LLM 에이전트를 잘 쓰려면 모델만 보면 부족하다.
같은 모델이라도 어떤 system prompt를 주는지, 어떤 tool을 어떻게 감싸는지, 실패한 tool call 뒤에 어떤 recovery rule을 주는지, required artifact를 언제 만들게 하는지에 따라 행동이 크게 달라진다.
이 주변 실행층을 논문은 harness라고 부른다.
Self-Harness: Harnesses That Improve Themselves는 이 하네스를 사람이 계속 고치는 대신, 에이전트가 자기 실행 trace를 보고 자기 하네스의 일부를 직접 제안·검증·채택할 수 있는가를 묻는다.
중요한 점은 모델 가중치를 바꾸지 않는다는 것이다.
MiniMax M2.5, Qwen3.5-35B-A3B, GLM-5 같은 고정 모델을 그대로 두고, 그 모델이 작동하는 DeepAgent 기반 실행 하네스만 바꾼다.
논문이 주장하는 Self-Harness는 “무제한 자기개선”이 아니다.
오히려 반대에 가깝다.
바꿀 수 있는 surface를 미리 선언하고, 실패 trace를 verifier-grounded cluster로 묶고, 같은 모델이 bounded edit을 여러 개 제안하게 한 뒤, held-in과 held-out regression test에서 성능이 떨어지지 않는 후보만 받아들인다.
그래서 이 논문의 핵심은 거창한 recursive self-improvement보다 하네스 변경을 empirical state transition으로 다루는 방법론에 있다.
무엇을 해결하려는가
현실의 코딩·터미널 에이전트는 모델 하나로 완성되지 않는다.
Claude Code, Codex, OpenHands, ReAct 계열 시스템을 떠올리면, 실제 성능은 모델과 함께 tool loop, filesystem access, memory, verification instruction, failure recovery policy 같은 주변 장치에 의해 결정된다.
문제는 모델마다 실패 방식이 다르다는 점이다.
어떤 모델은 required file을 끝까지 만들지 못하고, 어떤 모델은 같은 실패한 명령을 반복하고, 어떤 모델은 shell session 사이에서 environment setting을 잃어버린다.
사람 엔지니어가 매 모델마다 하네스를 관찰하고 고치는 방식은 새 모델이 빨리 나오는 환경에서는 확장성이 낮다.
반대로 더 강한 외부 에이전트가 target agent를 고치는 Meta-Harness 방식은 비용, 접근성, frontier model 비공개성 문제가 생길 수 있다.
Self-Harness가 잡은 질문은 그래서 좁고 실용적이다.
고정된 모델이 자기 실패 증거를 보고, 자기에게 맞는 작은 harness edit을 제안하고, regression gate를 통과한 변경만 누적하면 실제 pass rate가 오르는가?
논문은 이 질문을 Terminal-Bench-2.0에서 검증한다.
공개 arXiv abs/html 기준으로 별도 공식 GitHub 저장소나 project page 링크는 확인되지 않으며, 현재 근거는 논문 본문과 arXiv HTML/PDF가 중심이다.
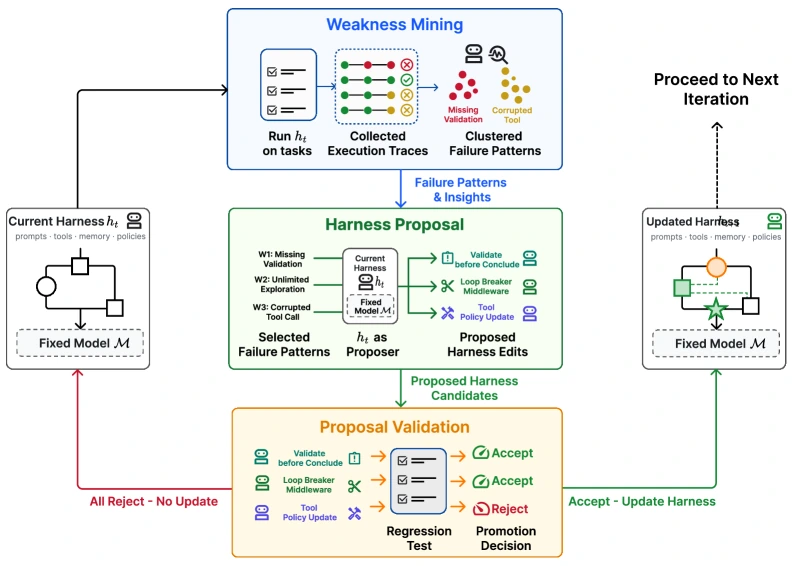
핵심 루프: 채굴하고, 제안하고, 검증한다
Self-Harness는 매 iteration마다 세 단계를 돈다.
| 단계 | 하는 일 | 실무적으로 중요한 이유 |
|---|---|---|
| Weakness Mining | held-in task에서 실패 trace를 모으고 verifier-level cause, agent-side behavior, reusable mechanism으로 failure signature를 만든다 | “timeout” 같은 표면 증상만 보지 않고, 실제로 어떤 행동 메커니즘이 실패를 만들었는지 분리한다 |
| Harness Proposal | 같은 모델을 proposer로 호출해 editable surface에 대한 여러 bounded edit 후보를 만든다 | 외부 초강력 optimizer가 아니라 target model 자신의 관찰과 제안 능력을 쓴다 |
| Proposal Validation | 후보 하네스를 같은 evaluator로 다시 실행하고 held-in/held-out split 모두에서 non-regression을 요구한다 | held-in 실패만 고치고 unseen task를 망가뜨리는 patch를 막는다 |
Acceptance rule은 보수적이다.
후보 edit Δj로 만든 하네스가 held-in pass count와 held-out pass count 중 하나라도 올리되, 다른 split을 떨어뜨리면 안 된다.
둘 다 그대로거나 하나라도 감소하면 reject다.
여러 후보가 동시에 통과하면 compatible edit을 merge하고, reject된 후보는 active harness를 바꾸지 않는다.
논문은 stochastic evaluation일 때 repeated evaluation의 aggregate pass count에 같은 rule을 적용한다고 설명한다.
이 구조에서 중요한 분리는 세 가지다.
첫째, 모델 M과 evaluator E는 고정한다.
둘째, proposer가 볼 수 있는 것은 raw log 전체가 아니라 구조화된 evidence bundle이다.
셋째, 하네스 변경은 선언된 surface 안에서만 일어난다.
그래서 성능이 오르면 적어도 실험 설계 안에서는 “모델이 바뀌어서”가 아니라 “하네스 scaffold가 바뀌어서”라고 해석할 수 있다.
실험 설정: Terminal-Bench-2.0 위의 최소 DeepAgent 하네스
실험은 Terminal-Bench-2.0을 사용한다.
논문 설명 기준 Terminal-Bench-2.0은 deterministic verifier가 있는 containerized terminal task 89개를 포함하고, 저자들은 unstable external web resource에 의존하거나 multimodal input이 필요한 task를 제외해 고정 64개 subset에서 평가한다.
각 task는 fresh benchmark environment에서 시작한다.
초기 하네스는 일부러 작다.
DeepAgent SDK 위에 짧은 Terminal-Bench용 system prompt와 기본 filesystem/shell tool만 얹고, Self-Harness가 바꿀 수 있는 interface를 선언한다.
Figure 3의 baseline prompt는 “Terminal Bench 2 Harbor task environment 안에서 workspace를 inspect하고, concrete edit을 만들고, 실제 환경에서 verify하라”는 정도의 최소 지시다.
| 축 | 설정 |
|---|---|
| Benchmark | Terminal-Bench-2.0, fixed 64-case subset |
| Models | MiniMax M2.5, Qwen3.5-35B-A3B, GLM-5 |
| Harness base | DeepAgent 기반 최소 system prompt + 기본 file/shell tools |
| 바뀌는 것 | harness definition file의 declared configuration surfaces |
| 고정되는 것 | model backend, tool set, decoding/budget, benchmark environment, evaluator |
| Split | held-in은 trace와 failure evidence 제공, held-out은 proposer에게 보이지 않는 regression gate |
| Metric | Pass (%), 각 harness candidate에 대해 기본적으로 task당 2회 repeated attempt 평균 |
여기서 held-out split이 중요하다.
Self-Harness는 held-in에서 나온 실패 증거를 바탕으로 edit을 만들지만, promotion은 held-out에서도 떨어지지 않아야 한다.
이는 “실패 사례를 prompt에 하드코딩해서 점수만 올리는” 방향을 줄이기 위한 최소한의 안전장치다.
결과: 세 모델 모두 held-out pass rate가 오른다
가장 직접적인 결과는 Figure 4다.
세 모델 모두 initial harness보다 Self-Harness가 만든 final harness에서 held-in과 held-out pass rate가 개선됐다.
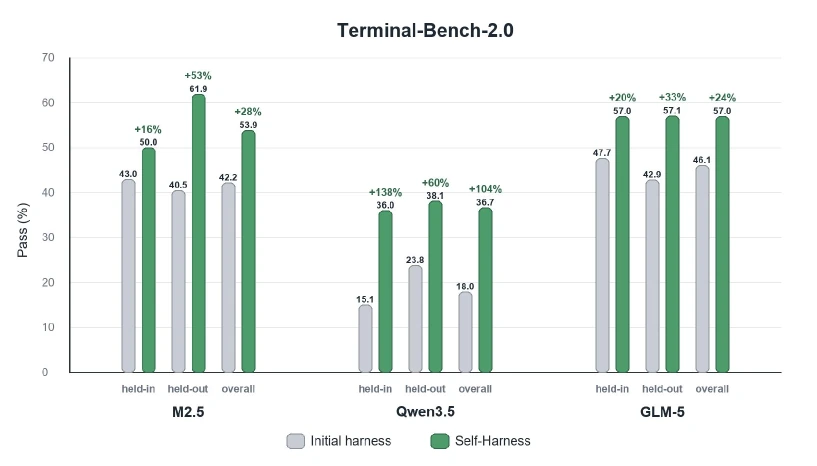
| Model | Held-in initial → Self-Harness | Held-out initial → Self-Harness | 해석 |
|---|---|---|---|
| MiniMax M2.5 | 43.0 → 50.0 (+16% relative) | 40.5 → 61.9 (+53% relative) | output artifact를 더 일찍 만들고, schema/tool loop 실패를 줄이는 edit이 효과를 냄 |
| Qwen3.5-35B-A3B | 15.1 → 36.0 (+138% relative) | 23.8 → 38.1 (+60% relative) | 약한 baseline에서 artifact check, dependency precheck, retry discipline이 크게 작용 |
| GLM-5 | 47.7 → 57.0 (+20% relative) | 42.9 → 57.1 (+33% relative) | shell/session 환경 보존과 exploration→implementation 전환이 도움이 됨 |
논문이 강조하는 포인트는 두 가지다.
하나는 하네스 수준의 작은 edit만으로도, 모델·tool set·budget·evaluator를 고정한 상태에서 measurable improvement가 나온다는 점이다.
다른 하나는 개선이 held-in failure에만 머물지 않고 held-out split에도 나타난다는 점이다.
물론 이것이 모든 환경으로 일반화된다는 뜻은 아니지만, 최소한 Terminal-Bench-2.0의 고정 subset에서는 case-specific patch만 한 것이 아니라 reusable execution mechanism을 건드렸다는 신호로 읽을 수 있다.
어떤 edit이 살아남았나
Self-Harness가 흥미로운 이유는 “좋은 문장을 더 붙였다” 수준에서 끝나지 않는다는 점이다.
논문은 accepted/rejected candidate trajectory와 final harness에 남은 code-level edit을 같이 보여준다.
전체적으로 final harness는 많은 후보 중 일부만 통과한 결과다.
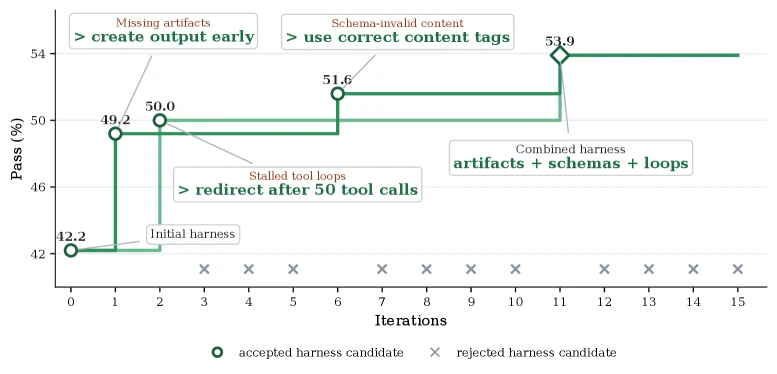
MiniMax M2.5의 final harness는 overall pass rate를 42.2%에서 53.9%로 올린다. retained edit은 대략 세 방향이다. required output artifact를 더 일찍 만들게 하고, structured tool content를 올바르게 다루게 하며, tool interaction이 길게 늘어질 때 redirect하도록 runtime policy를 켠다.
논문 Figure 7의 trace case에서는 초기 하네스가 관련 metadata configuration을 찾고도 계속 dataset exploration을 하다가 /app/answer.txt를 만들지 못하지만, 수정된 하네스는 science subset을 식별하고 token total을 계산한 뒤 answer file을 쓰고 다시 읽어 검증한다.

Qwen3.5-35B-A3B는 다른 병목을 보인다. evolution run은 20.3%에서 36.7%까지 올라가며, retained edit은 artifact checking, missing-artifact recovery, retry discipline, tool-error-triggered middleware 쪽으로 모인다.
논문은 Qwen3.5가 file-editing 또는 tool failure 이후에도 verifier-required artifact를 남기도록 회복 행동을 바꾸는 데 효과가 있었다고 설명한다.
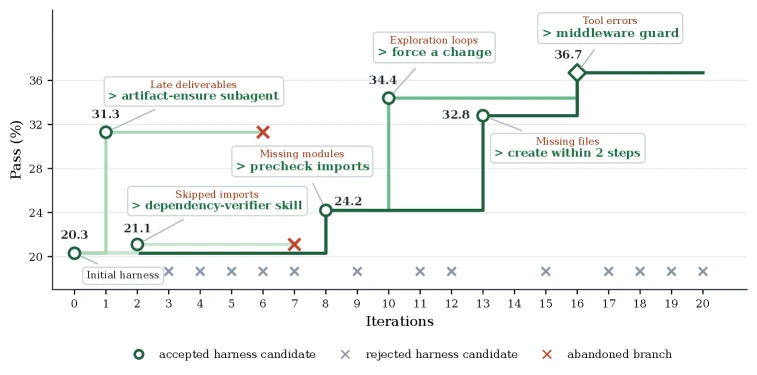
GLM-5는 또 다르다.
논문 본문과 appendix 분석은 GLM-5의 retained edit이 late artifact, external computation, session-scoped tools, implementation-oriented exploration을 겨냥한다고 설명한다.
요지는 shell command 사이에서 환경 변경이 유지되도록 하고, 긴 탐색보다 구현과 테스트로 빨리 넘어가게 하는 것이다.
이 차이는 실무적으로 중요하다.
같은 초기 하네스라도 모델마다 드러나는 실패 양상이 다르고, 따라서 좋은 하네스 변경도 달라진다.
Self-Harness의 장점은 이 차이를 “모델별 실패 trace → 모델별 bounded edit → regression gate”로 연결했다는 데 있다.
실무 관점에서의 해석
내가 보기에 이 논문에서 가장 쓸 만한 문장은 “self-improvement”가 아니라 recorded, testable, reversible harness change다.
실제 에이전트 운영에서 위험한 것은 에이전트가 자기 프롬프트나 tool policy를 아무렇게나 고치는 것이다.
Self-Harness는 그 방향으로 가지 않는다.
오히려 다음 조건을 둔다.
- 어떤 behavior를 바꾸려는지 failure evidence가 있어야 한다.
- 어떤 harness surface를 바꾸는지 명시되어야 한다.
- candidate edit은 bounded해야 한다.
- held-in과 held-out regression gate를 통과해야 한다.
- accepted/rejected decision과 changed surface가 audit log로 남아야 한다.
이 다섯 조건은 연구 실험을 넘어 agent platform 설계 원칙으로도 유용하다.
예를 들어 사내 코딩 에이전트가 매주 실패 trace를 모은다고 해도, 곧바로 CLAUDE.md나 tool middleware를 자동 수정하게 하면 위험하다.
대신 실패 cluster, candidate diff, regression result, rollback path를 함께 저장해야 한다.
사람 리뷰를 붙일 수도 있고, low-risk skill/prompt surface부터 canary로 적용할 수도 있다.
또 하나의 포인트는 하네스 변경이 “더 긴 instruction”과 같지 않다는 점이다.
MiniMax의 경우 output artifact를 일찍 만들게 하는 bootstrap change와 loop breaker가 중요했고, Qwen3.5는 tool error 이후 복구와 retry discipline이 중요했으며, GLM-5는 shell/session persistence와 implementation 전환이 중요했다.
좋은 하네스 edit은 일반론이 아니라 반복 실패를 관찰한 뒤 실행 프로토콜의 작은 부분을 바꾸는 것에 가깝다.
이 관점은 최근 harness/skill/self-evolution 논문들과도 맞물린다.
어떤 논문은 “좋은 update를 쓰는 능력”과 “그 update를 실제 작업에서 활용하는 능력”을 분리한다.
Self-Harness는 여기서 한 발 더 들어가, target model이 자기 update 후보를 쓰고 자기 평가 gate를 통과해야만 lineage에 반영되는 protocol을 보여준다.
즉 harness self-evolution은 결국 prompt writing 문제가 아니라, trace collection, failure attribution, proposal search, validation gate, auditability를 모두 포함하는 운영 시스템 문제다.
한계와 주의점
Self-Harness를 읽을 때 가장 조심해야 할 점은 이것이 open-ended recursive self-improvement의 증명이 아니라는 것이다.
논문도 결론에서 bounded harness edits under fixed benchmarks라고 한계를 분명히 둔다.
모델, evaluator, benchmark protocol은 고정되어 있고, 바뀌는 것은 선언된 harness surface다.
또한 실험은 Terminal-Bench-2.0의 fixed 64-case subset에 한정된다. unstable external web resource와 multimodal task를 제외한 것은 noise를 줄이기 위한 합리적 선택이지만, 동시에 결과가 더 넓은 웹·멀티모달·비결정적 업무로 바로 확장된다는 뜻은 아니다.
Accepted edit도 benchmark-specific failure pattern을 일부 반영할 수 있다.
Regression gate도 최소 조건으로 봐야 한다.
논문 acceptance rule은 pass-count non-regression을 요구하지만, 고위험 업무라면 이것만으로 부족하다.
보안·권한·비용·데이터 유출 위험이 있는 하네스 변경은 pass rate가 올라도 reject되어야 할 수 있다.
실제 제품에서는 destructive tool, credential access, network egress, package install, external API billing 같은 별도 policy gate가 필요하다.
마지막으로 공개 구현 표면도 확인해야 한다. arXiv abs/html에는 논문 PDF와 HTML 외에 공식 code repository 링크가 보이지 않는다.
따라서 현재 글은 논문 본문과 arXiv HTML에서 확인되는 실험 설계·수치·그림을 근거로 해석한 것이며, 재현 코드가 안정적으로 공개되어 있다고 가정하지 않는다.
그럼에도 이 논문은 좋은 방향을 보여준다.
에이전트가 오래 일할수록 좋아지려면 단순히 “더 좋은 모델”을 기다리는 것만으로는 부족하다.
실패 trace를 구조화하고, 작은 하네스 변경을 제안하고, regression gate로 검증하며, audit 가능한 lineage로 남기는 운영 체계가 필요하다.
Self-Harness는 그 체계를 연구 실험 형태로 압축해 보여준 사례다.