GRPO는 단일 프롬프트에 대해 여러 completion을 뽑고, 같은 그룹 안의 상대 보상으로 정책을 업데이트하는 비교적 실용적인 RL post-training 방법이다.
하지만 실제 AI 시스템은 점점 단일 프롬프트 하나보다 여러 개의 LM 호출, 서로 다른 프롬프트 템플릿, retriever·외부 API 같은 도구, 그리고 프로그램 제어 흐름으로 구성된다.
RAG 파이프라인, privacy delegation, 멀티홉 검색 에이전트가 모두 이 범주에 들어간다.
Composing Policy Gradients and Prompt Optimization for Language Model Programs는 이 간극을 직접 겨냥한다.
논문의 핵심 질문은 간단하다.
GRPO를 DSPy 같은 LM programming framework의 모듈형 프로그램에 “그 프로그램을 다시 설계하지 않고” 붙일 수 있는가?
저자들은 이를 위해 multi-module GRPO, 줄여서 mmGRPO를 정의하고, 자동 프롬프트 최적화(MIPROv2)와 순차적으로 조합하는 BetterTogether 설정을 실험한다.
공개 표면은 비교적 명확하다.
논문은 arXiv:2508.04660v2로 공개되어 있고, ACM CAIS 2026 accepted paper다.
저자들은 multi-module GRPO를 DSPy 라이브러리 쪽에 공개했다고 밝히며, 논문 소스와 arXiv HTML도 https://github.com/stanfordnlp/dspy, https://dspy.ai를 공식 연결점으로 제시한다.
별도의 독립 benchmark bundle이나 모델 checkpoint release라기보다는, DSPy의 프로그램 최적화 레이어에 online RL optimizer를 추가하는 연구/라이브러리 업데이트로 읽는 편이 정확하다.
무엇을 해결하려는가
표준 GRPO의 학습 단위는 비교적 단순하다.
하나의 prompt q에서 여러 output o_i를 생성하고, 각 output의 reward r_i를 같은 그룹 안에서 정규화해 advantage를 만든다.
이 구조는 수학 문제 풀이처럼 “질문 하나 → 답변 하나” 형태의 작업에는 잘 맞는다.
그러나 LM program에서는 같은 입력 하나가 여러 모듈 호출로 펼쳐진다.
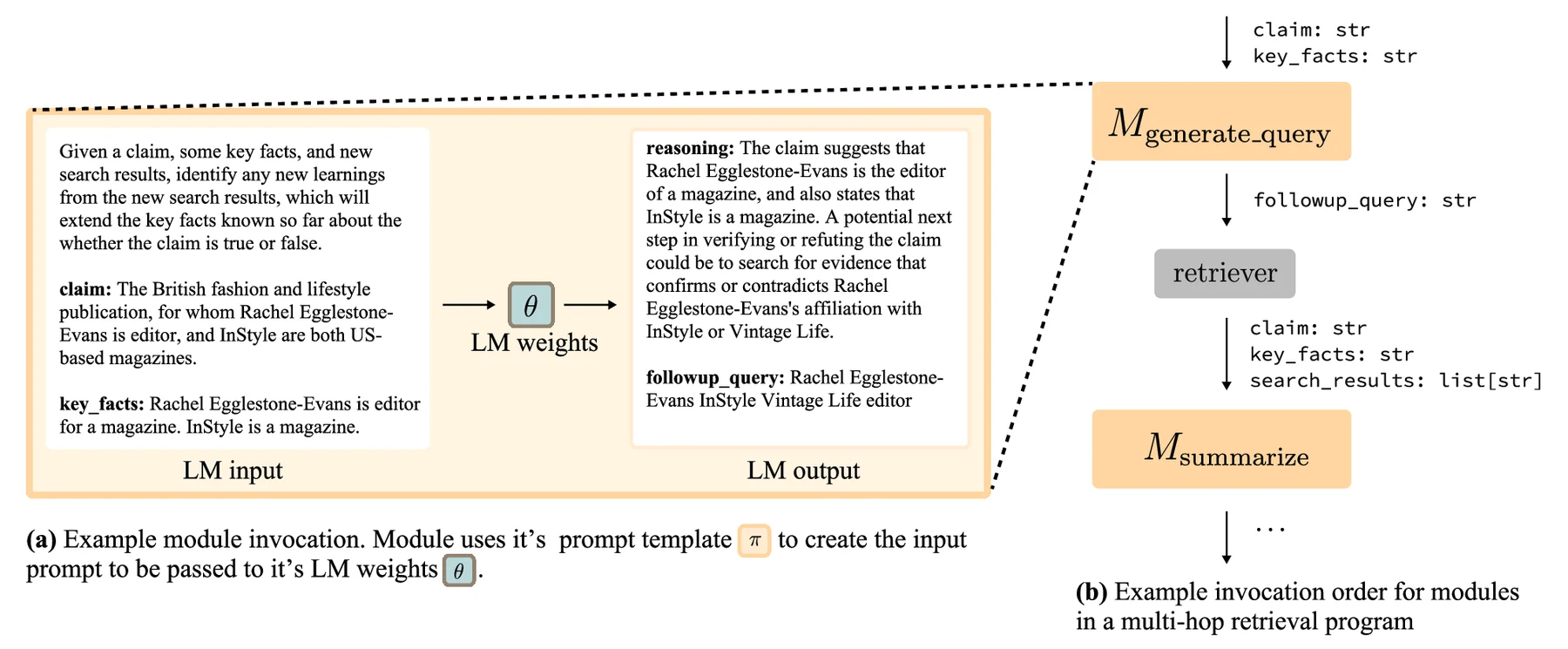
예를 들어 멀티홉 claim verification 프로그램은 먼저 현재 claim에서 검색 쿼리를 만들고, retriever가 문서를 가져오고, 다음 모듈이 핵심 사실을 정리하고, 다시 새 쿼리를 만드는 과정을 여러 번 반복할 수 있다.
PAPILLON 같은 privacy delegation 프로그램은 private query를 redaction한 뒤 untrusted external LM에 보내고, 다시 원래 private query와 외부 응답을 합쳐 최종 답변을 만든다.
Banking77처럼 단일 intent classification 모듈만 있는 경우도 있지만, 논문의 주 관심사는 이런 단일 모듈이 아니라 모듈마다 다른 prompt와 역할을 갖는 프로그램이다.
이때 어려움은 세 가지다.
첫째, reward는 대개 최종 프로그램 출력에 대해서만 나온다.
중간 query나 redaction 문장마다 정답 보상이 주어지는 것이 아니다.
둘째, 각 모듈의 prompt는 다르다.
같은 그룹 안에서 “동일 prompt의 completion”을 비교한다는 표준 GRPO 가정이 깨진다.
셋째, 프로그램 제어 흐름 때문에 trajectory 길이와 모듈 호출 순서가 달라질 수 있다. parsing failure나 조기 종료가 생기면 어떤 trajectory에는 특정 모듈 호출 자체가 없을 수도 있다.
mmGRPO의 목표는 이 복잡성을 숨기는 것이 아니라, LM program이 이미 남기는 execution trace를 학습 데이터로 재구성하는 것이다.
즉 프로그램은 계속 프로그램답게 실행하고, optimizer가 그 trace를 읽어 GRPO group을 만든다.
핵심 아이디어 / 구조 / 동작 방식
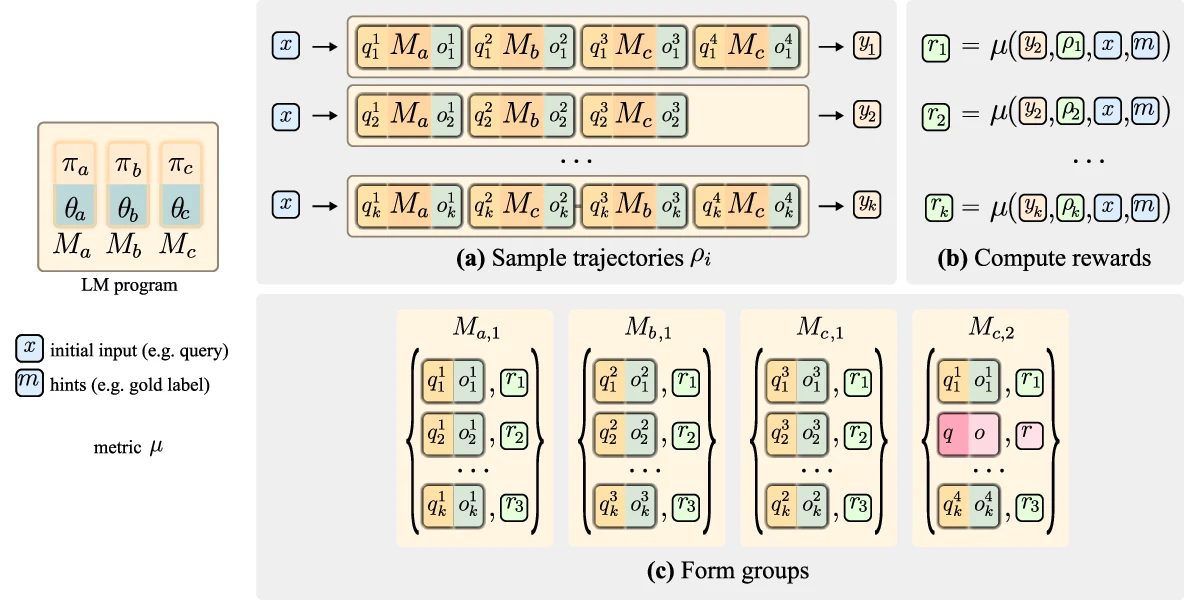
논문의 메인 변형은 module-level mmGRPO다.
같은 프로그램 입력 x에 대해 여러 rollout을 샘플링한 뒤, 각 rollout의 최종 출력 또는 전체 trajectory를 reward function μ로 점수화한다.
그 다음 전체 trajectory를 그대로 하나의 sample로 다루지 않고, 모듈 호출을 (module, invocation index) 기준으로 정렬한다.
예를 들어 “모듈 M_c의 두 번째 호출”에 해당하는 prompt-output-reward triple들을 여러 rollout에서 모아 하나의 GRPO group으로 만든다.
중요한 점은 여기서 각 triple의 prompt가 완전히 같을 필요는 없다는 것이다. upstream context가 다르면 같은 모듈의 같은 번째 호출이라도 local prompt q_i는 달라진다.
그래도 reward는 해당 호출이 속한 전체 프로그램 rollout의 reward를 가져온다.
이렇게 하면 중간 모듈은 별도 supervised label 없이도 “최종 성공에 기여한 방향”으로 업데이트된다.
이 설계는 두 가지 실용적 장점이 있다.
첫째, 기존 prompt-completion GRPO trainer에 비교적 쉽게 올릴 수 있다.
학습 예시는 여전히 local prompt, local output, scalar reward의 형태이기 때문이다.
둘째, 모듈별 출력 길이가 크게 다를 때 각 호출을 자기 output 길이로 정규화할 수 있다.
반대로 단점도 있다. trajectory 구조가 달라지면 alignment와 padding 정책을 정해야 하고, 어떤 모듈 호출이 같은 “상대 위치”인지에 대한 프로그램별 판단이 들어간다.
저자들은 대안으로 trajectory-level mmGRPO도 실험한다.
이 변형은 전체 프로그램 실행을 하나의 그룹 단위로 보고, 최종 reward를 trajectory 안의 모든 LM 토큰에 전파한다. module-level보다 가정이 덜 들어가지만, 긴 trajectory 전체의 token 길이와 credit assignment를 함께 다뤄야 한다.
논문은 메인 결과에는 module-level을 쓰고, HoVer + Qwen3-8B에서 trajectory-level 변형을 별도 ablation으로 확인한다.
여기에 붙는 두 번째 축이 BetterTogether다.
MIPROv2 같은 prompt optimizer는 모듈의 instruction과 few-shot example을 바꿔 더 좋은 rollout 분포를 만든다. mmGRPO는 그 rollout 분포 위에서 weight adapter를 업데이트한다.
논문은 두 절차를 경쟁 관계로 두지 않고, 먼저 MIPROv2로 프롬프트를 최적화한 뒤 그 프로그램을 고정하고 mmGRPO를 돌린다.
해석은 꽤 직관적이다.
온라인 RL은 초반 rollout 품질이 낮으면 좋은 trajectory를 발견하기 어렵다.
프롬프트 최적화가 먼저 탐색 가능한 공간을 좋은 쪽으로 당겨 주면, 이후 GRPO가 더 안정적인 reward signal을 받는다.
공개된 근거에서 확인되는 점
실험은 LangProBe 기반 세 가지 LM program에서 진행된다.
Banking77은 77개 intent classification을 하는 단일 CoT 모듈이다.
PAPILLON은 private query를 redaction하고 외부 LM 응답을 활용해 답변하는 privacy-conscious delegation 프로그램이다.
HoVer 4-HOP은 query generation과 fact summarization 모듈을 여러 hop 동안 반복하면서 ColBERTv2 retriever에서 관련 passage를 찾는 멀티홉 claim verification 프로그램이다.
모델은 Llama 3.1 8B Instruct와 Qwen3-8B를 사용한다. mmGRPO는 Hugging Face TRL의 GRPOTrainer 기반으로 구현되고, 8,192 token train context, LoRA rank 16, learning rate 1e-5, step당 4개 training example과 example당 12 rollout을 사용한다.
논문이 강조하는 점은 intermediate module supervision을 쓰지 않는다는 것이다.
각 방법은 같은 program-level metric만 보고 학습한다.
메인 수치는 다음처럼 요약할 수 있다.
표의 값은 각 task/model pair accuracy 또는 Recall@100 계열 점수이며, 논문 Table 1은 3 seed 평균을 보고한다.
| 전략 | Llama 평균 | Qwen 평균 | 전체 평균 | 읽을 점 |
|---|---|---|---|---|
| Vanilla CoT | 64.7 | 67.8 | 66.3 | 기본 CoT prompt 프로그램 |
| MIPROv2 (PO) | 68.9 | 71.1 | 70.0 | 프롬프트만 최적화해도 강한 baseline |
| mmGRPO | 69.3 | 73.1 | 71.2 | weight adapter 업데이트만으로 Vanilla CoT보다 개선 |
| BetterTogether(PO, mmGRPO) | 72.8 | 73.9 | 73.4 | PO로 rollout 품질을 올린 뒤 mmGRPO를 적용한 조합이 최상 |
논문은 평균적으로 mmGRPO가 Vanilla CoT 대비 7%, MIPROv2가 6%, BetterTogether가 11% 개선된다고 보고한다.
BetterTogether는 MIPROv2 단독 대비 5%, mmGRPO 단독 대비 3% 이득을 낸다.
절대 평균 점수로 보면 전체 평균은 66.3에서 73.4로 올라가며, 특히 HoVer의 Llama 설정에서는 MIPROv2 63.4, mmGRPO 60.2보다 BetterTogether 68.3이 뚜렷하게 높다.
반대로 PAPILLON Qwen 설정에서는 mmGRPO 83.3이 BetterTogether 81.1보다 높다.
즉 조합이 평균적으로 가장 강하지만, 모든 cell에서 무조건 단독 방법을 이기는 것은 아니다.
비용 측면에서는 prompt optimization의 실용성이 분명하다.
논문은 MIPROv2가 평균 1.4시간, H100 1장으로 끝난 반면, vanilla mmGRPO는 평균 18.7시간, H100 2장을 사용했다고 보고한다.
단순 환산하면 mmGRPO는 약 37.4 H100-hours 규모다.
따라서 이 결과를 “항상 RL을 붙이면 된다”로 읽으면 안 된다.
계산 예산이 낮거나 빠른 반복이 중요한 팀에게는 MIPROv2 같은 PO가 더 좋은 첫 선택일 수 있다. mmGRPO의 가치는 그 다음 단계, 즉 이미 괜찮은 프로그램을 더 밀어붙이거나 prompt optimization과 weight optimization을 함께 쓰는 설정에서 커진다.
trajectory-level ablation도 흥미롭다.
저자들은 HoVer + Qwen3-8B에서 전체 프로그램 execution을 group으로 묶는 변형을 실험했고, CISPO loss와 group/batch size tuning을 더했을 때 Recall@100 75.3을 얻었다고 보고한다.
메인 table의 module-level mmGRPO 수치 71.0보다 높다.
이는 “module-level grouping이 유일한 정답”이라기보다, multi-module program을 위한 policy-gradient 설계 공간이 아직 넓다는 신호에 가깝다.
실무 관점에서의 해석
이 논문의 가장 중요한 메시지는 GRPO 자체보다 LM program optimization의 단위가 바뀌고 있다는 점이다.
프롬프트 하나를 잘 쓰는 문제에서, 이제는 여러 모듈이 남긴 trace를 어떻게 학습 신호로 바꿀지가 중요해진다.
DSPy는 원래 signature, module, optimizer를 분리해 “programming, not prompting”을 지향하는 프레임워크다. mmGRPO는 그 철학을 RL 쪽으로 확장한다.
프로그램 코드를 바꾸지 않고 optimizer를 바꿔 끼우며, 같은 metric으로 prompt와 weight를 각각 개선하는 구조다.
특히 에이전트나 RAG 시스템에서는 이 구분이 실용적이다. query generator, note appender, answer synthesizer, redaction module은 실패 방식이 다르다.
하나의 긴 ReAct transcript로만 학습하면 어느 부분이 어떤 역할을 했는지 흐려질 수 있다.
반면 module-level trace를 유지하면 “검색 쿼리를 더 retrieval-oriented하게 만드는 학습”, “중간 note에 verification state를 더 잘 남기는 학습”처럼 행동 변화가 모듈 역할과 연결된다.
논문의 HoVer qualitative case도 이 방향을 보여준다. mmGRPO는 긴 문장형 검색 질문을 더 compact하고 entity-rich한 검색 쿼리로 바꾸거나, 이미 확인된 사실과 아직 부족한 evidence gap을 중간 state에 더 잘 남기는 경향을 보인다.
다만 현재 단계에서는 조심스럽게 봐야 할 부분도 많다.
실험은 8B급 모델과 LoRA fine-tuning에 집중되어 있고, full-parameter update나 더 큰 frontier-scale 모델에서 같은 경향이 유지되는지는 별도 검증이 필요하다.
Banking77은 의도적으로 제한된 reward-only 설정으로 다루기 때문에 supervised encoder baseline과 직접 비교하는 목적이 아니다.
또한 DSPy 문서의 online RL 튜토리얼 표면도 아직 “extremely experimental”에 가깝다.
실제 제품 팀이 바로 production optimizer로 채택하기보다는, 연구/내부 실험에서 시작하는 편이 안전하다.
그럼에도 방향은 분명하다.
프롬프트 최적화는 빠르고 싸게 프로그램의 rollout 분포를 개선한다. policy-gradient RL은 그 분포 위에서 모델 weight를 더 세밀하게 적응시킨다.
둘은 같은 문제를 두 방식으로 푸는 경쟁자가 아니라, 프로그램의 다른 층을 조정하는 상보적 optimizer다. mmGRPO가 흥미로운 이유는 바로 그 접점을 DSPy식 LM program abstraction 안에 넣었다는 데 있다.
앞으로 agent system이 더 모듈화될수록, “어떤 optimizer가 어떤 trace를 읽고 어떤 컴포넌트를 바꿀 것인가”가 모델 선택만큼 중요한 설계 문제가 될 것이다.