MoE 모델 서빙에서 “로드밸런싱”은 생각보다 덜 충분하다.
같은 수의 요청을 받은 두 decode worker가 있어도, 한쪽 batch가 훨씬 많은 expert weight를 건드리면 latency가 달라진다.
특히 prefill과 decode를 다른 worker pool로 분리하는 PD-disaggregated serving에서는 prefill이 끝난 뒤 어느 decode worker로 요청을 넘길지가 시스템 성능을 직접 좌우한다.
ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving는 이 지점을 겨냥한다.
기존 decode router가 queue length, round-robin, power-of-two choices처럼 “얼마나 바쁜가”만 보았다면, ELDR는 이 요청이 어떤 expert들을 쓸 가능성이 높은가를 함께 본다.
핵심은 prompt prefill 단계에서 이미 MoE gate가 지나간 expert activation을 관찰할 수 있고, 이 footprint가 decode 단계의 expert 사용과 강하게 상관된다는 점이다.
이 글은 arXiv 2607.00466의 abstract, HTML 본문, 표와 그림을 기준으로 정리했다.
공개 검색 기준으로 별도 공식 구현 저장소는 확인하지 못했다.
따라서 현재 읽을 수 있는 공개 artifact는 논문과 arXiv HTML figure가 중심이며, 논문은 ELDR가 vLLM 위에 약 2,000 lines of Python으로 구현됐다고 설명한다.
무엇을 해결하려는가
PD-disaggregated serving은 LLM inference를 두 단계로 나눈다.
Prefill은 prompt를 병렬로 처리하는 compute-bound 단계이고, decode는 token을 순차 생성하는 latency-sensitive, memory-bandwidth-bound 단계다. xPyD topology에서는 x개의 prefiller와 y개의 decoder가 따로 있고, 요청은 prefill 후 KV state와 함께 decoder로 넘어간다.
Dense model이라면 decode batch의 token들은 같은 FFN weight를 쓰므로 load가 비슷하면 work도 대체로 비슷하다.
하지만 MoE에서는 token마다 top-k expert가 다르다.
한 decode step은 batch 안에서 어느 token이든 선택한 모든 distinct expert의 weight를 읽어야 한다.
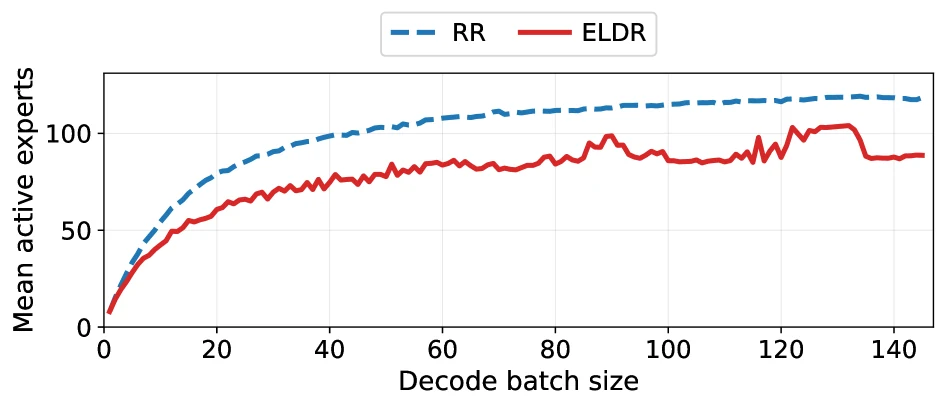
그래서 batch size보다 active expert union이 latency를 더 잘 설명하는 구간이 생긴다.
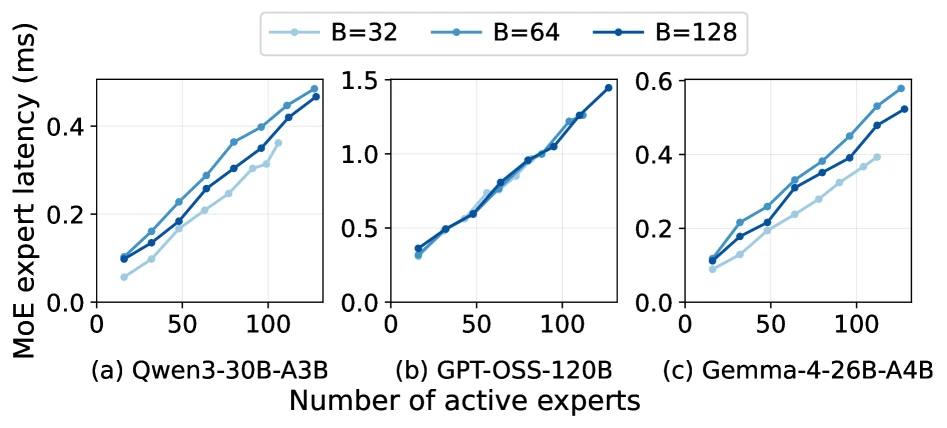
ELDR의 출발점은 expert 사용이 무작위가 아니라는 관찰이다.
Code, math, medical, legal 같은 task domain은 서로 다른 expert subset을 더 많이 활성화한다.
WildChat의 English, Chinese, Russian, French traffic도 language별 expert activation region이 갈라진다.
같은 domain끼리 batch를 만들면 mixed-domain batch보다 distinct expert 수가 task workload에서 17–21%, language workload에서 3–10% 줄어든다.
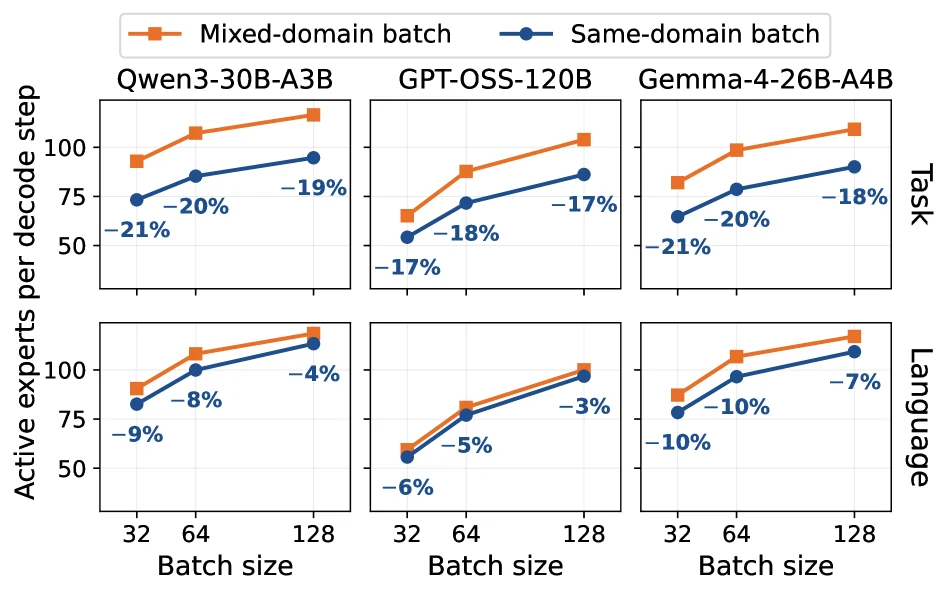
문제는 decode token이 아직 생성되기 전에 routing 결정을 해야 한다는 점이다.
ELDR는 prefill phase에 이미 MoE gate가 prompt token을 통과했다는 사실을 이용한다.
논문은 세 MoE 모델에서 prefill activation과 decode activation 사이의 per-expert correlation이 0.70–0.92 범위라고 보고한다.
즉 decode worker를 고르는 바로 그 순간에, future decode expert footprint를 예측할 신호가 이미 있다.
| 기존 decode routing 관점 | MoE에서 부족한 이유 | ELDR의 전환 |
|---|---|---|
| worker별 queue/load를 맞춘다 | 같은 load라도 batch가 켜는 expert union이 다르면 latency가 다르다 | load와 expert locality를 함께 본다 |
| decoder를 서로 interchangeable하게 본다 | domain별 prompt는 서로 다른 expert subset을 반복적으로 활성화한다 | 비슷한 signature의 요청을 같은 decoder 쪽으로 모은다 |
| prefix cache는 prefill routing 쪽 관심사다 | cache hit prefix의 expert footprint가 누락되면 signature가 깨진다 | KV cache와 co-indexed signature cache를 둔다 |
핵심 아이디어 / 구조 / 동작 방식
ELDR는 요청마다 expert signature를 만든다.
이 signature는 prefill 중 관찰한 expert activation count를 요약한 벡터이며, decode에서 어떤 expert를 다시 쓸지 예측하는 proxy다.
논문은 여러 변환을 비교한 뒤, IDF로 reweight한 discrete top-k count signature, 즉 count · idf가 softmax gate probability 같은 continuous alternative보다 낫다고 보고한다.
또 모든 layer를 쓰지 않고 greedy layer selection으로 signature quality가 높은 layer subset만 사용한다.
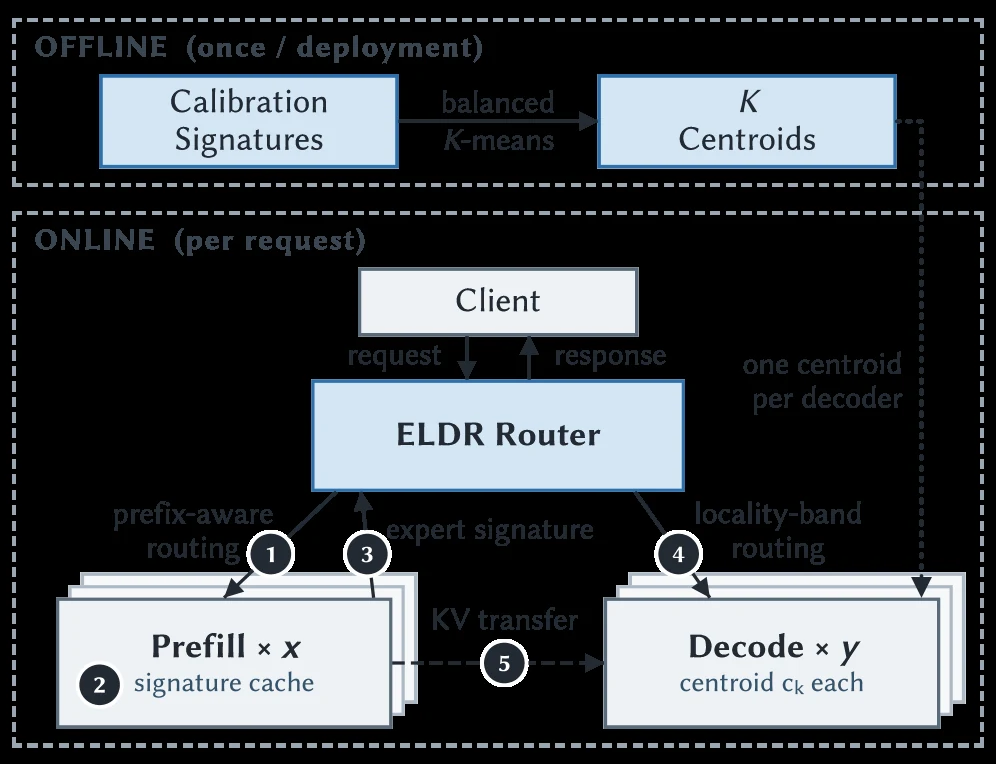
전체 pipeline은 두 단계다.
Offline에서는 calibration prompt 1,000개를 prefill로 흘려 expert signature를 모은다.
이후 Hungarian-balanced K-means를 사용해 signature space를 decode worker 수 K = D개의 cluster로 나눈다.
균형 제약을 넣는 이유는 단순 K-means가 locality는 잘 만들 수 있지만 한 decoder에 요청이 몰려 tail latency를 망칠 수 있기 때문이다.
논문 기준 greedy mask selection과 balanced K-means fit은 CPU에서 10초 미만에 끝난다.
Online에서는 request가 먼저 prefix-aware routing으로 prefiller에 간다.
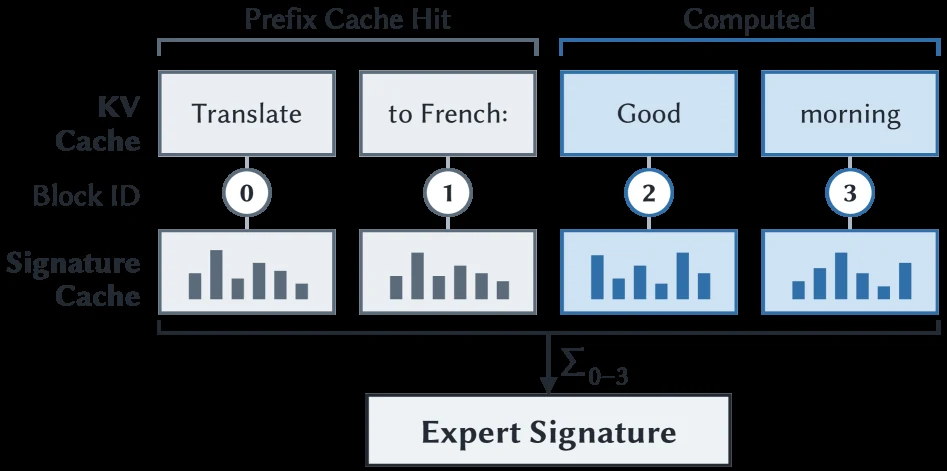
Prefill hook은 KV block granularity로 expert signature를 기록한다.
Prefill이 끝나면 router는 request signature를 decoder centroid들과 비교한다.
가장 가까운 centroid 하나에 무조건 보내지 않고, τ=0.1 locality band 안에 들어오는 후보 decoder 중 least-loaded worker를 고른다.
이 작은 band가 중요하다. pure top-1 locality routing은 순간적으로 비슷한 요청이 몰릴 때 tail을 악화시킬 수 있고, 너무 넓은 band는 locality 이득을 희석한다.
핵심적으로 ELDR는 모델 계산 자체를 바꾸지 않는다.
Token의 expert selection, gate, kernel, batching semantics는 그대로 두고 어느 decode worker가 request를 맡는가만 바꾼다.
그래서 논문은 output이 standard top-k gating과 동일하다고 강조한다.
대형 MoE에서 expert parallelism을 쓰는 경우에는 decoder마다 cluster가 다르므로, cluster별 예상 expert activation을 바탕으로 per-decoder expert-rank placement도 함께 조정한다.
| 구성 요소 | 논문에서의 역할 | 실무적 의미 |
|---|---|---|
| Expert signature | prefill expert activation을 decode expert locality의 proxy로 사용 | request domain label 없이도 모델 내부 routing footprint를 이용한다 |
| Balanced K-means | decoder마다 하나의 centroid를 두되 cluster size를 균형화 | locality만 보다가 worker hot spot을 만드는 문제를 줄인다 |
| Locality-band routing | 가까운 centroid 후보 중 least-loaded decoder 선택 | expert reuse와 live load balancing의 절충점이다 |
| Signature cache | KV block과 함께 expert footprint 저장 | prefix cache hit가 있어도 full prompt signature를 유지한다 |
| Per-decoder EP placement | large MoE의 cluster별 hot expert를 EP rank에 분산 | inter-worker routing과 intra-decoder EP balancing을 연결한다 |
공개된 근거에서 확인되는 점
실험 환경은 꽤 시스템 논문답다.
저자들은 AMD MI300X 8-GPU node 5대, 총 40 GPU cluster를 사용하고, 400 Gbps NDR InfiniBand와 GPU당 ConnectX-7 HCA를 둔다.
Serving stack은 vLLM 0.21.0rc1 / ROCm 7.2, PD disaggregation에는 vLLM의 NIXL connector를 쓴다.
주 실험은 8P16D topology다.
Qwen3-30B-A3B, GPT-OSS-120B, Gemma-4-26B-A4B는 TP=1로 평가하고, large-MoE scaling에서는 Qwen3-235B-A22B를 decoder instance당 TP=4 / EP=4로 둔다.
Workload는 code, math, medical, legal을 섞은 11,668-prompt task set과 WildChat에서 뽑은 14,000-prompt multilingual language set이다.
Baseline은 Random, Round-Robin, JSQ, P2C, 그리고 oracle domain label을 쓰는 Domain routing이다.
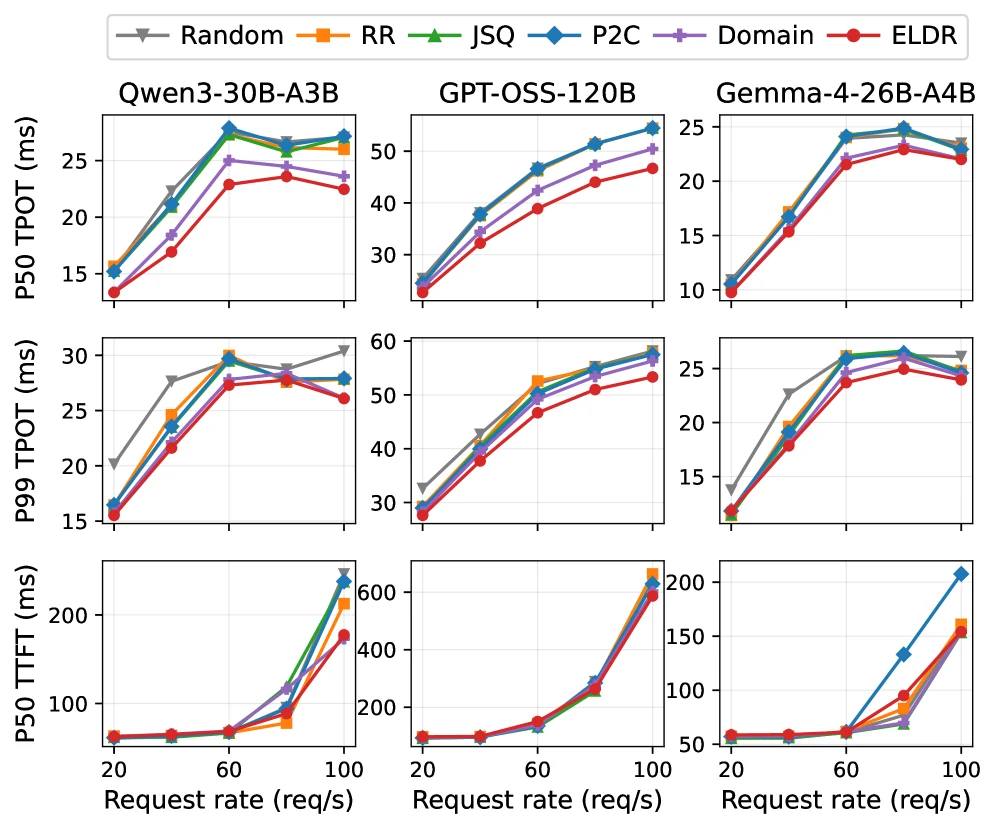
Task workload에서는 ELDR가 best load-balancing baseline 대비 median TPOT를 7.0–13.9%, tail TPOT를 3.4–6.0% 줄인다.
Domain baseline도 이 환경에서는 강하다. code/math/medical/legal label이 실제 expert cluster와 어느 정도 맞기 때문이다.
그래도 ELDR는 Domain보다 median 1.4–6.9%, tail 1.6–4.5% 더 낮다.
네 개 label보다 K=16 signature cluster가 더 세밀하고, hard partition이 아니라 locality band로 load spillover를 허용하기 때문이다.
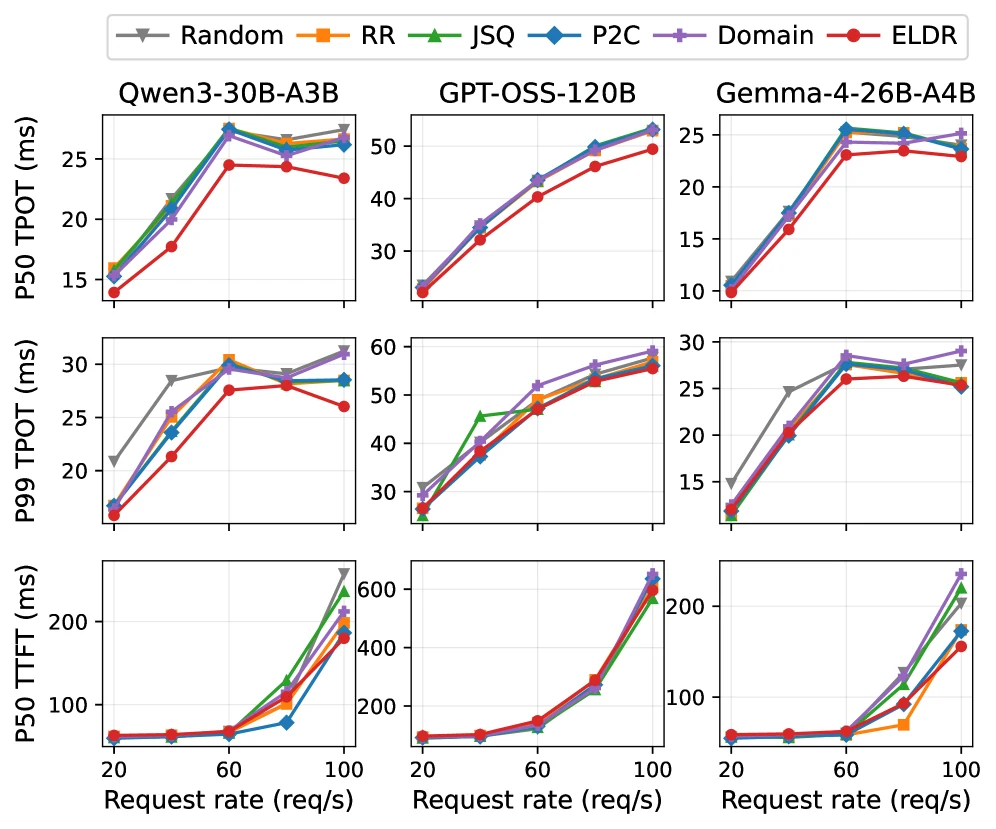
Language workload는 더 미묘하다.
ELDR는 best load balancer 대비 median TPOT를 5.9–10.0% 줄인다.
Tail은 Qwen3-30B-A3B에서 평균 6.2% 좋아지지만, GPT-OSS-120B는 1.5%, Gemma-4-26B-A4B는 0.2% 평균 regression이 있다.
다만 각 model cell의 peak 기준으로는 세 모델 모두 tail 감소 구간이 있다.
이 차이는 language label이 expert locality를 충분히 설명하지 못하고, WildChat traffic이 English/Chinese 중심으로 skew되어 static label partition이 hot block을 만들기 쉽다는 점과 연결된다.
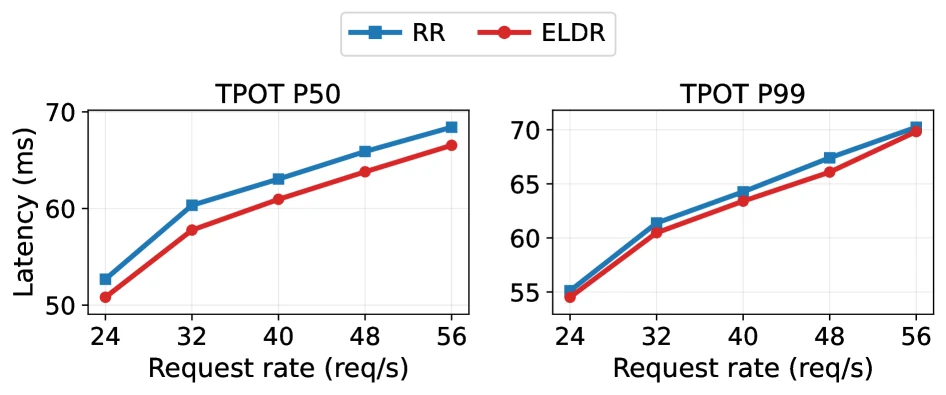
Overhead도 작게 측정된다.
Qwen3-30B-A3B task workload, 8P16D, 60 req/s, median TTFT 69 ms 조건에서 ELDR는 request당 0.86 ms를 더한다.
이는 median TTFT의 1.2%다.
가장 큰 항목은 prefill GPU의 reduce() scatter 0.48 ms와 signature D2H staging 0.21 ms이고, scheduler fetch와 proxy routing은 sub-percent다.
Signature cache는 HBM의 0.24%, KV cache 대비 1% 미만이며, request마다 전달되는 signature는 12 KiB 수준이라고 보고된다.
| 검증 항목 | 공개된 수치 | 해석 |
|---|---|---|
| Task median TPOT | best load balancer 대비 7.0–13.9% 감소 | domain별 expert locality가 뚜렷할 때 가장 강하다 |
| Task tail TPOT | 3.4–6.0% 감소 | locality만이 아니라 balanced clustering과 live load band가 tail을 보호한다 |
| Language median TPOT | 5.9–10.0% 감소 | label보다 signature가 세밀한 locality 구조를 잡는다 |
| Language tail TPOT | Qwen3 평균 6.2% 감소, GPT-OSS/Gemma 평균은 1.5%/0.2% regression | traffic skew와 softer boundary에서는 tail tradeoff를 따로 봐야 한다 |
| Active expert count | Qwen3 task에서 round-robin 대비 22.0% 감소 | 성능 개선이 active expert union 축소에서 온다는 직접 검증이다 |
| Serving overhead | 0.86 ms/request, TTFT의 1.2% | routing 이득에 비해 request-level cost는 작다 |
| Signature cache | HBM 0.24%, KV cache의 1% 미만 | prefix cache와 함께 써도 memory overhead가 작다 |
Generalization도 두 갈래로 확인한다.
Decoder pool을 8P8D, 8P16D, 8P24D로 늘리면 Qwen3-30B-A3B language workload에서 median TPOT 감소가 round-robin 대비 8.0%, 9.8%, 10.2%로 커진다.
Decoder가 많아질수록 workload를 더 세밀한 cluster로 나눌 수 있어서 per-decoder expert union이 줄어든다는 해석이다.
실무 관점에서의 해석
ELDR의 실무적 의미는 “MoE router를 더 똑똑하게 만들자”보다 조금 다르다.
모델 내부 gate는 그대로 두고, serving layer에서 request placement를 바꾸는 작업이다.
그러므로 quality regression을 감수하는 approximate expert dropping이나 piggybacking 방식과 다르게, output semantics를 건드리지 않는다.
운영팀 입장에서는 이 점이 크다.
모델 품질 검증을 다시 전부 해야 하는 변경이 아니라, routing policy와 cache metadata를 바꾸는 변경에 가깝기 때문이다.
두 번째로 중요한 점은 prefix locality와 expert locality가 서로 다른 축이라는 것이다.
Prefill side에서는 prefix cache hit가 중요하고, decode side에서는 active expert union이 중요하다.
ELDR는 KV cache와 signature cache를 co-indexing해서 이 둘을 충돌시키지 않으려 한다.
장기적으로 PD-disaggregated serving stack은 prefix-aware prefill routing, expert-locality-aware decode routing, EP rank balancing을 별도 layer로 조합하는 방향으로 갈 가능성이 높다.
반대로 도입 조건도 분명하다.
ELDR는 calibration trace가 필요하고, model·dataset·topology가 바뀌면 offline fit을 다시 해야 한다.
Workload의 expert locality가 약하거나 traffic skew가 심한데 locality band를 잘못 잡으면 tail이 흔들릴 수 있다.
논문에서도 language workload tail은 모델별로 엇갈린다.
즉 운영자는 median TPOT만 보지 말고 p99, load skew, domain drift, prefix-cache hit pattern을 함께 봐야 한다.
내가 보기에 ELDR는 최근 MoE serving 최적화 흐름에서 중요한 한 칸을 채운다.
SGLang Waterfill/LPLB류가 physical rank·replica dispatch를 조정해 slowest EP path를 줄인다면, ELDR는 그보다 한 단계 위에서 어떤 요청들을 같은 decoder에 모을 것인가를 다룬다.
둘은 경쟁 관계라기보다 서로 다른 레이어의 locality 문제다.
대형 MoE를 실제 서비스에 올리는 팀이라면 이제 load balancing을 “요청 수를 맞추는 문제”가 아니라, expert weight reuse를 만드는 placement 문제로 다시 정의해야 한다.