긴 컨텍스트는 이제 텍스트 모델만의 기능이 아니다.
장문 문서 이해, 긴 영상 분석, 여러 턴의 도구 사용, 에이전트형 워크플로까지 생각하면 VLM도 수십만 토큰의 이미지-텍스트 맥락을 안정적으로 다뤄야 한다.
문제는 “컨텍스트 창을 128K로 늘렸다”는 발표는 많아졌지만, 실제로 어떤 데이터로 어떤 비율로 continued pre-training을 해야 하는지는 여전히 덜 공개돼 있다는 점이다.
Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context는 이 빈틈을 정면으로 다룬다.
논문은 Qwen2.5-VL-7B를 출발점으로 삼아 32K 컨텍스트 모델을 128K로 확장하고, long-context continued pre-training(LongPT)에서 데이터 유형, 길이 분포, task mixture, short-context 데이터 혼합이 성능에 어떤 영향을 주는지 비교한다.
그 결과물인 MMProLong은 새로운 거대 모델 계열이라기보다, 장문 멀티모달 학습 레시피를 검증하기 위한 7B급 실험체에 가깝다.
흥미로운 점은 결론이 “무조건 더 긴 샘플을 더 많이 넣자”가 아니라는 데 있다.
논문은 오히려 다양한 길이의 문서에서 핵심 정보를 찾는 능력, retrieval-heavy QA mixture, instruction 형태의 long-document VQA가 더 중요하다고 말한다.
무엇을 해결하려는가
논문이 겨냥하는 병목은 long-context VLM 학습의 레시피 불투명성이다.
최근 LVLM들은 128K 이상 컨텍스트를 빠르게 지원하기 시작했지만, 그 능력이 어디서 오는지에 대한 공개 정보는 제한적이다.
특히 문서 페이지 이미지, OCR 결과, 긴 텍스트, 질문-답변 데이터가 섞이는 멀티모달 환경에서는 단순히 RoPE scaling이나 최대 길이 확장만으로는 충분하지 않다.
기존 접근 중 하나는 OCR transcription처럼 긴 문서를 텍스트화해 모델이 이미지와 텍스트의 긴 의존성을 학습하게 만드는 방식이다.
하지만 문서 이해 평가가 결국 질문-답변 형태라면, transcription 자체가 최종 태스크와 얼마나 잘 맞는지는 별개의 문제다.
또 다른 직관은 128K를 잘하려면 128K 근처의 긴 샘플을 많이 넣어야 한다는 것이다.
이 역시 그럴듯하지만, 긴 샘플에 토큰 예산을 몰아주는 것이 실제로 generalizable한 long-context 능력을 만드는지는 검증이 필요하다.
이 논문은 이 질문들을 모두 통제된 ablation으로 쪼갠다.
같은 5B-token 예산 안에서 long-document VQA와 OCR transcription을 비교하고, pool-native 길이 분포와 long-biased 길이 분포를 비교하며, 정보추출형 QA와 reasoning QA의 비율을 grid search한다.
즉 “긴 컨텍스트가 된다”를 모델 카드의 숫자가 아니라, 데이터 설계 문제로 다시 끌어내린다.
핵심 아이디어 / 구조 / 동작 방식
전체 실험은 Qwen2.5-VL-7B를 128K 컨텍스트로 확장하는 LongPT 설정에서 진행된다.
저자들은 Dynamic-NTK heuristic을 따라 mRoPE base frequency를 1×10^6에서 4×10^6으로 조정하고, 최대 길이 131,072 토큰에서 학습한다.
최종 레시피의 토큰 예산은 5B tokens이며, 논문 표 기준 약 2.9K H20 hours가 들어간다.
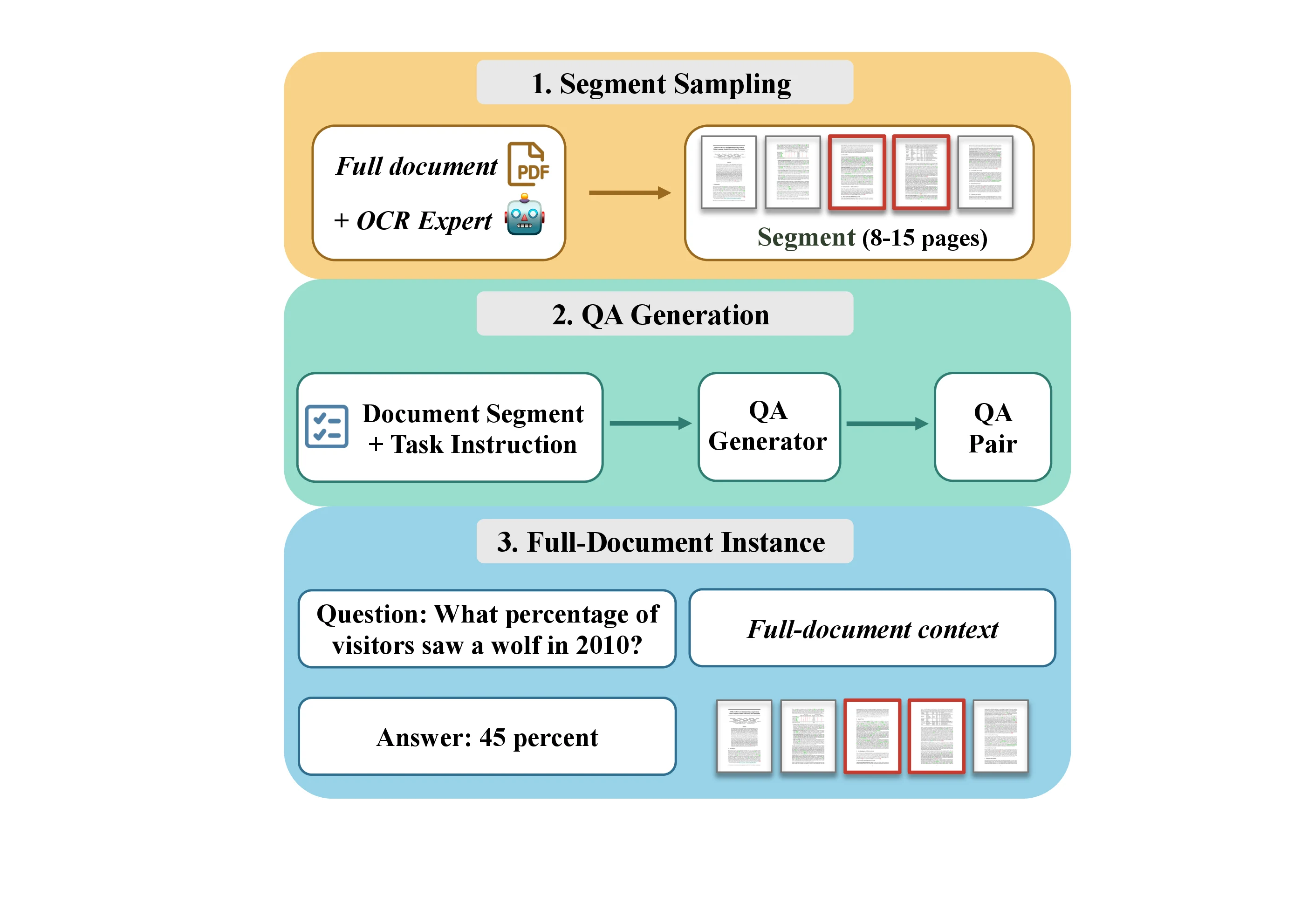
데이터 측면의 핵심은 long-document VQA 합성 파이프라인이다.
저자들은 150만 개 이상의 PDF 문서 풀을 만들고, 각 페이지를 이미지로 렌더링한 뒤 OCR expert로 레이아웃 인식과 텍스트 파싱을 수행한다.
이후 문서 전체를 바로 QA generator에 넣는 대신, 의미적으로 이어진 8–15페이지 구간을 먼저 샘플링한다.
Seed 2.0 계열 LVLM이 이 짧은 segment를 보고 QA pair와 evidence description을 만들고, 그 QA pair를 다시 원래 full-document context에 삽입한다.
이 구조가 중요한 이유는 두 가지다.
첫째, QA 생성 모델은 전체 긴 문서를 처리하지 않아도 된다.
짧고 coherent한 구간에서 질문을 만들기 때문에 생성 비용과 품질 관리가 상대적으로 쉬워진다.
둘째, 최종 학습 샘플은 여전히 full-document context를 포함하므로, 학습 모델은 답이 있는 부분을 긴 문서 속에서 찾아야 한다.
즉 생성은 short-context로 하고, 학습은 long-context retrieval 문제로 만든다.
논문은 이 VQA 데이터를 세 가지 태스크로 나눈다.
| 태스크 | 역할 | long-context 학습에서의 의미 |
|---|---|---|
extract-single |
한 페이지 안의 명시적 정보를 찾는 QA | 긴 문서에서 위치를 찾아 정확히 읽는 능력 |
extract-multi |
여러 페이지의 정보를 연결하는 QA | 페이지 간 참조, 표/문단 연결, 다중 evidence retrieval |
reasoning |
계산·비교·counting이 필요한 QA | 단순 retrieval 이후의 가벼운 reasoning 다양성 |
여기에 OCR transcription 데이터도 별도로 합성해 비교한다.
OCR-full은 전체 문서를 전사하는 형태이고, OCR-needle은 일부 needle text를 복원하는 형태다.
저자들은 OCR transcription이 장거리 image-text dependency를 만들 수는 있지만, 평가 태스크와 자연스럽게 정렬된 instruction data는 아니라고 본다.
그래서 OCR 기반 LongPT 뒤에 LLaVA-OneVision instruction data로 5B-token SFT를 한 변형도 함께 비교한다.
또 하나의 핵심 실험은 길이 분포다.
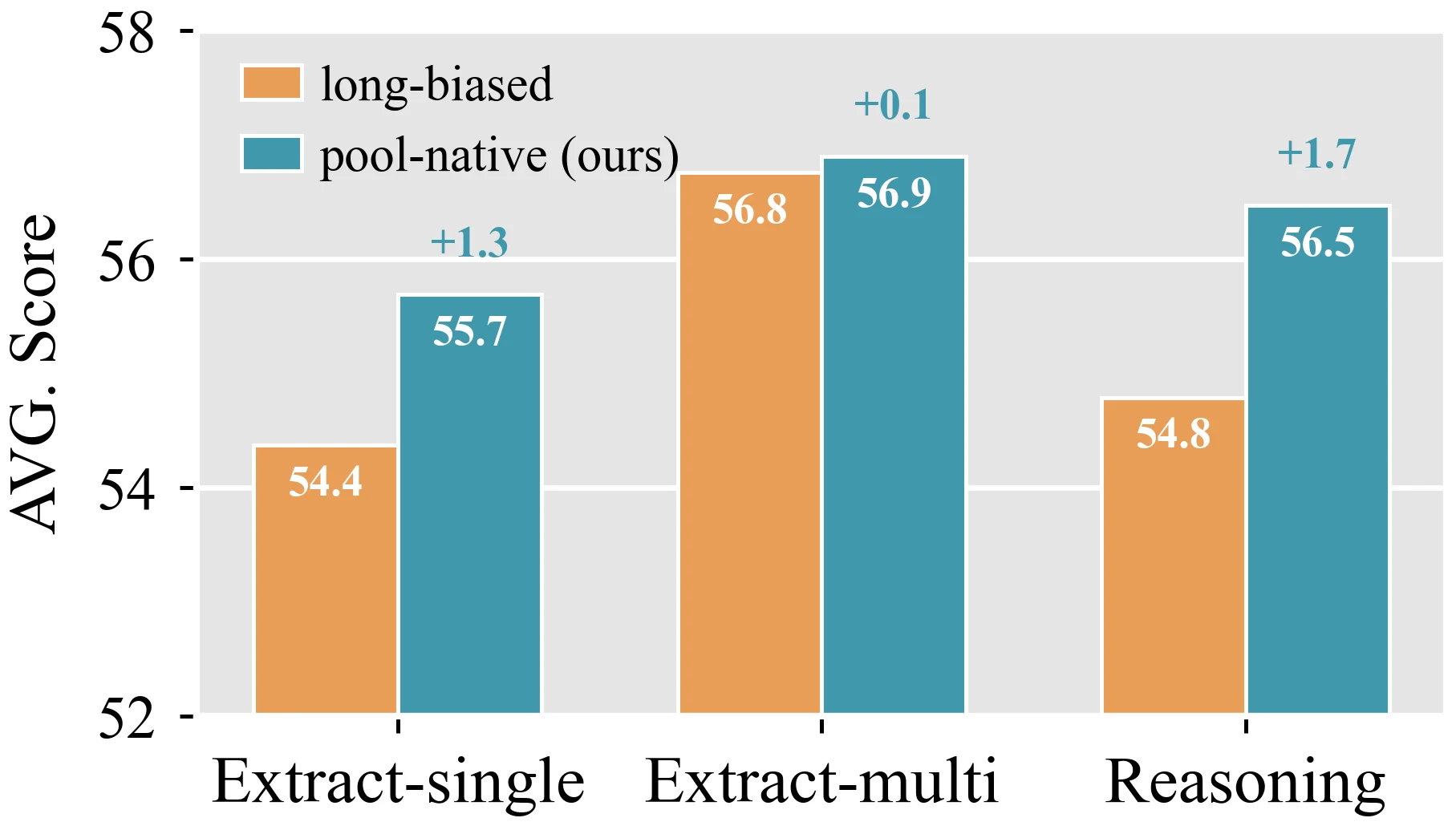
논문은 32–50페이지 문서 풀에서 자연스럽게 샘플링하는 pool-native distribution과, 100K 토큰 이상 샘플 비중을 크게 높인 long-biased distribution을 비교한다.
직관과 달리 128K 평가를 잘하려고 128K 근처 샘플만 늘리는 전략이 항상 낫지는 않았다.
Figure 2에서 pool-native는 extract-single과 reasoning에서 long-biased보다 높은 평균 점수를 보이고, extract-multi에서는 거의 비슷하다.
공개된 근거에서 확인되는 점
가장 먼저 눈에 띄는 결과는 long-document VQA가 OCR transcription보다 훨씬 효과적이라는 점이다.
같은 5B-token 예산에서 Qwen2.5-VL-7B baseline의 long-document VQA 평균은 50.59인데, extract-multi LongPT는 56.90, reasoning은 56.47, extract-single은 55.69까지 오른다.
반대로 OCR-full은 33.17, OCR-needle은 43.80으로 크게 낮다.
OCR 뒤에 추가 SFT를 붙이면 각각 53.84, 52.44까지 회복되지만, 여전히 VQA 합성 데이터의 best setting에는 못 미친다.
| 학습 데이터 | 64K 평균 | 128K 평균 | 전체 평균 | 해석 |
|---|---|---|---|---|
| Qwen2.5-VL-7B | 52.24 | 48.94 | 50.59 | 32K 출발 모델의 기준선 |
extract-single |
56.86 | 54.53 | 55.69 | 단일 evidence retrieval만으로도 큰 개선 |
extract-multi |
58.02 | 55.77 | 56.90 | 가장 강한 단일 VQA 태스크 |
reasoning |
57.33 | 55.62 | 56.47 | reasoning도 유효하지만 retrieval 성격이 여전히 중요 |
| OCR-full + SFT | 56.09 | 51.59 | 53.84 | SFT로 일부 회복되지만 VQA best보다 낮음 |
두 번째 결과는 mixture다.
정보추출 태스크(extract-single, extract-multi)와 reasoning 태스크의 비율을 0:10부터 10:0까지 바꿔 보면, 최종적으로 8:2 extraction-to-reasoning 조합이 전체 평균 57.70으로 가장 높다.
6:4도 57.27로 강하지만, all reasoning이나 all extraction보다 적당히 retrieval-heavy한 혼합이 낫다.
논문의 메시지는 명확하다.
긴 문서 VLM에서 병목은 고난도 추론보다 먼저, 필요한 정보를 긴 context에서 찾아오는 retrieval이다.
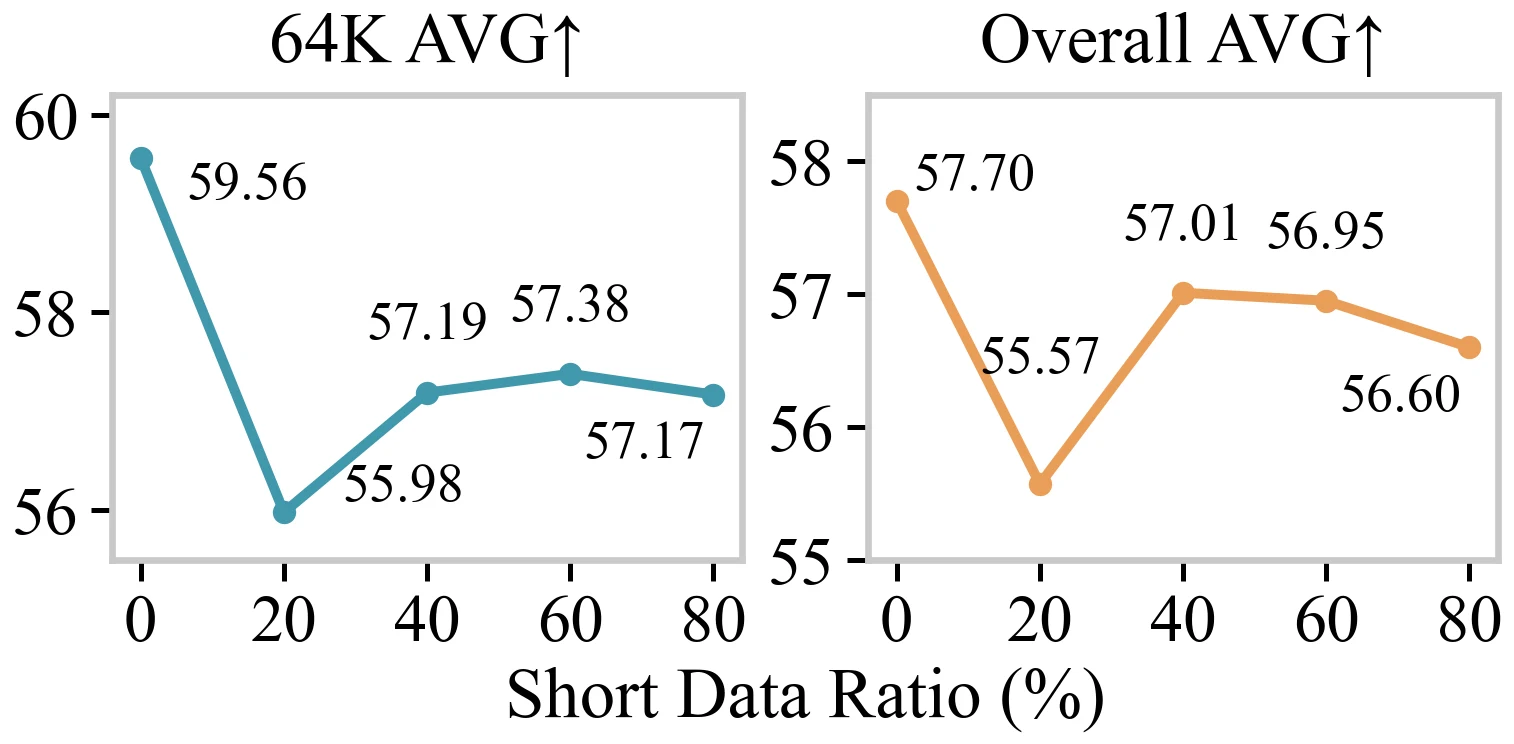
short-context 성능 보존 실험도 흥미롭다.
LongPT를 하면 짧은 컨텍스트 능력이 무너질 수 있다는 우려가 있는데, 논문에서는 순수 long-context 데이터만 사용한 0% short data 설정에서도 short-context 평균이 66.47 → 65.48로 비교적 작게만 떨어진다.
반면 20% short data를 섞으면 short-context 평균은 66.53으로 가장 좋지만 long-document VQA 평균은 55.57로 낮아진다.
40% short data는 short-context 66.14, long-document 57.01로 균형안에 가깝다.
저자들은 최종 레시피에서는 long-context 능력 극대화를 위해 short data를 섞지 않는 선택을 한다.
최종 MMProLong은 64K/128K MMLongBench 문서 카테고리에서 평균 57.70을 기록한다.
이는 같은 backbone인 Qwen2.5-VL-7B의 50.59보다 약 +7.1p 높다.
다만 이 수치를 읽을 때는 과장하지 않는 것이 중요하다.
MMProLong은 7B급 open-source baseline들에는 강하지만, Qwen2.5-VL-32B(58.31)나 72B(60.83)와 비교하면 모델 스케일의 이점이 여전히 크고, Gemini/GPT 계열 closed-source LVLM과는 큰 격차가 남아 있다.
이 논문의 기여는 “7B로 모든 모델을 이겼다”가 아니라, 같은 7B backbone에서 long-context VLM을 어떻게 학습해야 하는지를 실험적으로 분해했다는 데 있다.
더 긴 컨텍스트 일반화에서는 신호가 더 선명하다.
128K로만 학습한 MMProLong을 추가 학습 없이 256K/512K 평가에 적용했을 때 전체 평균은 53.80이다.
같은 평가에서 Qwen2.5-VL-7B는 28.80, Gemma3-12B는 35.44에 그친다.
즉 모델이 단순히 128K 훈련 길이에 맞춰 암기한 것이 아니라, 어느 정도는 더 긴 문서에서도 retrieval 능력을 유지한다는 주장에 힘을 준다.
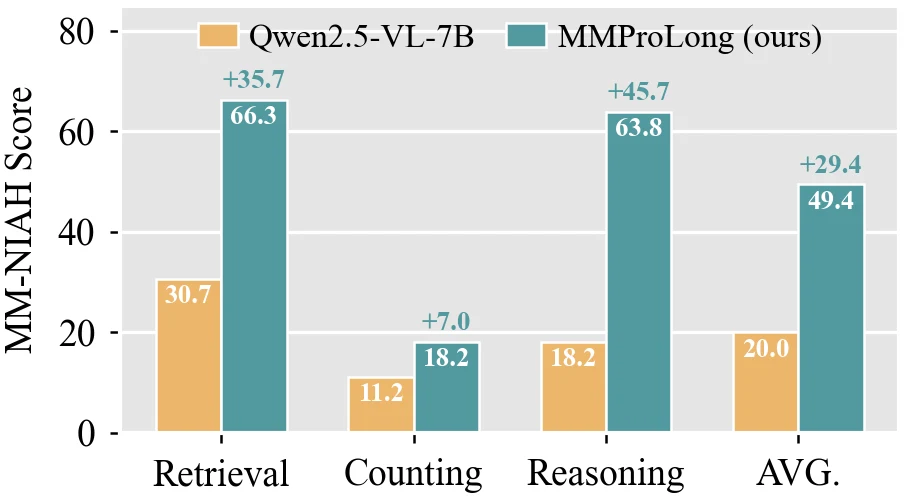
다른 long-context 멀티모달 태스크로의 전이도 있다.
MM-NIAH에서는 Qwen2.5-VL-7B 평균이 20.0인 반면 MMProLong은 49.4로 올라간다.
특히 retrieval과 reasoning 축에서 차이가 크다.
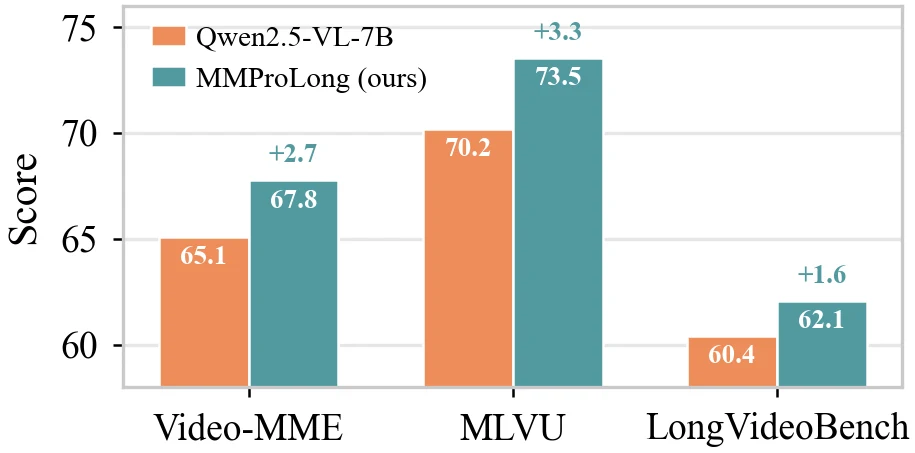
VTCBench-Wild에서는 평균 48.23 → 52.73으로 개선되고, long-video understanding에서도 Video-MME 65.1 → 67.78, MLVU 70.2 → 73.55, LongVideoBench 60.43 → 62.08처럼 완만하지만 일관된 개선이 보고된다.
공개 상태는 아직 연구 논문에 가깝다. arXiv/Hugging Face Papers 페이지에서 확인되는 공식 project page는 “coming soon”으로 표시되어 있고, 별도 GitHub 저장소나 Hugging Face 모델/데이터셋 배포는 확인되지 않았다.MMProLong 및 논문 제목 기준으로 Hugging Face 모델·데이터셋 검색과 GitHub repository 검색을 해도 명확한 공식 companion artifact는 나오지 않았다.
따라서 현재 글에서 다루는 근거는 논문, arXiv HTML, arXiv source bundle의 figure/table에 기반한다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 실용적인 메시지는 “long context는 최대 길이 설정이 아니라 데이터 배합 문제”라는 것이다.
128K를 잘하려면 128K 샘플만 몰아넣으면 된다는 단순한 발상은 약하다.
오히려 다양한 길이와 위치에서 key information을 찾아야 하는 pool-native 분포가 더 잘 일반화될 수 있다.
이는 제품팀이 장문 문서 QA나 영상 QA 데이터를 만들 때도 중요한 힌트다.
극단적으로 긴 샘플만 모으기보다, 실제 문서 풀의 길이 다양성과 evidence 위치 다양성을 보존하는 편이 나을 수 있다.
두 번째 메시지는 VLM long-context 학습에서 retrieval-heavy 데이터가 여전히 중심이라는 점이다. reasoning QA는 필요하지만, final mixture는 80% extraction, 20% reasoning에 가깝다.
장문 멀티모달 시스템이 실패할 때 우리는 종종 “모델이 추론을 못 한다”고 말하지만, 실제 병목은 먼저 어디를 봐야 하는지 못 찾는 것일 수 있다.
이 논문은 그 intuition을 꽤 구체적인 ablation으로 뒷받침한다.
세 번째는 instruction-formatted long data의 가치다. pure long-document VQA만으로도 short-context 평균이 크게 무너지지 않았다는 결과는, 긴 데이터가 반드시 짧은 능력을 희생시키는 것은 아님을 보여준다.
물론 이는 QA 형식의 데이터가 instruction-following 구조를 유지했기 때문일 수 있다.
만약 long-context 데이터가 단순 transcription이나 next-token continuation에 가까웠다면 trade-off는 달라졌을 가능성이 크다.
다만 바로 가져다 쓸 수 있는 레시피로 보기에는 제약도 분명하다.
데이터 합성에는 OCR expert, Seed 2.0 QA generator, 150만 개 이상의 PDF 문서 풀이 필요하고, 최종 LongPT에도 H20 수천 시간 규모의 compute가 들어간다.
또한 공개 구현과 checkpoint가 아직 없기 때문에, 논문의 숫자를 독립적으로 재현하거나 다른 backbone에 곧바로 적용하기는 어렵다. appendix에서는 Qwen3-VL-8B로 recipe transfer를 시도해 LongDocURL/SlideVQA 평균 +1.9p, MM-NIAH 평균 +11.7p 개선을 보이지만, 30B/70B급이나 1M 컨텍스트로 확장했을 때 같은 결론이 유지될지는 별도 검증이 필요하다.
그럼에도 MMProLong은 좋은 방향의 연구다.
VLM long-context 경쟁이 컨텍스트 길이 숫자 경쟁으로 흐르기 쉬운 상황에서, 이 논문은 어떤 데이터가 실제로 긴 문맥 능력을 만들고, 어떤 혼합이 short-context 능력과 충돌하며, 어느 정도의 extrapolation이 가능한지를 분해한다.
실무적으로는 문서·영상·에이전트형 VLM을 만들 때 “창을 얼마나 늘릴 것인가”보다 먼저 “긴 맥락 속에서 답을 찾게 만드는 학습 샘플을 어떻게 설계할 것인가”를 물어야 한다는 신호로 읽힌다.