수학 AI의 최근 성과는 두 방향으로 나뉘어 보인다.
한쪽은 자연어 풀이에서 더 강한 reasoning model을 만드는 흐름이고, 다른 한쪽은 Lean, Isabelle, Coq 같은 formal system 위에서 기계적으로 검증 가능한 증명을 만드는 흐름이다.
문제는 두 능력이 자동으로 이어지지 않는다는 점이다.
모델이 비형식 풀이를 잘 설명하더라도, 그 풀이를 Lean 코드로 한 번에 번역해 통과시키는 일은 전혀 다른 난이도의 작업이다.
LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks는 이 간극을 agentic system 설계 문제로 다시 정의한다.
논문의 핵심 주장은 꽤 선명하다.
전문 theorem prover model을 따로 fine-tuning하지 않더라도, 일반 foundation LLM을 비형식 청사진 작성, 하위 목표 분해, AND-OR DAG 메모리, Lean compiler feedback, LLM reviewer가 결합된 루프 안에 넣으면 formal theorem proving 성능을 크게 끌어올릴 수 있다는 것이다.
헤드라인 결과는 강하다.
논문은 LEAP이 2025 Putnam 12문제를 모두 Lean으로 해결했고, 새로 제안한 Lean-IMO-Bench에서는 general-purpose LLM의 one-shot formal solve rate를 10% 미만에서 70%로 끌어올렸다고 보고한다.
하지만 이 글에서 더 중요하게 볼 지점은 “또 하나의 수학 벤치마크 SOTA”보다, 형식 증명용 에이전트가 어떤 작업 기억과 검증 경계를 가져야 하는지를 꽤 구체적으로 보여 준다는 점이다.
무엇을 해결하려는가
LLM은 이미 자연어 수학 문제 풀이에서 강한 신호를 보여 왔다.
그러나 formal mathematics에서는 답이 그럴듯하다는 것만으로 충분하지 않다.
Lean kernel이 받아들이는 theorem statement와 proof term이 있어야 하고, 중간 lemma의 조건, type, dependency가 모두 맞아야 한다.
작은 논리적 비약이나 notation mismatch도 곧바로 compile error가 된다.
논문이 지적하는 병목은 “모델이 수학을 전혀 모른다”가 아니다.
Lean-IMO-Bench에서 Gemini 2.5 Pro는 자연어 proof task에서는 Basic 55.2%, Advanced 17.6%를 보이지만, Gemini 3.1 Pro의 formal theorem proving pass@128은 Basic 20.0%, Advanced 3.3%에 그친다.
심지어 올바른 비형식 proof를 제공하고 formal proof translation task로 바꿔도 pass@128은 크게 나아지지 않는다.
즉 자연어 reasoning과 Lean proof construction 사이에는 별도의 시스템 병목이 있다.
기존 formal theorem proving 연구는 이 병목을 주로 전문화된 prover model, formal corpus fine-tuning, search engine으로 풀어 왔다.
LEAP은 다른 방향을 택한다.
일반 LLM이 이미 가진 informal reasoning과 instruction following 능력을 버리지 않고, 그 능력을 Lean compiler가 계속 검사하는 structured workflow 안에 넣는다.
모델이 긴 Lean proof를 한 번에 맞히는 대신, 증명 계획을 하위 목표로 쪼개고, 검증된 부분만 graph memory에 남기며, 실패한 가지를 다시 고친다.
핵심 아이디어 / 구조 / 동작 방식
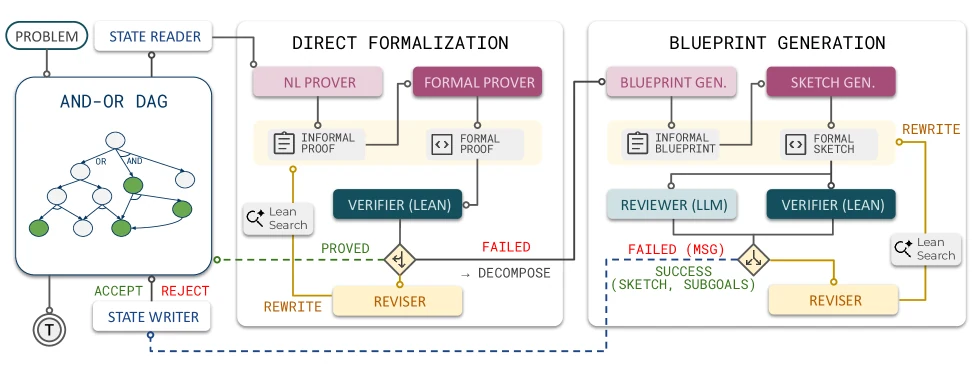
LEAP의 작업 단위는 theorem 하나가 아니라 proof graph다.
입력 theorem은 AND-OR DAG의 root goal로 등록된다.
OR node는 아직 증명해야 할 goal이나 lemma statement를 뜻하고, AND node는 “이 하위 lemma들이 모두 증명되면 parent goal도 증명된다”는 decomposition을 뜻한다.
이 구조 때문에 LEAP은 증명 탐색을 단순한 재귀 호출 스택이 아니라, 공유 가능한 중간 lemma가 쌓이는 작업 공간으로 다룰 수 있다.
동작 흐름은 크게 두 경로다.
첫째, direct formalization 경로다.
LEAP은 현재 goal을 읽고, 먼저 비형식 proof를 작성한 뒤 이를 Lean code로 번역한다.
Lean compiler가 통과시키면 해당 goal은 proved node가 된다.
실패하면 compiler error를 바탕으로 reviser가 수정을 시도한다.
둘째, decomposition 경로다.
직접 증명이 막히면 LEAP은 informal blueprint를 만든다.
이 blueprint는 현재 goal을 어떤 중간 lemma들로 줄일 수 있는지 설명한다.
그 다음 LEAP은 이 blueprint를 Lean proof sketch로 바꾼다.
중요한 제약은 parent theorem body는 sorry 없이 compiler를 통과해야 하고, sorry는 새로 제안된 child lemma 자리에만 허용된다는 점이다.
이 조건을 만족하면 “child lemma들을 나중에 모두 증명하면 parent도 증명된다”는 AND-OR 의미론이 보존된다.
구조를 요약하면 다음과 같다.
| 구성 요소 | LEAP에서의 역할 | 왜 중요한가 |
|---|---|---|
| Informal blueprint | 복잡한 goal을 사람이 읽을 수 있는 proof plan으로 분해 | LLM이 강한 자연어 수학 전략 생성을 활용한다 |
| Lean proof sketch | blueprint가 실제 Lean dependency로 성립하는지 확인 | 그럴듯한 계획과 compiler가 받아들이는 계획을 분리한다 |
| AND-OR DAG | goal, decomposition, lemma dependency를 graph로 저장 | 중간 lemma를 여러 branch에서 재사용하고 search state를 보존한다 |
| Compiler feedback | proof와 sketch를 기계적으로 검증 | 성공 선언을 모델 판단이 아니라 Lean verifier에 묶는다 |
| LLM reviewer | subgoal이 parent보다 쉬운지, 관련 있는지, 유망한지 평가 | 형식적으로 admissible하지만 쓸모없는 decomposition을 걸러낸다 |
| Backtracking / revision | 실패한 proof attempt나 약한 blueprint를 수정·폐기 | 긴 증명에서 한 번의 실패가 전체 작업을 무너뜨리지 않게 한다 |
이 설계의 핵심은 DAG memoization이다.
일반적인 tree search에서는 같은 보조정리가 다른 branch에서 반복해서 등장해도 매번 다시 찾거나 증명해야 한다.
LEAP은 lemma를 graph node로 저장하기 때문에, 이미 증명된 subgoal을 다른 decomposition이 재사용할 수 있다.
논문은 이를 monotone refinement와 lemma memoization으로 설명한다.
한번 만들어진 dependency order는 유지하면서, 국소적인 proof attempt만 수정하거나 확장한다.
또 하나 중요한 점은 reviewer의 위치다.
Lean compiler는 “이 sketch가 type-check되는가”는 말해 줄 수 있지만, “새로 만든 subgoal이 실제로 더 쉬운가”까지 판단하지는 않는다.
예컨대 어떤 decomposition은 형식적으로는 parent를 child로 줄였지만, child가 사실상 grandparent goal을 다시 말하는 것에 불과할 수 있다.
LEAP은 이 지점에 LLM reviewer를 둬서 relevance, simplification, plausibility를 평가하게 한다.
이는 formal verifier와 heuristic reviewer의 역할을 분리한 설계다.
공개된 근거에서 확인되는 점
논문은 Lean-IMO-Bench라는 새 benchmark도 함께 제안한다.
이는 IMO-Bench의 proof problem을 Lean statement로 수작업 formalization한 60문제 세트다.
Basic 30문제는 pre-IMO에서 IMO-Medium 수준이고, Advanced 30문제는 novel problem부터 IMO-Hard 수준까지 포함한다.
분야는 algebra, combinatorics, number theory, geometry로 나뉘며, Lean expert가 모든 statement를 수동 formalize하고 verify했다고 설명한다.
실험 결과는 두 층으로 볼 수 있다.
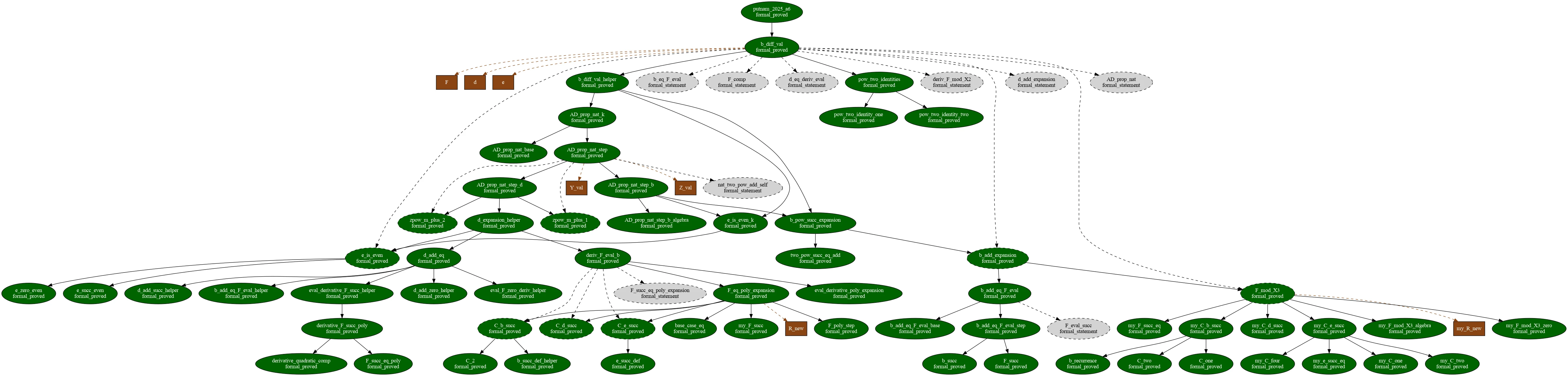
Putnam 2025에서는 direct formalization baseline인 Gemini 3.1 Pro와 Goedel-Prover-V2-32B가 pass@128에서도 0문제를 해결했고, Hilbert는 4/12, Aristotle은 9/12를 해결했다.
LEAP은 rollout=2 설정에서 12/12를 모두 해결했다고 보고된다.
논문은 Hilbert의 recursive search가 redundant LLM call을 많이 만들기 때문에 7일 제한을 두었다고도 설명한다.
Lean-IMO-Bench에서도 같은 패턴이 보인다.
| 방법 | Basic overall | Advanced overall | 해석 |
|---|---|---|---|
| Gemini 3.1 Pro direct formalization | 20.0% | 3.3% | 자연어 reasoning이 곧바로 Lean proof 능력으로 이전되지 않음 |
| Goedel-Prover-V2-32B | 10.0% | 0.0% | specialized prover도 이 benchmark에서는 난도가 높음 |
| Hilbert | 36.6% | 6.6% | agentic search가 도움이 되지만 Advanced에서 급락 |
| Aristotle | 76.7% | 20.0% | 강한 proprietary baseline이지만 난도 상승에 취약 |
| LEAP | 83.3% | 56.7% | DAG memoization과 blueprint-driven search가 가장 높은 solve rate를 보임 |
세부 결과를 보면 LEAP은 Basic과 Advanced 모두에서 algebra와 number theory를 100% 해결했다고 보고한다.
반면 geometry는 Basic 16.7%, Advanced 12.5%로 여전히 낮다.
논문은 olympiad-level geometry formalization이 Lean에서 domain-specific framework 없이 특히 어렵다고 해석한다.
따라서 LEAP의 결과를 “formal math 전체가 해결됐다”가 아니라, algebra/number theory류 문제에서는 구조화된 agentic formalization이 큰 효과를 냈지만 geometry는 여전히 병목이라는 식으로 읽어야 한다.
DAG memoization ablation도 실무적으로 중요하다.
LEAP의 tree variant는 Basic 73.3%, Advanced 40.0%를 기록하고, full DAG는 Basic 83.3%, Advanced 56.7%까지 올라간다.
이는 LEAP의 성능이 단순히 “여러 번 retry했다”에서만 나오지 않는다는 신호다.
중간 lemma를 전역 graph memory로 공유하고, 반복되는 subproblem을 다시 증명하지 않는 구조가 특히 어려운 문제에서 차이를 만든다.
공개 artifact 관점에서는 신중하게 봐야 한다. arXiv HTML은 공식적으로 Lean-IMO-Bench 사이트, google-deepmind/superhuman/leap, Knuth cycles 관련 repository를 연결한다. superhuman/leap 디렉터리는 LEAP.pdf, README, solutions/로 구성되어 있고, 확인 시점의 repository tree에는 LEAP 관련 Lean 파일 58개가 있었다.
그 안에는 Putnam 2025 solution 12개, Lean-IMO-Bench solved solution 42개, open-problem solution 2개와 원문 statement 2개가 포함된다.
다만 이 공개물은 “LEAP framework 전체 코드”라기보다 논문 결과로 나온 Lean 4 proof artifact에 가깝다.
README도 이 디렉터리가 LEAP paper의 Lean 4 proof results를 담고 있다고 설명한다.
GitHub API 기준 repository는 stars 749, forks 75, default branch main, Apache-2.0 license로 확인되지만, releases/latest는 404였고 tags는 비어 있었다.
따라서 재현 가능한 end-to-end prover package라기보다, 논문과 검증된 Lean proof 결과를 공개한 연구 artifact로 보는 편이 안전하다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv paper / HTML | workflow, benchmark, tables, figure, companion links | 방법론과 실험 근거의 중심 |
| Lean-IMO-Bench / IMO-Bench | 60개 IMO-style proof problem의 Lean formalization 기반 | saturated benchmark를 넘어서는 formal proving 평가 시도 |
google-deepmind/superhuman/leap |
README, PDF, Putnam/Lean-IMO/open-problem Lean proof results | 결과 검토용 proof artifact는 공개됨 |
| Releases / tags | GitHub releases/latest 404, tags empty | 안정 배포된 framework package로 보기는 어려움 |
| License | software Apache-2.0, 기타 material CC-BY 4.0로 설명 | 연구 artifact 재사용 조건은 비교적 명확함 |
실무 관점에서의 해석
LEAP의 가장 큰 메시지는 formal theorem proving을 “더 강한 모델 하나”가 아니라 검증 가능한 작업 운영체제로 봐야 한다는 점이다.
Lean proof는 긴 코드 생성 문제가 아니라, 하위 목표의 설계, dependency 관리, 실패한 attempt의 수정, 유망하지 않은 decomposition의 폐기, 이미 증명한 lemma의 재사용이 모두 필요한 작업이다.
이는 소프트웨어 엔지니어링 agent가 테스트, 타입체커, build log, code review를 엮어야 하는 이유와도 닮아 있다.
이 관점에서 LEAP은 AI-for-math만의 사례가 아니다.
어려운 domain task에서 LLM이 잘하는 것은 종종 “최종 artifact를 한 번에 쓰기”보다 “좋은 중간 표현을 제안하고, verifier feedback을 읽고, 다음 시도를 선택하기”다.
LEAP은 그 중간 표현을 informal blueprint와 Lean proof sketch로 나누고, 상태 저장소를 AND-OR DAG로 둔다.
이 조합은 다른 고신뢰 도메인에도 번역될 수 있다.
예를 들어 program synthesis에서는 test-passing subproblem graph, hardware verification에서는 lemma dependency graph, scientific workflow에서는 hypothesis-experiment-result graph가 비슷한 역할을 할 수 있다.
또 하나의 실무적 교훈은 reviewer와 verifier를 혼동하지 않는 것이다.
LEAP에서 Lean compiler는 엄격하지만 좁은 verifier다.
반대로 LLM reviewer는 넓지만 fallible한 heuristic filter다.
두 역할을 섞어 “LLM이 검토했으니 맞다”라고 해석하면 위험하고, 반대로 compiler만 믿고 decomposition quality를 방치해도 search budget이 낭비된다.
좋은 agentic system은 둘을 분리해 배치해야 한다.
확정은 verifier가 하고, 탐색 우선순위와 branch pruning은 reviewer가 돕는 구조가 더 현실적이다.
물론 한계도 분명하다.
첫째, 계산 비용이 작지 않다.
Putnam 2025 문제별 runtime table을 보면 LEAP은 문제에 따라 수십에서 수천 회의 LLM call을 사용한다.
가장 큰 경우는 3.0k call, active node 170개, Lean proof length 2.0k lines까지 간다.
이는 LEAP이 “cheap one-shot prover”가 아니라, 많은 시도와 검증을 조직하는 search system임을 뜻한다.
둘째, 공개 release는 아직 end-to-end 실행 가능한 LEAP framework라기보다 proof result bundle에 가깝다.
따라서 지금 팀이 바로 가져가서 돌릴 수 있는 것은 Lean solution files와 benchmark artifact이지, 논문 전체 workflow를 재현하는 packaged prover는 아니다.
셋째, geometry 결과가 낮게 남아 있다는 사실은 formal math에서 domain-specific representation과 library support가 여전히 중요하다는 점을 보여 준다.
그럼에도 LEAP은 중요한 방향을 제시한다.
형식 증명에서 LLM을 신뢰하려면 모델의 답을 믿는 것이 아니라, 모델을 verifier가 지배하는 loop 안에 넣어야 한다.
그리고 그 loop가 오래 달리려면 단순 retry가 아니라 stateful proof graph, reusable lemma memory, decomposition review, compiler-grounded acceptance가 필요하다.
LEAP은 이 설계를 수학이라는 가장 엄격한 도메인에서 꽤 설득력 있게 보여 준다.
한 줄로 요약하면
LEAP은 일반 LLM이 Lean proof를 한 번에 잘 쓰게 만드는 논문이라기보다, 일반 LLM을 청사진을 만들고, 하위 정리를 계획하고, compiler feedback으로 검증하며, DAG memory로 증명 탐색을 누적하는 formal proving agent로 바꾸는 시스템 설계 논문이다.