비디오 생성 모델이 “월드 모델”이라는 이름을 얻으려면, 카메라에 보이는 픽셀을 자연스럽게 이어 붙이는 것만으로는 부족하다.
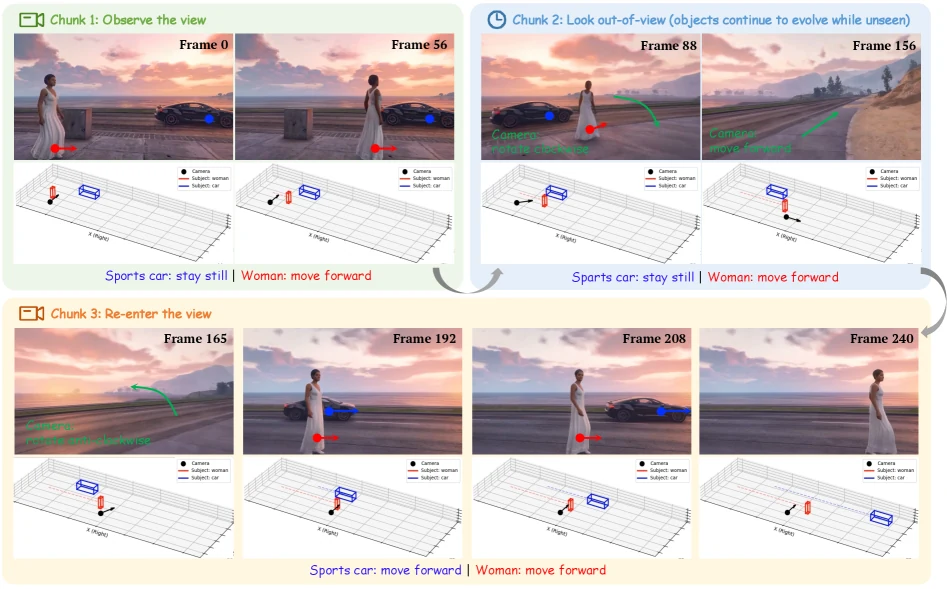
화면 밖으로 나간 사람이 계속 걷고 있는지, 잠시 사라진 자동차가 다시 들어왔을 때 같은 자동차인지, 카메라가 장면을 자유롭게 돌아도 객체의 위치와 정체성이 유지되는지까지 다뤄야 한다.
이런 능력은 논문이 말하는 object permanence와 dynamic object memory에 가깝다.
WorldDirector는 바로 이 문제를 정면으로 잡는다.
HKUST, Ant Group, ZJU, CUHK 연구진의 arXiv 2607.02517 논문과 프로젝트 페이지, GitHub 저장소, Hugging Face 모델 공개 기준으로 이 시스템은 비디오 생성기를 물리·의미 계획까지 알아서 떠안게 하지 않는다.
대신 LLM이 3D 객체 궤적과 카메라 경로를 먼저 계획하고, 그 계획을 2D bounding box 조건으로 투영한 뒤, 별도의 appearance condition과 memory frame을 붙여 causal chunk 단위로 영상을 생성한다.
중요한 점은 이 작업이 논문만 있는 아이디어가 아니라는 것이다.
프로젝트 페이지에는 데모 영상들이 올라와 있고, GitHub pPetrichor/WorldDirector에는 inference code, prompt.txt, LLM_plan.json, 3D bbox 추정·latent 준비·generation 코드가 공개되어 있다.
Hugging Face hlwang06/WorldDirector에는 WorldDirector-14B 가중치와 예제 .pt 데이터가 올라와 있으며, 모델 저장소는 비공개나 gated 상태가 아니다.
다만 라이선스는 코드와 모델 모두 CC BY-NC-SA 4.0 / academic research 목적으로 확인되므로 상업적 활용 전제의 배포물로 보면 안 된다.
무엇을 해결하려는가
기존 장기 비디오 생성 모델은 static scene consistency에는 점점 강해지고 있다.
같은 방, 같은 도로, 같은 배경이 몇 초 이상 이어지는 것은 sliding window, context retrieval, long-video diffusion 기법으로 어느 정도 개선됐다.
하지만 움직이는 객체가 화면 밖으로 나가면 문제가 달라진다.
모델은 그 객체가 계속 움직였는지, 어디에 있어야 하는지, 다시 들어왔을 때 어떤 모습이어야 하는지를 픽셀 관찰 없이 유지해야 한다.
논문은 이 문제를 두 축으로 나눈다.
첫째, independent motion이다.
객체의 궤적은 카메라 시야에 보이는지와 무관하게 연속적인 물리 논리를 따라야 한다.
둘째, strict appearance consistency다.
숨겨졌던 객체가 다시 등장할 때 시각적 정체성과 세부 외형이 그대로 유지되어야 한다.
이 둘이 없으면 월드 모델은 실제 세계를 시뮬레이션한다기보다, 보이는 구간만 그럴듯하게 보간하는 모델에 가깝다.
WorldDirector가 비판하는 기존 접근도 여기서 갈린다.
LiveWorld류의 monitor 기반 방식은 화면 밖 엔티티를 외부 추적기로 관리할 수 있지만, 동적 객체가 많아질수록 비용이 커진다.
HyDRA류의 implicit memory 방식은 짧은 occlusion에서는 작동할 수 있지만, 긴 카메라 diversion이나 복잡한 상호작용에서는 객체가 멈추거나, 궤적이 무너지거나, 재등장 시 정체성이 바뀌기 쉽다.
핵심 아이디어 / 구조 / 동작 방식
WorldDirector의 설계 철학은 semantic motion orchestration과 visual synthesis를 분리하는 것이다.
비디오 생성 모델이 “사람이 화면 밖에서 계속 걸어갔을 것”을 내부 prior로 추측하게 두는 대신, LLM이 먼저 3D 세계 좌표에서 객체와 카메라의 시간별 궤적을 만든다.
그 다음 이 3D bounding box와 camera pose를 2D 화면 좌표로 투영해, 생성 모델이 따라야 할 위치 조건을 명시적으로 제공한다.
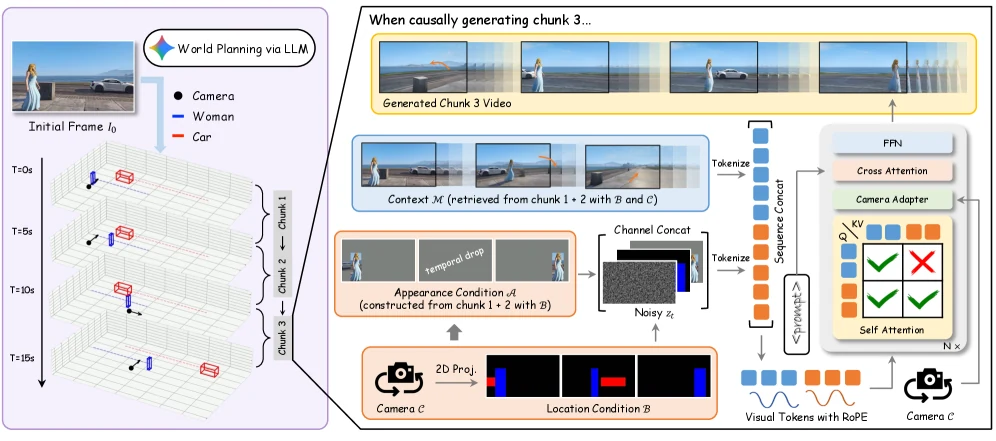
모델이 받는 조건은 크게 네 가지다.Location Condition은 모든 엔티티의 2D bounding box trajectory를 identity-preserving color mask로 표현한다.Appearance Condition은 이전 프레임이나 context frame에서 얻은 sparse RGB object feature를 제공해, 객체가 다시 보일 때 같은 정체성을 유지하도록 한다.Multi-Granularity Prompts는 전체 영상 설명과 개별 객체 행동 설명을 나눈다.Contextual Memory Frames는 정적 배경과 동적 객체를 모두 고려해 선택한 과거 프레임이다.
| 조건 | 논문에서의 역할 | 왜 중요한가 |
|---|---|---|
| Location Condition | 2D bbox를 색상 마스크로 인코딩 | 화면 밖에서도 객체가 어디로 움직여야 하는지 결정론적 위치 제어를 줌 |
| Appearance Condition | 과거/문맥 프레임의 RGB 객체 특징 | 재등장 객체의 옷, 형태, 세부 외형이 새로 샘플링되는 것을 막음 |
| Multi-Granularity Prompts | global prompt + entity별 prompt | 여러 객체가 동시에 움직일 때 의미가 서로 새는 문제를 줄임 |
| Contextual Memory Frames | 정적 장면 + 동적 객체 문맥 검색 | 장기 생성에서 배경과 동적 엔티티의 히스토리를 함께 유지 |
| Camera Injection | Plücker coordinate 기반 카메라 임베딩 | 자유로운 viewpoint exploration을 생성 조건에 직접 반영 |
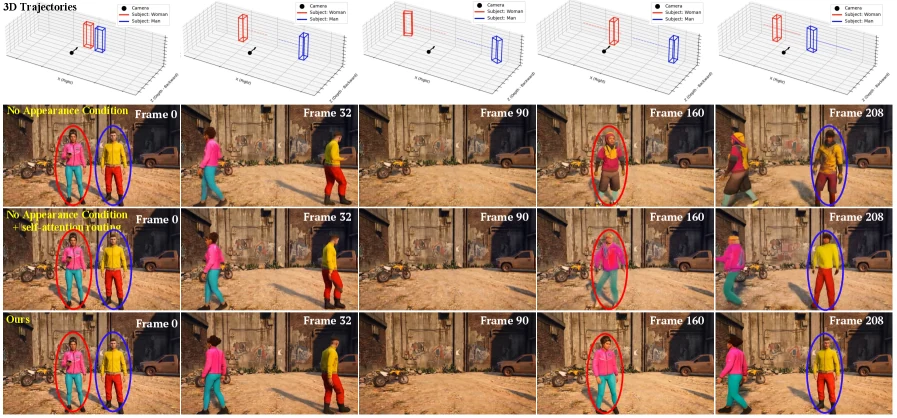
Appearance Condition에는 한 가지 장치가 더 붙는다.
저자들은 appearance reference를 너무 촘촘하게 넣으면 객체가 자연스럽게 걷거나 변형되는 대신, 같은 appearance patch가 미끄러지듯 이동하는 artifact가 생길 수 있다고 본다.
그래서 객체가 처음 등장한 뒤 16프레임은 조밀하게 유지하고, 이후에는 6프레임 간격으로 sparse하게 남기는 Temporal Drop Mechanism을 둔다. appearance는 정체성 anchor로 쓰되, 실제 자세와 움직임은 궤적과 prompt를 따라 새로 합성하게 만드는 병목이다.
데이터도 이 문제에 맞춰 설계됐다.
논문은 화면 밖으로 나갔다가 다시 들어오는 동적 객체가 충분한 실제 비디오 데이터가 부족하다고 보고, 게임 기반 플랫폼으로 15초 영상을 만들었다고 설명한다.
여기서 5초 training window는 새로 보이는 객체가 최대가 되도록 샘플링하고, 나머지 10초는 appearance와 spatiotemporal context 후보 풀로 사용한다.
SAM3로 2D bbox trajectory를 추출하고, Qwen2.5-VL-72B로 entity-level caption을 만든다.
공개된 근거에서 확인되는 점
실험 설정은 비교적 명확하다.
WorldDirector는 LingBot-World-Base 위에 구축됐고, 학습 비디오는 832×480 해상도, 16fps로 전처리된다. context length는 N=10 프레임이며, 모델은 global batch size 64, learning rate 1e-5, 3,000 step으로 post-training된다.
논문 부록은 64 GPU 분산 설정에서 전체 post-training이 약 72시간, 즉 3일 정도 걸렸다고 적는다.
추론에서는 Gemini가 3D 궤적과 상태를 계획하고, 전체 영상을 5초 segment로 나눠 autoregressive하게 생성한다.
정량 결과에서 WorldDirector의 강점은 reconstruction과 dynamic object consistency 쪽에 선명하다.
논문 Table 1 기준 WorldDirector는 PSNR 18.127, SSIM 0.502, LPIPS 0.359로 비교 모델 대비 가장 높거나 낮은 reconstruction 지표를 낸다.
가장 강한 baseline과 비교해도 PSNR은 HY-World의 14.782보다 +3.345, SSIM은 Yume1.5의 0.455보다 +0.047, LPIPS는 HY-World의 0.398보다 0.039 낮다.
| 방법 | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Subject Consistency ↑ | Background Consistency ↑ | DSC_DINO ↑ | DSC_CLIP ↑ |
|---|---|---|---|---|---|---|---|
| Yume1.5 | 14.391 | 0.455 | 0.425 | 0.898 | 0.919 | 0.765 | 0.898 |
| HY-World | 14.782 | 0.418 | 0.398 | 0.923 | 0.931 | 0.758 | 0.911 |
| Infinite-World | 14.574 | 0.431 | 0.406 | 0.934 | 0.908 | 0.773 | 0.913 |
| HyDRA | 13.421 | 0.352 | 0.439 | 0.855 | 0.902 | 0.632 | 0.877 |
| WorldDirector | 18.127 | 0.502 | 0.359 | 0.891 | 0.909 | 0.769 | 0.917 |
이 표는 한 가지 뉘앙스를 같이 읽어야 한다.
Subject Consistency와 Background Consistency에서는 Infinite-World나 HY-World가 더 높은 항목이 있다.
논문은 이 baseline들이 상대적으로 객체·카메라 motion을 덜 만들기 때문에 VBench류 consistency metric에서 유리할 수 있다고 해석한다.
즉 WorldDirector의 주장은 “모든 coherence 숫자를 압도한다”가 아니라, 더 역동적인 장면을 만들면서도 재등장 객체의 동적 일관성을 유지한다에 가깝다.

Ablation도 이 논문의 핵심 주장을 잘 뒷받침한다.
Appearance Condition을 제거하면 PSNR은 16.764, SSIM은 0.469, DSC_DINO는 0.693, DSC_CLIP은 0.882로 떨어진다. self-attention routing을 추가해도 PSNR 17.461, DSC_CLIP 0.886 수준에 머문다.
완전한 WorldDirector는 각각 18.127, 0.502, 0.769, 0.917이다.
특히 DSC_DINO는 appearance condition이 없을 때보다 +0.076, routing을 붙인 경우보다도 +0.083 높다.
논문은 정적 배경 픽셀이 MSE loss를 지배하기 때문에 작은 동적 객체 영역의 고충실도 identity mapping을 모델이 암묵적으로 배우기 어렵다고 해석한다.
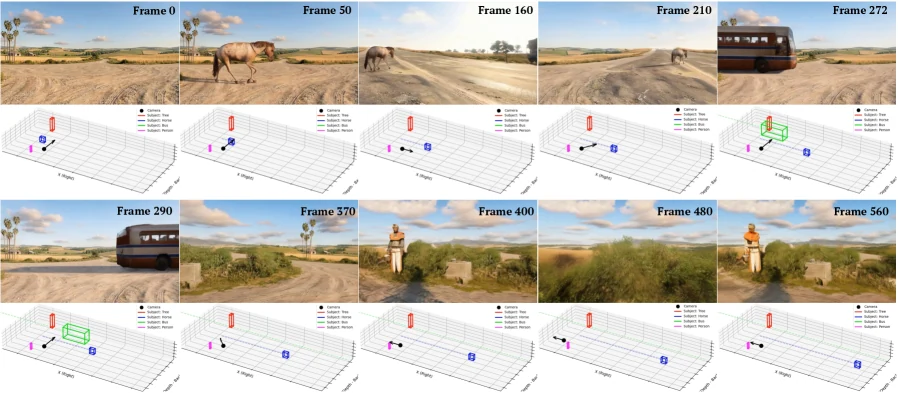
또 하나 흥미로운 기능은 Promptable World Events다.
WorldDirector는 초기 프레임에 이미 있는 객체만 제어하지 않는다.
LLM이 새로운 객체의 정체성, 등장 시점, 3D motion trajectory를 정의하면, 그 객체가 처음 화면에 들어올 때 text prompt에서 appearance와 movement를 합성하고, 이후에는 Appearance Condition pool에 추가해 일관성을 유지한다.
이 설계는 비디오 생성 모델을 단순 extrapolator가 아니라, 사용자가 사건을 설계하는 world simulator 쪽으로 밀어붙인다.
공개 패키징은 연구 재현 쪽에 꽤 적극적이다.
GitHub API 기준 pPetrichor/WorldDirector는 2026-07-02에 생성됐고, 확인 시점에 star 36개, fork 0개, 최신 push는 2026-07-03이다. releases와 tags는 아직 비어 있으며, 루트에는 3D_bbox_infer, worldlatent_prepare, generate, prompt.txt, LLM_plan.json이 있다.
README는 full inference code와 WorldDirector-14B가 released 상태라고 적고, torch 2.4+, FlashAttention, 8-way torchrun, --dit_fsdp, --t5_fsdp 등을 전제로 한 실행 명령을 제공한다.
Hugging Face 모델 저장소 hlwang06/WorldDirector는 public, gated false, disabled false로 확인된다.
API 기준 tags는 diffusers, safetensors, license:cc-by-nc-sa-4.0이고, 저장 용량은 약 160.3GB, 즉 149.3GiB다.
파일 구조에는 weights/ 아래 high-noise/low-noise diffusion model shard, Wan2.1 VAE, UMT5-XXL tokenizer·text encoder, 그리고 WorldDirector_pt_examples/ 아래 fire/walk/woman 예제 데이터가 들어 있다.
모델 카드 본문은 사실상 라이선스 frontmatter만 있어, 실제 사용 지침은 GitHub README 쪽이 더 중요하다.
실무 관점에서의 해석
내가 보기에 WorldDirector의 가장 중요한 메시지는 비디오 월드 모델에서 “기억”을 픽셀 생성기의 내부 상태로만 맡기면 안 된다는 점이다.
장면 밖 동적 객체는 보이지 않기 때문에, 생성 모델이 다음 프레임을 예쁘게 만드는 objective만으로는 위치와 identity를 안정적으로 유지하기 어렵다.
WorldDirector는 이 문제를 LLM 기반 3D planning, deterministic 2D location control, appearance binding, memory retrieval로 쪼갠다.
이는 모델 크기를 더 키우는 방향보다, 어떤 정보를 어떤 표현으로 외부화할지 설계하는 방향에 가깝다.
특히 LLM orchestrator의 역할이 흥미롭다.
여기서 LLM은 최종 영상을 직접 생성하지 않는다.
대신 OpenGL 좌표계, 카메라 intrinsic, 3D bbox, 시간대별 user instruction을 받아 Python code와 3D/2D trajectory 계획을 만드는 world planner로 쓰인다.
생성 모델은 그 계획을 시각적으로 실현한다.
이 분업은 앞으로 interactive video editing, game simulation, robotics synthetic data generation에서 꽤 중요한 패턴이 될 수 있다.
언어 모델은 사건의 논리와 궤적을 짜고, diffusion/DiT 모델은 픽셀 렌더링을 맡는 식이다.
다만 지금 단계의 WorldDirector를 곧바로 범용 제품 시스템으로 해석하면 과하다.
학습 데이터는 게임 기반 synthetic pipeline에서 출발하므로 논문도 domain gap을 제한점으로 인정한다.
실제 영상에서는 얼굴 blur나 부자연스러운 locomotion이 생길 수 있다고 적는다.
실행 측면에서도 14B급 모델, 480P, FlashAttention, FSDP, 8-GPU torchrun 전제를 보면 연구용/고성능 GPU 환경에 가깝다.
GitHub releases와 tags가 비어 있고, HF model card가 매우 얇은 것도 release maturity 측면에서는 아직 초기 신호다.
안전성도 따로 봐야 한다.
논문 부록은 WorldDirector가 LLM orchestrator로 구동되는 highly controllable generative video model이기 때문에, prompt safety filter, generated-video watermarking, content provenance metadata, deployment-time monitoring 같은 외부 safeguard가 필요하다고 말한다.
연구진은 inference code, prompt template, pretrained checkpoint를 학술 연구와 평가 목적으로 staged release하겠다고 적고 있다.
장기적이고 논리적으로 일관된 synthetic scenario를 쉽게 만들 수 있다는 장점은, 동시에 더 설득력 있는 가짜 영상 생성 리스크도 키운다.
그럼에도 WorldDirector는 좋은 방향을 보여준다.
긴 비디오 생성의 다음 경쟁은 “몇 초를 더 생성했는가”가 아니라, 카메라가 보지 않는 동안 세계가 계속 존재했는가에 가까워질 가능성이 크다.
WorldDirector는 이 질문에 대해 꽤 명확한 답을 제시한다.
보이지 않는 객체의 상태를 생성 모델의 암묵적 기억에만 맡기지 말고, 3D 계획·2D 제어·appearance anchor·context memory로 나눠 명시적으로 다루라는 것이다.
그런 의미에서 이 논문은 비디오 생성 모델을 단순한 sequence generator에서 controllable world simulator로 옮기려는 중요한 중간 단계로 읽힌다.