작은 vision-language model을 제품에 넣을 때 제일 곤란한 지점은 “이미지를 잘 설명하는가”보다 “후속 시스템이 바로 읽을 수 있는 값을 안정적으로 내는가”일 때가 많다.
카메라 프레임에서 이상 상황을 감지하거나, 제품 이미지를 속성 태그로 바꾸거나, 현장 사진에서 설비 상태를 구조화하려면 자연어 캡션보다 JSON이 더 중요하다.
그리고 이 JSON은 예쁘게 생겼다는 것만으로 충분하지 않다.
요청한 키를 지켜야 하고, 값은 이미지에 근거해야 하며, rule engine·analytics·agent pipeline이 파싱할 수 있어야 한다.
Liquid AI의 LFM2.5-VL-450M-Extract는 바로 이 좁은 계약을 전면에 둔 모델이다.
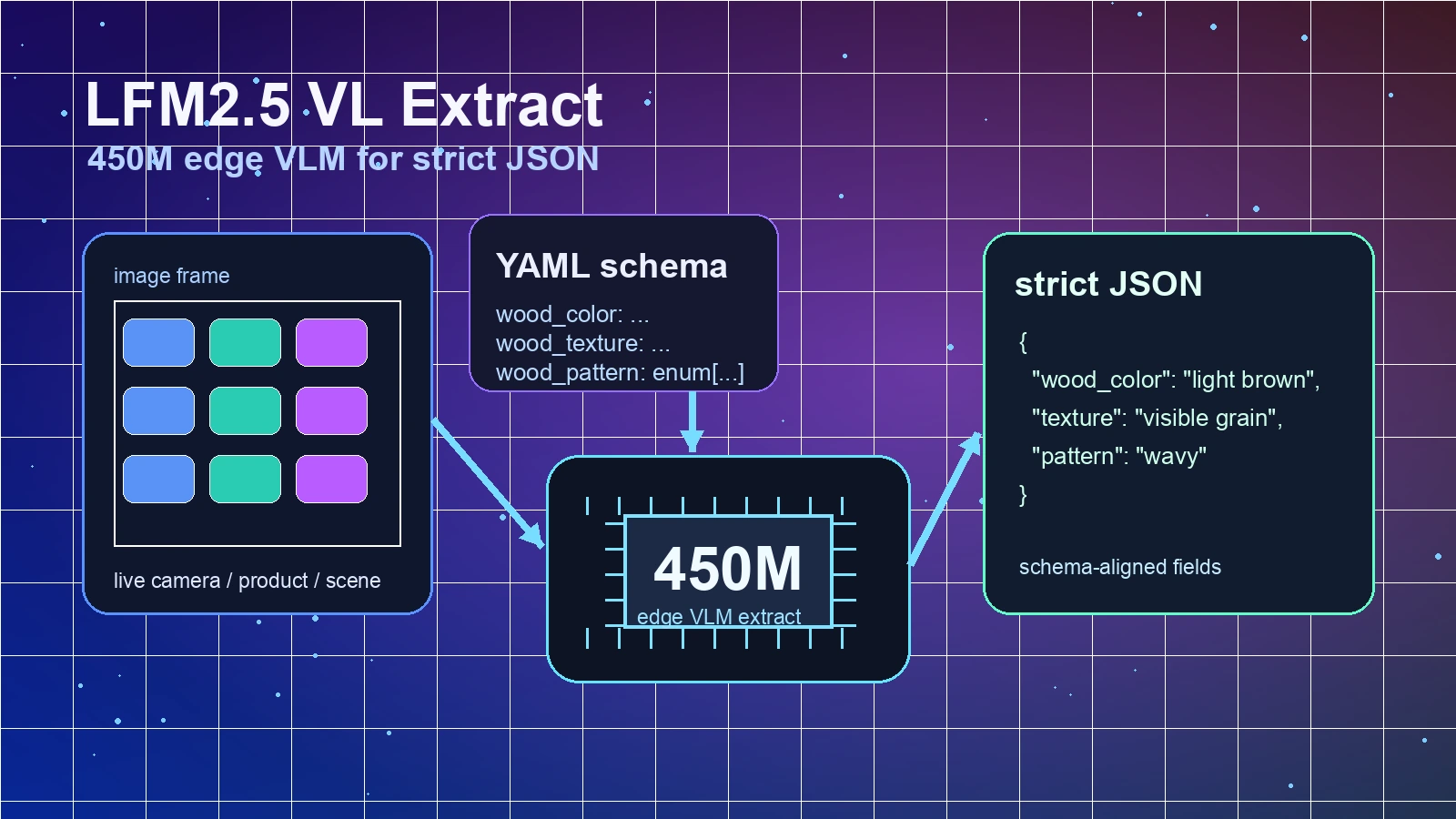
Hugging Face 모델 카드 기준으로 이 모델은 LiquidAI/LFM2.5-VL-450M을 base model로 하는 image-text-to-text 모델이고, 사용자가 시스템 프롬프트에 YAML 형태의 field list를 넣으면 단일 이미지를 보고 해당 필드만 JSON 객체로 반환하도록 설계됐다.
Liquid는 이를 Liquid Nanos 컬렉션의 첫 vision model이라고 설명하며, 텍스트 문서용 LFM2-350M-Extract와 나란히 task-specific extraction family로 배치한다.
이 글은 모델 카드의 예시만 옮기는 대신, Hub API와 raw config, bundled evaluation code, GGUF 변형, 그리고 원래 base 모델인 LFM2.5-VL-450M의 공식 블로그/문서를 함께 읽어 본다.
핵심 질문은 “450M급 VLM이 거대 범용 모델을 이겼다”가 아니라, 스키마를 입력 계약으로 삼는 작은 VLM이 edge visual workflow에서 어떤 운영 단위를 만들 수 있는가다.
무엇을 해결하려는가
범용 VLM을 정보 추출기로 쓰면 실패 모드가 여러 겹으로 생긴다.
어떤 모델은 이미지를 정확히 보지만 JSON 형식을 깨고, 어떤 모델은 JSON은 맞추지만 스키마 설명을 그대로 echo하거나 예시 값을 복사한다.
또 어떤 모델은 요청하지 않은 필드를 추가하거나, enum처럼 제한된 선택지를 무시하거나, 이미지에 없는 값을 그럴듯하게 채운다.
사람에게는 작은 오류처럼 보여도, 자동화 파이프라인에서는 파싱 실패·잘못된 trigger·잘못된 데이터 입력으로 이어진다.
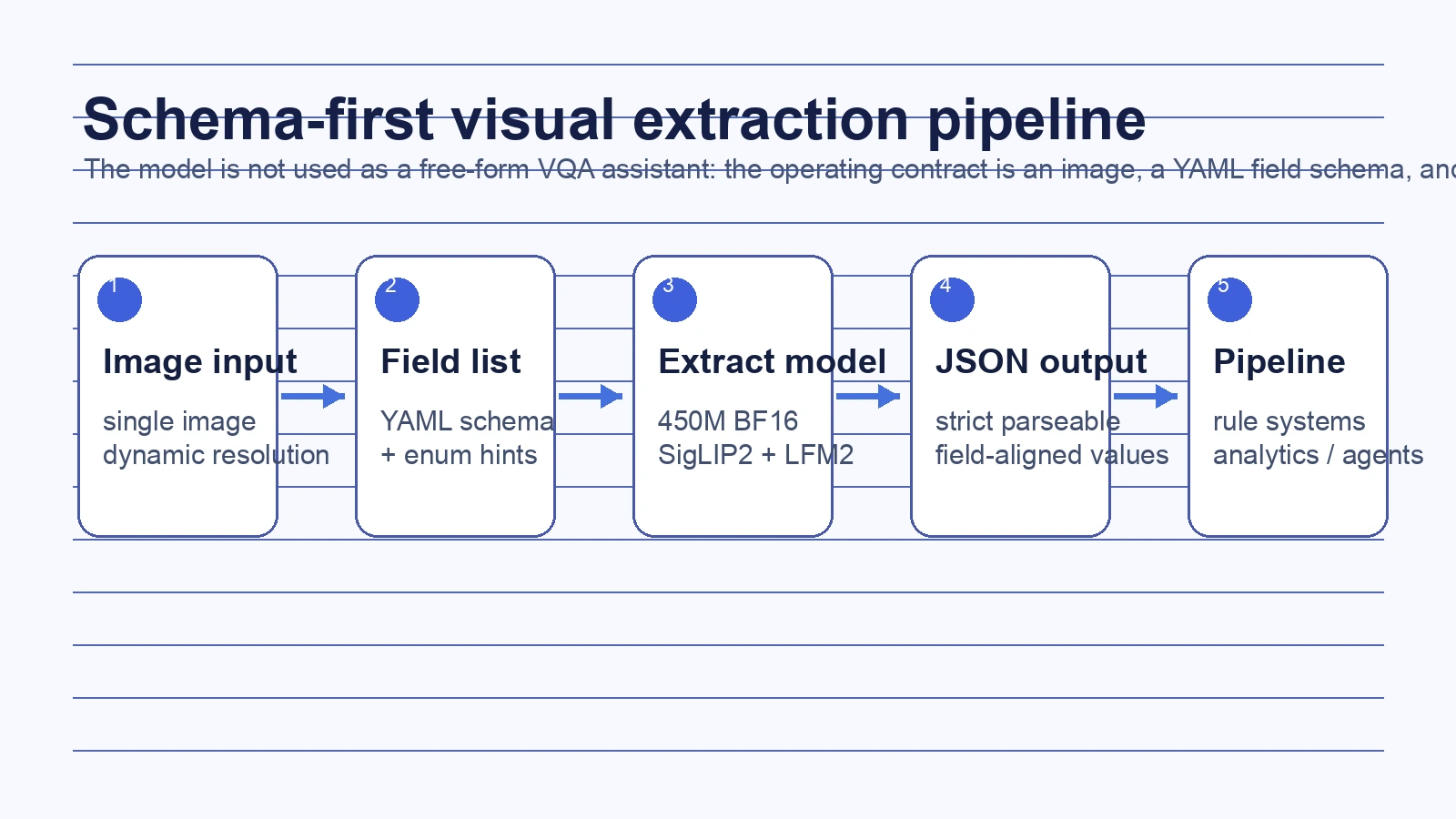
LFM2.5-VL-450M-Extract의 설계는 이 문제를 “더 똑똑한 대화 모델”이 아니라 출력면을 좁힌 extraction model로 푼다.
사용자는 시스템 프롬프트에 필드 이름과 설명을 YAML처럼 넣고, user message에는 이미지를 넣는다.
모델은 추가 설명 없이 JSON 객체만 반환하도록 학습·권장된다.
모델 카드의 warning도 명확하다.
단일 turn conversation을 의도하고, temperature=0에 가까운 greedy decoding을 권장한다.
이 framing은 Liquid가 2026년 4월 공개한 LFM2.5-VL-450M의 방향과 이어진다.
당시 공식 블로그는 450M compact VLM을 “structured visual intelligence, edge to cloud”로 소개하면서 grounding, instruction following, function calling, multilingual image understanding, 저지연 edge inference를 강조했다.
Extract 변형은 그 general VLM 표면을 한 번 더 좁혀, 이미지 설명·질문답변보다 사용자 정의 field extraction에 맞춘 Nano로 읽을 수 있다.
핵심 아이디어 / 구조 / 동작 방식
모델 카드의 기본 예시는 매우 단순하다.
시스템 프롬프트에는 추출할 필드를 적고, user prompt에는 이미지를 넣는다.
wood_color: The overall coloration of the wood surface
wood_texture: The tactile quality of the wood surface
wood_pattern: The pattern types visible on the wood surface
그 결과는 다음처럼 flat JSON 객체다.
{
"wood_color": "light to medium brown",
"wood_texture": "smooth with visible grain",
"wood_pattern": "parallel, irregular, wavy"
}
필드 설명 안에 “select from smooth, rough, or grainy”처럼 가능한 선택지를 넣으면 enum처럼 동작하도록 유도할 수 있다는 점도 중요하다.
이는 모델이 JSON grammar만 맞추는 수준을 넘어, downstream system의 schema/version 관리와 연결될 수 있다는 뜻이다.
실무적으로는 “이미지를 설명해 줘”가 아니라 “이 카메라 프레임을 이 이벤트 스키마에 맞춰 판정해 줘”에 가깝다.
구조 쪽에서는 이름의 450M이 꽤 직접적으로 확인된다.
Hugging Face API 기준 model.safetensors의 BF16 parameter total은 448,718,848개다.
모델 카드의 상세 표는 LM only 350M, vision encoder는 SigLIP2 약 100M이라고 설명한다. raw config.json도 텍스트 쪽 _name_or_path를 LiquidAI/LFM2-350M으로 두고, 16개 layer의 hybrid conv+full-attention 구성을 노출한다. vision config는 hidden size 768, 12 layers, patch size 16의 siglip2_vision_model이다.
이미지 처리 설정도 edge-oriented VLM의 성격을 보여 준다. processor config는 tile size 512, max tiles 10, thumbnail 사용, dynamic image splitting, max image tokens 256, min image tokens 64를 둔다.
모델 카드 표는 single image와 dynamic resolution을 명시하고, context는 128,000 tokens, vocab size는 65,536, precision은 bfloat16로 정리한다.
즉 이 모델은 “문서 전체를 여러 페이지로 읽는 OCR 엔진”이라기보다, 단일 이미지에서 필요한 속성·상태·이벤트 값을 구조화하는 작은 VLM에 가깝다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 해석 |
|---|---|---|
| 전체 checkpoint | BF16 448,718,848 parameters | 모델명 450M과 맞는 compact VLM |
| 언어 백본 | LFM2-350M 계열, 16 layers, conv + full attention 혼합 | 작은 text backbone에 구조화 출력 능력을 얹음 |
| vision encoder | SigLIP2 약 100M, hidden size 768, 12 layers | 이미지 인식은 별도 lightweight encoder가 담당 |
| 이미지 입력 | single image, dynamic resolution, tile size 512 | video stream·제품 이미지·현장 사진 같은 단일 프레임 처리에 적합 |
| 출력 계약 | YAML field list → flat JSON object | downstream parser와 rule system에 바로 연결하기 쉬움 |
공개된 근거에서 확인되는 점
릴리스 표면은 단순 모델 파일 하나보다 더 넓다.
확인 시점의 Hugging Face API 기준 LiquidAI/LFM2.5-VL-450M-Extract는 2026년 5월 26일 생성, 2026년 6월 6일 마지막 수정, gated false, downloads 1,495, likes 45로 표시된다. sibling file에는 config.json, processor_config.json, tokenizer_config.json, chat_template.jinja, model.safetensors뿐 아니라 model_eval/ 디렉터리 전체와 lfm2_vl_450m_metrics.png, sample_image.png가 포함된다.
특히 model_eval/이 같이 올라와 있다는 점이 좋다.
README 기준 평가 파이프라인은 WebDataset tar로 제공되는 2,000개 (image, schema, JSON) 샘플을 읽고, extraction은 local GPU의 vLLM/HF backend에서 수행하며, 별도 VLM judge는 OpenRouter API를 통해 원격으로 호출한다.
구조 metric은 JSON validity와 requested field key F1을 계산하고, 이미지와 값의 일치도는 VLM judge score로 집계한다.
전체 2,000샘플 평가는 기본값 기준 약 30분으로 안내된다.
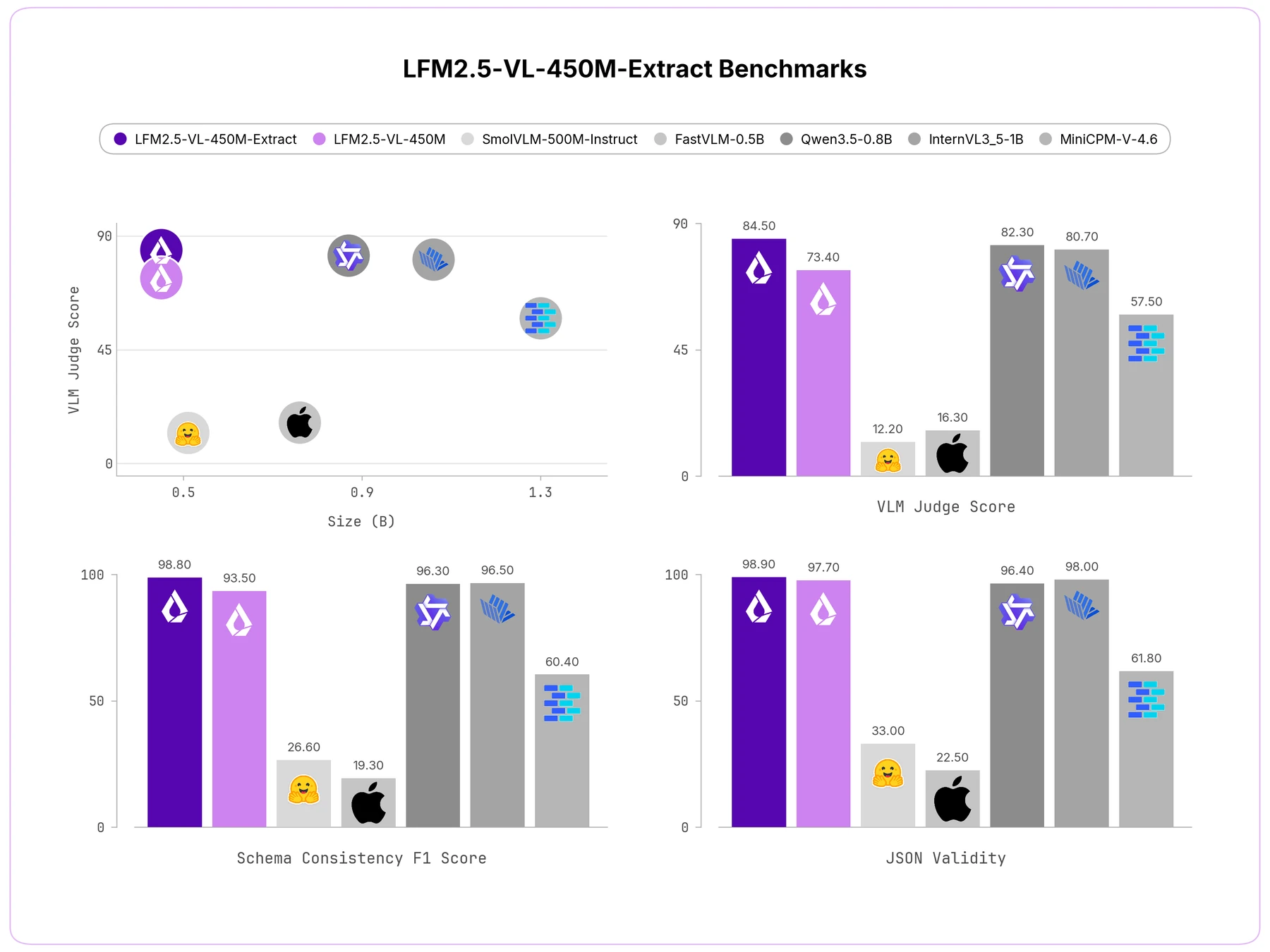
모델 카드의 표를 그대로 읽으면 LFM2.5-VL-450M-Extract는 이 benchmark에서 JSON Validity 98.9, F1 Score 98.8, VLM Judge Score 84.5를 기록한다.
같은 0.45B base 모델인 LFM2.5-VL-450M은 각각 97.7, 93.5, 73.4다.
즉 Extract 변형의 차이는 모델 크기보다 스키마 추출에 맞춘 후처리/특화에서 나온다.
비슷한 작은 VLM과의 비교에서는 SmolVLM-500M-Instruct가 33.0/26.6/12.2, FastVLM-0.5B가 22.5/19.3/16.3으로 크게 낮게 제시된다.
| Model | Params | JSON Validity | F1 Score | VLM Judge Score |
|---|---|---|---|---|
| LFM2.5-VL-450M-Extract | 0.45B | 98.9 | 98.8 | 84.5 |
| LFM2.5-VL-450M | 0.45B | 97.7 | 93.5 | 73.4 |
| Qwen3.5-0.8B | 0.87B | 96.4 | 96.3 | 82.3 |
| InternVL3_5-1B | 1.06B | 98.0 | 96.5 | 80.7 |
| MiniCPM-V-4.6 | 1.30B | 61.8 | 60.4 | 57.5 |
| ref: Qwen3.5-2B | 2.27B | 97.9 | 97.7 | 89.7 |
| ref: InternVL3_5-2B | 2.35B | 99.6 | 99.2 | 87.7 |
이 수치는 유용하지만, 해석은 좁게 해야 한다. reference labels는 frontier multimodal model ensemble로 만들고 consistency 후처리를 거친 것으로 설명되며, VLM Judge Score도 별도 vision model judge에 의존한다.
또한 모델 카드가 직접 적은 scope는 “single input image, YAML field list as schema, flat JSON object output”이다. multi-image reasoning, 자유 형식 VQA, 복잡한 OCR/Markdown 변환으로 일반화되는 숫자가 아니다.

배포면도 확인할 만하다.
Extract 모델 자체는 Transformers repo로 공개되어 있고, 별도 LiquidAI/LFM2.5-VL-450M-Extract-GGUF repo도 존재한다.
GGUF repo에는 LFM2.5-VL-450M-Extract-Q4_0.gguf, Q4_K_M, Q5_K_M, Q6_K, Q8_0, F16과 vision projection용 mmproj-LFM2.5-VL-450M-Extract-F16.gguf, mmproj-LFM2.5-VL-450M-Extract-Q8_0.gguf가 있다.
API상 GGUF metadata는 architecture lfm2, context length 128,000을 노출한다. base LFM2.5-VL-450M 쪽에는 GGUF뿐 아니라 ONNX와 MLX 4bit 변형도 별도로 올라와 있어, Liquid가 이 계열을 edge/runtime packaging 단위로 관리하고 있음을 보여 준다.
실무 관점에서의 해석
내가 보기에 이 모델의 가장 중요한 메시지는 “작은 VLM도 VQA를 잘한다”가 아니다.
더 정확한 메시지는 작은 VLM을 한 작업의 API surface로 고정하면 제품 파이프라인에 넣기 쉬워진다는 것이다.
입력은 이미지와 field schema, 출력은 JSON이다.
이 계약이 안정적이면 safety-critical event detector, frame-level analytics, retail/e-commerce product tagging, local agent의 visual observation adapter처럼 후속 시스템이 바로 소비할 수 있는 형태가 된다.
이는 문서 AI 모델과도 닮았지만 완전히 같지는 않다.
NuExtract3나 PaddleOCR-VL 같은 문서 파싱 모델은 PDF/스캔 문서의 레이아웃, 표, Markdown/OCR, multi-page 처리까지 끌어안는다.
반면 LFM2.5-VL-450M-Extract는 일반 이미지 하나에서 요청한 field만 JSON으로 뽑는 쪽에 더 선명하다.
그래서 문서 ingestion 전체를 대체한다기보다, 카메라·이미지 스트림에서 구조화 observation을 만드는 작은 adapter로 보는 편이 맞다.
운영할 때는 몇 가지 경계가 필요하다.
첫째, JSON validity가 높아도 field-level provenance, bounding box, confidence score는 별도 제공되지 않는다.
안전·금융·의료처럼 값의 근거 위치와 검수 기록이 필요한 업무라면 schema validator, retry policy, confidence proxy, human review queue가 여전히 필요하다.
둘째, enum은 필드 설명으로 유도하는 방식이지 hard grammar constraint는 아니다.
중요한 선택지는 후처리 validator와 fail-closed 정책으로 감싸야 한다.
셋째, 모델 카드 예시처럼 trust_remote_code=True와 최신 Transformers 경로를 쓰는 경우가 있으므로 배포 환경의 보안/재현성 검토도 필요하다.
그럼에도 이 release는 작은 VLM의 제품화 방향을 꽤 명확히 보여 준다.
모델을 더 크게 만드는 대신, 출력 계약을 좁히고, 평가도 그 계약에 맞춰 JSON parseability·schema consistency·image faithfulness로 나눈다.
그리고 그 evaluation code와 데이터 형식, GGUF 변형까지 함께 올린다. edge AI에서 중요한 것은 “모델이 말할 수 있는 모든 것”보다 “내 시스템이 신뢰할 수 있는 형식으로 반복해서 받을 수 있는 것”일 때가 많다.LFM2.5-VL-450M-Extract는 그 관점에서, VLM을 범용 assistant가 아니라 스키마 기반 visual extraction component로 다루는 좋은 release bundle이다.