtime harness를 어떻게 조립하고, 관찰하고, 진화시키는가의 문제이기도 하다.
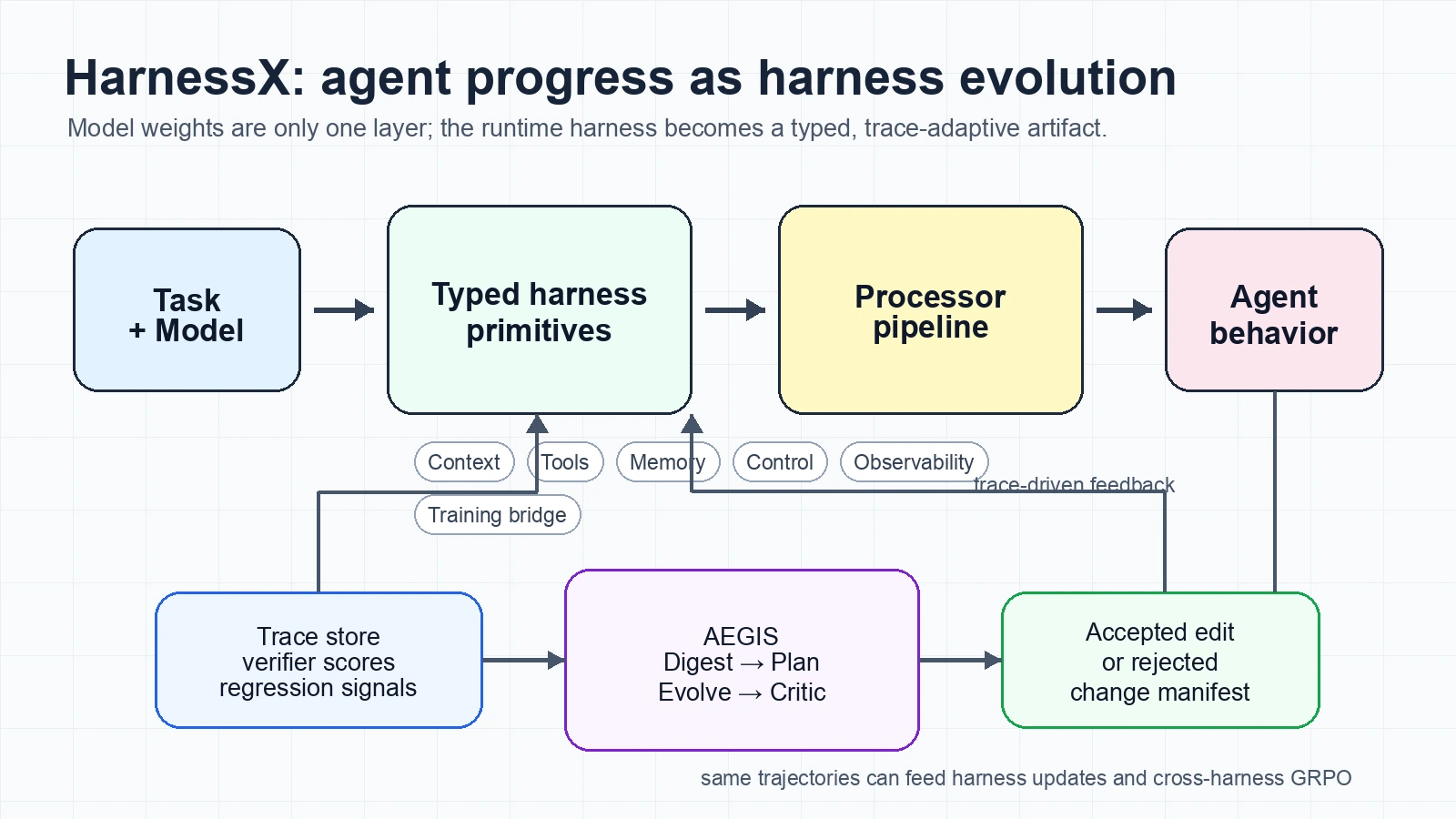
논문은 HarnessX를 세 가지 층으로 제안한다.
첫째, prompt·tool·memory·control flow·observability를 typed primitive로 나누어 하네스를 조립한다.
둘째, AEGIS라는 trace-driven multi-agent evolution engine으로 실행 trace와 verifier score를 읽고 하네스를 고친다.
셋째, 같은 trajectory를 harness update와 model RL training signal로 함께 써서 하네스와 모델을 같이 움직인다.
무엇을 해결하려는가
논문이 보는 기존 에이전트 하네스의 문제는 세 가지다.
첫째, 하네스는 여전히 손으로 만든 정적 scaffold에 가깝다.
새 모델, 새 benchmark, 새 tool set이 들어오면 사람이 prompt와 tool wrapper와 retry rule을 다시 고친다.
실패 trace가 쌓여도 그것이 체계적으로 다음 하네스 개선으로 들어가지 않는다.
둘째, 구조가 얽혀 있다. prompt template, tool wrapper, retry policy, memory policy, tracing이 같은 코드 경로에 섞이면 작은 수정이 엉뚱한 regression을 만든다.
재사용도 composition이라기보다 copy-paste가 된다.
셋째, 하네스 개선과 모델 학습이 분리돼 있다.
하네스 evolution 과정에서 나온 trajectory는 실패 분석에는 쓰이지만, 모델이 그 trajectory에서 학습하도록 연결되지는 않는다.
반대로 모델이 좋아져도 하네스가 그 능력을 끌어낼 context, tool, control flow를 제공하지 않으면 개선이 표면화되지 않는다.
HarnessX는 이 문제를 “하네스를 first-class object로 만들자”는 방향으로 푼다.
논문 정의에서 하네스는 모델 설정과 하네스 설정의 쌍이다.
H = (M, C)
여기서 M은 main, judge, evaluator 같은 역할에 어떤 모델을 쓸지와 fallback policy를 기록한다.C는 모델 정체성과 독립적인 행동 설정이다.
하네스 설정 C는 hook별 processor 목록 P와 tool registry, tracer, workspace, sandbox provider, plugin list 같은 shared slot resource S로 나뉜다.
즉 HarnessX가 하려는 일은 “좋은 prompt를 더 붙이자”가 아니다.
에이전트 runtime을 다음처럼 분해 가능한 객체로 만드는 것이다.
| 하네스 축 | HarnessX에서의 의미 | 실무적으로 읽는 법 |
|---|---|---|
| Context assembly | 모델 앞에 어떤 task/history/evidence를 놓을지 | 검색·요약·압축·history editing이 성능을 좌우한다 |
| Memory management | step/session을 넘어 무엇을 보존할지 | 장기 작업에서는 기억이 prompt보다 더 큰 상태가 된다 |
| Tool ecosystem | 어떤 tool을 어떤 schema와 권한으로 열지 | tool list 자체가 policy surface다 |
| Execution environment | side effect가 어디에서 발생하는지 | sandbox, workspace, filesystem, network boundary를 분리해야 한다 |
| Evaluation / reward | 무엇을 성공으로 볼지 | weak verifier는 reward hacking을 부른다 |
| Control / safety | looping, overspending, drift를 어떻게 막을지 | stop rule, retry rule, human gate가 하네스의 일부다 |
| Observability | model call, tool call, result, timing을 어떻게 기록할지 | trace 없이는 실패를 진화시킬 수 없다 |
| Training bridge | trajectory를 model update로 어떻게 연결할지 | 하네스 개선 로그가 RL 데이터가 될 수 있다 |
AEGIS: 하네스 편집을 symbolic RL로 다룬다
HarnessX의 핵심 엔진은 AEGIS다.
논문은 하네스 evolution을 강화학습과 비슷한 구조로 본다.
단, 여기서 state는 neural activation이 아니라 현재 harness configuration과 trace store이고, action은 typed harness edit이며, feedback은 execution trace와 verifier score다.
이 비유가 중요한 이유는 RL에서 보던 병리도 하네스 evolution에서 다시 나타나기 때문이다.
| RL 병리 | Harness evolution에서의 형태 | AEGIS가 노리는 방어 |
|---|---|---|
| Reward hacking | verifier 형식이나 평가 취약점을 이용해 점수만 올림 | trace 분석, critic, second-path cross-check |
| Catastrophic forgetting | 한 task cluster를 고치는 edit이 다른 cluster를 망침 | regression signal, variant isolation, per-edit gating |
| Under-exploration | prompt edit 같은 쉬운 영역만 반복하고 structural edit을 못 찾음 | Planner가 adaptation landscape를 만들고 edit neighborhood를 넓힘 |
AEGIS는 Digester, Planner, Evolver, Critic 네 단계를 돈다.
Digester는 raw trace를 task-level failure summary로 압축한다.
Planner는 어떤 task가 실패했고 어떤 edit이 이미 시도됐으며 어떤 component가 의심되는지 adaptation landscape를 만든다.
Evolver는 type contract를 지키는 candidate harness edit과 change manifest를 만든다.
Critic과 deterministic gate는 후보가 실제로 ship될 수 있는지 판단한다.
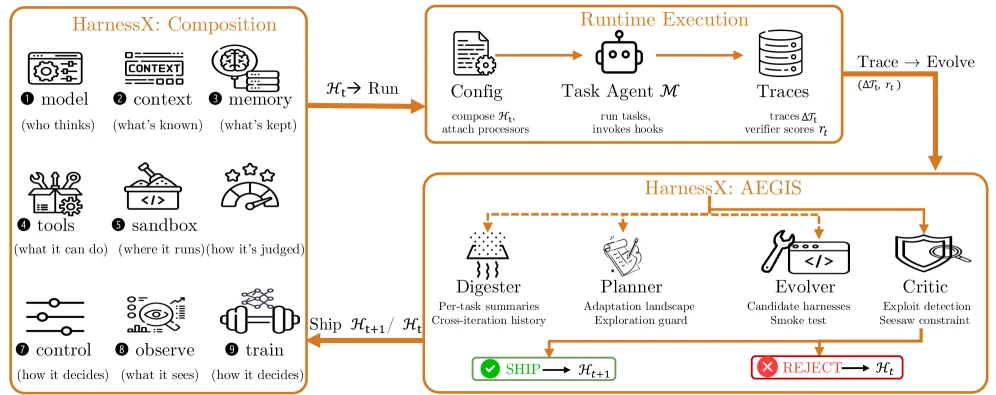
여기서 좋은 설계는 change manifest다.
후보 edit은 단지 “prompt를 개선했다”가 아니라, 어떤 파일과 component를 바꾸는지, 어떤 task가 좋아질 것으로 예측하는지, 그 edit이 실제로 발동했다면 다음 trace에서 어떤 attribution signature가 보여야 하는지를 남긴다.
이는 하네스 변경을 감이 아니라 falsifiable state transition으로 다루려는 장치다.
실험 결과: 평균 +14.5%, 최대 +44.0%
논문은 HarnessX를 다섯 benchmark와 세 task-agent family에서 평가한다. benchmark는 GAIA, ALFWorld, WebShop, τ³-Bench, SWE-bench Verified이고, task agent는 Claude Sonnet 4.6, GPT-5.4, Qwen3.5-9B다. meta-agent는 기본적으로 Claude Opus 4.6을 사용해 AEGIS loop를 돌린다.
headline은 강하다. pass@2 success rate 기준으로 15개 model-benchmark configuration 중 14개가 개선됐고, 평균 절대 개선은 +14.5%다.
가장 큰 개선은 ALFWorld에서 Qwen3.5-9B가 53.0%에서 97.0%로 오른 +44.0%다.
| Benchmark | 대표 결과 | 해석 |
|---|---|---|
| ALFWorld | Qwen3.5-9B 53.0 → 97.0, +44.0 | baseline이 약한 embodied planning에서 하네스 개선 폭이 가장 큼 |
| WebShop | GPT-5.4 55.0 → 73.0, +18.0 | web interaction에서는 tool/context/control edit이 안정적으로 작동 |
| GAIA | Qwen3.5-9B 20.3 → 37.4, +17.1 / GPT-5.4 73.8 → 73.8, 0.0 | heterogeneous task에서는 single global harness가 충돌할 수 있음 |
| SWE-bench Verified | GPT-5.4 45.5 → 63.6, +18.2 / Qwen3.5-9B 23.6 → 41.8, +18.2 | software engineering에서도 fixed model 위의 harness edit이 큰 축이 됨 |
| τ³-Bench Avg. | GPT-5.4 76.2 → 90.7, +14.5 | multi-turn dialogue compliance에도 효과가 있지만 near-ceiling baseline에서는 이득이 작음 |
흥미로운 패턴은 inverse scaling이다.
강한 모델보다 약한 모델이 더 큰 이득을 받는 경우가 많다.
논문은 ALFWorld에서 Qwen3.5-9B가 +44.0%를 얻는 반면 Sonnet 4.6은 +11.2%를 얻는다고 보고한다.
이는 약한 모델일수록 prompt, tool selection, decomposition, memory, recovery policy 같은 하네스 차원의 보조 장치가 더 많은 행동 gap을 메울 수 있다는 신호로 읽힌다.
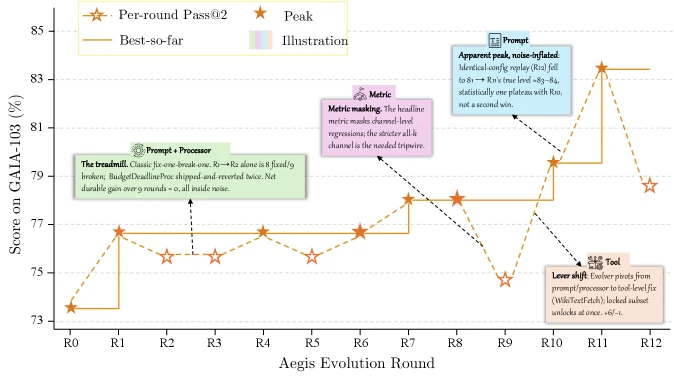
다만 GAIA의 GPT-5.4 결과는 일부러 자세히 봐야 한다. main table에서는 73.8%에서 73.8%로 개선이 없다.
논문은 이것을 single global harness가 heterogeneous task cluster를 모두 만족시키지 못한 사례로 설명한다.
실제로 variant isolation ablation에서는 GAIA GPT-5.4가 87.4%까지 올라 +13.6%를 만든다.
즉 “하네스 evolution이 안 된다”가 아니라, 한 개 global harness에 모든 task를 몰아넣으면 cluster 간 regression을 막기 어렵다는 해석이 더 맞다.
모델도 같이 움직이면 +4.7%가 더 나온다
HarnessX의 두 번째 축은 harness-model co-evolution이다.
하네스만 고치면 언젠가 scaffolding ceiling에 부딪힌다.
하네스가 올바른 tool과 context를 열어 줘도 모델이 그 구조를 제대로 활용할 reasoning capacity가 없으면 더 이상 못 오른다.
반대로 모델만 학습하면 training-signal ceiling에 부딪힌다.
하네스가 새 능력을 끌어낼 task representation과 tool path를 제공하지 않으면 학습된 능력이 표면화되지 않는다.
그래서 논문은 같은 replay buffer를 두 방향으로 쓴다.
각 round에서 task batch를 실행하고 verifier가 trace에 reward를 붙인다.
이 trace는 AEGIS의 harness evolution evidence가 되고, 동시에 cross-harness GRPO의 model training data가 된다.
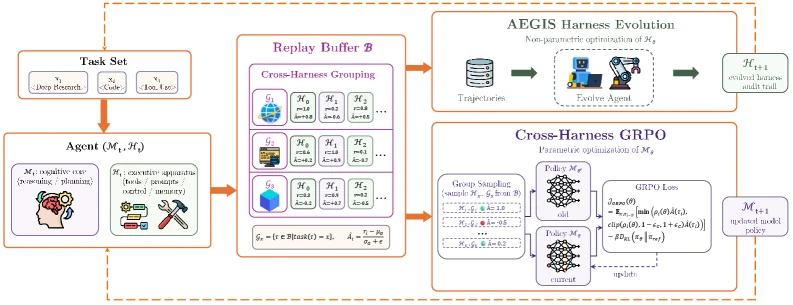
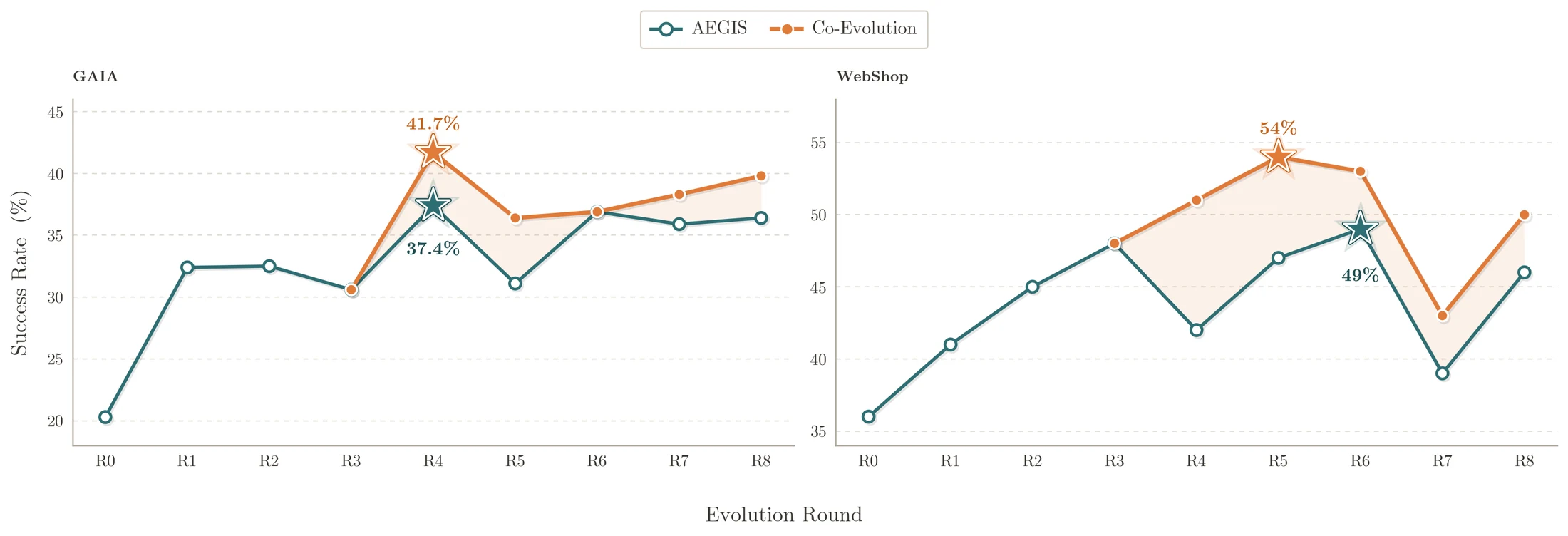
Qwen3.5-9B 기준으로 co-evolution은 harness-only보다 GAIA에서 37.4% → 41.7% (+4.3%), WebShop에서 49.0% → 54.0% (+5.0%)를 만든다.
평균 추가 이득은 +4.7%다.
논문은 두 곡선이 R4 이후 벌어지며, co-evolution이 끝까지 harness-only 이상을 유지한다고 보고한다.
실무 관점에서의 해석
내가 보기에 HarnessX의 가장 중요한 문장은 “typed primitives”보다 “language-model subagents explore, hypothesize, and propose; typed structure and deterministic gates determine what ships”에 가깝다.
모델은 후보를 만들 수 있지만, 무엇이 실제 runtime에 들어갈지는 하네스 타입, smoke test, verifier, regression gate, change manifest가 결정해야 한다는 뜻이다.
이 관점은 agent platform을 만드는 팀에게 바로 적용된다.
| 설계 질문 | HarnessX가 주는 힌트 |
|---|---|
| 실패 trace를 어떻게 저장할 것인가 | raw log만 모으지 말고 outcome, failure category, implicated component, evidence excerpt로 요약해야 한다 |
| 하네스 변경을 어떻게 리뷰할 것인가 | prompt diff만 보지 말고 predicted impact와 attribution signature를 같이 남겨야 한다 |
| regression을 어떻게 막을 것인가 | single global harness보다 task cluster별 variant isolation과 routing이 필요할 수 있다 |
| 비용은 어떻게 해석할 것인가 | evolution은 upfront token cost가 크지만, 배포 시점에는 static artifact가 될 수 있다 |
| 모델 학습과 어떻게 연결할 것인가 | 같은 trajectory를 harness update evidence와 model RL data로 동시에 쓰는 replay buffer가 핵심이다 |
특히 variant isolation은 실무적으로 중요하다.
한 조직 안에서도 coding task, retrieval task, browser task, spreadsheet task는 서로 다른 실패 cluster를 갖는다.
하나의 system prompt나 tool policy를 모든 task에 강제로 적용하면 어떤 cluster는 좋아지고 다른 cluster는 나빠질 수 있다.
HarnessX가 GAIA GPT-5.4에서 global strategy의 stagnation과 variant isolation의 회복을 보여준 것은 이 점에서 실용적인 경고다.
또한 cost-performance tradeoff도 단순하지 않다.
논문은 GAIA variant isolation ablation에서 107.8M token을 쓰지만 per-task token consumption이 약 25% 줄어 upfront cost가 약 1,300 invocation 안에 amortize될 수 있다고 설명한다.
반대로 ALFWorld에서는 per-task cost가 약 60% 늘어난다.
이 경우 return은 비용 절감이 아니라 정확도 상승이다.
즉 “하네스를 진화시키면 싸진다”가 아니라, 어떤 benchmark에서는 비용을 줄이고 어떤 benchmark에서는 더 많은 scaffold를 써서 성공률을 산다는 식으로 읽어야 한다.
한계와 주의점
이 논문은 강한 주장만큼 한계도 분명하다.
첫째, reported gain은 evolution에 사용한 같은 task set 위에서 측정된다.
논문도 held-out evaluation이 없고, peak accuracy reporting에는 selection bias와 overfitting 가능성이 있다고 밝힌다.
따라서 +14.5%를 “새로운 unseen task에서도 그대로 오른다”로 읽으면 안 된다.
둘째, AEGIS meta-agent는 Claude Opus 4.6 같은 closed-source frontier급 모델이다. trace analysis, multi-file code generation, multi-step planning을 안정적으로 수행하는 meta-agent가 필요하다. open-weight model을 meta-agent로 썼을 때 같은 결과가 나는지는 아직 검증되지 않았다.
셋째, code release는 아직 공개 상태가 아니다. arXiv abstract와 HTML은 “complete codebase will be open-sourced in a future release”라고 명시한다.
별도 공식 GitHub repository나 project page는 현재 확인되지 않는다.
그래서 이 글은 runnable OSS 도구 리뷰가 아니라, 공개 논문 본문과 arXiv HTML figure/table을 기반으로 한 시스템 제안 분석이다.
넷째, action space는 discrete, text-based agent에 한정된다. robotics 같은 continuous control 환경으로 확장되는지는 검증되지 않았다.
SWE-bench Verified도 55-task subsample이고, τ³-Bench도 retail, airline, telecom 세 domain만 본다.
그럼에도 HarnessX가 던지는 질문은 유효하다.
앞으로 agent 성능 개선은 “다음 모델이 나오면 해결된다”와 “더 긴 prompt를 쓰면 된다” 사이의 넓은 공간에서 일어날 가능성이 크다.
그 공간은 tool interface, memory policy, verifier, trace store, permission boundary, evaluator-owned feedback, model training bridge 같은 하네스 설계의 공간이다.
정리하면 HarnessX는 agent harness를 더 이상 보조 코드가 아니라, 조립 가능하고, 관찰 가능하고, 검증 가능하고, 모델과 함께 진화할 수 있는 runtime artifact로 본다.
이 관점은 최근 Self-Harness, Evoflux, Code as Agent Harness 같은 흐름과도 이어진다.
모델은 agent의 cognitive core지만, 하네스는 그 core가 세계를 보고 행동하고 실패에서 배우는 executive apparatus다.
장기 실행 에이전트의 신뢰성과 성능은 결국 이 두 층을 함께 설계할 때 나온다.