수학 AI를 둘러싼 최근 경쟁은 주로 “어떤 모델이 어려운 문제를 몇 퍼센트 더 풀었는가”로 소비된다. 하지만 실제 수학 연구는 벤치마크 문제 하나에 정답을 쓰는 과정과 꽤 다르다. 문제 정의가 흔들리고, 관련 문헌을 다시 뒤지고, 작은 계산을 돌려 직관을 만들고, 틀린 보조정리를 버리고, 며칠 뒤 다시 같은 가설을 꺼내 검토하는 일이 반복된다. 논문으로 남는 것은 polished proof지만, 연구자의 하루는 훨씬 더 지저분한 상태 관리에 가깝다.
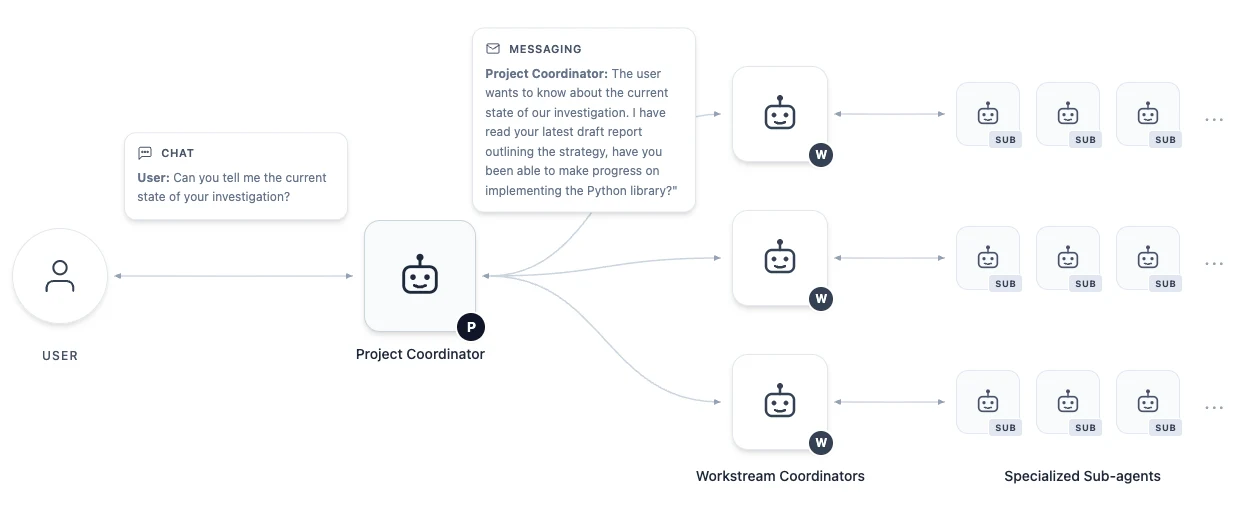
AI co-mathematician: Accelerating mathematicians with agentic AI는 바로 이 간극을 겨냥한다. 이 논문이 소개하는 AI co-mathematician은 수학자를 대신해 최종 증명만 내놓는 theorem prover가 아니라, 수학자가 장기 연구 프로젝트를 함께 운영할 수 있는 agentic workbench다. 사용자는 상위 project coordinator와 대화하고, 시스템은 내부적으로 여러 workstream coordinator와 specialized sub-agent를 배치해 문헌 조사, 계산 실험, 코드 작성, 증명 탐색, 리뷰를 나눠 수행한다.
헤드라인 수치도 강하다. 논문은 AI co-mathematician이 FrontierMath Tier 4에서 48%를 기록해, 평가 당시 모든 AI 시스템 중 새 최고점을 냈다고 보고한다. 하지만 이 글에서 더 중요하게 볼 지점은 “또 하나의 수학 벤치마크 SOTA”가 아니다. 진짜 신호는 AI 수학 시스템의 중심이 정답 생성기에서 연구 운영체제로 이동하고 있다는 점이다.
무엇을 해결하려는가
AI-for-mathematics에는 이미 여러 강한 축이 있다. Minerva류의 수학 추론 모델, AlphaProof 같은 formal reasoning 시스템, AlphaEvolve처럼 프로그램 탐색으로 수학적 구조를 찾는 시스템, 그리고 Gemini Deep Think 같은 강한 inference-time reasoning 모델이 각각 발전해 왔다. 이들은 “문제 풀이 능력” 자체를 빠르게 끌어올렸다.
그런데 논문이 지적하는 병목은 조금 다르다. 수학자는 하나의 프롬프트를 던지고 답을 기다리는 방식으로 연구하지 않는다. 연구 과정에서는 질문 자체가 바뀌고, 실패한 접근이 다음 접근의 힌트가 되고, 문헌에서 찾은 정리의 조건을 다시 확인해야 하며, 계산 실험과 비형식 증명과 형식 검증 가능성이 함께 움직인다. 일반적인 채팅 UI는 이런 상태를 오래 보존하지 못하고, 전문화된 증명/탐색 엔진은 넓은 프로젝트 맥락을 스스로 조직하기 어렵다.
AI co-mathematician의 설계 원칙은 이 문제의식에서 나온다. 논문은 수학 연구를 final proof만이 아니라 ideation, literature search, computational exploration, theorem proving, theory building이 섞인 활동으로 본다. 따라서 시스템도 사용자가 처음부터 완벽한 문제 정의를 넣는다는 전제를 버리고, 연구 질문을 함께 정리하고, 승인된 목표를 만들고, 병렬 workstream을 열고, 실패한 가설과 부분 결과를 workspace 안에 남기는 쪽으로 설계된다.
이 접근은 “완전 자동 수학자”보다 mathematician-in-the-loop에 더 가깝다. 논문은 수학이 인간 이해를 진전시키는 사회적 활동이라는 관점을 명시적으로 가져온다. 따라서 목표는 인간을 배제하고 논문을 자동 생산하는 것이 아니라, 인간 수학자가 자신의 문제 감각과 검증 능력을 유지한 채 더 많은 탐색을 병렬로 진행할 수 있게 하는 것이다.
핵심 아이디어 / 구조 / 동작 방식
시스템의 기본 단위는 프로젝트 workspace다. 이 workspace에는 공유 파일시스템과 내부 메시징 시스템이 있고, 계층형 에이전트들이 그 위에서 작업한다. 사용자가 직접 상대하는 것은 top-level project coordinator다. project coordinator는 사용자의 의도를 정리하고, 목표를 확정하고, 필요하면 workstream을 만들거나 멈추며, 하위 작업의 결과를 사용자에게 설명한다.
논문이 제시하는 대표 흐름은 moving sofa problem의 변형을 다루는 시나리오다. 사용자가 논문과 간단한 목표를 올리면 project coordinator는 곧장 증명에 뛰어들지 않는다. 먼저 “어떤 variant에 집중할 것인가”, “특정 lower bound가 sharp하다는 것을 보일 것인가, 아니면 새로운 upper bound면 충분한가”처럼 연구 의도를 다시 묻는다. 이 대화가 끝나면 research question과 project goals가 만들어지고, 사용자가 이를 승인한 뒤에야 본격적인 workstream이 시작된다.
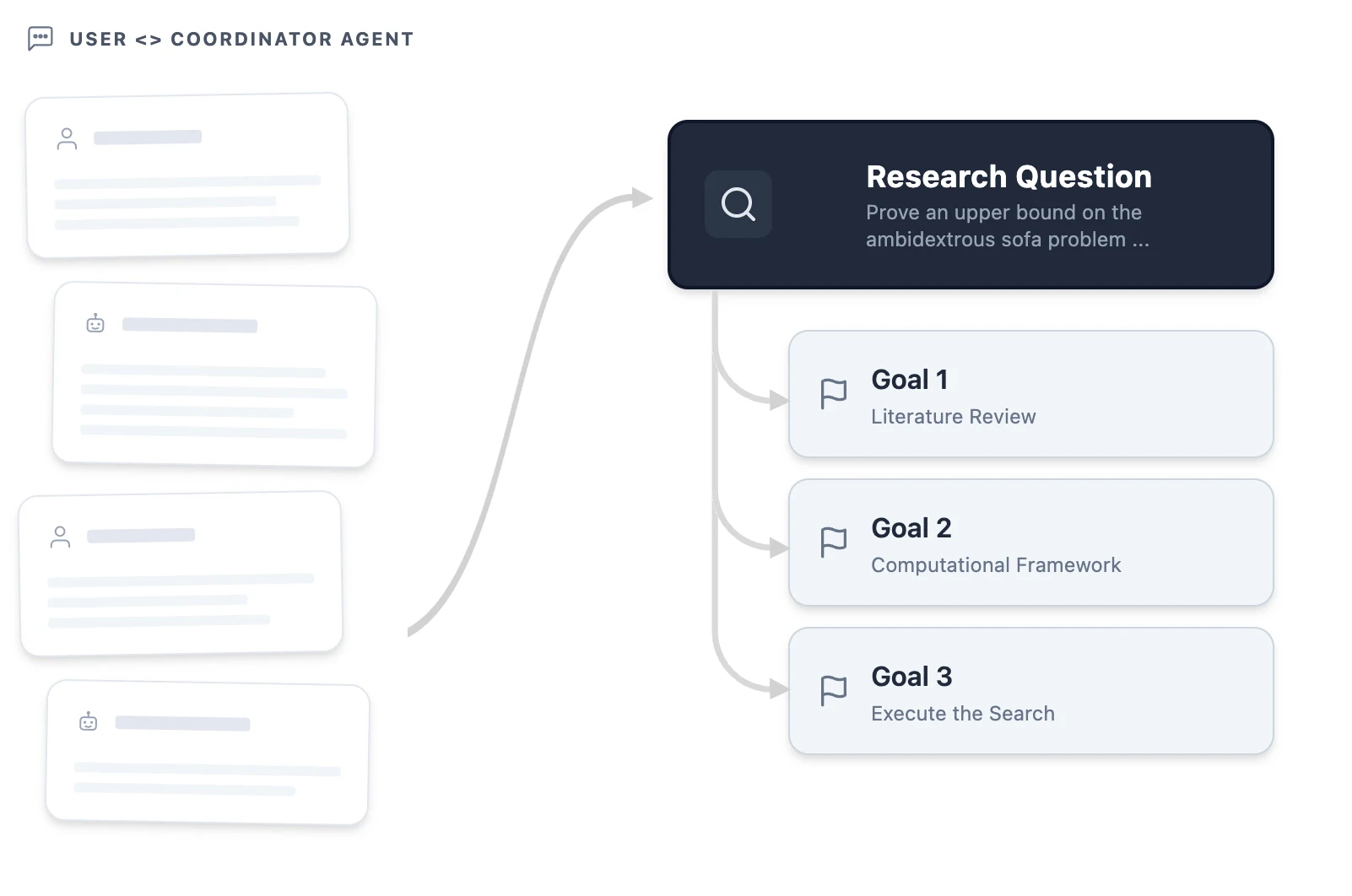
구조를 단순화하면 다음과 같다.
| 구성 요소 | 역할 | 왜 중요한가 |
|---|---|---|
| Project coordinator | 사용자와 대화하고 전체 목표·상태·우선순위를 관리 | 연구 방향이 바뀔 때 하위 작업을 다시 조정한다 |
| Workstream coordinator | 특정 목표나 하위 문제를 맡아 순차/병렬 작업을 운영 | 문헌 조사, 계산 프레임워크, 증명 탐색을 분리해 진행한다 |
| Specialized sub-agent | literature review, coding, proving, web/document query 같은 세부 작업 수행 | 수학 연구의 이질적인 활동을 하나의 모델 호출로 뭉개지 않는다 |
| Shared workspace | 파일, 중간 보고서, 실패 기록, 코드, 참고 문헌을 보존 | 장기 연구에서 중요한 상태와 provenance를 잃지 않는다 |
| Reviewer agents | 산출물을 반복 검토하고 오류를 지적 | agent가 섣불리 성공을 선언하는 것을 줄인다 |
| Human steering | 사용자가 중간 상태를 읽고 새 힌트나 hard constraint를 제공 | 인간의 수학적 직관을 루프 밖으로 밀어내지 않는다 |
흥미로운 부분은 시스템이 실패를 숨기지 않도록 설계했다는 점이다. 논문은 표준 AI agent가 어려운 연구 문제에서 invalid shortcut, hallucinated lemma, premature success claim으로 빠지기 쉽다고 지적한다. 그래서 AI co-mathematician은 코드 작업에서는 테스트와 reviewer approval이 통과되기 전까지 완료를 선언하지 못하게 하고, computational search가 막히면 그 실패한 접근을 workspace에 보존한 뒤 사용자에게 명시적으로 도움을 요청한다.
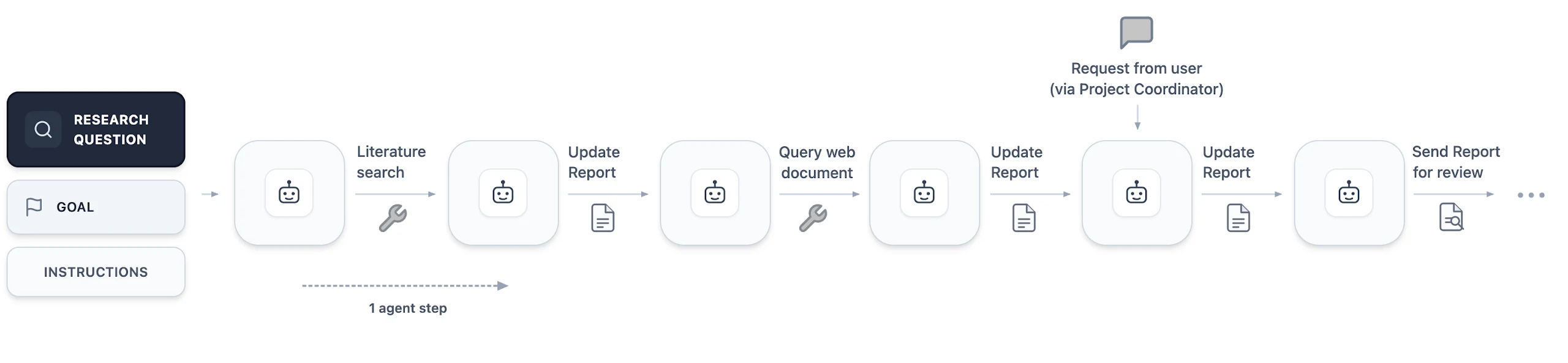
최종 산출물도 채팅 답변이 아니다. 각 workstream coordinator는 LaTeX 기반 working paper를 만들고, 그 문서에는 연구 과정의 설명, margin annotation, 내부 workspace 문서 링크, 외부 문헌 링크, 리뷰 이력이 붙는다. 즉 시스템은 “답은 이렇다”라고 말하는 대신, 사용자가 나중에 검토하고 수정할 수 있는 수학 커뮤니티의 native artifact를 만들려고 한다.
공개된 근거에서 확인되는 점
논문은 arXiv 기준 2026년 5월 7일 공개, 5월 13일 v2로 업데이트된 cs.AI 논문이다. arXiv abstract와 HTML에는 별도 공식 GitHub 코드 링크나 프로젝트 페이지가 노출돼 있지 않고, GitHub/Hugging Face 검색에서도 공개 구현이나 모델 저장소는 확인되지 않았다. 따라서 현재 공개 근거는 논문 본문, arXiv HTML의 공식 figure, Hugging Face Papers 토론 페이지, 그리고 논문이 연결한 FrontierMath/Epoch AI 관련 페이지로 보는 것이 안전하다. 이 글도 AI co-mathematician을 즉시 설치 가능한 OSS 도구가 아니라, Google 연구진이 보고한 제한 공개/프로토타입 연구 시스템으로 해석한다.
초기 사용자 사례는 세 가지가 제시된다. 첫째, Marc Lackenby는 topology/group theory 문제 중 Kourovka Notebook Problem 21.10을 다뤘다. 시스템은 처음에 flawed proof를 만들었지만 reviewer agent가 오류를 표시했고, Lackenby는 그 안의 “clever proof strategy”를 보고 gap을 메우는 방법을 제안했다. 이후 시스템은 완성된 증명을 다시 작성하고 리뷰했다. 이 사례에서 중요한 것은 AI가 혼자 완벽한 증명을 냈다는 점이 아니라, 불완전하지만 유용한 전략을 인간 수학자가 읽고 보정하는 협업 루프가 작동했다는 점이다.
둘째, Gergely Bérczi는 symmetric power representation의 Stirling coefficients 관련 conjecture를 다뤘다. 그는 배경 노트와 기존 실험 방향을 함께 넣었고, 시스템은 여러 workstream에서 증명과 계산 증거를 만들었다. 논문은 이 결과가 아직 detailed human review 중이라고 신중하게 표현한다. 셋째, Semon Rezchikov는 Hamiltonian diffeomorphism 관련 technical subproblem을 제시했고, 시스템은 관련 문헌 조사와 Gemini Deep Think 기반 proving step을 거쳐 key lemma가 포함된 write-up을 만들었다고 보고한다.
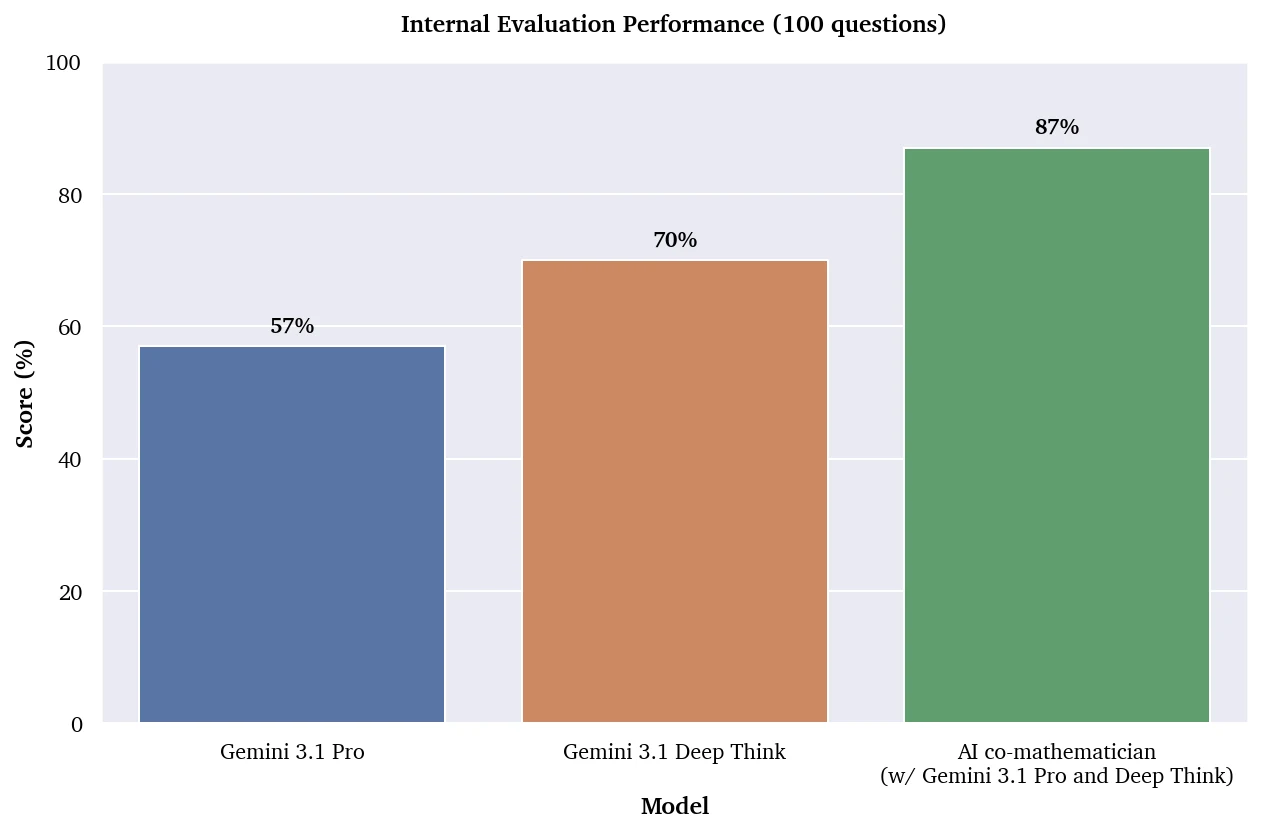
정량 결과는 두 층이다. 내부 연구 수학 벤치마크에서는 전문 수학자들이 만든 100개의 unleaked research-level 문제를 사용했고, 정답은 code-checkable 형태였다고 설명한다. 여기서 단일 Gemini 3.1 Pro 호출은 57%, Gemini 3.1 Deep Think는 70%, AI co-mathematician은 87%를 기록했다. 중요한 점은 co-mathematician 자체도 Gemini 3.1 Pro와 Deep Think를 내부 agent로 활용한다는 것이다. 즉 이 비교는 “다른 base model”의 우월성이라기보다, 상태ful workspace, 병렬 workstream, 도구 사용, 리뷰 루프가 같은 계열 모델의 문제 해결 능력을 얼마나 끌어올리는가에 가깝다.
외부 벤치마크로는 FrontierMath Tier 4 결과가 제시된다. 논문에 따르면 Epoch AI가 AI co-mathematician UI에 직접 문제를 입력하고 답을 회수하는 blind evaluation을 수행했고, 공개 샘플 2개를 제외한 48문제 중 23개를 맞혀 48%를 기록했다. 같은 절에서 논문은 Gemini 3.1 Pro base model이 19%였다고 비교한다. 또한 세 문제는 이전에 평가된 어떤 시스템도 풀지 못한 문제였지만, 반대로 적어도 한 시스템은 풀었던 두 문제를 실패했다고도 적는다.
이 결과를 읽을 때는 비용과 harness 차이를 같이 봐야 한다. 논문은 내부 평가에서는 24시간, FrontierMath에서는 48시간 제한을 둔 final-answer mode를 사용했고, 일반적인 Epoch AI agentic harness와 달리 자체 tool implementation을 쓰며 모델 호출이나 token 생성량에 명시적 제한을 두지 않았다고 설명한다. 따라서 48%는 강한 신호지만, “동일 예산의 단일 모델 비교”로 과잉 해석하면 안 된다. 더 정확한 해석은 장시간 agentic workspace가 어려운 수학 문제에서 큰 compute와 도구 사용을 조직할 때 어느 정도 성과를 낼 수 있는지를 보여 준다는 것이다.
논문 스스로도 한계를 꽤 직접적으로 적는다.
| 한계 | 논문이 지적하는 실패 모드 | 실무적 해석 |
|---|---|---|
| Reviewer-pleasing bias | flawed argument가 reviewer를 만족시키는 형태로 수렴할 수 있음 | 리뷰 루프가 있다고 해서 논리적 진실이 자동 보장되지는 않는다 |
| Intractable disagreements | reviewer와 작성 agent가 합의하지 못해 무한 수정/거절 루프에 빠질 수 있음 | long-running agent에는 종료 조건과 escalation 설계가 필수다 |
| Autonomy vs control | 시스템이 몇 시간 동안 autonomously 진행되면 사용자가 통제권을 일부 내려놓아야 함 | 중간 점검, interrupt, steering UI가 성능만큼 중요하다 |
| Typeset rigor illusion | 잘 조판된 LaTeX가 실제 엄밀성보다 더 높은 신뢰감을 줄 수 있음 | 산출물 UI는 “working document”임을 명확히 표시해야 한다 |
| Literature signal-to-noise | AI가 그럴듯한 LaTeX와 문헌 합성을 대량 생산할 수 있음 | 수학 커뮤니티 차원의 필터링과 검토 비용이 커질 수 있다 |
이 한계 표가 오히려 논문의 신뢰도를 높인다. AI co-mathematician은 “검토자를 붙였으니 안전하다”고 단순화하지 않는다. reviewer agent끼리의 합의도 하나의 동역학이고, 그 자체가 false consensus나 death spiral에 빠질 수 있음을 인정한다. 수학 연구에서 가장 위험한 것은 틀린 답보다, 틀렸다는 사실을 아주 잘 포장된 문서가 가리는 경우다.
실무 관점에서의 해석
내가 보기에 이 논문의 핵심 기여는 수학 AI를 문제 풀이 모델 경쟁에서 연구 워크플로우 설계 문제로 옮긴 것이다. 수학 문제를 더 많이 맞히는 모델은 계속 나올 것이다. 하지만 실제 연구 생산성을 바꾸려면 모델 하나의 답변 품질보다, 가설을 어떻게 분기하고, 실패를 어떻게 기록하고, 문헌과 계산과 증명을 어떻게 연결하며, 인간이 어디서 개입할 수 있는지를 설계해야 한다.
이 관점은 수학 바깥의 AI 연구·소프트웨어 엔지니어링·과학 자동화에도 그대로 이어진다. 좋은 agentic research system은 “많은 sub-agent를 띄운다”가 아니라, 다음 속성을 가져야 한다.
- 사용자의 의도를 초기에 함께 정제하고 명시적으로 승인받는다.
- 병렬 workstream을 열되, 각 workstream의 목표와 provenance를 분리한다.
- 실패한 가설과 막힌 계산을 지우지 않고 감사 가능한 기록으로 남긴다.
- 최종 채팅 답변보다 domain-native artifact를 만든다.
- 리뷰 루프를 두되, 그 리뷰 자체의 실패 가능성을 사용자에게 드러낸다.
- 인간 전문가가 중간에 들어와 방향을 바꿀 수 있는 steering surface를 제공한다.
그래서 AI co-mathematician은 “수학자가 필요 없어졌다”의 증거가 아니다. 오히려 논문에서 가장 인상적인 사례들은 사용자가 해당 분야를 잘 알 때 시스템이 더 잘 작동한다는 쪽이다. Lackenby가 gap을 메우고, Bérczi가 structured posing을 준비하고, Rezchikov가 문제 정의와 관련 논문을 제공했기 때문에 시스템이 의미 있는 workstream을 만들 수 있었다. 이는 한계이기도 하지만, 동시에 현실적인 제품 방향이다. 전문가는 사라지는 것이 아니라, 더 많은 탐색을 병렬로 지휘하는 역할로 이동한다.
반대로 현재 공개 상태만 보면, 이 시스템을 재현 가능한 도구로 평가하기는 어렵다. 공개 코드는 없고, benchmark harness와 내부 workspace 구현도 논문 수준에서만 설명된다. 따라서 지금 당장 팀이 가져갈 수 있는 것은 설치 명령이 아니라 설계 패턴이다. 특히 “working paper + margin annotations + internal links + reviewer loop + escalation” 조합은 수학뿐 아니라 long-horizon research agent를 만드는 팀들이 참고할 만하다.
결론적으로, AI co-mathematician의 48% FrontierMath Tier 4 결과는 눈에 띄는 수치지만, 더 큰 메시지는 수학 연구용 AI의 단위가 바뀌고 있다는 점이다. 앞으로 중요한 질문은 “어떤 모델이 답을 맞혔는가”에서 “어떤 시스템이 인간 연구자가 불확실성을 잃지 않도록 도우면서 탐색을 확장했는가”로 이동할 가능성이 크다. 이 논문은 그 전환을 꽤 선명하게 보여 주는 사례다.