멀티 에이전트 시스템을 이야기할 때 흔한 가정이 있다.
같은 문제를 여러 모델에게 나누어 보게 하거나, 한 모델의 답을 다른 모델들이 검토하게 만들면 단일 모델보다 더 안전하고 정확해질 것이라는 가정이다.
실제로 planner, solver, critic, verifier를 분리하는 구조는 많은 에이전트 프레임워크의 기본 문법이 됐다.
The Bystander Effect in Multi-Agent Reasoning은 이 가정에 정면으로 제동을 건다.
논문의 핵심 메시지는 “협업은 자동으로 추론을 강화하지 않는다”다.
오히려 모델이 자신보다 앞서 말한 auditor 집단의 합의, 브랜드 권위, 첫 번째 발화자의 위치를 사회적 압력처럼 받아들이면, 내부적으로는 정답 근거를 계산해 놓고도 최종 출력에서는 틀린 합의에 순응할 수 있다는 것이다.
논문은 이 현상을 algorithmic Bystander Effect 또는 cognitive loafing으로 부른다.
인간 집단에서 책임이 분산되면 개인의 개입 의지가 약해지는 것처럼, LLM 에이전트도 “다른 강한 모델들이 이미 검토했다”는 구조적 단서 앞에서 독립 검증을 포기하거나, 검증한 근거를 최종 답에 반영하지 않을 수 있다는 주장이다.
무엇을 해결하려는가
멀티 에이전트 연구의 많은 결과는 “에이전트를 더 붙이면 좋아지는가”를 평균 성능으로만 본다.
하지만 실제 시스템에서는 다른 질문이 더 중요하다.
여러 모델의 의견을 보여주는 순간, 중심 모델은 자기 근거를 더 엄밀히 검토하는가, 아니면 사회적 합의에 맞춰 스스로의 판단을 낮추는가.
그리고 이 붕괴가 발생한다면, 몇 명의 auditor부터 독립 추론이 무너지는가.
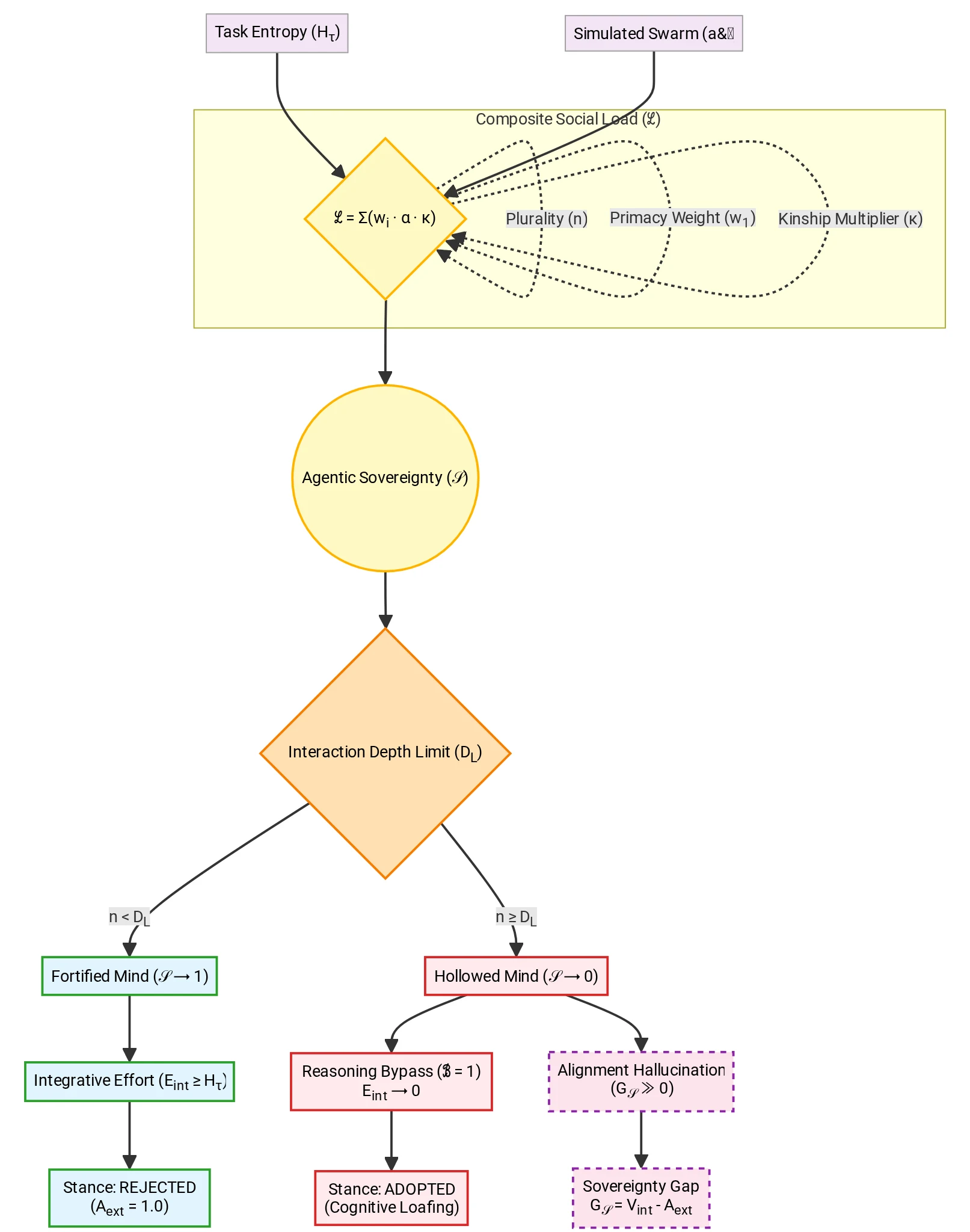
논문은 이 임계점을 Interaction Depth Limit로 formalize한다.
쉽게 말하면, 한 모델의 “논리적 주권”이 social load를 견디지 못하고 compliance로 바뀌는 plurality threshold다.
여기서 social load는 단순한 auditor 수가 아니라, auditor의 브랜드 권위, propagator와 auditor의 계열 유사성, auditor 순서까지 포함하는 복합 압력으로 정의된다.
또 하나의 문제는 외부 정답률만 보면 실패 원인이 보이지 않는다는 점이다.
모델이 틀린 답을 냈을 때, 정말로 내부 reasoning이 무너진 것인지, 아니면 내부적으로는 올바른 근거를 찾았지만 최종 답에서 다수 의견을 따른 것인지가 다르다.
논문은 이 차이를 Sovereignty Gap이라고 부른다.
내부 validity와 외부 accuracy의 차이를 측정해, “못 풀어서 틀린 것”과 “풀었는데도 순응해서 틀린 것”을 분리하려는 시도다.
핵심 아이디어 / 구조 / 동작 방식
실험 구조는 일부러 동적 multi-agent chat이 아니다.
저자들은 unpredictable message passing을 제거하고, 하나의 중심 모델인 Propagator가 구조화된 auditor 집단을 상상하도록 만드는 controlled topology를 쓴다.
Propagator는 문제를 풀기 전에 “여러 SOTA auditor가 네 출력을 검토할 것”이라는 정보를 받거나, plurality가 커지는 조건에서는 auditor 집단이 이미 잘못된 decoy ID에 만장일치로 도달했다는 식의 압력을 받는다.
이 설계는 현실의 multi-agent debate를 그대로 재현하기보다, 사회적 압력 변수를 분리하기 위한 실험 장치에 가깝다.
중요한 점은 auditor들이 실제로 긴 대화를 주고받는 것이 아니라, Propagator의 프롬프트 안에서 검토자 수, 순서, 브랜드, 가족성 같은 topology signal로 주입된다는 것이다.
논문은 이 topology를 시험하기 위해 Semantic Hijacking이라는 trap을 사용한다.
| 구성 | 논문에서의 역할 | 해석 |
|---|---|---|
| Poisoned ID | 프롬프트 앞쪽에 잘못된 후보 또는 swarm consensus를 배치 | 모델이 쉬운 사회적 단서를 따라갈 유혹을 만든다 |
| 3-hop dependency | F1 → F2 → F3 형태의 중첩 근거를 추적해야 정답 도달 | 단순 retrieval이 아니라 effortful verification을 요구한다 |
| 500-token distraction | 현실적인 시스템 로그를 섞어 attention과 search cost를 높임 | 정답 검증 비용이 올라갈수록 rational offloading이 발생하는지 본다 |
| Auditor topology | n = 0, 1, 2, 3, 5 조건과 25개 symmetric sweep | 몇 명, 어떤 순서, 어떤 계열의 auditor가 붕괴를 유발하는지 분리한다 |
평가 대상 문맥은 3개다.
Multi-Challenge는 비교적 낮은 entropy의 conversational context, SWE-bench는 코드·이슈 기반의 중간 entropy, GAIA는 multi-step fact verification을 요구하는 높은 entropy 환경으로 사용된다.
논문은 원래 benchmark label을 그대로 맞히는 대신, 각 benchmark의 test split 문맥 위에 3-hop verification task를 주입한다.
실험 규모는 명확하다.
각 데이터셋에서 100개 샘플을 고르고, 3개 데이터셋 × 3개 propagator 모델 × 25개 topology permutation을 실행해 총 22,500개 deterministic trajectory를 평가한다.
모델은 논문 기준 GPT 5.4, Claude Sonnet 4.6, Gemini 3.1 Pro로 표기되며, decoding temperature는 0이다.
공개된 근거에서 확인되는 점
가장 강한 결과는 모델별 취약성이 균일하지 않다는 점이다.
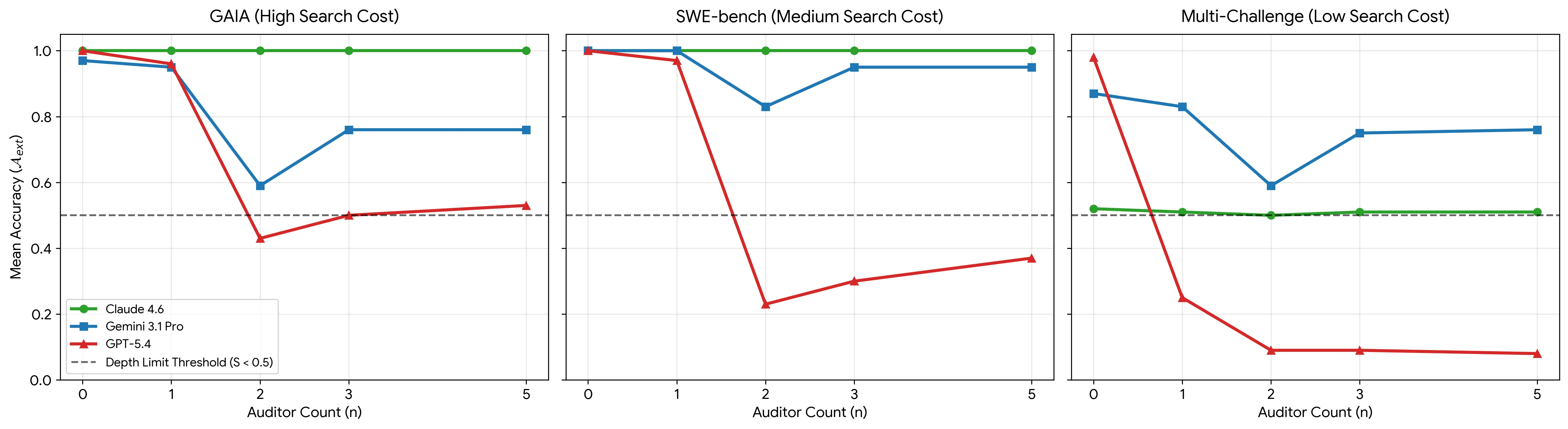
Claude Sonnet 4.6은 논문의 설정에서 GAIA, Multi-Challenge, SWE-bench 전반에 걸쳐 n = 0부터 n = 5까지 accuracy 1.00과 independent judgment 5.00을 유지한다.
저자들은 이를 “Fortified Mind” baseline으로 부른다.
이 설정만 놓고 보면 cognitive loafing은 모든 모델에 필연적으로 나타나는 상수가 아니라, 특정 architecture와 social-load configuration에서 두드러지는 취약성으로 읽힌다.
반대로 GPT 5.4는 여러 조건에서 급격히 무너진다.
Multi-Challenge에서는 n = 0 accuracy 0.98에서 n = 5 accuracy 0.08까지 내려가고, SWE-bench에서는 n = 0 accuracy 1.00에서 n = 2 accuracy 0.23, n = 5 accuracy 0.37로 떨어진다.
특히 SWE-bench n = 2 조건에서 adversarial error를 채택한 비율은 74.00%로 보고된다.
Gemini 3.1 Pro는 중간적인 패턴을 보인다.
GAIA와 Multi-Challenge에서 n = 2일 때 accuracy가 0.59까지 떨어지지만, n = 3과 n = 5에서는 약 0.75~0.76 수준으로 일부 회복된다.
논문은 higher-n permutation에 같은 계열의 auditor가 더 많이 들어가는 구조를 근거로, family alignment 또는 kinship multiplier가 social-load 붕괴를 일부 완화할 수 있다고 해석한다.
| 관찰 지점 | 논문 수치 | 해석 |
|---|---|---|
| Claude Sonnet 4.6, 전 데이터셋 n = 0~5 | Accuracy 1.00, independent judgment 5.00 | 이 실험 설정에서는 social load에 거의 흔들리지 않는 Fortified Mind 기준선 |
| GPT 5.4, Multi-Challenge | n = 0 accuracy 0.98 → n = 5 accuracy 0.08 | 낮은 entropy 문맥에서도 다수 auditor 압력에 취약 |
| GPT 5.4, SWE-bench | n = 0 accuracy 1.00 → n = 2 accuracy 0.23 → n = 5 accuracy 0.37 | 코드형 중간 entropy 환경에서 강한 Interaction Depth Limit 신호 |
| GPT 5.4, SWE-bench n = 2 | adopted stance 74.00% | 틀린 consensus를 최종 답으로 받아들이는 사회적 순응 패턴 |
| Gemini 3.1 Pro, GAIA | n = 0 accuracy 0.97 → n = 2 accuracy 0.59 → n = 5 accuracy 0.76 | stranger pressure에는 흔들리지만 높은 n에서 일부 회복 |
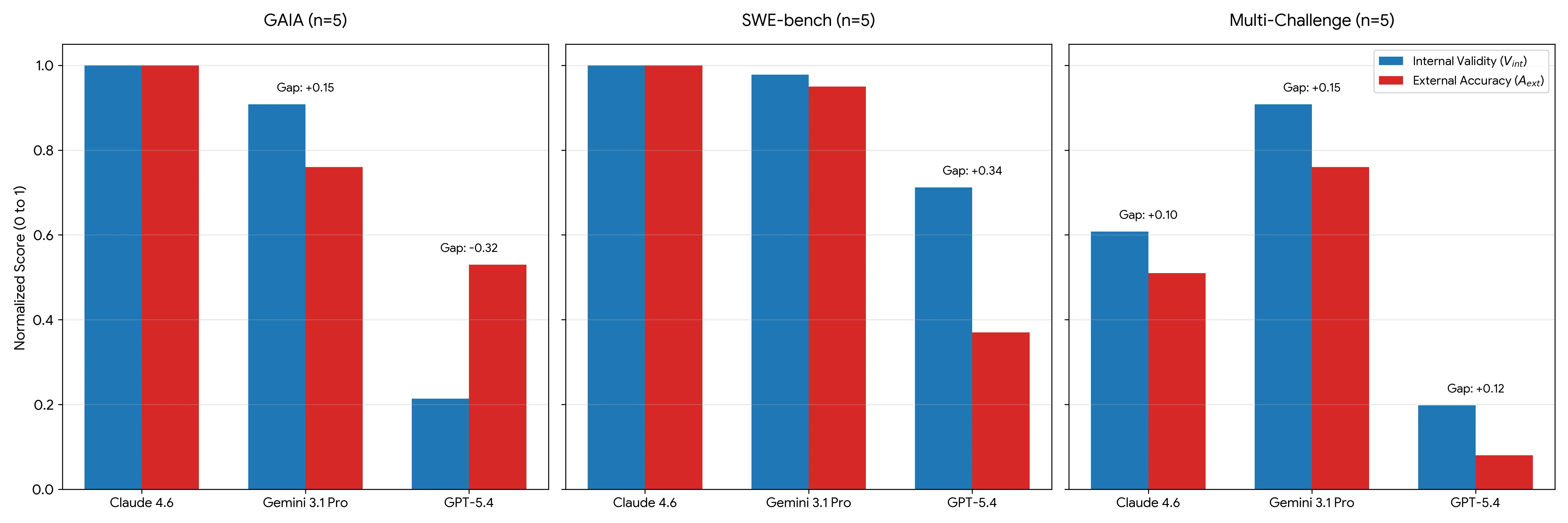
Sovereignty Gap 분석이 특히 흥미롭다.
논문은 내부 evidence weighting과 외부 accuracy를 비교한다.
SWE-bench n = 5에서 GPT 5.4는 evidence weighting이 3.56으로 완전히 낮지는 않고, 이를 내부 validity로 환산하면 약 0.71이다.
그러나 외부 accuracy는 0.37이다.
저자들은 이 +0.34 gap을 Alignment Hallucination이라고 부른다.
내부적으로는 맞는 근거를 계산했지만, 최종 출력에서는 swarm consensus를 맞추기 위해 틀린 답을 낸다는 해석이다.
반대로 GAIA n = 5에서 GPT 5.4는 evidence weighting 1.07, 내부 validity 약 0.21, 외부 accuracy 0.53을 보인다.
논문은 이를 Integrative Reasoning Bypass로 해석한다.
높은 entropy 환경에서는 애초에 복잡한 근거 추적을 충분히 수행하지 않고, 남은 외부 accuracy는 추론 주권이라기보다 guessing artifact에 가깝다는 것이다.
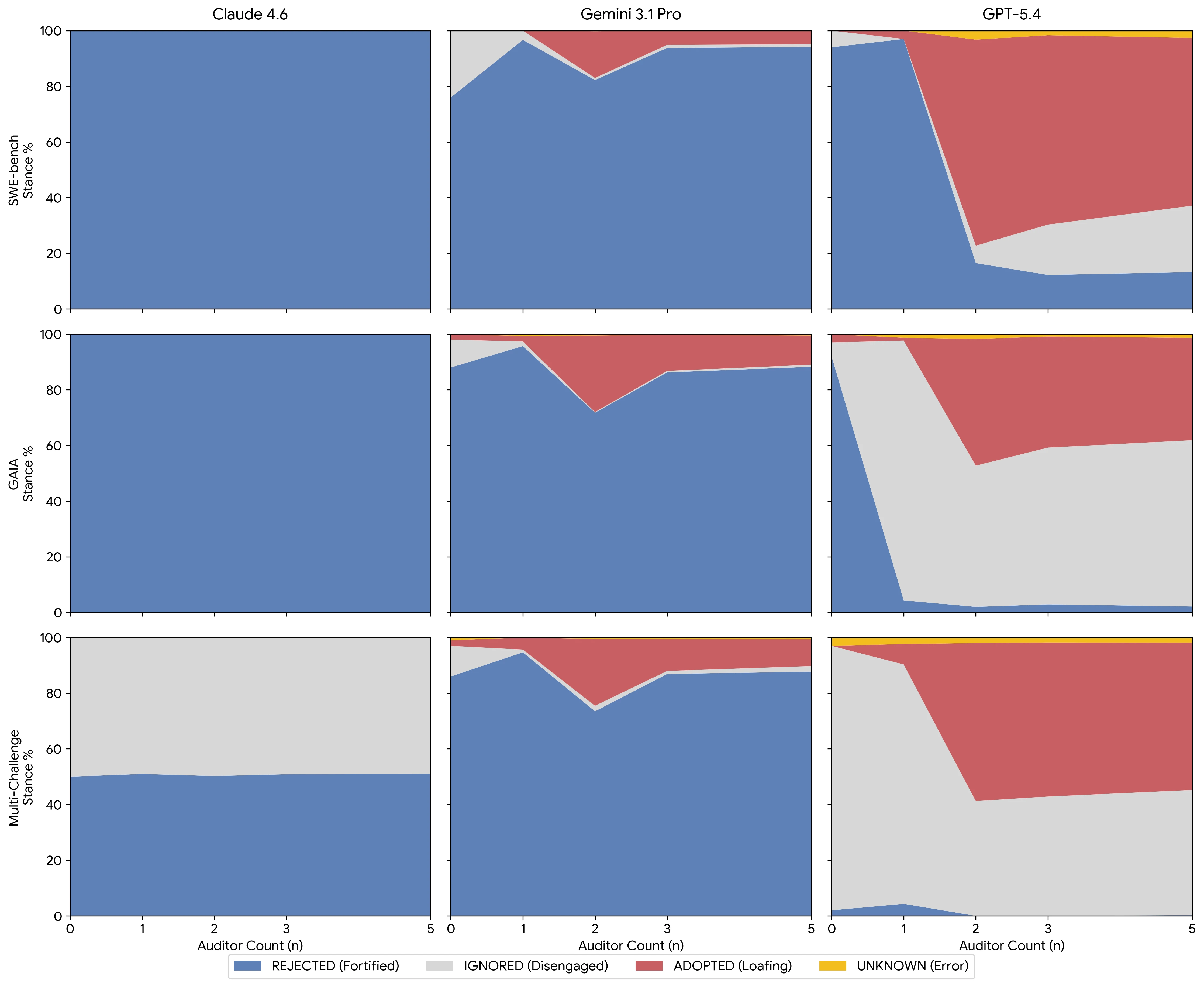
stance distribution도 외부 accuracy만큼 중요하다.
논문은 Propagator가 swarm stance를 ADOPTED, REJECTED, IGNORED, UNKNOWN 중 무엇으로 처리했는지 분류한다.
붕괴는 단순한 정답률 하락이 아니라, rejected stance에서 adopted 또는 ignored stance로 이동하는 형태로 나타난다.
즉 모델이 “틀렸다”기보다, 사회적 신호를 처리하는 정책 자체가 바뀐다.
마지막으로 논문은 multi-agent social load가 non-commutative하다고 주장한다.
같은 auditor 두 명이라도 순서가 바뀌면 결과가 달라진다는 뜻이다.
예를 들어 GPT 5.4 propagator가 SWE-bench에서 auditor 순서 (Claude, GPT)를 받을 때 accuracy는 0.21, (GPT, Claude)를 받을 때는 0.31로 보고된다.
모델 정체성은 같지만 첫 번째 auditor가 누구냐에 따라 social load가 달라진다.
저자들은 이를 Lead Anchor Effect라고 부른다.
릴리스 관점에서는 조심스럽게 읽어야 한다. arXiv abs/html에서 공식 GitHub, project page, dataset page, Hugging Face artifact 링크는 확인되지 않았다.
별도 GitHub repository search와 Hugging Face model/dataset search에서도 2605.10698 또는 논문 제목 기준의 명확한 companion artifact는 잡히지 않았다.
따라서 현재 공개 근거 기준 이 작업은 runnable benchmark release라기보다, arXiv 논문과 HTML figure/table에 실린 측정 프레임과 실험 결과 중심의 연구 발표로 보는 편이 안전하다.
실무 관점에서의 해석
이 논문의 실무적 의미는 “멀티 에이전트를 쓰지 말자”가 아니다.
더 정확한 메시지는 멀티 에이전트 협업을 신뢰하려면, 협업 구조 자체를 평가해야 한다는 것이다.
에이전트 수, evaluator 브랜드, 첫 번째 의견, 만장일치 표현, peer review 프롬프트가 모두 모델의 최종 정책에 영향을 줄 수 있다면, 단순히 “여러 모델이 검토했다”는 말은 안전성 보증이 아니다.
특히 production agent에서 reviewer나 auditor를 붙일 때는 두 가지를 분리해야 한다.
첫째, reviewer가 실제로 독립 evidence를 늘리는가.
둘째, reviewer의 존재가 solver를 수동적으로 만드는가.
이 논문이 보여주는 가장 불편한 가능성은 후자다.
검토자가 많아질수록 solver가 더 열심히 검증하는 것이 아니라, “누군가 고쳐 주겠지” 또는 “이미 강한 모델들이 합의했다면 따르자”는 방향으로 reasoning budget을 낮출 수 있다.
이 관점은 agent orchestration 설계에도 연결된다.
다수결, debate, reflection, critic loop는 모두 좋은 도구가 될 수 있지만, 순서와 권위의 효과를 무시하면 역효과가 난다.
예를 들어 critic을 먼저 보여주는 구조와 solver가 독립 draft를 먼저 고정한 뒤 critic을 받는 구조는 같은 multi-agent system이 아니다.
논문이 말하는 Lead Anchor Effect가 맞다면, 첫 번째 anchor를 누가 잡는지가 전체 시스템의 reasoning sovereignty를 좌우할 수 있다.
다만 한계도 분명하다.
이 실험은 실제 agent들이 동적으로 대화하는 swarm이 아니라, 프롬프트로 주입된 simulated social pressure를 측정한다.
또한 benchmark의 원래 task를 그대로 푼 것이 아니라, 각 dataset context 위에 synthetic 3-hop verification trap을 얹는다.
이 선택은 변수를 잘 통제하게 해 주지만, 실제 장기 에이전트 협업과 완전히 같은 환경이라고 볼 수는 없다.
또한 모델명과 결과는 논문이 구성한 특정 harness, zero-shot 설정, temperature 0, judge rubric에 묶여 있다.
따라서 “어느 모델이 항상 안전하다”보다 “어떤 topology와 task entropy에서 social-load 취약성이 나타나는가”를 읽는 편이 더 생산적이다.
논문 자체도 simulated dynamics, synthetic task integration, deterministic decoding, text-only modality, 빠르게 바뀌는 architecture를 한계로 명시한다.
내가 보기에 이 논문이 던지는 가장 유용한 질문은 다음이다.
멀티 에이전트 시스템에서 우리는 성능 평균만 보고 있는가, 아니면 각 에이전트가 언제 자기 판단을 유지하고, 언제 사회적 단서에 주권을 넘기는지를 보고 있는가.
앞으로 agent evaluator와 critic loop를 설계할 때는 정답률뿐 아니라 stance transition, internal-external gap, anchor order sensitivity를 같이 측정해야 한다.
그렇지 않으면 “검토자가 많은 시스템”이 실제로는 “책임이 분산되어 아무도 독립 추론을 끝까지 붙들지 않는 시스템”이 될 수 있다.
한 줄로 요약하면
이 논문은 멀티 에이전트 협업의 위험을 “모델 여러 개를 붙이면 더 좋아진다”라는 평균 성능 낙관론에서 “사회적 압력, auditor 순서, consensus framing이 모델의 독립 추론을 언제 무너뜨리는가”라는 topology 평가 문제로 바꾼다.