Sparse retrieval은 RAG 시스템에서 여전히 매력적이다.
Dense retriever처럼 의미를 어느 정도 잡으면서도, 결과는 vocabulary 차원의 sparse vector라서 inverted index와 잘 맞고, 어떤 term이 retrieval에 기여했는지도 비교적 해석 가능하다.
SPLADE 계열이 오래 살아남는 이유도 여기에 있다.
그런데 sparse encoder를 영어 밖으로 가져가면 구조적인 문제가 생긴다.
Dense model은 연속 latent space에서 언어 간 의미가 어느 정도 섞일 수 있지만, sparse encoder는 출력 공간 자체가 vocabulary다.
영어 중심 vocabulary에 한국어·중국어·아랍어 token이 거의 없다면, target language term에 중요도를 줄 차원 자체가 부족하다.
단순 fine-tuning만으로는 “한국어 검색어를 영어 vocabulary 위에 어떻게 표시할 것인가”라는 병목을 피하기 어렵다.
arXiv 2605.26002의 SemBridge: Language Transfer in Sparse Encoders via Multilingual Semantic Bridges는 이 문제를 model architecture가 아니라 target tokenizer embedding 초기화 문제로 재정의한다.
핵심 아이디어는 간단하다.
영어 sparse encoder가 이미 학습한 source vocabulary embedding을 버리지 말고, multilingual dense embedding model을 semantic bridge로 써서 target-language token을 source token들의 sparse weighted combination으로 초기화한다.
논문 기준 SemBridge는 2026년 5월 25일 제출된 cs.IR preprint이며, 저자는 Korea University와 University of Amsterdam 소속의 Seongtae Hong, Youngjoon Jang, Jia-Heui Ju, Hyeonseok Moon, Heuiseok Lim이다.
실험은 Arabic, Chinese, Hindi, Korean, Russian 다섯 언어와 네 sparse encoder(splade-v3, Splade_PP_en_v1, opensearch-neural-sparse-encoding-v1, granite-embedding-30m-sparse)를 대상으로 한다.
평가에는 WebFAQ와 MIRACL, 지표는 nDCG@10과 FLOPS가 사용된다.
왜 sparse encoder의 다국어 이전은 어렵나
Sparse encoder는 문서나 query를 “vocabulary token별 중요도”로 표현한다.
이 설계는 retrieval에는 강력하다. inverted index를 그대로 활용할 수 있고, 특정 token이 왜 점수를 받았는지 추적하기 쉽다.
하지만 vocabulary가 명시적인 출력 공간이라는 점은 cross-lingual transfer에서는 약점이 된다.
논문은 여러 source sparse encoder의 vocabulary 분포를 분석한다.
대부분의 모델에서 non-English token 비중은 매우 작고, 특히 granite-embedding-30m-sparse는 Korean token이 2개뿐이라고 보고한다. splade-v3도 영어 편향이 크다.
즉 한국어 query를 넣어도 모델이 한국어 token 차원에 충분한 중요도를 줄 수 있는 구조가 애초에 없다.
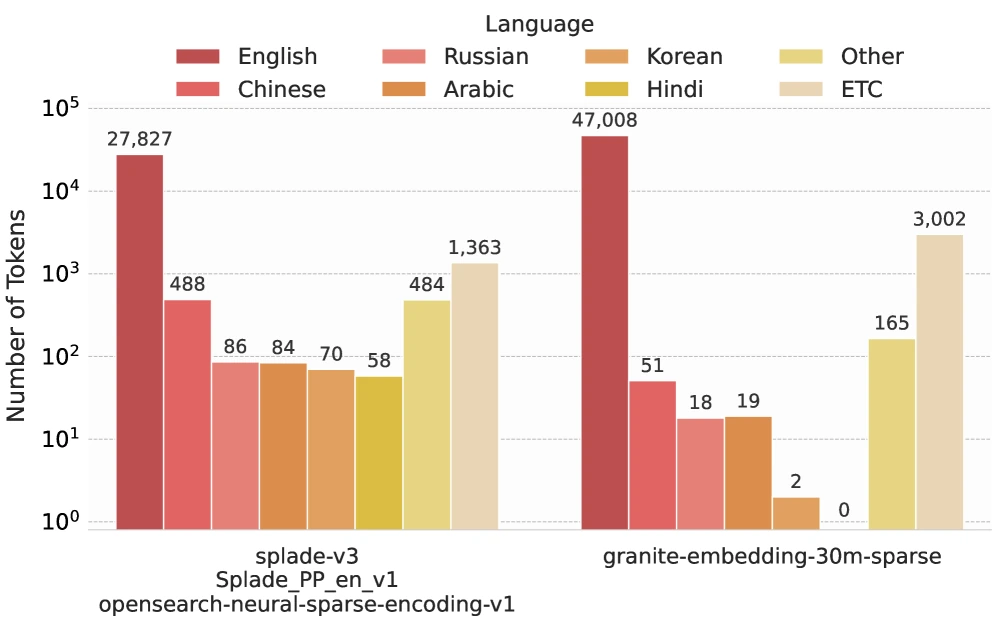
이 병목을 피하려면 target language tokenizer를 붙여야 한다.
하지만 새 tokenizer의 token embedding을 어떻게 초기화할지가 문제다.
Random이나 평균 초기화는 source sparse encoder가 갖고 있던 term weighting 지식을 거의 보존하지 못한다.
표면 문자열 overlap에 의존하는 방법도 script가 다른 언어에서는 약하다.
SemBridge는 여기서 “문자열이 닮았는가”가 아니라 “multilingual dense space에서 의미가 닮았는가”를 기준으로 source token을 골라 온다.
SemBridge의 절차: overlap은 복사하고, 나머지는 semantic bridge로 채운다
SemBridge는 target tokenizer를 기존 sparse encoder에 붙일 때 embedding matrix를 초기화하는 방법이다.
큰 흐름은 세 단계다.
-
Overlapping token transfer
Source vocabulary와 target vocabulary에 동시에 존재하는 token은 source embedding을 그대로 복사한다. 숫자, punctuation, 일부 shared subword처럼 의미가 그대로 이어지는 token은 굳이 재구성하지 않는다. -
Multilingual semantic bridge
나머지 target tokenx_t와 모든 source tokenx_s를 multilingual dense embedding modelB에 넣어 같은 semantic space의 vector로 바꾼다. 논문 기본 설정에서는bge-m3를 bridge model로 사용한다. 그런 다음 source-token vector와 target-token vector 사이의 similarity matrix를 계산한다. -
Similarity-based sparse weighting
Target token 하나를 모든 source token의 평균으로 만들면 noise가 너무 많다. SemBridge는 similarity vector에 Entmax를 적용해 소수의 core synonym만 남긴다. 논문은 기본적으로alpha = 4를 사용해 높은 sparsity를 둔다. 최종 target embedding은 선택된 source embedding들의 weighted sum으로 초기화된다.
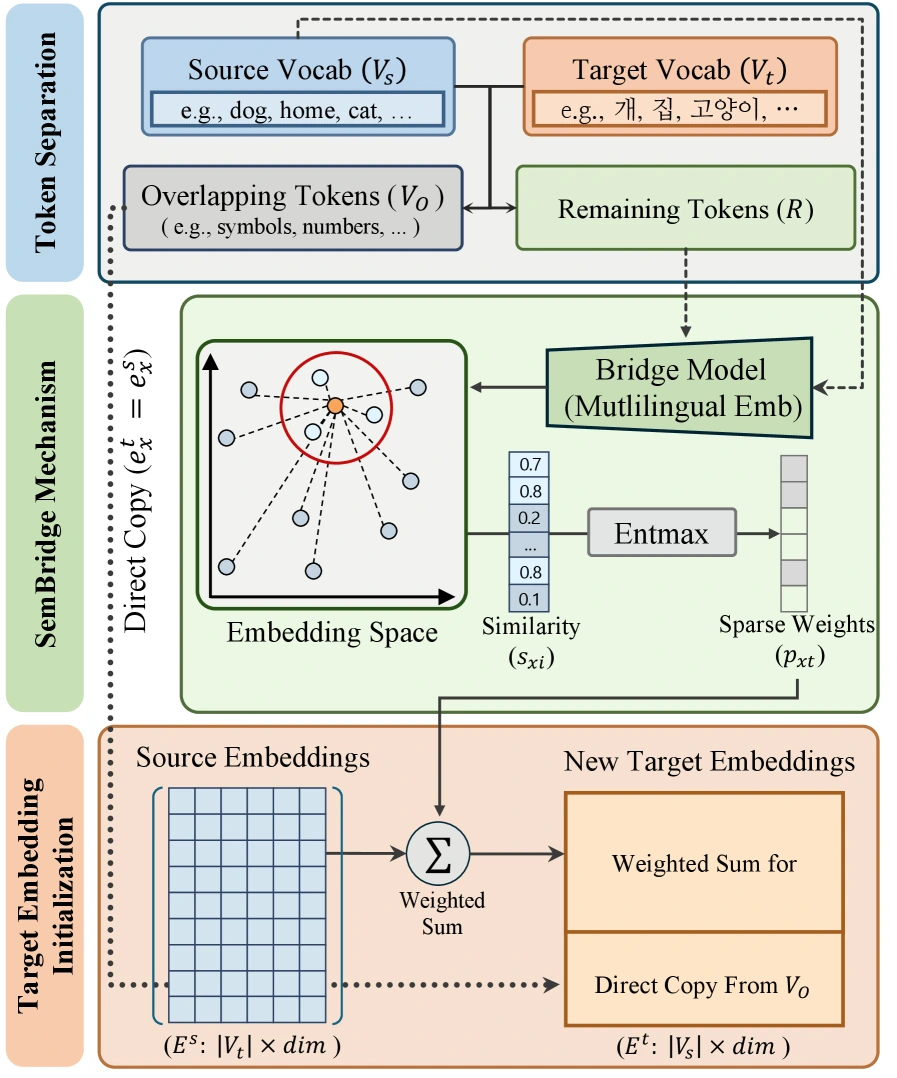
이 설계가 중요한 이유는 architecture를 바꾸지 않는다는 점이다.
Embedding dimension은 source sparse encoder와 동일하게 유지되고, target tokenizer vocabulary만 확장 또는 교체된다.
따라서 기존 sparse encoder의 retrieval capability를 최대한 보존하면서 target language query/document를 받을 수 있다.
실험 설계: 4개 sparse encoder × 5개 언어 × 2개 retrieval benchmark
논문은 다음 네 sparse encoder를 source model로 사용한다.
| Source sparse encoder | 의미 |
|---|---|
splade-v3 |
SPLADE 계열의 대표 sparse encoder |
Splade_PP_en_v1 |
영어 SPLADE 변형 baseline |
opensearch-neural-sparse-encoding-v1 |
OpenSearch ecosystem의 neural sparse encoder |
granite-embedding-30m-sparse |
IBM Granite embedding 계열의 small sparse model |
Target tokenizer는 언어별로 다르게 둔다.
Arabic은 ARBERT, Chinese는 bart-base-chinese, Hindi는 hindi-bert-v2, Korean은 kobigbird-bert-base, Russian은 rubert-base-cased를 쓴다.
Fine-tuning에는 WebFAQ의 언어별 query-positive pair가 사용되며, 논문이 보고한 규모는 Arabic 132k, Chinese 122k, Hindi 90k, Korean 92k, Russian 377k다.
비교 baseline은 크게 세 부류다.
Random, Mean, Univariate Gaussian, Multivariate Gaussian 같은 일반 초기화 방법, 그리고 FOCUS와 OFA처럼 language transfer를 의식한 embedding initialization 방법이다.
모든 방법은 overlapping token은 source embedding을 직접 복사하고, non-overlap token 처리 방식에서 차이가 난다.
결과 1: zero-shot에서 초기화 품질 차이가 바로 드러난다
첫 번째 질문은 fine-tuning 없이 embedding 초기화 직후 retrieval이 가능한가다.
Table 1 기준으로 Base, Random, Mean은 대부분의 언어와 모델에서 nDCG@10이 거의 0에 가깝다.
이는 source sparse encoder가 target tokenizer를 제대로 이해하지 못하면 retrieval capability가 거의 이전되지 않는다는 뜻이다.
SemBridge는 이 구간에서 강하게 차이를 만든다.
예를 들어 splade-v3의 평균 zero-shot nDCG@10은 WebFAQ에서 SemBridge 0.422로 OFA 0.351, Multivariate Gaussian 0.334보다 높다.
MIRACL에서도 SemBridge 0.179로 OFA 0.110, Multivariate Gaussian 0.104보다 높다.Splade_PP_en_v1도 WebFAQ 평균에서 SemBridge 0.409로 OFA 0.336보다 높다.
다만 모든 셀에서 무조건 이기는 식으로 읽으면 안 된다. opensearch-neural-sparse-encoding-v1의 MIRACL 평균에서는 Multivariate Gaussian이 0.141, SemBridge가 0.127로 나온다. granite-embedding-30m-sparse의 Korean zero-shot처럼 성능이 낮게 남는 경우도 있다.
즉 SemBridge의 메시지는 “모든 모델·언어에서 magic bullet”이 아니라, source vocabulary의 의미 구조를 target language로 옮길 때 semantic bridge와 sparse selection이 대체로 더 강한 출발점을 만든다에 가깝다.
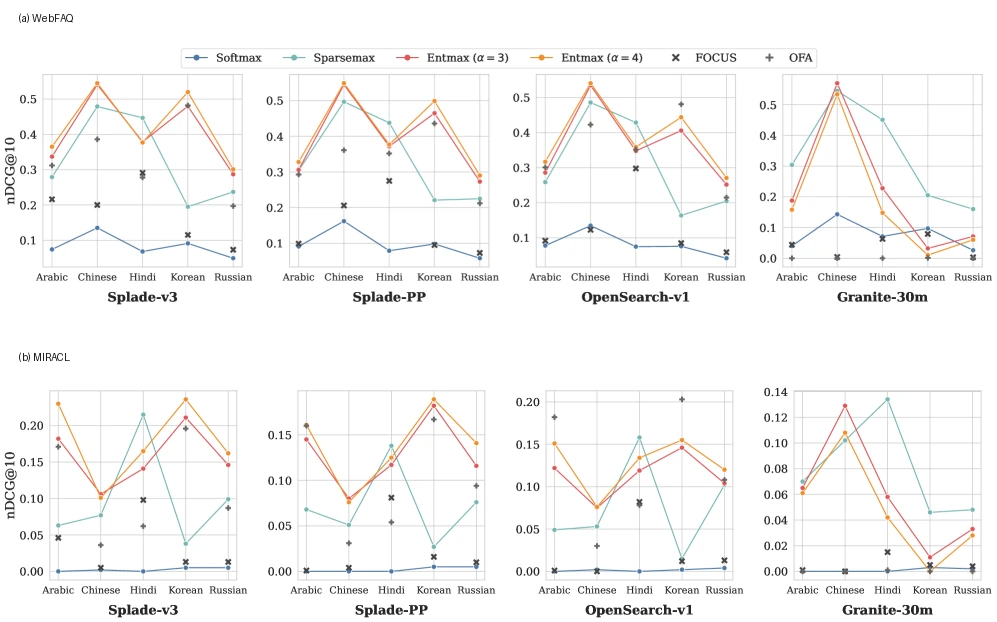
위 그림은 Entmax sparsity level alpha를 바꿨을 때의 zero-shot 성능을 보여 준다.
Softmax에 해당하는 alpha = 1은 모든 source token에 weight를 나눠 주므로 semantic noise를 함께 가져오기 쉽다. alpha >= 2부터는 sparse weighting이 들어가면서 성능이 안정적으로 올라가고, 논문은 alpha = 3, 4가 FOCUS/OFA보다 강한 구간을 보인다고 해석한다.
단, 너무 sparse하면 의미 단서를 버릴 수 있으므로 언어·tokenizer별 adaptive sparsity는 후속 과제로 남는다.
결과 2: fine-tuning 후에도 초기화의 흔적은 남는다
두 번째 질문은 “어차피 fine-tuning할 거면 초기화가 중요한가?”
다.
SemBridge 논문은 그렇다고 답한다.
동일한 language-specific retrieval data로 fine-tuning해도 초기 embedding의 품질 차이는 사라지지 않는다.
Table 2에서 splade-v3의 fine-tuned 평균 nDCG@10은 WebFAQ 기준 SemBridge 0.697, Univariate/Multivariate 0.644, OFA 0.640이다.
MIRACL에서도 SemBridge 0.319로 Multivariate 0.307, OFA 0.292보다 높다.Splade_PP_en_v1과 opensearch-neural-sparse-encoding-v1도 평균적으로 SemBridge가 강하다.
특히 granite-embedding-30m-sparse에서는 논문 본문이 SemBridge가 두 데이터셋 모두에서 모든 baseline을 넘은 유일한 방법이라고 설명한다.
이 결과는 실무적으로 중요하다.
다국어 retrieval에서 “target data로 조금 fine-tuning하면 되겠지”라고 생각하기 쉽지만, sparse encoder에서는 target token이 source vocabulary semantic space의 어디에서 시작하는지가 계속 영향을 준다.
잘못된 초기화는 학습 과정에서 noise를 학습하거나, target language의 sparse term weighting을 비효율적으로 다시 찾아가게 만든다.
결과 3: convergence와 FLOPS trade-off도 좋아진다
논문은 training loss trajectory도 비교한다. splade-v3를 Chinese, Korean, Russian으로 옮기는 실험에서 SemBridge는 대체로 더 낮은 initial loss로 시작하고, 초반 epoch에서 빠르게 안정적인 위치로 이동한다.
이는 source model이 갖고 있던 semantic retrieval capability를 target tokenizer embedding에 더 잘 심어 두었기 때문으로 해석할 수 있다.
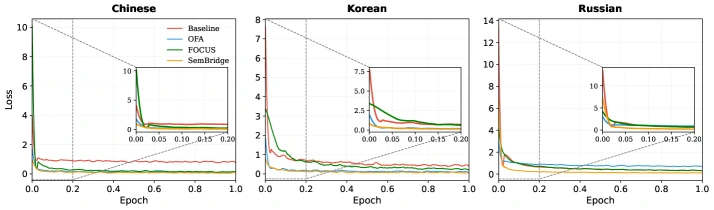
Efficiency 관점도 중요하다.
Sparse retrieval은 성능만 높으면 되는 것이 아니라, inverted index에서 실제로 얼마나 sparse하게 검색되는지가 운영 비용과 latency에 직결된다.
논문은 MIRACL dev set의 Chinese 실험에서 FLOPS와 nDCG@10 trade-off를 비교한다.
FOCUS는 FLOPS가 과도하게 높고, Gaussian 계열은 FLOPS는 낮지만 성능이 불안정하다.
SemBridge는 높은 nDCG@10과 낮은 FLOPS 사이에서 더 좋은 균형을 보인다고 보고한다.
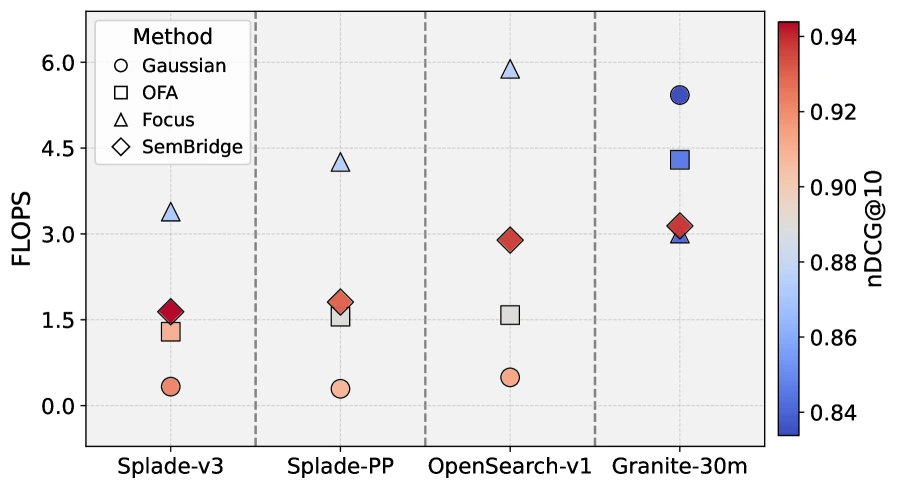
이 지점이 SemBridge의 제품적 의미다.
다국어 검색기를 만들 때 dense retriever만 쓰면 언어 이전은 쉬울 수 있지만 inverted index compatibility와 term-level interpretability를 잃기 쉽다.
반대로 sparse retriever를 그대로 쓰면 target language vocabulary 병목이 생긴다.
SemBridge는 sparse retrieval의 운영 장점을 유지하면서, target language 초기화를 더 의미 있게 만드는 중간 경로다.
정성 분석: “home”을 어떤 source token으로 초기화하나
논문의 qualitative table은 SemBridge가 왜 작동하는지 직관적으로 보여 준다.
다섯 언어에서 “home”에 해당하는 target-language token을 초기화할 때, 각 방법이 어떤 source token을 top-weight로 고르는지 비교한다.
FOCUS는 ani, ##asa 같은 무의미한 subword나 문맥상 어긋난 token을 고르는 경우가 있고, OFA는 family, maison처럼 일부 개선된 결과를 보이지만 Arabic에서 israel, Chinese에서 hush처럼 불안정한 alignment도 나온다.
반면 SemBridge는 home, house, casa, maison처럼 핵심 의미가 더 가까운 source token을 일관되게 고른다. alpha = 2는 dwelling, households처럼 넓은 문맥 단서도 포함하고, alpha = 4는 더 좁은 core synonym 중심으로 noise를 줄인다.
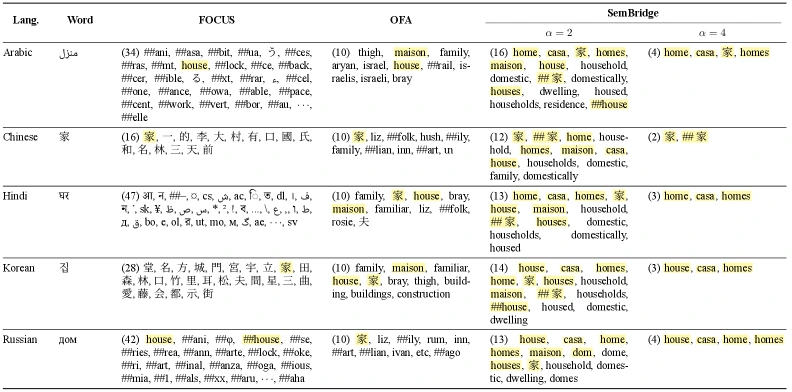
이 분석은 숫자보다 더 중요한 메시지를 준다.
Sparse encoder의 다국어 이전은 단순히 embedding matrix를 채우는 작업이 아니다.
Target token 하나하나가 source sparse model이 이미 배운 semantic term space에서 어느 좌표를 차지해야 하는지 정하는 작업이다.
SemBridge는 multilingual dense model을 이 좌표 찾기의 중간 번역기로 쓴다.
공개 source 기준 확인 사항
이번 정리는 arXiv abstract/PDF/HTML과 Hugging Face Papers mirror를 기준으로 했다.
Web search와 arXiv HTML 내 URL 추출 기준으로는 논문이 직접 연결한 공식 GitHub repository나 companion code repository는 확인되지 않았다.
논문 본문에는 tokenizer/model artifact로 Hugging Face repository들이 다수 등장하지만, SemBridge 자체 구현 repo를 별도로 공개했다는 표시는 보이지 않았다.
| 항목 | 확인 내용 |
|---|---|
| Paper | arXiv:2605.26002, SemBridge: Language Transfer in Sparse Encoders via Multilingual Semantic Bridges |
| 상태 | 2026-05-25 submitted, preprint, cs.IR |
| 핵심 방법 | Multilingual dense bridge(bge-m3) + Entmax sparse weighting으로 target token embedding 초기화 |
| Source encoders | splade-v3, Splade_PP_en_v1, opensearch-neural-sparse-encoding-v1, granite-embedding-30m-sparse |
| Target languages | Arabic, Chinese, Hindi, Korean, Russian |
| 평가 | WebFAQ, MIRACL, nDCG@10, FLOPS |
| 공식 code | arXiv/HF Papers/웹 검색 기준 별도 공식 SemBridge repo는 확인되지 않음 |
한계와 후속 질문
SemBridge의 한계도 명확하다.
첫째, 평가 언어는 다섯 개로 제한된다.
한국어가 포함된 것은 반갑지만, 형태소 구조가 더 복잡하거나 resource 수준이 다른 언어에서 같은 경향이 유지되는지는 별도 검증이 필요하다.
둘째, Entmax alpha는 중요한 hyperparameter다.
논문은 robustness를 보이지만, 너무 낮으면 source-token noise가 들어오고 너무 높으면 의미 단서가 잘릴 수 있다.
실서비스에서는 language-aware 또는 tokenizer-aware sparsity selection이 필요할 수 있다.
셋째, bridge model의 품질에 의존한다.
Appendix 실험은 bge-m3, MiniLM, mGTE, Qwen3 등을 비교하며, 더 좋은 cross-lingual alignment를 가진 bridge model일수록 초기화 품질이 좋아질 수 있음을 보여 준다.
즉 SemBridge는 independent한 silver bullet이라기보다, multilingual dense embedding model의 semantic alignment를 sparse encoder vocabulary space로 투영하는 방법이다.
실무적으로 가져갈 점
SemBridge가 흥미로운 이유는 sparse retrieval을 다시 다국어 RAG 시스템의 현실적인 선택지로 끌어온다는 데 있다.
Dense retriever가 모든 것을 해결하는 것처럼 보이지만, 대규모 문서 검색에서는 inverted index, term-level explanation, sparse representation의 비용 구조가 여전히 강력하다.
특히 enterprise RAG에서 keyword precision과 semantic expansion을 동시에 원할 때 sparse encoder는 매력적이다.
다만 영어 중심 sparse encoder를 그대로 한국어 검색에 쓰는 것은 구조적으로 무리다.
Vocabulary에 한국어 차원이 없으면 모델이 줄 수 있는 term importance도 없다.
SemBridge는 이 gap을 target tokenizer embedding initialization으로 좁힌다.
한국어 tokenizer의 token을 source sparse encoder의 semantic term space에 의미 있게 배치한 뒤, 필요하면 WebFAQ 같은 target-language retrieval data로 fine-tuning한다.
내가 이 논문에서 가장 크게 가져가는 메시지는 이것이다.
다국어 retrieval에서 transfer의 단위는 model 전체가 아니라 vocabulary coordinate일 수 있다.
Dense bridge는 언어 간 의미를 찾고, Entmax는 noise를 자르고, sparse encoder는 그 결과를 inverted index 친화적인 term-weight representation으로 유지한다.
이 조합은 한국어 RAG나 다국어 enterprise search를 만들 때 꽤 실용적인 설계 패턴이 될 수 있다.