작은 언어모델은 보통 두 가지 이유로 주목받는다.
비용이 낮고, 배포가 쉽다.
하지만 어려운 수학, 경쟁 프로그래밍, 장기 추론처럼 여러 단계의 탐색과 검증이 필요한 영역에서는 여전히 “진짜 성능은 큰 모델에서 나온다”는 인식이 강하다.
WeiboAI의 VibeThinker-3B는 이 인식을 정면으로 건드리는 기술 보고서다.
모델 자체는 3B dense model이고, 기반은 Qwen2.5-Coder-3B다.
새 거대 아키텍처를 만든 것이 아니라, VibeThinker-1.5B에서 제안한 Spectrum-to-Signal Principle, SSP를 3B 스케일에서 더 체계적인 post-training pipeline으로 확장한다.
핵심 주장은 과감하다.
모든 능력이 파라미터 수에 같은 방식으로 의존하지는 않으며, 수학·코딩처럼 답을 비교적 명확히 검증할 수 있는 추론 능력은 작은 모델 안에도 상당히 압축될 수 있다는 것이다.
반대로 개방형 지식, 롱테일 사실, 범용 대화 능력은 여전히 넓은 파라미터 커버리지를 요구한다.
이 글에서 중요한 해석도 바로 이 지점이다.
VibeThinker-3B는 “3B가 모든 대형 모델을 대체한다”는 이야기가 아니라, 검증 가능한 추론이라는 좁지만 중요한 축에서는 작은 모델의 상한이 생각보다 높을 수 있다는 실험이다.
무엇을 해결하려는가
VibeThinker-3B가 겨냥하는 문제는 “작은 모델도 reasoning을 할 수 있는가”보다 조금 더 구체적이다.
이미 Qwen, DeepSeek distillation, VibeThinker-1.5B 같은 공개 모델은 작은 모델에서도 chain-of-thought 성능이 일정 수준 나타날 수 있음을 보여 줬다.
이번 보고서의 질문은 그 다음 단계다.
엄격히 3B인 dense model이, 수학·코딩처럼 정답 검증이 가능한 과제에서 프론티어 reasoning system의 성능대에 들어갈 수 있는가?
논문은 이를 위해 능력을 두 부류로 나눈다.
첫째는 verifiable reasoning처럼 답 검증, 제약 만족, 오류 수정, 탐색이 핵심인 parameter-dense capability다.
둘째는 넓은 세계 지식과 롱테일 시나리오를 커버해야 하는 parameter-expansive capability다.
VibeThinker-3B의 실험 결과는 이 구분을 뒷받침하는 사례로 제시된다.
수학·코딩 점수는 매우 높지만, GPQA-Diamond 같은 지식 집약 벤치마크에서는 대형 범용 모델과 격차가 남는다.
이 관점은 제품적으로도 중요하다.
온디바이스, 로컬, 저비용 서버 환경에서 작은 모델을 쓰려면 “모든 일을 조금씩 하는 범용 assistant”보다 “검증 가능한 좁은 일을 아주 잘하는 specialist”가 더 현실적일 수 있다.
VibeThinker-3B는 그런 specialist가 post-training으로 얼마나 멀리 갈 수 있는지를 보여 주는 사례다.
핵심 아이디어 / 구조 / 동작 방식
VibeThinker-3B의 학습 철학은 SSP, 즉 Spectrum-to-Signal이다.
SFT 단계에서는 하나의 정답 풀이만 모방하지 않고 다양한 유효 추론 궤적을 넓게 만든다.
이 넓은 해 공간이 “spectrum”이다.
그 다음 RL 단계에서는 검증 가능한 보상으로 올바른 궤적을 증폭한다.
이것이 “signal”이다.
공식 파이프라인은 크게 네 덩어리로 읽을 수 있다.
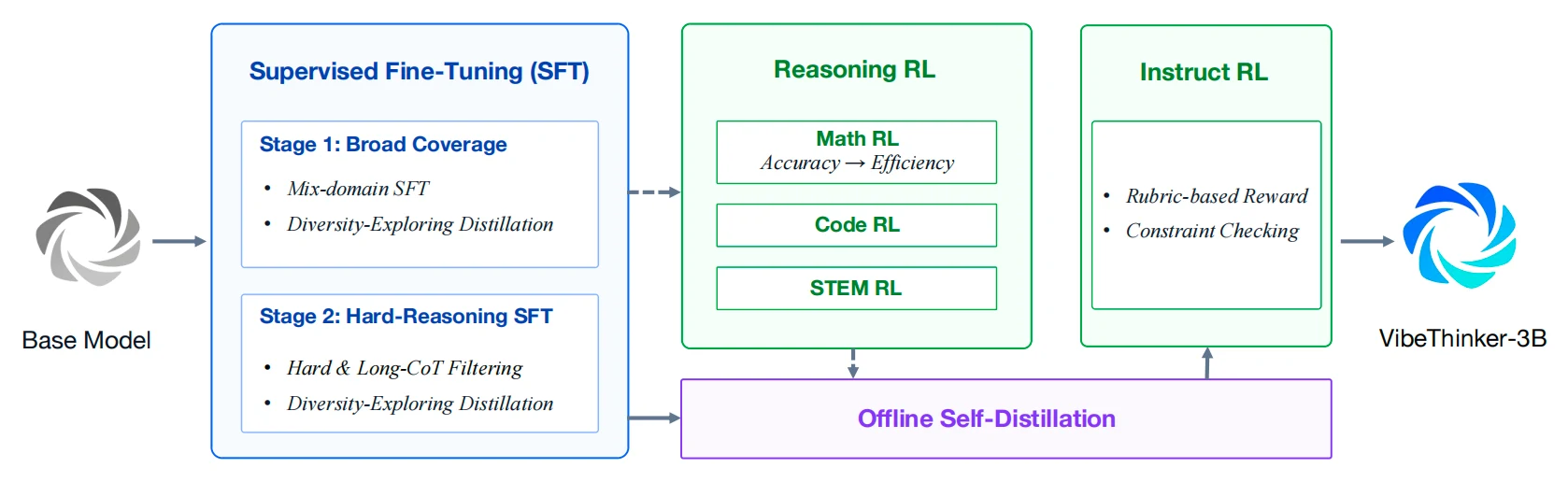
첫 번째는 커리큘럼 기반 2단계 SFT다.
Stage 1은 수학, 코드, STEM reasoning, 일반 대화, instruction following을 섞어 넓은 cold-start policy를 만든다.
Stage 2는 더 어렵고 긴 reasoning sample로 분포를 옮긴다.
보고서 기준으로 짧은 추론 궤적은 제거하고, VibeThinker-1.5B를 참조 모델로 8회 rollout을 돌려 쉬운 문제를 걸러내는 식으로 hard-reasoning subset을 만든다.
목적은 얕은 풀이보다 긴 논리 전개와 복잡한 제약 만족에 모델을 노출시키는 것이다.
두 번째는 다중 도메인 Reasoning RL이다.
알고리즘 backbone은 VibeThinker-1.5B의 MGPO, MaxEnt-Guided Policy Optimization을 유지한다.
핵심 아이디어는 너무 쉬운 문제나 너무 어려운 문제보다, 모델의 현재 경계에 걸쳐 있어 정답과 오답이 함께 나오는 문제에 학습 가중치를 주는 것이다.
RL은 Math → Code → STEM 순서로 이어지고, VibeThinker-3B에서는 처음부터 64K long-context window를 사용한다.
저자들은 high-truncation warmup이 오히려 긴 사고 능력을 약화시킬 수 있다고 보고했다.
세 번째는 Long2Short Math RL이다.
정확도만 올리면 모델이 장황한 추론을 계속 생성할 수 있다.
VibeThinker-3B는 정답 궤적끼리만 보상을 재분배해, 맞았지만 더 짧은 응답에 더 높은 보상을 준다.
중요한 점은 오답을 짧게 만드는 것이 아니라, 정확도를 유지한 상태에서 불필요한 토큰을 줄이는 것이다.
네 번째는 Offline Self-Distillation과 Instruct RL이다.
여러 RL 체크포인트에서 나온 고품질 궤적을 다시 학습 데이터로 통합하고, 마지막에는 rubric 기반 보상과 constraint checking으로 지시 준수 능력을 보강한다. reasoning 전용 모델이 되면서 사용자 지시를 무시하는 문제를 줄이려는 단계다.
공개된 근거에서 확인되는 점
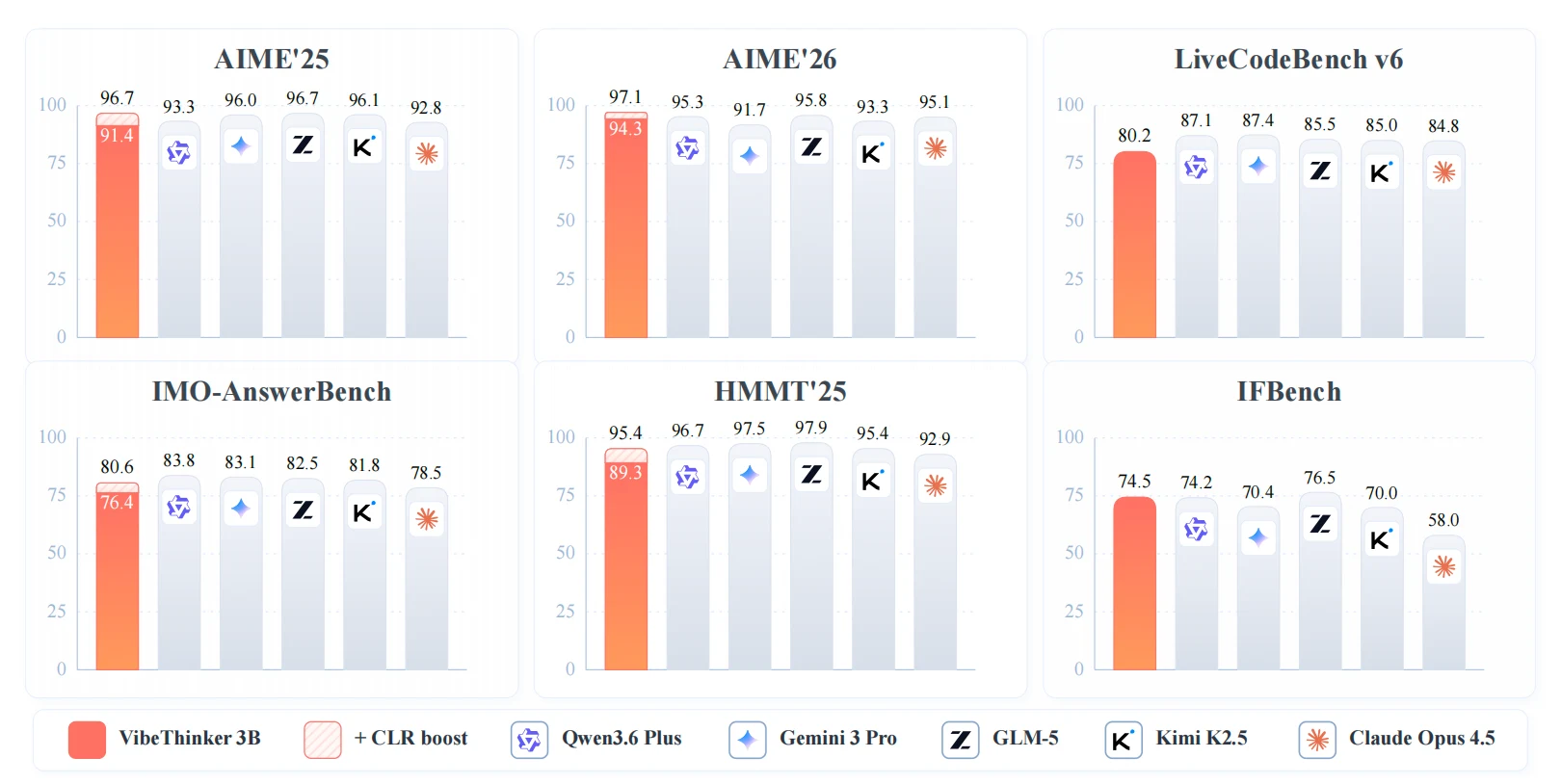
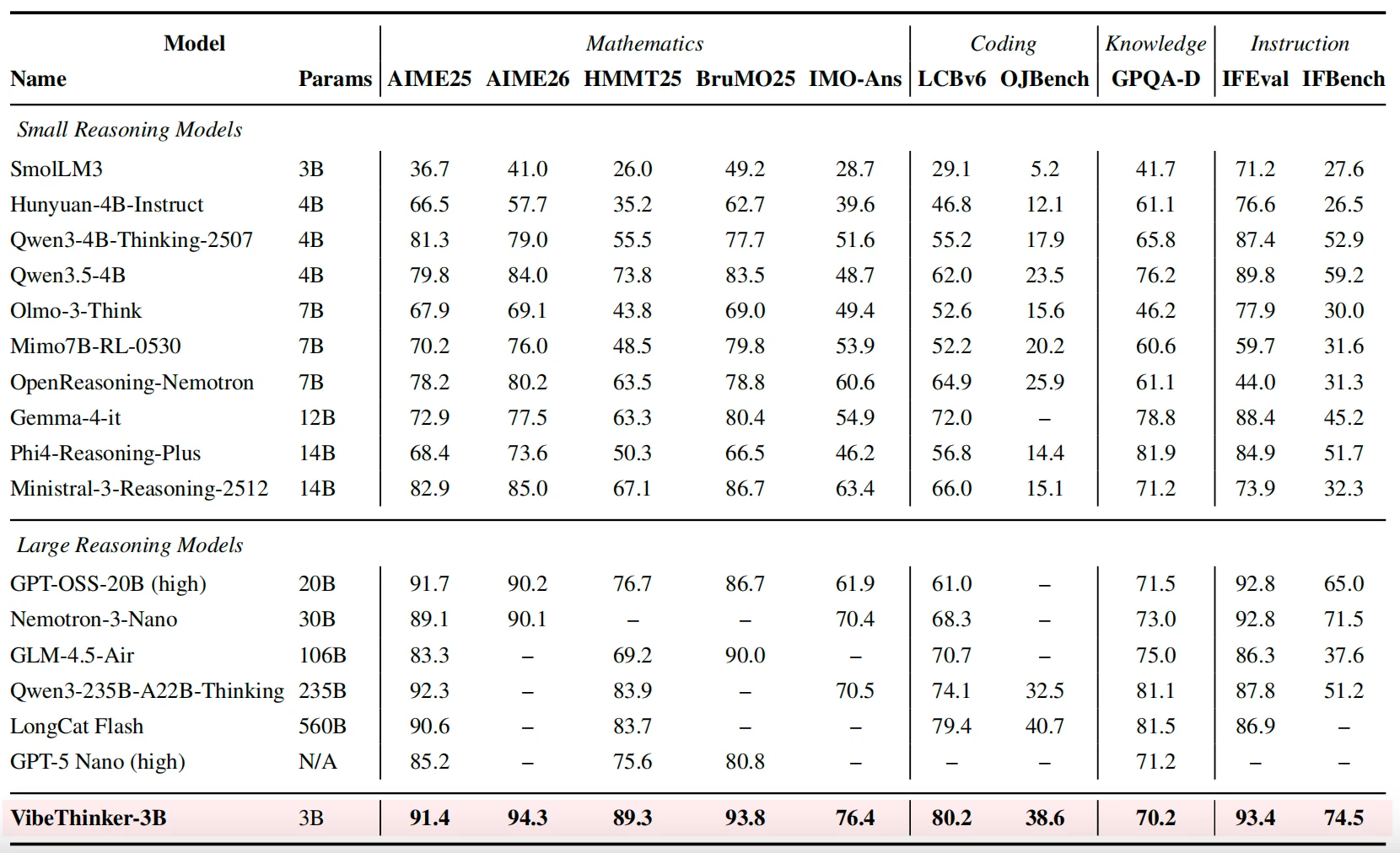
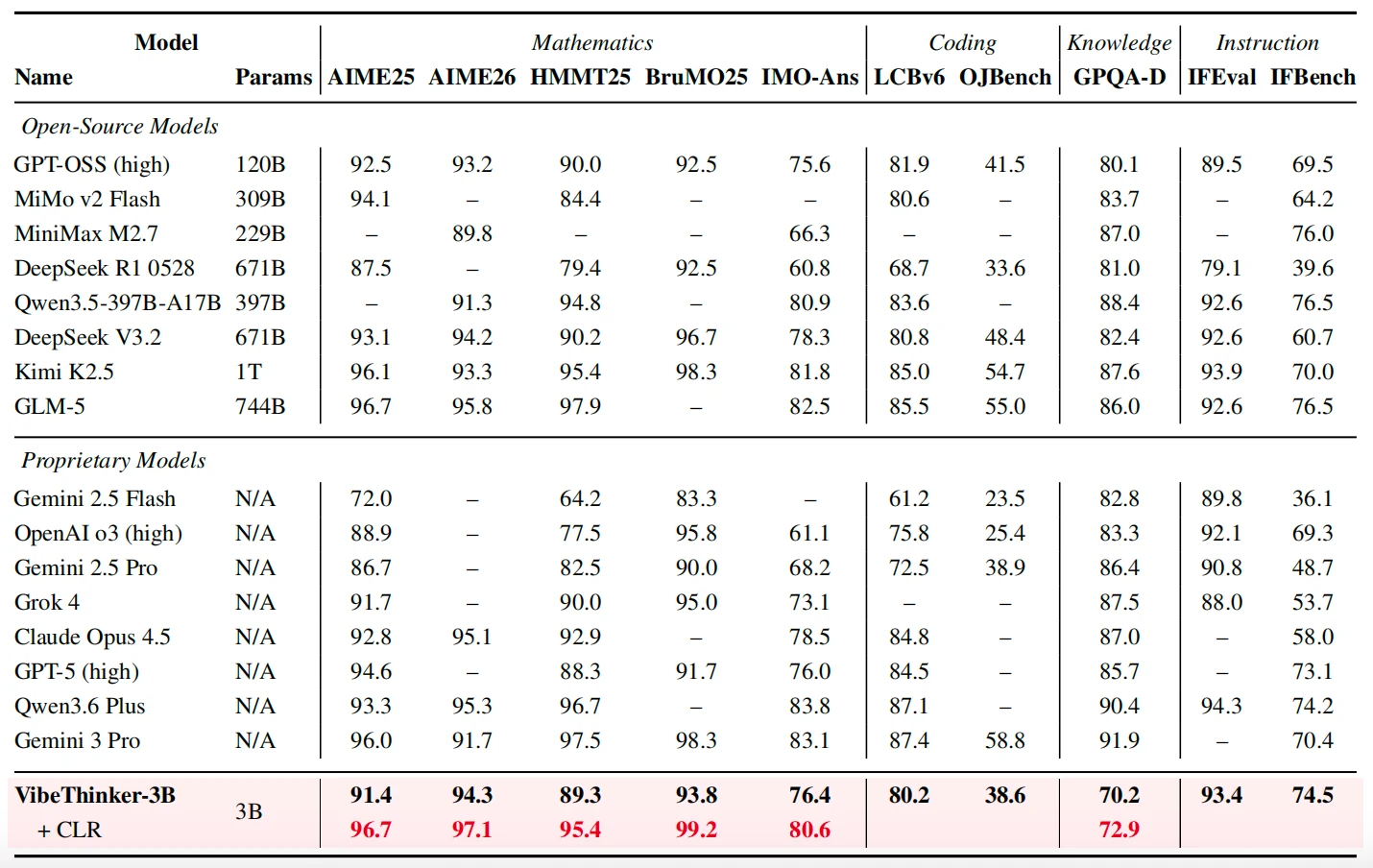
가장 눈에 띄는 수치는 core benchmark table이다.
논문 Table 1 기준 VibeThinker-3B는 AIME25 91.4, AIME26 94.3, HMMT25 89.3, BruMO25 93.8, IMO-AnswerBench 76.4, LiveCodeBench v6 80.2, OJBench 38.6, GPQA-D 70.2, IFEval 93.4, IFBench 74.5를 보고한다.
비교를 조금 좁히면 메시지가 선명해진다.
같은 표에서 Qwen3.5-4B는 AIME26 84.0, HMMT25 73.8, LCBv6 62.0이고, Ministral-3-Reasoning-2512 14B는 AIME26 85.0, HMMT25 67.1, LCBv6 66.0이다.
VibeThinker-3B는 이 small/mid-sized reasoning model 묶음에서는 거의 모든 핵심 reasoning 지표에서 높은 쪽에 있다.
대형 모델과의 비교는 더 조심해서 읽어야 한다.
논문 Table 2에서 VibeThinker-3B는 AIME26 94.3으로 DeepSeek V3.2의 94.2와 비슷하고, LiveCodeBench v6 80.2로 DeepSeek V3.2의 80.8에 가깝다.
하지만 Kimi K2.5, GLM-5, Gemini 3 Pro, Qwen3.6 Plus 같은 대형 시스템은 GPQA-D, OJBench, 일부 수학 지표에서 여전히 앞선다.
따라서 “3B가 대형 모델을 전부 이긴다”가 아니라, 일부 검증 가능한 reasoning benchmark에서 대형 모델의 성능대에 들어온다가 정확한 해석이다.
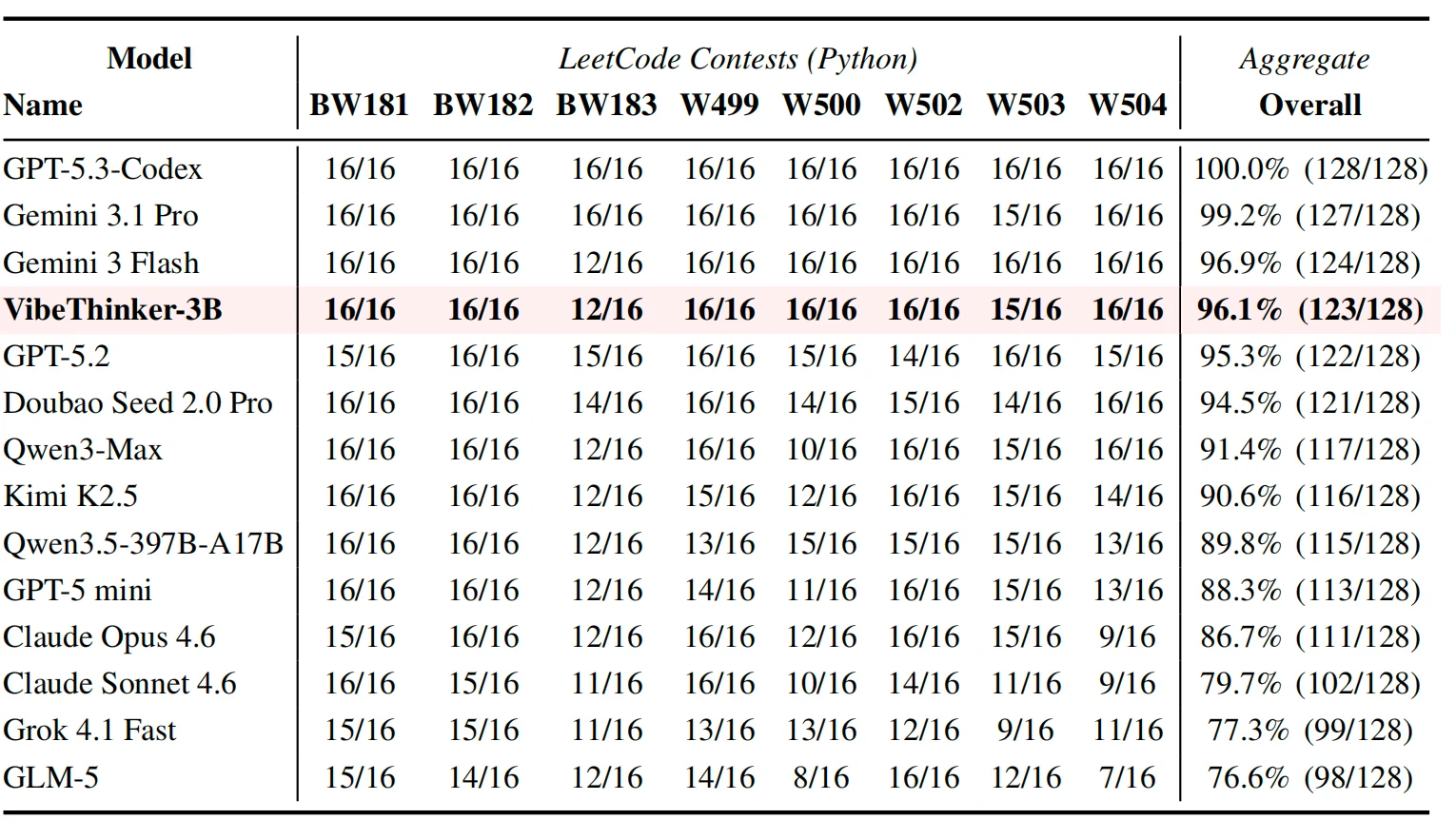
코딩 쪽에서는 별도 OOD 평가가 흥미롭다.
논문은 2026년 4월 25일부터 5월 31일까지의 LeetCode weekly/biweekly contest를 Python 첫 제출 기준으로 평가한다.
VibeThinker-3B는 128문제 중 123개를 통과해 96.1% acceptance rate를 보고한다.
같은 표에서 GPT-5.3-Codex는 128/128, Gemini 3.1 Pro는 127/128, Gemini 3 Flash는 124/128이다.
또 하나의 포인트는 CLR, Claim-Level Reliability Assessment다.
CLR은 전체 reasoning trace를 통째로 투표하는 대신, 각 후보 풀이에서 중요한 claim을 뽑아 모델이 스스로 검증하게 하고, claim 신뢰도를 기반으로 최종 답을 고르는 test-time scaling 방식이다.
보고서 기준 K=32 후보 trajectory, M=5 decision-relevant claims를 사용한다.
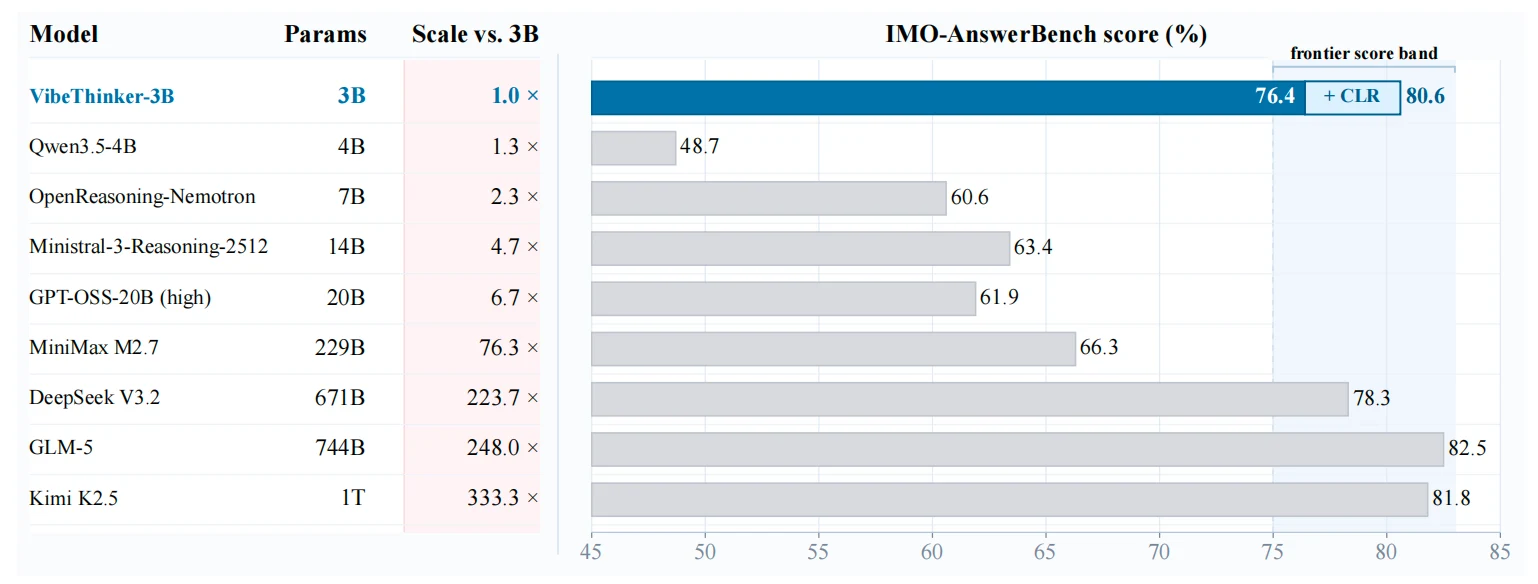
Table 2에서는 VibeThinker-3B + CLR이 AIME25 96.7, AIME26 97.1, HMMT25 95.4, BruMO25 99.2, IMO-AnswerBench 80.6을 보고한다.
공개 아티팩트도 비교적 명확하다.
Hugging Face 모델 저장소 WeiboAI/VibeThinker-3B는 gated가 아니고, license는 MIT로 표시되어 있으며, 모델 트리는 Qwen/Qwen2.5-3B → Qwen/Qwen2.5-Coder-3B → WeiboAI/VibeThinker-3B로 이어진다.
GitHub 저장소 WeiboAI/VibeThinker도 MIT license이며, README는 2026년 6월 16일 VibeThinker-3B release와 모델 다운로드 링크를 명시한다.
ModelScope에도 같은 모델 페이지가 있다.
다만 사용 범위는 모델 카드가 직접 제한한다.
Hugging Face README는 이 모델이 tool-calling 또는 agent-based programming data로 학습되지 않았으므로, function calling, API orchestration, autonomous coding agent 용도에는 권장하지 않는다고 적는다.
프로그래밍 과제라면 LeetCode-style competitive programming처럼 답을 실행 검증할 수 있는 문제를 권장한다.
실무 관점에서의 해석
VibeThinker-3B의 가장 중요한 메시지는 작은 모델의 역할을 다시 나누자는 것이다.
지금까지 작은 모델은 대형 모델의 저가형 대체재처럼 다뤄지는 경우가 많았다.
하지만 이 보고서가 보여 주는 방향은 다르다.
작은 모델을 범용 지식 모델로 쓰기보다, 검증 가능한 문제 공간에서 집중적으로 post-training하면 특정 능력 축에서는 대형 모델의 성능대에 접근할 수 있다.
이 접근이 특히 잘 맞는 영역은 세 가지다.
첫째, 정답 검증기가 있는 수학·코딩 문제다.
둘째, 평가 환경과 배포 환경이 비슷한 constrained reasoning task다.
셋째, 온디바이스나 로컬 서버처럼 모델 크기와 비용이 실제 제약인 환경이다.
이런 곳에서는 70B generalist 하나보다 3B specialist 여러 개를 라우팅하는 설계가 더 현실적일 수 있다.
하지만 caveat도 분명하다.
첫째, 논문 수치는 자체 기술 보고서와 공개 leaderboard/공식 기록 비교를 섞어 구성된다.
독립 재현과 장기적인 leaderboard 검증은 별도 문제다.
둘째, GPQA-D 결과가 보여 주듯 broad knowledge coverage는 여전히 대형 모델 쪽이 유리하다.
셋째, 모델 카드가 경고하듯 agentic tool use나 autonomous coding agent 용도로 해석하면 안 된다.
이 모델의 강점은 “코딩 에이전트”라기보다 “검증 가능한 알고리즘 문제 풀이”에 가깝다.
정리하면 VibeThinker-3B는 작은 모델의 효율성 이야기만으로는 부족하다.
더 흥미로운 점은 능력별 scaling law가 다를 수 있다는 주장이다.
수학·코딩처럼 피드백이 명확한 영역에서는 모델 크기보다 데이터 합성, 다양성 보존, on-policy RL, self-distillation, test-time verification의 설계가 더 직접적인 병목일 수 있다.
VibeThinker-3B가 장기적으로 얼마나 재현될지는 지켜봐야 하지만, 3B 모델을 “싸지만 약한 모델”이 아니라 “검증 가능한 reasoning core”로 보는 관점은 앞으로 더 자주 등장할 가능성이 크다.