Gemma 4 계열은 이미 온디바이스·로컬 퍼스트 공개 모델 경쟁에서 꽤 공격적인 포지션을 잡고 있었다.
E2B/E4B는 모바일과 엣지를, 26B A4B MoE와 31B Dense는 소비자 GPU와 워크스테이션을 겨냥했다.
그런데 그 사이에는 실무적으로 중요한 빈틈이 있었다.
4B급은 가볍지만 복잡한 코딩·멀티모달 에이전트에는 아쉽고, 26B/31B는 성능은 좋지만 노트북에서 상시 띄워 두기에는 부담이 크다.
Google이 공개한 Gemma 4 12B Unified는 이 중간 지점을 정면으로 겨냥한다.
공식 런치 글은 이 모델을 “노트북에 agentic multimodal intelligence를 가져오기 위한” 모델로 설명하고, 개발자 가이드는 더 구체적으로 dense multimodal model with a unified, encoder-free architecture라고 부른다.
핵심은 12B라는 크기 자체보다, 이미지와 오디오를 별도 encoder로 먼저 처리하지 않고 단일 decoder-only transformer에 직접 밀어 넣는 설계다.
이 릴리스는 단순히 새 체크포인트 하나를 추가한 사건이라기보다, Google이 공개 모델을 로컬 에이전트 제품 스택으로 묶는 방식이 더 선명해졌다는 신호에 가깝다.
Hugging Face와 Kaggle의 가중치, Transformers/llama.cpp/MLX/vLLM/SGLang/Unsloth 경로, LiteRT-LM의 OpenAI 호환 로컬 서버, Google AI Edge Gallery와 Eloquent의 macOS 앱, 그리고 Gemma 전용 skills repository가 한 번에 같이 등장한다.
모델·런타임·데스크톱 UX·에이전트 스킬을 같은 릴리스 표면으로 묶은 셈이다.

무엇을 해결하려는가
Gemma 4 12B가 겨냥하는 첫 번째 병목은 로컬 멀티모달 에이전트의 메모리·지연 균형이다.
기존 멀티모달 모델은 보통 이미지나 오디오를 별도 encoder에 통과시킨 뒤, 그 표현을 LLM 토큰 공간에 맞춰 projection한다.
이 방식은 강력하지만, encoder 가중치와 중간 표현이 따로 필요하고, fine-tuning이나 런타임 최적화에서도 여러 모듈을 함께 관리해야 한다.
노트북이나 통합 메모리 환경에서는 이런 분리 구조가 곧 latency와 memory fragmentation으로 이어진다.
두 번째 병목은 오디오를 포함한 중간 크기 공개 모델의 부재다.
Google 개발자 가이드는 기존 Gemma family에서 오디오 입력이 E4B 같은 작은 edge architecture에 제한되어 있었다고 설명한다.
12B Unified는 이 제약을 풀어, 텍스트·이미지·오디오·비디오 프레임을 모두 다루는 중간 체급 모델로 자리 잡는다.
음성 명령, 화면/이미지 이해, 로컬 코드 실행, 문서 분석을 하나의 에이전트 루프로 묶으려면 이 조합이 중요하다.
세 번째 병목은 런타임 표면이다.
로컬 AI 제품에서 “모델이 공개됐다”는 말만으로는 부족하다.
사용자는 LM Studio나 Ollama로 바로 시험해 보고 싶고, 개발자는 OpenAI 호환 로컬 endpoint를 원하며, 코딩 에이전트는 함수 호출·시스템 프롬프트·멀티모달 입력 순서·thinking mode를 안정적으로 처리해야 한다.
Gemma 4 12B 릴리스가 LiteRT-LM, Google AI Edge Gallery, Eloquent, gemma-skills, MTP drafter와 함께 묶인 이유도 여기에 있다.
핵심 아이디어 / 구조 / 동작 방식
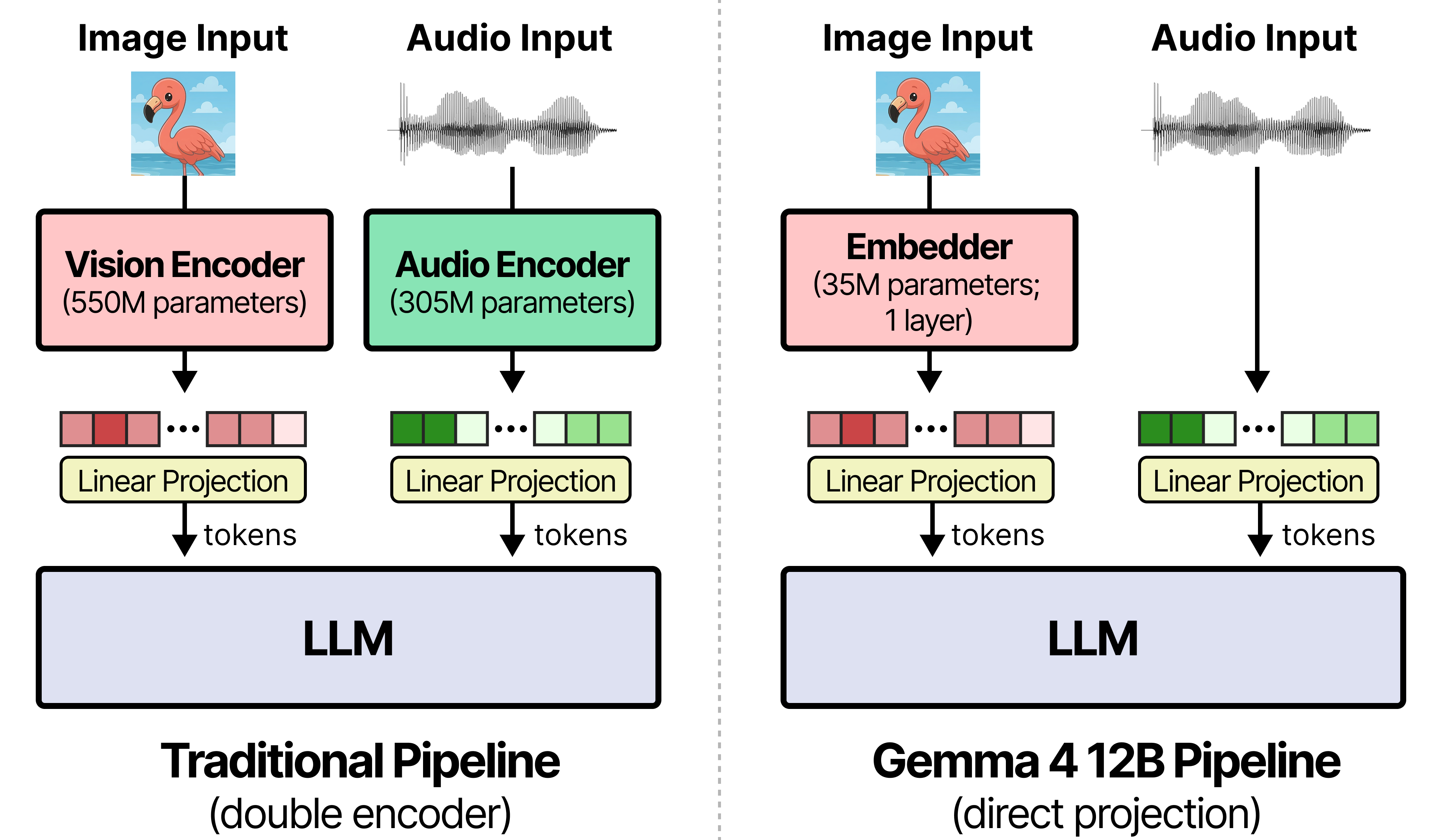
아키텍처의 중심은 encoder-free multimodality다.
개발자 가이드에 따르면 Gemma 4 12B는 Gemma 4 31B Dense와 같은 고급 decoder 구조를 쓰는 단일 decoder-only transformer이며, 별도 비전·오디오 encoder를 제거한다.
Hugging Face 모델 카드와 API 기준 instruction-tuned 모델은 Gemma4UnifiedForConditionalGeneration, gemma4_unified architecture로 공개되어 있고, BF16 safetensors 파라미터 수는 11,959,730,224개다.
비전 경로는 특히 단순하다.
다른 중간 크기 Gemma 4 모델에서 쓰던 27개 vision transformer layer 대신, 12B Unified는 35M parameter vision embedder를 사용한다.
이미지는 raw 48×48 pixel patch로 나뉘고, 이 patch들이 단일 matrix multiplication을 통해 LLM hidden dimension으로 projection된다.
위치 정보는 X/Y factorized coordinate lookup으로 붙는다.
즉 “이미지 전용 tower가 먼저 장면을 이해한 뒤 LLM에 전달한다”가 아니라, LLM backbone이 시각 처리를 더 직접적으로 떠안는 구조다.
오디오 경로도 같은 방향이다.
Gemma 4 E2B/E4B에서 쓰던 12개 conformer layer의 별도 audio encoder를 건너뛰고, raw 16kHz waveform을 40ms frame으로 자른다.
각 frame은 640 floats이며, 이를 LLM input space로 선형 projection한다.
Hugging Face config.json에서도 audio_samples_per_token: 640, audio_embed_dim: 640으로 이 경로를 확인할 수 있다.
이 설계의 fine-tuning 의미도 중요하다.
별도 frozen encoder를 co-tune하지 않아도 되므로, LoRA나 adapter, full fine-tuning이 텍스트·비전·오디오가 공유하는 같은 weight loop를 한 번에 업데이트할 수 있다.
모델 카드도 Hugging Face와 Unsloth를 통한 fine-tuning 경로를 언급한다.
실무적으로는 domain-specific voice assistant, 시각 문서 처리, 로컬 코딩 도구처럼 modality가 섞인 작업에서 tuning surface가 단순해진다.
다만 “encoder-free”를 “전처리가 전혀 없다”로 읽으면 안 된다.
비전에는 35M embedder와 위치 lookup이 있고, 오디오에는 waveform projection이 있다.
차이는 별도 대형 encoder stack이 multimodal representation을 먼저 완성하는 방식이 아니라, lightweight projection 뒤에 LLM backbone이 더 많은 해석 부담을 진다는 점이다.
| 축 | Gemma 4 12B Unified에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| 모델 형태 | 11.95B dense, gemma4_unified, 48 layers |
26B MoE/31B Dense보다 노트북 친화적인 중간 체급 |
| 입력 modality | Text, Image, Audio, Video frame 입력 | 로컬 음성·시각·코딩 agent loop에 적합 |
| 비전 경로 | 48×48 raw patch, 35M vision embedder, X/Y coordinate lookup | 별도 vision transformer encoder stack 제거 |
| 오디오 경로 | 16kHz audio를 40ms/640-float frame으로 projection | conformer encoder 없이 waveform을 token stream에 연결 |
| 컨텍스트/토큰 | 모델 카드 표는 12B 256K context, 현재 HF config는 max_position_embeddings: 131072 |
실제 배포에서는 카드·config·runtime limit를 함께 확인해야 함 |
| 라이선스/배포 | Apache 2.0, public/ungated HF repo, Kaggle, LiteRT-LM 변환 모델 | 연구·제품 실험에 접근성은 높지만 runtime별 검증은 필요 |
공개된 근거에서 확인되는 점
성능표에서 12B Unified는 단순히 “작은 모델”이라고 보기 어려운 위치를 잡는다.
Hugging Face 모델 카드의 공식 benchmark table 기준 Gemma 4 12B Unified는 MMLU Pro 77.2%, AIME 2026 no tools 77.5%, LiveCodeBench v6 72.0%, GPQA Diamond 78.8%, MMMU Pro 69.1%, MATH-Vision 79.7%를 기록한다.
31B Dense나 26B A4B에 비하면 낮은 항목이 많지만, E4B/E2B와는 꽤 큰 차이를 만든다.
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 12B Unified | 해석 |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 77.2% | 일반 지식·추론에서는 상위 모델과 격차가 남음 |
| AIME 2026 no tools | 89.2% | 88.3% | 77.5% | 수학 reasoning은 12B 체급치고 강하지만 26B 이상과는 차이 |
| LiveCodeBench v6 | 80.0% | 77.1% | 72.0% | 로컬 coding assistant 후보로 볼 만한 수준 |
| GPQA Diamond | 84.3% | 82.3% | 78.8% | 과학·전문 QA에서는 12B가 꽤 근접 |
| Tau2 평균 | 76.9% | 68.2% | 69.0% | agentic tool-use 평균에서는 26B A4B와 비슷하거나 약간 앞섬 |
| MMMU Pro | 76.9% | 73.8% | 69.1% | 멀티모달 reasoning도 E4B보다 높은 중간층을 형성 |
오디오 쪽은 12B Unified의 차별점이다.
모델 카드 기준 CoVoST는 38.5, FLEURS는 0.069로 표시되며, FLEURS는 낮을수록 좋다.
12B 표에는 “excluding Chinese language” 주석이 붙어 있어 그대로 일반화하면 안 되지만, E4B/E2B보다 큰 모델에서 native audio path를 제공한다는 점은 로컬 transcription·voice editing·spoken command agent 관점에서 중요하다.
릴리스 표면도 넓다.
Hugging Face API 기준 google/gemma-4-12B-it는 public, ungated이며 model.safetensors, config.json, generation_config.json, processor_config.json, tokenizer, chat template를 포함한다. usedStorage는 약 23.95GB이고, 같은 컬렉션에는 base model, assistant drafter 계열, E2B/E4B/26B/31B 모델이 함께 묶여 있다.
별도로 litert-community/gemma-4-12B-it-litert-lm repo에는 gemma-4-12B-it.litertlm 파일이 올라와 있어 LiteRT-LM 로컬 실행 경로도 분리되어 있다.
개발자 가이드의 예시는 이 모델이 어떤 워크로드를 상정하는지 잘 보여 준다.
하나는 llama.cpp로 로컬 serving한 Gemma 4 12B가 OpenCode와 gemma-skills를 통해 Gradio 이미지 처리 앱을 작성하고, 그 앱이 다시 같은 Gemma 4 12B를 runtime model로 쓰는 사례다.
다른 하나는 Google I/O keynote의 약 5분 구간에서 1FPS로 추출한 313개 frame과 audio, prompt를 함께 넣어 “셀피 장면에서 무슨 일이 일어나는가”를 묻는 비디오 이해 사례다.
LiteRT-LM 쪽 발표도 주목할 만하다.
Google AI Edge 문서는 LiteRT-LM CLI가 Linux, macOS, Windows, Raspberry Pi에서 .litertlm 모델을 실행하고, interactive chat, multimodality attachment, function calling, Multi-Token Prediction, OpenAI-compatible server를 지원한다고 설명한다.
개발자 가이드의 예시 명령도 litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm ... 뒤에 litert-lm serve를 실행하는 형태다.
즉 로컬 앱이 기존 OpenAI-compatible client, coding agent, editor extension과 연결될 수 있도록 endpoint 표면을 맞추려는 선택이다.
반대로 caveat도 있다.
첫째, 공식 카드와 config 사이에 context length 해석이 완전히 매끄럽지는 않다.
카드의 Dense Models 표는 12B Unified를 256K context로 적지만, 현재 google/gemma-4-12B-it의 config.json은 max_position_embeddings: 131072를 노출한다.
둘째, 모델 카드의 일반 best practice 섹션은 audio maximum length 30초, video 60초 가이드를 적고 있는데, 개발자 가이드는 5분 I/O 구간 예시를 별도로 보여 준다.
실제 제품에 붙일 때는 “모델 family가 가능하다”와 “내 runtime/processor path에서 안정적으로 처리된다”를 분리해 검증해야 한다.
실무 관점에서의 해석
내가 보기엔 Gemma 4 12B의 핵심은 12B라는 숫자보다 로컬 멀티모달 agent runtime의 기본 단위를 다시 정의하려는 시도에 있다.
지금까지 많은 로컬 모델은 텍스트 채팅이나 코드 보조에 치우쳤고, 멀티모달 입력은 별도 vision model이나 cloud API에 기대는 경우가 많았다.
12B Unified는 음성·이미지·비디오 프레임·텍스트·도구 호출을 같은 모델 카드와 같은 runtime story 안으로 끌어온다.
제품 팀 입장에서 매력적인 부분은 세 가지다.
첫째, 16GB VRAM 또는 unified memory 노트북을 목표로 한다는 점이다.
이는 “서버에서만 가능한 멀티모달 에이전트”가 아니라 개발자 개인 장비에서 반복 실험 가능한 agent loop를 의미한다.
둘째, encoder-free 설계 덕분에 modality별 encoder tuning과 memory fragmentation을 줄일 수 있다.
셋째, LiteRT-LM serve, LM Studio, Ollama, MLX, llama.cpp, vLLM, SGLang, Unsloth 같은 경로가 동시에 열려 있어 프로토타입과 배포 환경 사이의 이동 비용이 낮다.
하지만 이 모델을 곧바로 “로컬 GPT-급 만능 agent”로 읽는 것은 과하다.
31B/26B 대비 benchmark gap은 분명히 있고, 12B는 여전히 retrieval, tool grounding, prompt discipline, safety filtering, quantization별 품질 검증에 의존한다.
또 encoder-free 구조가 latency와 tuning surface를 줄인다는 주장은 설득력 있지만, 실제 앱에서는 이미지 token budget, audio/video 길이, first-token latency, thermal throttling, MTP drafter 사용 여부, batch regime에 따라 체감이 크게 갈릴 수 있다.
오히려 이 릴리스의 진짜 가치는 공개 모델 경쟁의 평가 축을 바꾼 데 있다.
이제 모델 하나의 leaderboard 점수보다 더 중요한 것은 모델이 어떤 로컬 제품 표면으로 내려오는가다.
Gemma 4 12B는 가중치, model card, desktop app, local server CLI, OpenAI-compatible endpoint, agent skills, MTP drafter를 함께 내놓으며 “로컬 에이전트는 모델이 아니라 스택”이라는 메시지를 준다.
따라서 Gemma 4 12B를 채택하려는 팀은 단순히 성능표만 볼 것이 아니라 다음 질문을 먼저 던지는 편이 좋다.
내 앱은 텍스트·이미지·오디오를 실제로 같은 세션에서 섞는가?
사용자의 데이터가 로컬에 남아야 하는가?
OpenAI-compatible local endpoint가 기존 도구 체인과 맞는가?
12B의 품질과 16GB급 로컬 지연 사이의 trade-off가 제품 UX에 맞는가?
이 질문에 “예”가 많다면, Gemma 4 12B Unified는 단순한 신규 공개 모델이 아니라 로컬 멀티모달 에이전트를 실험하기 위한 꽤 현실적인 출발점이 된다.