LLM 추론 최적화에서 speculative decoding은 오래전부터 매력적인 아이디어였다.
작은 초안 모델이 여러 토큰을 먼저 제안하고, 큰 타깃 모델이 그 후보를 한 번에 검증하면, 출력 분포를 보존하면서도 토큰당 지연 시간을 줄일 수 있기 때문이다.
문제는 이 기법이 실제로 빨라지려면 “초안 모델이 무엇을 얼마나 잘 제안하느냐”와 “어떤 토큰을 검증에 올릴 것이냐”가 함께 맞아야 한다는 점이다.
DeepSeek이 공개한 deepseek-ai/DeepSpec은 이 지점을 정면으로 다룬다.
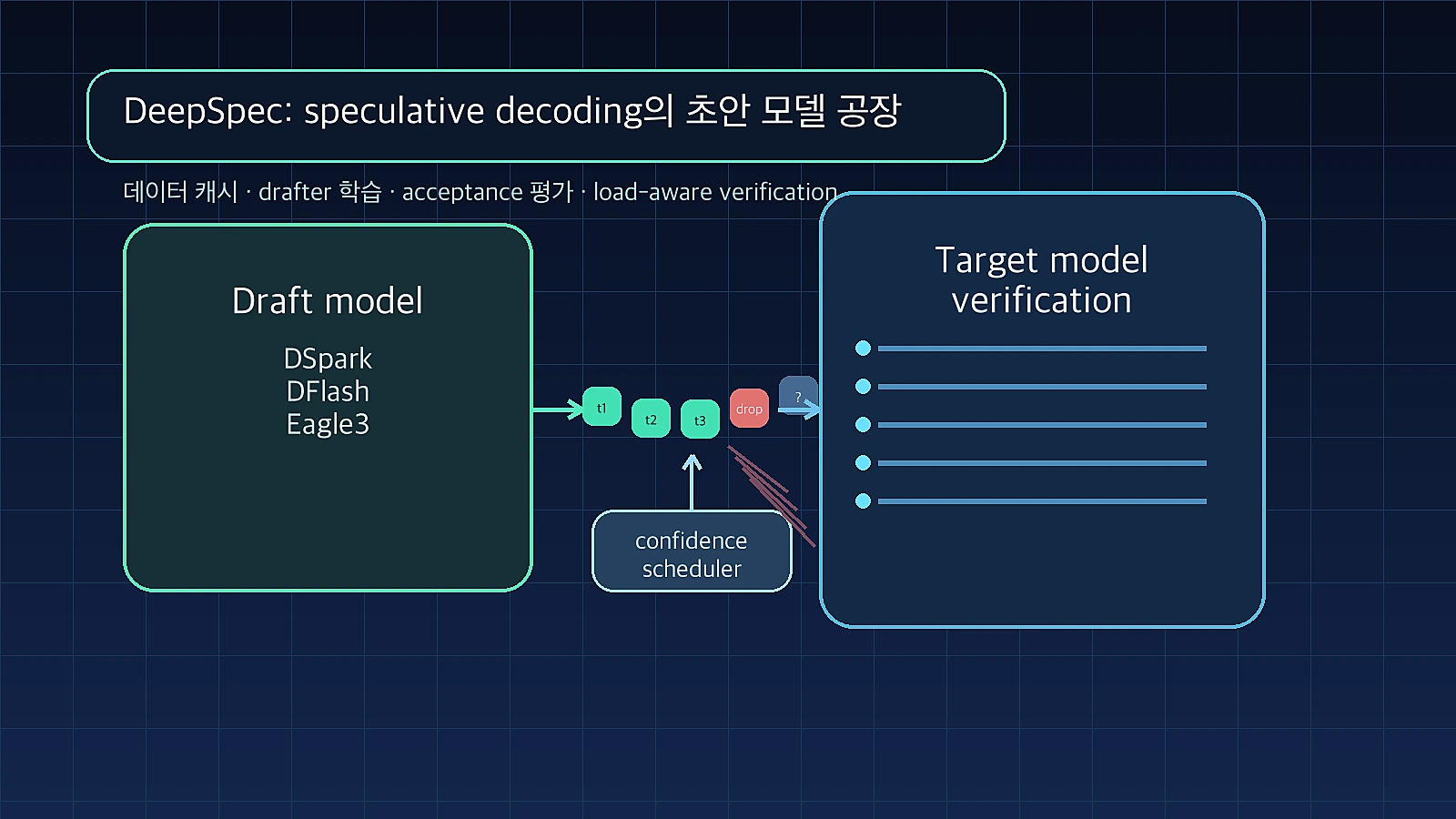
DeepSpec은 새 채팅 모델 하나를 공개한 것이 아니라, speculative decoding용 draft model을 데이터 준비부터 학습, 평가까지 다루는 풀스택 코드베이스다.
저장소는 DSpark, DFlash, Eagle3 세 계열의 초안 모델을 같은 파이프라인 위에 올리고, Qwen3와 Gemma 4 계열 타깃 모델에 대한 공개 체크포인트도 Hugging Face 컬렉션으로 제공한다.
무엇을 해결하려는가
일반적인 autoregressive decoding은 한 번의 forward pass에서 토큰 하나를 만든다.
모델이 커지고 응답이 길어질수록 전체 latency는 출력 길이에 비례해 커진다.
Speculative decoding은 이 병목을 줄이기 위해 작은 draft model이 앞으로 나올 여러 토큰을 미리 제안하게 하고, target model이 그 후보들을 한 번에 검증한다. target이 초안을 받아들이면 한 번의 비싼 검증으로 여러 토큰을 전진할 수 있다.
하지만 draft model을 아무렇게나 길게 만들면 오히려 손해가 난다.
완전 병렬 drafter는 한 번에 긴 후보 블록을 만들 수 있지만, 블록 안의 앞 토큰과 뒤 토큰 사이 의존성을 충분히 반영하지 못하면 뒤쪽 토큰의 acceptance가 빠르게 무너진다.
반대로 autoregressive drafter는 후보 품질은 안정적일 수 있지만, 초안 생성 자체가 다시 순차 병목이 된다.
여기에 serving 시스템 관점의 문제가 더해진다. traffic이 가벼울 때는 낮은 확률의 후보를 조금 더 검증해도 비용이 작지만, 동시 요청이 많은 상황에서는 실패할 가능성이 큰 후보 토큰이 target model batch capacity를 잡아먹는다.
DeepSpec의 가치는 이 둘을 분리해서 볼 수 있게 만든다는 데 있다.
하나는 draft model을 어떻게 학습할 것인가이고, 다른 하나는 생성된 후보 중 무엇을 target verification에 올릴 것인가다.
DeepSpec은 코드와 체크포인트를 통해 이 문제를 재현 가능한 실험 단위로 내려놓는다.
핵심 아이디어 / 구조 / 동작 방식
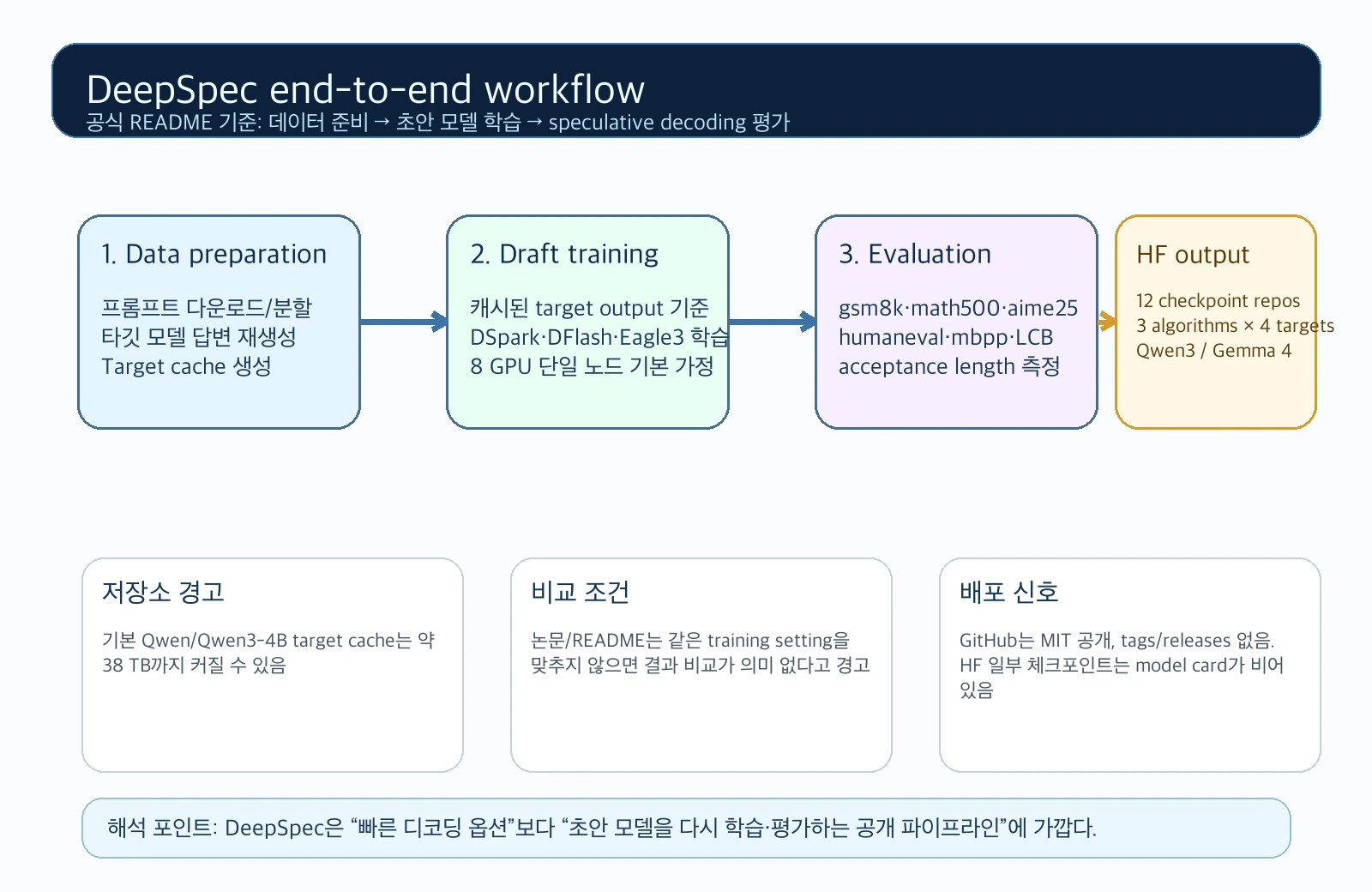
공식 README 기준 DeepSpec의 기본 워크플로우는 세 단계다.
먼저 프롬프트를 다운로드하고 분할한 뒤, target model 답변을 다시 생성해 target cache를 만든다.
그 다음 캐시된 target output을 기준으로 draft model을 학습한다.
마지막으로 학습된 draft checkpoint를 speculative decoding benchmark에서 평가한다.
이 파이프라인에서 중요한 현실 신호는 두 가지다.
첫째, 데이터 준비는 target model을 서빙할 별도 inference engine을 요구한다.
README는 기본 Qwen/Qwen3-4B 설정에서도 target cache가 대략 38 TB까지 커질 수 있다고 경고한다.
둘째, 기본 training script는 보이는 GPU마다 worker를 하나씩 띄우며, 기본 설정은 GPU 8장을 가진 단일 노드를 가정한다.
즉 DeepSpec은 “노트북에서 바로 눌러 보는 데모”라기보다, 초안 모델 학습을 진지하게 반복하려는 팀을 위한 연구·서빙 인프라 코드에 가깝다.
지원 알고리즘은 세 가지다.
| 알고리즘 | DeepSpec에서의 의미 | 해석 |
|---|---|---|
| DSpark | DeepSeek의 DSpark 논문과 연결된 confidence-scheduled speculative decoding 계열 | 긴 draft block과 load-aware verification을 함께 다루는 핵심 축 |
| DFlash | 블록 확산 기반 draft model 설계와 학습 레시피를 반영한 계열 | 병렬 drafter 쪽 baseline이자 비교 대상 |
| Eagle3 | SpecForge 기반 Eagle3 구현을 포함한 계열 | autoregressive draft model 계열의 강한 비교군 |
평가는 eval_datasets/ 아래의 speculative decoding benchmark를 사용한다.
README가 나열한 task는 gsm8k, math500, aime25, humaneval, mbpp, livecodebench, mt-bench, alpaca, arena-hard-v2다.
핵심 지표는 decoding round당 accepted length, 즉 target model 검증 한 번으로 얼마나 많은 draft token을 실제 출력으로 전진시켰는가다.
DSpark가 강조하는 두 층: 더 잘 초안 만들기, 더 똑똑하게 검증하기
DeepSpec README가 연결하는 DSpark 논문(arXiv:2607.05147)은 DSpark를 “Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation”으로 설명한다.
이름 그대로 두 층이 결합돼 있다.
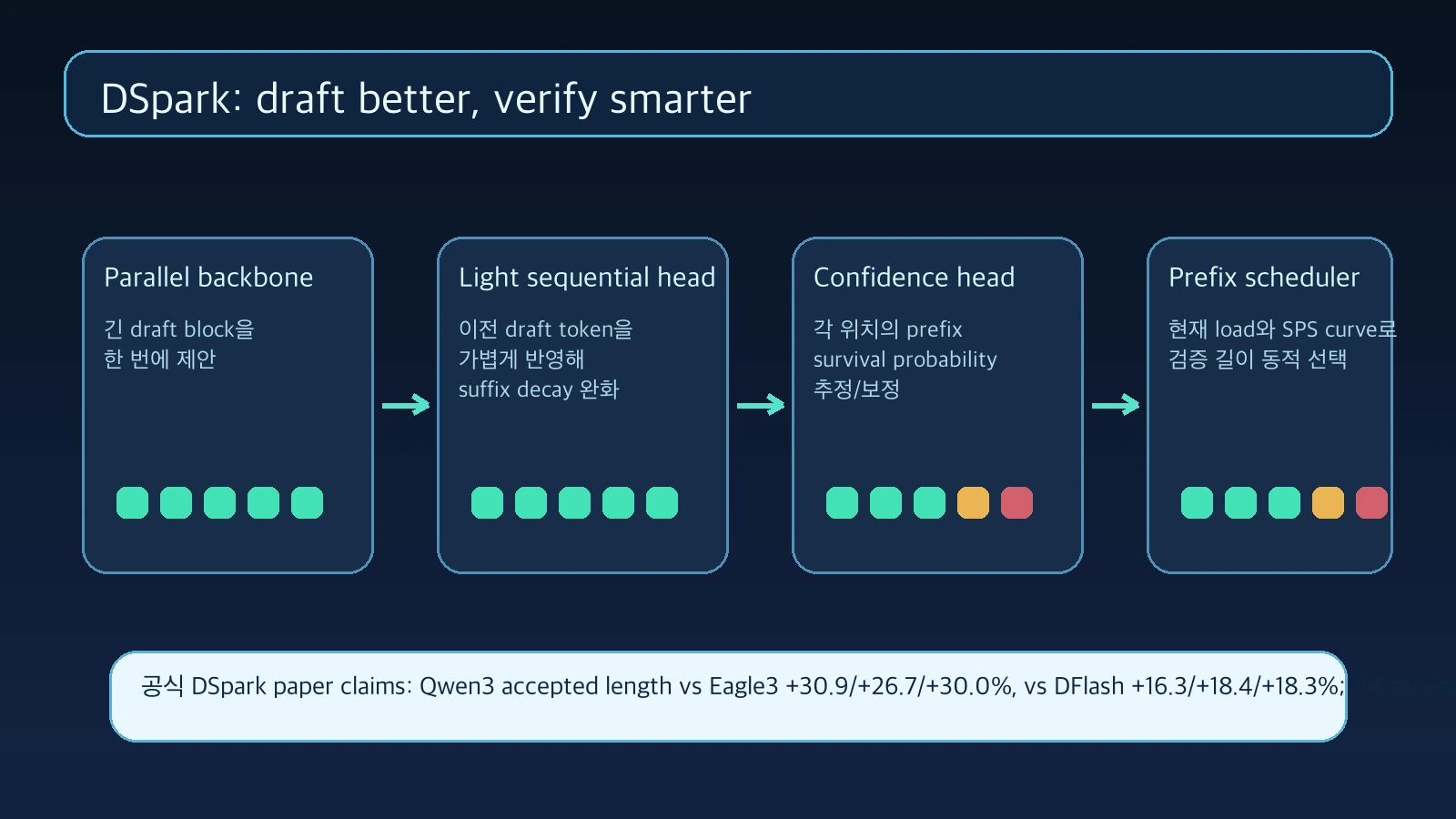
첫째는 semi-autoregressive generation이다.
DSpark는 무거운 draft backbone은 병렬로 유지하되, 가벼운 sequential head를 붙여 block 내부 토큰 의존성을 일부 반영한다.
논문은 병렬 drafter가 “of course”와 “no problem”처럼 여러 가능한 continuation을 섞다가 “of problem” 같은 조합을 만들 수 있다고 설명한다.
DSpark는 Markov head 또는 RNN head 같은 작은 순차 모듈을 통해 앞서 샘플된 draft token이 뒤쪽 token logit에 영향을 주게 만들어 suffix decay를 줄이려 한다.
둘째는 confidence-scheduled verification이다. draft model이 길게 후보를 만들었다고 해서 전부 target model에 올리는 것은 낭비일 수 있다.
DSpark는 각 위치의 조건부 acceptance 확률을 confidence head로 추정하고, 이를 누적 prefix survival probability로 바꾼다.
그 다음 hardware-aware prefix scheduler가 현재 engine throughput profile, 즉 batch size에 따른 steps-per-second curve를 고려해 request별 검증 길이를 고른다.
요지는 target model compute를 “통과할 가능성이 큰 prefix”에 우선 배분하는 것이다.
이 설계는 단순히 “더 긴 draft block을 만들자”가 아니다.
논문은 verifying smarter, not longer에 가깝다. confidence threshold sweep에서는 chat workload처럼 entropy가 높은 영역에서 낮은 가치의 suffix token을 많이 걸러낼 수 있음을 보인다.
또한 production serving 환경에서는 정적인 threshold보다 현재 load를 반영한 scheduler가 중요하다고 주장한다.
공개된 근거에서 확인되는 점
GitHub API와 저장소 내용을 확인한 시점 기준 deepseek-ai/DeepSpec은 2026년 6월 26일 만들어진 공개 Python 저장소이며, MIT 라이선스로 배포된다.
루트에는 LICENSE, NOTICE, README.md, config/, deepspec/, scripts/, train.py, eval.py, eval_datasets/가 있고, DSpark 논문은 arXiv로 연결된다. config/는 dspark, dflash, eagle3로 나뉘며, eval_datasets/에는 수학·코딩·채팅 benchmark JSONL이 들어 있다.
다만 GitHub tags와 releases는 아직 비어 있었다.
따라서 현재 공개 표면은 안정 릴리스 패키지라기보다 빠르게 공개된 연구·훈련 코드베이스로 읽는 편이 안전하다.
Hugging Face 쪽에서는 DeepSpec 컬렉션이 12개 모델 repo를 묶는다.
구성은 세 알고리즘, 즉 Eagle3·DFlash·DSpark와 네 target model, 즉 Qwen/Qwen3-4B, Qwen/Qwen3-8B, Qwen/Qwen3-14B, google/gemma-4-12B-it의 조합이다.
README는 이 checkpoint들이 DSpark paper의 Table 1에 사용된 것이며, 각 target model이 non-thinking mode로 생성한 open-perfectblend 데이터로 학습됐다고 설명한다.
예시로 deepseek-ai/dspark_qwen3_4b_block7 모델 API는 public, non-gated 상태였고, safetensors BF16 파라미터 약 1.393B, 저장 크기 약 2.79GB를 보고했다.
하지만 렌더링된 Hugging Face 페이지에는 “No model card”가 표시됐다.
즉 checkpoint는 공개돼 있지만, 개별 모델 카드 수준의 사용 설명과 제한 사항은 아직 빈약한 편이다.
성능 근거는 DSpark paper에 더 자세히 있다.
논문 초록과 실험 섹션은 Qwen3-4B, 8B, 14B target model에서 DSpark가 macro-average accepted length를 Eagle3 대비 각각 30.9%, 26.7%, 30.0% 개선했고, DFlash 대비 16.3%, 18.4%, 18.3% 개선했다고 보고한다.
DeepSeek-V4 serving 시스템의 live traffic 배포에서는 기존 MTP-1 production baseline 대비, matched aggregate throughput 조건에서 V4-Flash per-user generation speed를 60%–85%, V4-Pro를 57%–78% 높였다고 설명한다.
다만 이 수치를 읽을 때는 비교 기준을 분명히 해야 한다.
60%–85%는 “naive decoding 대비 무조건 그만큼 빨라진다”는 뜻이 아니라, DeepSeek의 기존 MTP-1 production baseline과 matched throughput 조건에서의 per-user speed 비교다.
또 논문은 strict SLA 지점에서 DSpark가 훨씬 높은 aggregate throughput을 보이는 사례도 제시하지만, 그 자체를 일반적인 배수 향상으로 읽기보다 baseline이 효율적으로 버티기 어려운 interactivity frontier를 DSpark가 넓힌 증거로 해석해야 한다.
| 공개 표면 | 확인된 내용 | 실무적 의미 |
|---|---|---|
| GitHub 저장소 | MIT 공개, Python 중심, config/, scripts/, eval_datasets/, DSpark paper 포함 |
초안 모델 학습·평가를 직접 재현할 수 있는 연구 코드베이스 |
| 릴리스 상태 | tags/releases 없음 | 빠른 공개 단계이며 운영 도입 전 코드 고정과 자체 검증 필요 |
| Hugging Face 컬렉션 | 3개 알고리즘 × 4개 target model = 12개 checkpoint repo | Qwen3·Gemma 4 계열에서 drafter 비교를 시작할 수 있음 |
| 예시 모델 카드 | 일부 checkpoint는 파일은 있으나 “No model card” | 가중치 사용법·제약·품질 설명은 README/PDF와 함께 보완해서 읽어야 함 |
| 데이터/학습 경고 | 기본 Qwen3-4B cache 약 38 TB, 기본 8 GPU 단일 노드 가정 | hobby-scale 데모보다 infra 준비가 필요한 재학습 파이프라인 |
| 라이선스/출처 | DeepSpec MIT, NOTICE에 SpecForge Apache-2.0 및 DFlash MIT 출처 명시 | derivative code 경계를 확인하고 배포 시 NOTICE까지 함께 검토 필요 |
실무 관점에서의 해석
내가 보기에 DeepSpec의 핵심은 speculative decoding을 “runtime trick”에서 “훈련 가능한 시스템 구성요소”로 끌어내린 것이다.
그동안 많은 팀에게 speculative decoding은 serving runtime이 이미 제공하면 쓰고, 아니면 구현 난도가 높은 최적화였다.
DeepSpec은 여기서 한 걸음 더 나아가, target model별로 draft model을 학습하고, task mix별 acceptance를 측정하고, load-aware verification까지 고려해야 한다는 점을 코드 형태로 드러낸다.
특히 Qwen3나 Gemma 4를 실제로 서빙하는 팀이라면, DeepSpec은 두 가지 질문을 던진다.
첫째, 내 workload에서 accepted length는 어떤 task에서 유지되고 어떤 task에서 무너지는가.
둘째, traffic load가 달라질 때 target model verification budget을 고정할 것인가, 아니면 confidence와 hardware profile에 따라 조절할 것인가.
DSpark의 메시지는 후자에 가깝다.
좋은 drafter만으로는 부족하고, serving scheduler까지 같이 봐야 한다.
반대로 도입 난도는 낮지 않다. target cache 38 TB 경고와 8 GPU 기본 가정은 실제 재학습 비용이 크다는 뜻이다.
공개 checkpoint가 있더라도 target model을 thinking mode로 쓰거나 특정 도메인에 맞추려면 README가 권하듯 다시 fine-tune하는 것이 더 적절할 수 있다.
또한 Hugging Face model card가 비어 있는 repo가 있어, 팀 내부 문서화 없이 바로 production dependency로 삼기에는 부족한 부분이 있다.
그래도 공개의 의미는 크다.
DeepSpec은 speculative decoding 연구를 논문 수치로만 남기지 않고, 데이터 준비, 초안 모델 학습, benchmark 평가, checkpoint 배포까지 이어지는 단위로 묶었다.
앞으로 inference optimization 경쟁은 quantization이나 attention kernel만의 문제가 아니라, draft model training + acceptance modeling + serving scheduler를 함께 설계하는 방향으로 더 많이 움직일 가능성이 높다.
DeepSpec은 그 흐름을 꽤 선명하게 보여 주는 공개 사례다.