리서치 에이전트를 만들 때 가장 먼저 부딪히는 병목은 모델 성능만이 아니다.
에이전트가 웹 페이지 여러 개를 읽고, 각 페이지에서 가격·기능·제약을 뽑고, 다시 Python 코드로 표와 차트를 만들기 시작하면 컨텍스트 창은 금방 원문과 중간 산출물로 가득 찬다.
그 결과 상위 에이전트는 전략적 판단보다 “방금 읽은 긴 텍스트를 들고 버티는 일”에 컨텍스트를 써 버린다.
AWS Machine Learning Blog의 **“Build context-rich research agents with Deep Agents and Bedrock AgentCore”**는 이 문제를 정면으로 쪼갠다.
핵심은 하나의 거대한 리서치 에이전트가 모든 일을 직접 하지 않게 만드는 것이다.
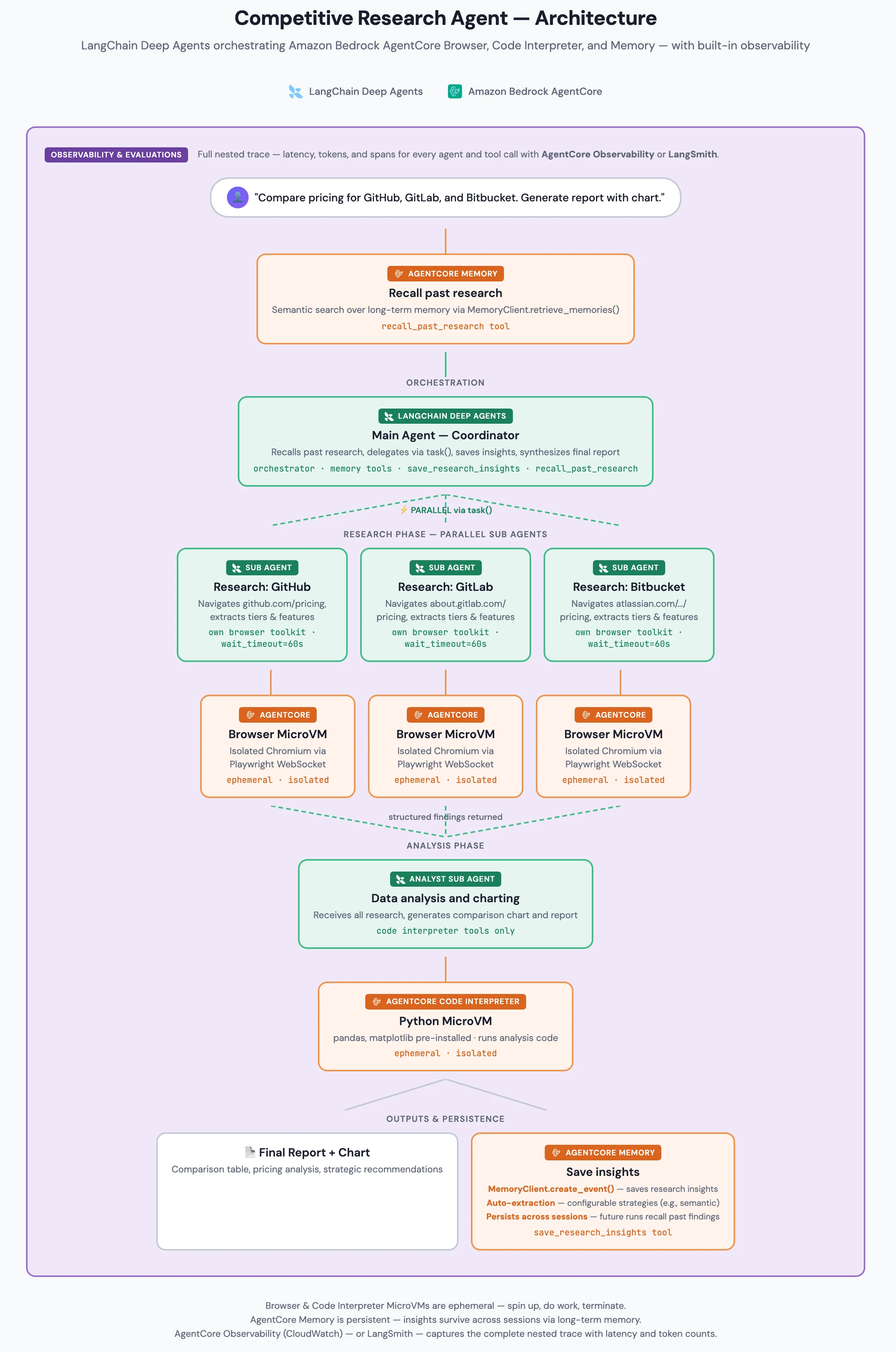
LangChain Deep Agents가 코디네이터와 전문 서브에이전트의 생명주기를 관리하고, Amazon Bedrock AgentCore가 브라우저·코드 실행·메모리·관측성 같은 실행 인프라를 분리된 MicroVM과 관리형 서비스로 제공한다.
예제 자체는 GitHub, GitLab, Bitbucket의 가격 페이지를 비교하는 경쟁사 리서치 에이전트다.
하지만 더 중요한 메시지는 가격 비교가 아니라 리서치 능력을 어떤 실행 경계로 나눌 것인가다.
웹 브라우징, 데이터 분석, 장기 메모리, 추적 로그를 모두 같은 프롬프트 안에 밀어 넣는 대신, 각각을 별도 역할과 별도 실행 환경으로 분리한다.
무엇을 해결하려는가
일반적인 딥리서치형 에이전트는 “많이 읽을수록 똑똑해진다”는 직관과 “많이 읽을수록 컨텍스트가 오염된다”는 현실 사이에 놓인다.
웹 페이지 열 개를 읽으면 원문, 중복 설명, 광고성 문구, 탐색 실패 로그가 모두 모델 앞에 남는다.
여기에 분석 코드, 차트 생성 코드, 중간 JSON, 실패한 tool call까지 들어오면 상위 에이전트가 정말 판단해야 할 비교 기준은 오히려 흐려진다.
AWS 글이 제안하는 구조는 이 압박을 줄이기 위해 리서치 작업을 세 단계로 나눈다.
| 단계 | 담당 주체 | 컨텍스트를 줄이는 방식 |
|---|---|---|
| 정보 수집 | 경쟁사별 browser research subagent | 각 서브에이전트가 자기 사이트의 원문을 읽고, 구조화된 요약만 반환 |
| 분석·시각화 | data analyst subagent + Code Interpreter | Python 실행과 차트 생성을 별도 sandbox에서 처리 |
| 종합·기억 | coordinator + AgentCore Memory | 최종 판단과 재사용 가능한 insight만 상위 상태에 남김 |
이 구조에서 코디네이터는 모든 원문을 직접 들고 있지 않아도 된다.
대신 task()로 병렬 서브에이전트를 호출하고, 각 서브에이전트는 자기 도구와 자기 실행 환경 안에서 깊게 작업한 뒤 결과만 돌려준다.
컨텍스트 창은 “작업장”이 아니라 “종합 회의실”에 가까워진다.
핵심 아이디어 / 구조 / 동작 방식
예제의 중심에는 LangChain Deep Agents의 코디네이터가 있다.
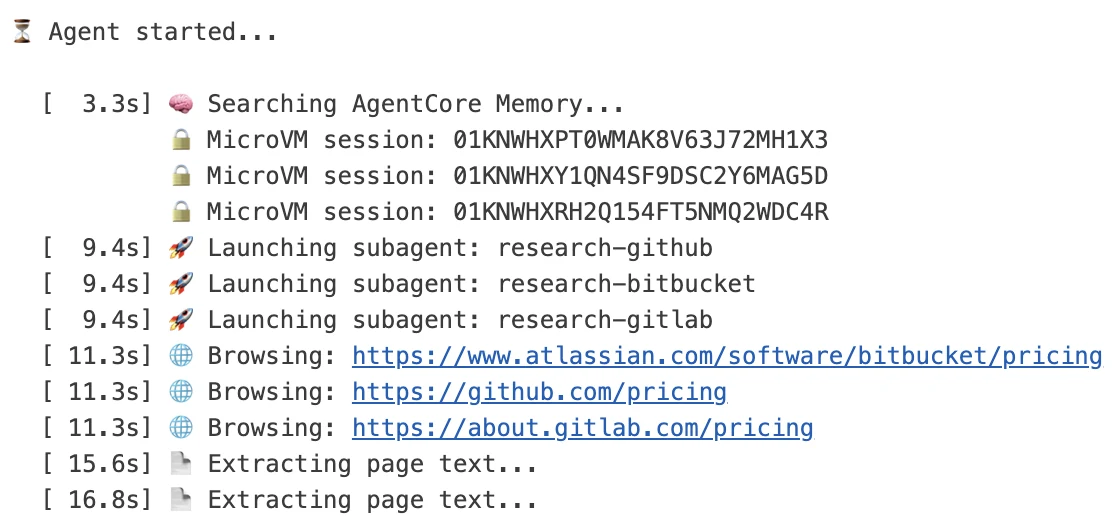
코디네이터는 먼저 AgentCore Memory에서 과거 리서치 insight를 검색할 수 있고, 그 다음 GitHub, GitLab, Bitbucket을 담당하는 세 개의 리서치 서브에이전트를 병렬로 띄운다.
각 리서처는 자기만의 AgentCore Browser toolkit을 갖고, 실제 Chromium 브라우저가 돌아가는 별도 Browser MicroVM에 연결된다.
리서치가 끝나면 세 서브에이전트의 구조화된 결과가 analyst subagent로 넘어간다. analyst는 AgentCore Code Interpreter를 사용해 pandas, matplotlib, numpy가 있는 Python 환경에서 비교표와 차트를 만든다.
마지막으로 코디네이터는 결과를 요약하고, 중요한 insight를 AgentCore Memory에 저장한다.
| 구성 요소 | 공식 예제에서의 역할 | 실무적으로 읽어야 할 점 |
|---|---|---|
| LangChain Deep Agents | create_deep_agent로 코디네이터와 서브에이전트 구성 |
agent harness가 역할 분리와 병렬 위임을 담당 |
| AgentCore Browser | 각 경쟁사 리서처에 별도 Chromium MicroVM 제공 | 웹 탐색 실패와 세션 상태가 다른 리서처로 번지지 않음 |
| AgentCore Code Interpreter | analyst가 Python으로 데이터 분석·차트 생성 | 코드 실행 컨텍스트를 상위 reasoning 컨텍스트와 분리 |
| AgentCore Memory | 과거 리서치 insight 저장·검색 | 매번 처음부터 조사하지 않는 누적 리서치 기반 |
| CloudWatch / LangSmith | nested trace, tool call, latency, token usage 추적 | 병렬 서브에이전트 디버깅과 운영 가시성의 핵심 |
| AgentCore Runtime | 같은 agent를 관리형 session-isolated endpoint로 배포 | notebook prototype을 장기 실행 서비스로 옮기는 경로 |
중요한 점은 각 역할이 접근하는 도구도 다르다는 것이다.
리서처는 browser tools만 받고, analyst는 code interpreter tools만 받으며, 코디네이터는 memory tools를 받는다.
이 단순한 제약은 운영 관점에서 크다.
에이전트가 모든 도구를 다 볼 수 있으면 편해 보이지만, 실패 분석과 권한 설계는 훨씬 어려워진다.
AgentCore는 이 분리를 AWS 쪽 실행 인프라로 받쳐 준다.
공식 문서는 AgentCore를 “어떤 프레임워크와 어떤 foundation model로도 agent를 구축·배포·운영할 수 있는 agentic platform”으로 설명한다.
Runtime은 framework-agnostic이고, 각 사용자 세션을 dedicated microVM에 격리하며, 장기 실행 workload를 최대 8시간까지 지원한다.
즉 이 글의 예제는 LangChain에 묶인 작은 튜토리얼이라기보다, 오픈소스 agent harness와 관리형 agent runtime을 어떻게 접합할지 보여주는 샘플에 가깝다.
공개된 근거에서 확인되는 점
AWS 글과 함께 공개된 langchain-aws notebook을 보면 구현의 구체적인 경계가 꽤 명확하다.
모델은 Amazon Bedrock의 Claude Sonnet 계열을 ChatBedrockConverse로 호출하고, 예제에서는 us.anthropic.claude-sonnet-4-6처럼 us. prefix가 붙은 cross-region inference profile을 사용한다.
브라우저 리서처는 경쟁사마다 create_browser_toolkit(region="us-west-2")를 호출해 각자 toolkit을 만들고, session_wait_timeout을 60초로 늘려 동시 browser operation이 끝날 시간을 확보한다.
AgentCore Browser는 Playwright WebSocket으로 연결되는 실제 Chromium 환경이다.
AWS 글은 세션이 몇 초 안에 뜨고, browser session은 1시간 뒤 자동 만료된다고 설명한다.
Code Interpreter는 pandas, matplotlib, numpy가 설치된 격리 Python MicroVM이며, interpreter session은 15분 뒤 자동 만료된다.
추가 라이브러리가 필요하면 runtime에서 install_packages tool로 설치할 수 있다.
Memory는 특히 주의해서 읽어야 한다.
예제의 save_research_insights는 MemoryClient.create_event()로 대화 이벤트를 저장하지만, AWS 글은 AgentCore Memory 리소스에 semanticMemoryStrategy 같은 extraction strategy가 최소 하나 설정돼 있어야 장기 recall이 동작한다고 강조한다. strategy가 없으면 raw event는 저장되지만, 검색 가능한 insight가 자동 추출되지 않는다.
“메모리에 저장했다”와 “나중에 의미 기반으로 회수할 수 있다”는 같은 말이 아니다.
관측성도 이 아키텍처의 부가 기능이 아니라 필수 축이다.
AgentCore Observability는 OpenTelemetry 형식의 trace와 span을 내보내며, CloudWatch GenAI Observability 화면에서 coordinator run, 각 research subagent span, analyst subagent span, tool input/output, timing, token usage를 볼 수 있다.
CloudWatch Transaction Search는 계정별로 한 번 활성화해야 하고, AgentCore Runtime에 올리면 OTEL instrumentation이 자동으로 붙는다.
Runtime 바깥에서 실행한다면 ADOT SDK와 LangChain instrumentation을 직접 추가해야 한다.
실무 관점에서의 해석
이 글의 가장 실용적인 메시지는 “리서치 에이전트를 더 크게 만들자”가 아니라 실행 경계를 더 작게 나누자에 가깝다.
코디네이터가 모든 사이트를 직접 탐색하고, 같은 컨텍스트에서 코드를 실행하고, 같은 대화 상태에 장기 기억까지 섞으면 빠르게 복잡해진다.
반대로 browser, interpreter, memory, trace를 별도 runtime capability로 분리하면 각 실패를 더 좁은 범위에서 볼 수 있다.
이 패턴은 기업형 리서치 워크플로에 특히 잘 맞는다. due diligence라면 SEC filing, 보도자료, 규제 문서 리서처를 따로 둘 수 있다.
콘텐츠 제작이라면 자료 수집 서브에이전트와 작성 서브에이전트를 분리할 수 있다.
데이터 파이프라인이라면 여러 source extractor가 결과를 만들고 analyst가 join과 변환을 담당하게 할 수 있다.
중요한 것은 “서브에이전트가 많다”가 아니라, 각 서브에이전트의 도구와 실행 환경이 분리된다는 점이다.
도입을 검토할 때는 다음 질문을 먼저 던지는 편이 좋다.
| 체크포인트 | 확인할 질문 |
|---|---|
| 컨텍스트 절약 | 원문 전체를 상위 agent에 넘기지 않고, 구조화된 finding만 넘기는가? |
| 권한 경계 | 리서처, analyst, coordinator가 서로 다른 tool set을 갖는가? |
| 실행 격리 | browser/code 실행이 사용자 세션·파일시스템·네트워크 상태를 오염시키지 않는가? |
| 장기 메모리 | 저장 이벤트와 추출 strategy, recall namespace, 삭제 정책이 함께 설계됐는가? |
| 관측성 | tool input/output, latency, token, 실패 span을 운영자가 실제로 볼 수 있는가? |
| 비용·수명 | 1시간 browser session, 15분 interpreter session, Runtime 최대 8시간 같은 수명과 과금 모델을 이해했는가? |
또 하나의 해석 포인트는 모델 독립성이다.
AWS 글은 같은 구조에서 Bedrock의 Claude를 쓰다가 Anthropic API나 Google Gemini로 바꾸는 예시를 보여준다.
AgentCore Browser, Interpreter, Memory는 모델을 바꿔도 같은 방식으로 쓸 수 있고, Runtime도 특정 프레임워크 하나에 고정되지 않는다.
장기적으로 agent platform을 만드는 팀에게 중요한 것은 “오늘 어떤 모델이 제일 강한가”보다 “모델 교체 후에도 유지되는 실행·권한·관측성 경계가 있는가”다.
한계와 다음 질문
다만 이 예제를 곧바로 완성형 딥리서치 제품으로 읽으면 안 된다.
공개된 notebook은 경쟁사 가격 비교라는 제한된 문제를 다룬다.
공식 글은 Claude Sonnet 기준 4~6분의 실행 시간을 언급하고, 순차 처리보다 최대 3배 빠를 수 있다고 설명하지만, 이는 세 사이트를 병렬 탐색하는 특정 예제의 wall-clock 관찰에 가깝다.
리서치 품질, 출처 검증 정확도, 최신 가격 변화 대응, hallucination 방어는 별도 평가가 필요하다.
보안과 운영도 남는다.
Browser MicroVM과 Code Interpreter가 격리돼 있다는 사실이 곧 정책 설계를 대신하지는 않는다.
어떤 사이트에 접근할 수 있는지, 어떤 파일을 interpreter에 올릴 수 있는지, trace에 민감한 tool input이 남을 때 retention과 redaction은 어떻게 할지, Memory에 저장된 insight를 누가 삭제하거나 scope 제한할 수 있는지는 별도 제품 설계 문제다.
AWS 의존성도 현실적인 고려사항이다.
AgentCore access, IAM permission, region, CloudWatch Transaction Search, Runtime 배포, 가격 정책을 모두 확인해야 한다.
Deep Agents CLI에서 deepagents --sandbox agentcore로 AgentCore CodeInterpreter를 실험할 수 있는 경로가 있지만, 프로덕션에 올릴 때는 notebook보다 훨씬 더 많은 인증·배포·관측성 설정이 필요하다.
정리
이 AWS 글의 가치는 “경쟁사 가격 비교 agent를 만들어 보자”보다 더 넓다.
리서치 에이전트가 길고 복잡한 작업을 할수록, 핵심은 더 큰 프롬프트가 아니라 더 명확한 실행 경계다.
LangChain Deep Agents는 그 경계를 agent harness 차원에서 만들고, Bedrock AgentCore는 browser, code interpreter, memory, runtime, observability를 관리형 runtime capability로 제공한다.
실무적으로는 이 패턴을 그대로 복사하기보다, 현재 팀의 리서치 워크플로에서 어떤 작업이 원문을 많이 소비하는지, 어떤 작업이 코드를 실행해야 하는지, 어떤 insight가 다음 세션에도 남아야 하는지부터 나누는 것이 좋다.
그 경계가 보이면 Deep Agents와 AgentCore 조합은 “컨텍스트가 풍부한 agent”를 만드는 도구라기보다, 컨텍스트를 낭비하지 않는 agent runtime 설계로 읽히기 시작한다.