LLM 추론 성능을 올리는 가장 익숙한 방법은 더 많이 생각하게 하는 것이다.
Chain-of-thought를 쓰고, 여러 답을 샘플링하고, self-consistency로 투표하거나, verifier로 후보를 고른다.
이 계열의 test-time scaling은 모델 파라미터를 건드리지 않는다는 점에서 운영하기 쉽다.
하지만 모델 내부에 이미 잘못 자리 잡은 개념이나, 특정 문제 구조에 대한 약한 inductive bias를 직접 바꾸지는 못한다.
KAIST 연구진의 Query-Conditioned Test-Time Self-Training for Large Language Models, 줄여서 QueST, 는 이 지점을 다르게 본다.
입력 질문 하나를 단순한 prompt로만 쓰지 않고, 그 질문이 품고 있는 개념·조건·추론 패턴을 seed로 삼아 유사한 문제-해설 쌍을 만든다.
그리고 그 쌍을 supervision으로 사용해 추론 시점에 LoRA 기반 SFT를 짧게 수행한 뒤, 적응된 모델로 원래 질문에 답한다.
핵심은 “외부 검색 데이터 없이도 질문 자체가 로컬 학습 신호를 만든다”는 주장이다.
논문은 QueST를 TENT, TLM 같은 test-time optimization baseline과 비교했고, 7개 수학 추론 benchmark와 GPQA-Diamond에서 일관된 개선을 보고한다.
다만 공개 코드 링크가 연결된 GitHub 저장소는 작성 시점 기준 README.md의 “Code will be released soon.”
한 줄만 포함하고 있어, 현재 공개 표면은 논문·프로젝트 페이지 중심의 연구 결과로 읽는 편이 안전하다.
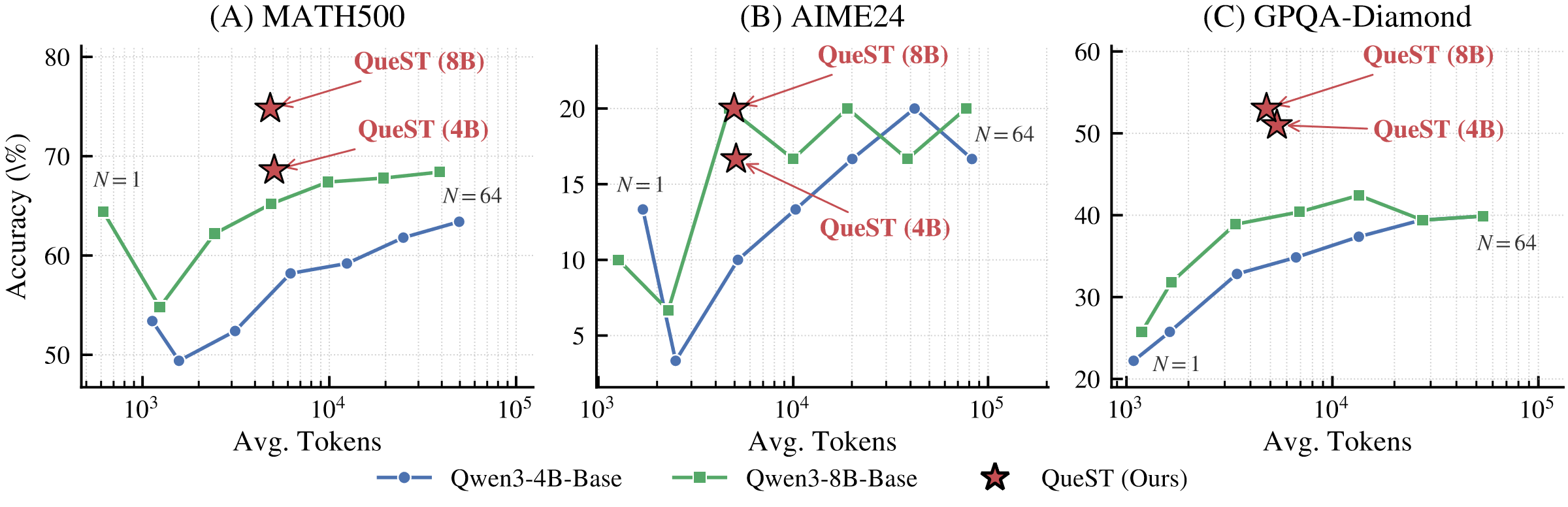
무엇을 해결하려는가
Test-time scaling은 모델을 고정한 채 inference compute를 늘린다.
이 방식은 확률적 탐색을 넓히거나 후보 답을 더 많이 모으는 데는 강하지만, 모델이 특정 문제 구조를 잘못 이해하고 있을 때 그 내부 표현을 바꾸지는 않는다.
예를 들어 수학 문제에서 반복적으로 같은 잘못된 공식이나 표면 패턴에 끌리는 모델은, 샘플을 더 많이 뽑아도 비슷한 오류를 반복할 수 있다.
Test-time optimization은 반대로 추론 시점에 모델 파라미터를 업데이트한다.
기존 LLM 계열 방법으로는 TTT-NN처럼 유사 문제를 외부 데이터베이스에서 검색해 fine-tuning하는 접근, TLM처럼 입력 perplexity를 줄이는 방식이 있다.
하지만 전자는 외부 corpus와 retrieval infrastructure에 의존하고, 후자는 현재 질문의 “추론 구조”와 직접 맞물린 supervision이라고 보기 어렵다.
QueST가 겨냥하는 빈칸은 명확하다.
테스트 시점에 업데이트는 하되, 외부 데이터 없이, 특정 입력 질문에 맞춰진 supervision을 만들 수 있는가?
논문은 이를 네 가지 속성으로 정리한다.
| 방법 | Query-specific | External data-free | Test-time update | Input-conditioned signal |
|---|---|---|---|---|
| Test-time scaling | ✗ | ✓ | ✗ | ✗ |
| Self-evolving | ✗ | ✓ | ✗ | ✗ |
| TTT-NN | ✓ | ✗ | ✓ | ✓ |
| TLM | ✗ | ✓ | ✓ | ✓ |
| QueST | ✓ | ✓ | ✓ | ✓ |
이 표에서 QueST의 차별점은 self-training을 전역 데이터 생성이나 장기적 self-evolution으로 쓰는 것이 아니라, 현재 들어온 질문 하나에 국소적으로 묶어 쓰는 것이다.
그래서 이 방법은 training pipeline이라기보다 inference pipeline의 일부에 가깝다.
핵심 아이디어 / 구조 / 동작 방식
QueST의 동작은 세 단계로 요약된다.
- 입력 질문
q를 받는다. q와 구조적으로 관련된 보조 문제-해설 쌍D(q)를 생성한다.- 이 쌍으로 LoRA 파라미터만 짧게 업데이트한 뒤, 적응된 모델로 원래 질문에 답한다.
논문은 입력 질문이 어떤 로컬 분포 D_q에서 나온 문제라고 가정한다.
같은 개념, 같은 조건, 같은 추론 패턴을 공유하는 문제들을 근처에 두고 보면, 원래 질문을 푸는 일은 그 로컬 분포 안에서 generalization하는 문제로 바뀐다.
QueST는 이 로컬 분포를 외부 데이터베이스에서 찾지 않고, base model 자체를 생성기로 사용해 근사한다.
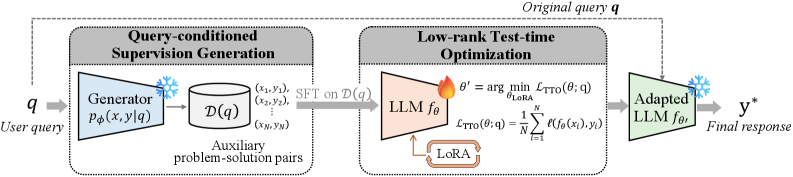
구현상 중요한 점은 full fine-tuning이 아니라 LoRA만 업데이트한다는 점이다.
논문 설정에서는 LoRA rank 16, alpha 32, dropout 0.05를 사용하고 q_proj, k_proj, v_proj, o_proj를 target module로 둔다.
최적화는 AdamW, learning rate 1e-4, batch size 1, gradient accumulation 4, bf16 precision, cross-entropy SFT loss다.
기본적으로 각 질문당 보조 문제-해설 쌍은 N=5개 생성한다.
Test-time optimization step 수는 benchmark 난도에 따라 다르다.
일반 benchmark에서는 T=10, AIME24/25처럼 더 긴 추론이 필요한 경우에는 T=40을 사용한다.
마지막 답변 생성은 greedy decoding으로 수행한다.
즉 QueST는 “여러 후보를 뽑아 투표하는” 방식이 아니라, 질문별 mini training episode를 거친 단일 adapted model inference에 가깝다.
| 구성 요소 | 논문 설정 | 해석 |
|---|---|---|
| 보조 데이터 생성 | base model이 입력 질문 조건부로 문제-해설 쌍 생성 | 외부 corpus 없이 query-local supervision 구성 |
| 업데이트 방식 | LoRA SFT, rank 16 | 추론 시점 비용과 안정성을 위해 업데이트 범위 제한 |
| 기본 보조 문제 수 | N=5 |
성능과 per-query compute 사이의 기본 절충점 |
| 최적화 step | 기본 T=10, AIME는 T=40 |
난도 높은 수학 문제에는 더 긴 적응 사용 |
| 최종 답변 | adapted model의 greedy decoding | self-consistency 투표와 다른 축의 test-time compute 사용 |
공개된 근거에서 확인되는 점
정량 결과의 중심은 7개 수학 benchmark다.
논문은 AMC, Minerva, MATH500, GSM8K, OlympiadBench, AIME25, AIME24에서 Qwen3-4B/8B, Qwen3-4B-Base/8B-Base, OctoThinker-3B/8B를 평가한다.
비교 대상은 TENT와 TLM이며, TTT-NN은 원래 retrieval database를 재현할 수 없어 제외했다고 밝힌다.
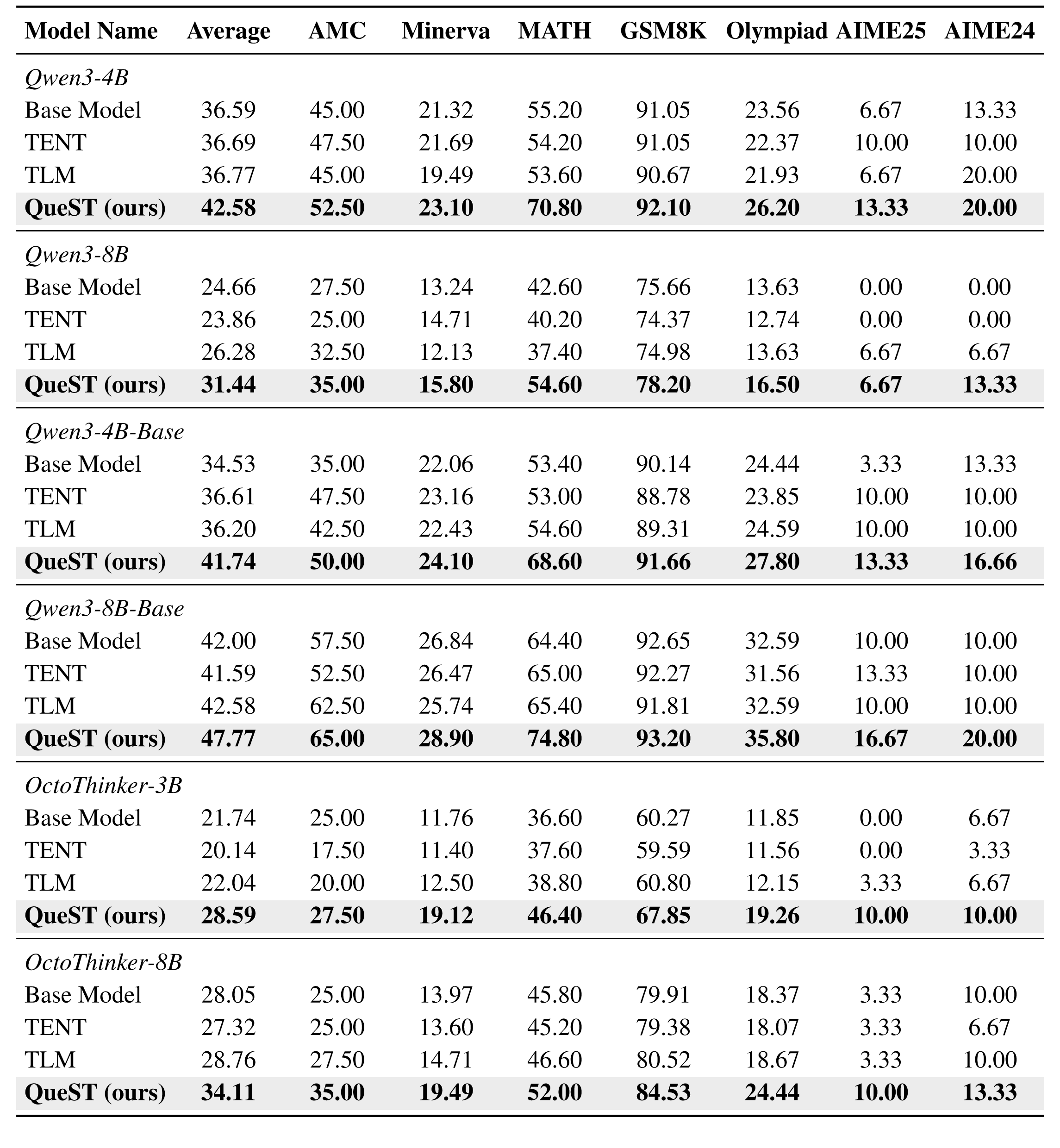
평균 정확도만 추려 보면 개선 폭이 꽤 일정하다.
| 모델 | Base average | QueST average | 개선폭 |
|---|---|---|---|
| Qwen3-4B | 36.59 | 42.58 | +5.99pp |
| Qwen3-8B | 24.66 | 31.44 | +6.78pp |
| Qwen3-4B-Base | 34.53 | 41.74 | +7.21pp |
| Qwen3-8B-Base | 42.00 | 47.77 | +5.77pp |
| OctoThinker-3B | 21.74 | 28.59 | +6.85pp |
| OctoThinker-8B | 28.05 | 34.11 | +6.06pp |
여섯 모델의 평균 개선폭은 약 +6.44 percentage points다.
논문도 이 값을 요약 수치로 제시한다.
중요한 점은 TENT와 TLM이 일부 항목에서 base보다 떨어지거나 아주 작은 개선만 보인 반면, QueST는 모든 모델 평균에서 가장 큰 상승을 보였다는 것이다.
이는 entropy minimization이나 input perplexity minimization 같은 generic objective가 수학적 추론 구조에는 충분히 정렬되지 않을 수 있음을 시사한다.
Ablation도 같은 방향을 가리킨다.
Qwen3-4B-Base / MATH500에서 query conditioning 없이 self-generated QA만 쓰면 58.00, LoRA를 붙여도 58.80이다.
반면 query-conditioned QA는 LoRA 없이도 66.60까지 올라가고, query-conditioned QA와 LoRA를 함께 쓰면 68.60이 된다.
즉 성능의 핵심 신호는 단순히 “자기가 만든 QA”가 아니라 입력 질문에 조건화된 QA다.
GPQA-Diamond 결과도 눈에 띈다.
Qwen3-4B-Base는 22.22에서 QueST 적용 후 46.97로, Qwen3-4B는 32.32에서 51.01로 상승한다.
논문은 이를 수학 영역 밖의 과학 추론으로의 generalization 근거로 제시한다.
다만 여기서도 실험 대상은 제한된 모델·benchmark 조합이므로, 모든 지식형 QA나 도메인 업무에 그대로 일반화된다고 해석해서는 안 된다.

Qualitative analysis는 방법의 장점과 위험을 동시에 보여 준다.
어떤 문제에서는 원래 질문의 구조를 공유하는 보조 문제가 생성되어 baseline 오류를 수정한다.
하지만 appendix의 failure case에서는 표면적으로만 비슷한 문제가 생성되거나, 성공적인 풀이 trace만 학습한 adapted model이 자기 오류를 발견하고도 같은 계산을 반복하는 사례도 제시된다.

실무 관점에서의 해석
QueST의 흥미로운 지점은 test-time compute의 단위를 바꾼다는 데 있다.
많은 test-time scaling 방법은 token budget을 더 많은 reasoning trace나 더 긴 search로 쓴다.
QueST는 같은 inference-time budget을 per-query adaptation budget으로 쓴다.
이 차이는 self-hosted LLM 환경에서는 꽤 중요하다.
LoRA adapter를 질문마다 만들고, 짧게 학습하고, 답변 후 reset하는 방식은 sampling-heavy inference와 완전히 다른 serving profile을 만든다.
장점은 명확하다.
첫째, 외부 검색 데이터가 없어도 된다.
TTT-NN류 방법처럼 유사 문제 corpus를 구축하고 embedding/retrieval 품질을 관리할 필요가 없다.
둘째, supervision이 현재 질문에 묶인다.
이는 특히 수학·과학 추론처럼 “문제 구조”가 성능을 크게 좌우하는 영역에서 강한 신호가 될 수 있다.
셋째, parameter-efficient update라서 full fine-tuning보다 실험 가능한 운영 형태에 가깝다.
하지만 비용과 안정성의 질문은 남는다.
논문 실험은 단일 NVIDIA H200 GPU에서 수행되며, 각 질문마다 보조 문제 생성과 LoRA 업데이트가 들어간다.
API 호출 한 번으로 끝나는 일반 inference와 비교하면 지연시간과 GPU memory scheduling이 훨씬 복잡해진다.
여러 사용자가 동시에 들어오는 서비스에서는 adapter 생성·학습·폐기, batch isolation, cache 전략, 실패 시 fallback 경로를 따로 설계해야 한다.
또 하나의 핵심 리스크는 supervision 품질이다.
질문이 애매하거나 잘못된 전제를 포함하면, 그 질문에서 생성된 보조 문제도 약하거나 오염된 신호가 될 수 있다.
논문도 ambiguity, misleading query, false premise가 adaptation을 악화시킬 수 있다고 말한다.
특히 의료·법률·금융처럼 잘못된 전제가 큰 비용을 만드는 영역에서는 query-conditioned self-training을 그대로 쓰기보다 verifier, constraint checker, retrieval evidence, error-correction trace를 결합해야 할 가능성이 크다.
마지막으로 release maturity는 보수적으로 봐야 한다. arXiv와 프로젝트 페이지는 논문, figure, 결과표, BibTeX를 잘 제공하지만, GitHub 저장소는 현재 코드 공개 전 상태이고 license도 GitHub API 기준 확인되지 않는다.
따라서 QueST는 지금 당장 production inference stack에 꽂을 수 있는 library라기보다, 질문별 test-time learning이라는 방향을 명확히 제시한 연구 prototype으로 보는 것이 정확하다.
그럼에도 이 논문은 test-time reasoning 논의에서 중요한 축을 추가한다.
추론 품질 개선을 “더 많이 샘플링하기”로만 보지 않고, “현재 질문이 제공하는 구조적 신호로 모델을 잠깐 학습시키기”로 바꾼다.
앞으로 inference system은 sampling, verifier, retrieval, confidence policy뿐 아니라, query-conditioned parameter update까지 포함하는 더 넓은 test-time adaptation stack으로 진화할 가능성이 있다.
QueST는 그 방향의 선명한 초기 사례다.