긴 컨텍스트 LLM은 과거 토큰을 다시 들여다보는 능력 덕분에 많은 문제를 풀었다.
하지만 모든 장기 의존성이 “어디 있었는지 찾아오는” 문제는 아니다.
대화에서 지금 무엇이 참인지, 게임에서 가능한 숫자 범위가 어떻게 줄었는지, 다의어가 문맥 속에서 어느 의미로 고정됐는지처럼, 입력이 들어올 때마다 내부 상태를 갱신해야 하는 문제가 있다.
The Topological Trouble With Transformers는 이 차이를 정면으로 건드린다.
Michael C.
Mozer, Shoaib Ahmed Siddiqui, Rosanne Liu는 arXiv 2604.17121v3에서 Transformer의 순수 feedforward topology가 동적 상태 추적(dynamic state tracking)과 잘 맞지 않는다고 주장한다.
핵심 식은 단순하다.
s_t = f(s_{t-1}, x_t)
여기서 s_t는 현재 belief/world state, x_t는 새 입력이다.
문제는 표준 decoder-only Transformer가 이 업데이트를 recurrent state로 직접 수행하지 않는다는 점이다.
이전 상태와 새 입력을 합쳐 다음 상태를 만들려면, feedforward layer stack 안에서 정보가 점점 더 깊은 layer로 올라가야 한다.
충분히 긴 상태 업데이트가 필요하면 결국 모델의 유한한 depth가 병목이 된다.
무엇을 해결하려는가
논문이 겨냥하는 것은 “Transformer가 기억을 못 한다”는 단순한 주장과 다르다.
Transformer는 오히려 과거 토큰을 검색하는 데 매우 강하다.
저자들이 문제 삼는 것은 검색(retrieval)과 상태 추적(state tracking)이 다른 계산이라는 점이다.
| 구분 | Transformer가 잘하는 경우 | 문제가 커지는 경우 |
|---|---|---|
| 과거 정보 접근 | 문맥 안의 특정 토큰·문장·사실을 다시 찾기 | 과거 사실을 현재 상태로 누적·갱신해야 할 때 |
| 상태 표현 | 모든 히스토리를 보존한 뒤 필요할 때 attention으로 선택 | compact belief state를 매 step 업데이트해야 할 때 |
| 실패 양상 | 관련 문장을 못 찾거나 distractor에 끌림 | 이전 답변과 모순, 해석 flip-flop, 멀티턴 coherence 붕괴 |
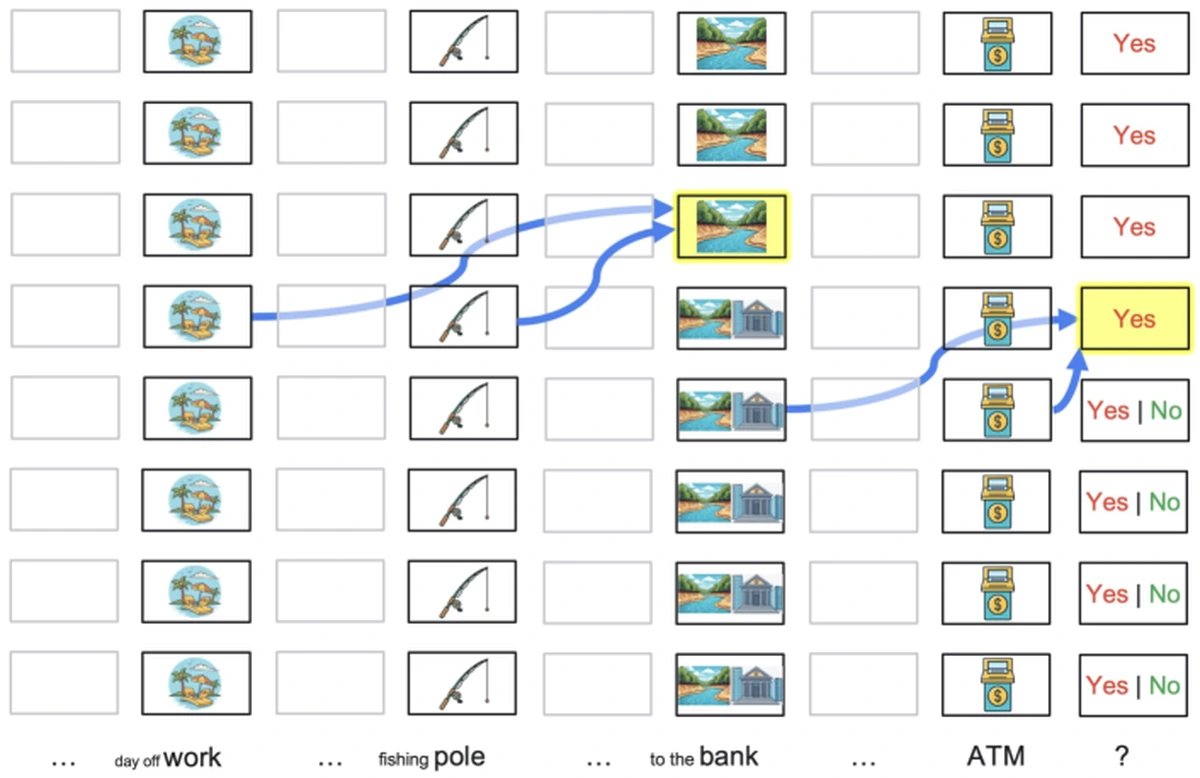
예를 들어 스무고개식 숫자 맞히기 게임에서 모델이 “60보다 낮다”, “41보다 낮다”고 답했다면 가능한 숫자 범위는 41 미만으로 줄어든다.
이후 70에 대해 “higher”라고 답하면 검색 실패라기보다 상태 제약을 유지하지 못한 것이다.
논문은 Gemini 모델의 이런 예시를 보여 주며, 명시적으로 생각을 생성하는 모델도 내부에서 고른 목표 숫자를 이후 답변에 일관되게 쓰지 못할 수 있다고 지적한다.
다의어 예시도 같은 맥락이다. bank를 강둑으로 해석해야 하는 문맥이 깊은 layer에서는 잡히더라도, 그 disambiguated belief가 뒤따르는 토큰의 얕은 layer 계산에 충분히 빨리 전달되지 않으면 모델은 금융기관 의미로 다시 튈 수 있다.
여기서 문제는 “문맥에 단서가 없었다”가 아니라, 이미 만들어진 상태가 다음 계산에 사용 가능한 위치에 있느냐이다.
핵심 아이디어 / 구조 / 동작 방식
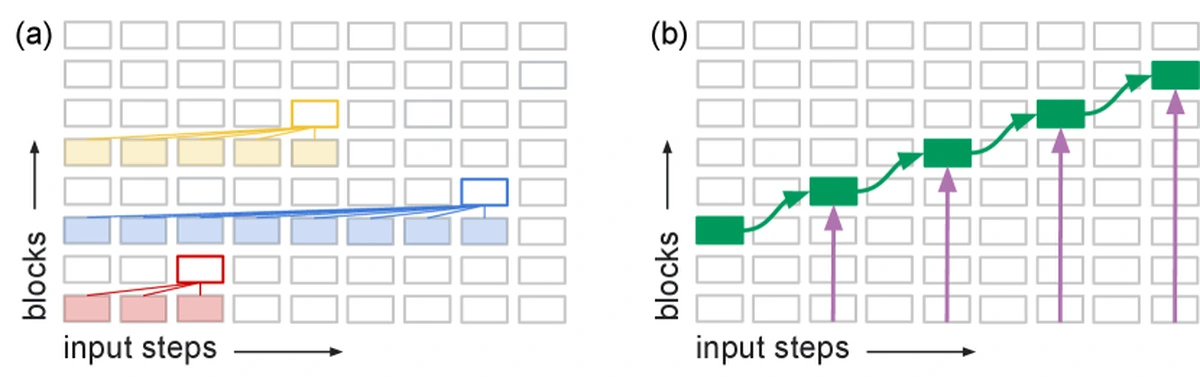
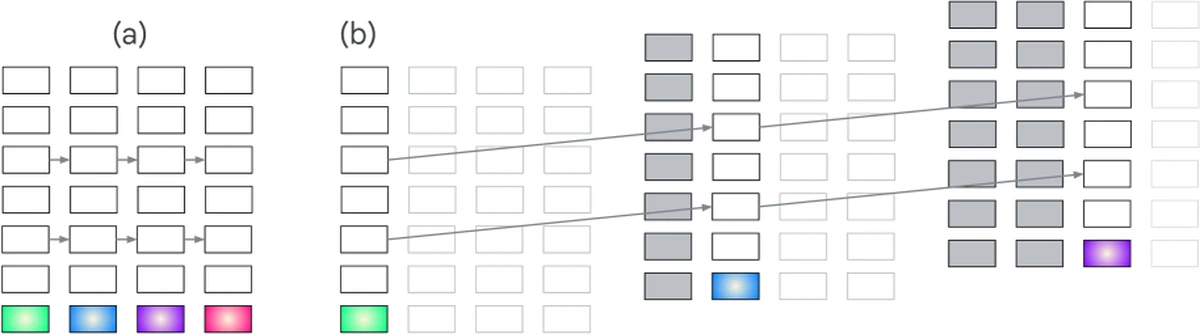
논문의 핵심은 topology다.
순수 feedforward Transformer에서는 각 token position의 activation이 layer 방향으로 위로 흐르고, causal attention은 이전 position의 activation을 참조한다.
따라서 s_{t-1}를 이용해 s_t를 만들고, 다시 s_t를 이용해 s_{t+1}을 만들려면 상태 표현이 step을 지날수록 더 높은 layer에 놓이기 쉽다.
이를 전개하면 다음과 같은 직관이 나온다.
- 첫 입력에서 만든 상태는 비교적 얕은 layer에도 있을 수 있다.
- 두 번째 입력은 이전 상태와 새 입력을 결합해야 하므로 더 깊은 계산이 필요하다.
- 세 번째, 네 번째 업데이트가 이어지면 상태 표현은 계속 layer stack을 올라간다.
- 모델 depth가 유한하므로 긴 상태 업데이트에서는 더 이상 올라갈 곳이 없다.
- 깊은 layer에서 만들어진 최신 상태는 이후 token의 shallow layer가 바로 활용하기 어렵다.
이것이 저자들이 말하는 “topological trouble”이다.
계산량이 부족하다는 말과도 다르고, attention window가 짧다는 말과도 다르다.
정보 흐름의 방향과 recurrent update의 방향이 맞지 않는다는 주장에 가깝다.
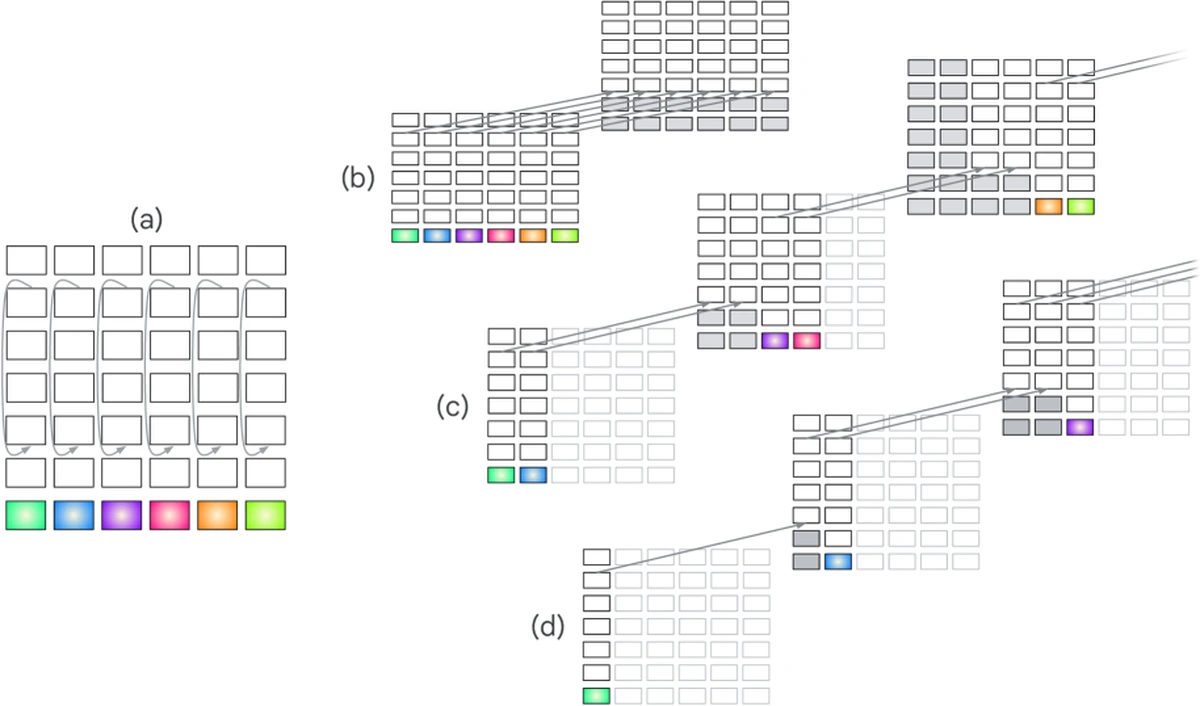
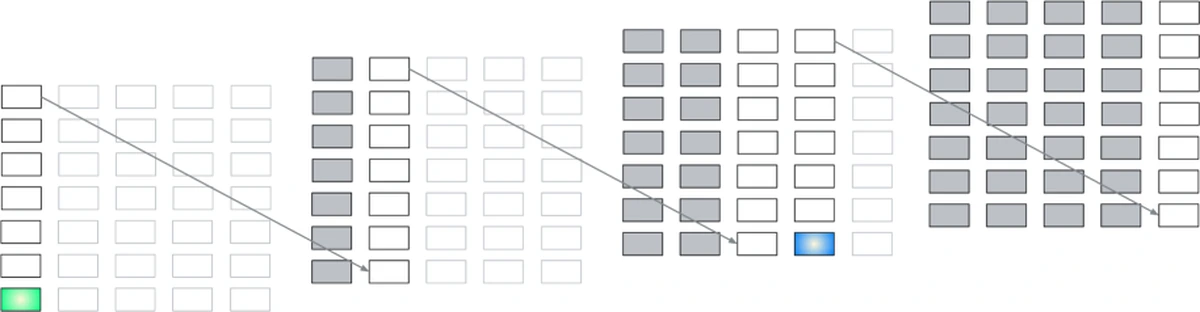
논문은 여기서 recurrent Transformer 계열을 단순히 하나로 묶지 않는다. recurrence가 어디로 흐르는지에 따라 depth-axis recurrence, step-axis recurrence, depth+step recurrence가 다르고, recurrence step당 입력 token 비율이 1보다 큰지, 같은지, 작은지도 구분한다.
이 분류가 중요한 이유는 “반복한다”는 사실만으로 상태 추적 능력이 보장되지 않기 때문이다.
저자들은 가장 인기 있는 일부 recurrence 형태도 충분한 state tracking을 제공하지 못할 수 있다고 본다.
공개된 근거에서 확인되는 점
논문은 새로운 benchmark leaderboard를 제시하기보다는, 상태 추적이 왜 구조적으로 어려운지 설명하고 기존 연구들을 taxonomy로 묶는 입장문에 가깝다.
그래도 공개 본문에서 확인되는 근거는 꽤 구체적이다.
첫째, 상태 추적 실패는 게임, 다의어 해석, 멀티턴 대화, multi-agent cooperation 같은 문제에서 나타난다.
저자들은 foundation model이 긴 문맥을 갖고도 이전 제약을 모순 없이 유지하지 못하거나, 해석을 바꾸고도 그 변화를 인식하지 못하는 사례를 구조적 증상으로 읽는다.
둘째, feedforward depth의 한계는 단순한 직관이 아니라 형식 분석들과 맞닿아 있다.
논문은 Transformer의 serial capacity bound, state representation이 깊은 layer로 밀릴수록 활용이 어려워진다는 분석, chain-of-thought가 표현력을 높이지만 비용이 커진다는 연구들을 연결한다.
셋째, chain-of-thought나 latent thinking은 우회로이지 근본 해결책은 아니라고 본다.
생각 token을 더 생성하면 모델은 외부화된 중간 상태를 다시 입력으로 받아 더 깊은 계산을 흉내낼 수 있다.
하지만 이는 토큰, 메모리, 지연 시간 비용을 늘린다. latent thought도 유사하게 내부 반복을 추가하지만, 여전히 “더 많은 step을 소비해 상태를 외부화/재입력한다”는 비용 구조가 남는다.
넷째, SSM과 recurrent architecture도 한 덩어리로 보면 안 된다.
논문은 선형 update만 갖는 일부 SSM은 표준 Transformer보다 표현력이 강하지 않을 수 있다고 조심스럽게 말한다.
반대로 Delta Net 계열, RWKV-7, PaTH attention처럼 더 풍부한 업데이트를 갖는 방향은 상태 추적 관점에서 유망하다고 본다.
논문이 정리한 유망한 방향은 다음처럼 읽을 수 있다.
| 방향 | 논문이 보는 역할 | 읽을 때의 주의점 |
|---|---|---|
| Enhanced SSM | 병렬 학습 가능성과 더 강한 상태 업데이트를 동시에 노림 | 단순 선형 SSM 전체를 과대평가하면 안 됨 |
| Feedforward 근사 | objective·구조 prior로 Transformer의 lookback 능력을 보강 | recurrence 없이 장기 상태를 얼마나 안정적으로 유지할지는 별도 문제 |
| Coarse recurrence | token마다가 아니라 chunk·sentence·thought 단위로 상태를 전달 | 계산 부담은 줄지만 chunking 기준이 중요 |
| Representational alignment | residual alignment를 활용해 layer/step 간 상태 전달을 쉽게 함 | fine-tuning이나 구조 변경 없이 얼마나 일반화될지는 미지수 |
| Efficient recurrent training | 초기에는 병렬 Transformer로 학습하고 이후 recurrent mechanism을 붙임 | pretraining 효율과 상태 추적 능력 사이의 trade-off를 새로 설계해야 함 |
실무 관점에서의 해석
이 논문은 “Transformer는 끝났다”는 선언이 아니다.
오히려 Transformer가 왜 지금까지 강했는지도 분명히 인정한다.
많은 문제는 전체 문맥을 보존하고 필요할 때 다시 검색하는 방식으로 충분히 풀린다. latch problem처럼 과거의 특정 bit를 오래 유지해야 하는 문제도, Transformer 입장에서는 그 token을 다시 보러 가면 되므로 쉬워질 수 있다.
하지만 agent, long-horizon coding, multi-turn planning, 협력적 multi-agent workflow처럼 상태가 계속 바뀌는 시스템에서는 이야기가 달라진다.
여기서 필요한 것은 “과거에 무엇이 있었나”가 아니라 “지금 상태가 무엇인가”다.
작업 큐, 제약 조건, 사용자 선호, 실패한 시도, 이미 내려진 결정은 매 turn마다 업데이트되어야 한다.
이 업데이트를 매번 자연어 scratchpad나 긴 chain-of-thought에 맡기면 비용과 drift가 함께 커진다.
그래서 이 논문의 실무적 메시지는 꽤 선명하다.
긴 컨텍스트와 CoT는 상태 추적 문제의 증상을 완화할 수 있지만, 제품 수준의 장기 에이전트에서는 더 명시적인 memory/state 설계가 필요하다.
모델 architecture 쪽에서는 recurrent activation dynamics, hybrid SSM, block recurrence, latent state 업데이트가 중요해지고, 시스템 쪽에서는 외부 상태 저장소와 검증 가능한 state transition이 계속 필요하다.
동시에 한계도 분명하다. arXiv 본문과 HTML에서 별도 공식 GitHub 저장소, project page, 모델 artifact는 확인되지 않았다.
따라서 이 글은 runnable framework release 소개가 아니라, Transformer architecture와 추론 방식에 대한 개념적·분류적 논문으로 읽어야 한다.
또한 논문이 드는 실패 사례는 구조적 직관을 보여 주는 데 유용하지만, 특정 최신 모델 전체 성능을 정량적으로 평가하는 benchmark는 아니다.
그럼에도 이 논문은 최근 “더 긴 컨텍스트”, “더 많은 thinking token”, “더 깊은 reasoning trace”로 흘러가는 LLM 논의에 좋은 제동을 건다.
문제는 생각을 더 길게 쓰는 것이 아니라, 바뀌는 세계 상태를 어디에, 어떤 topology로, 얼마나 싸게 유지할 것인가일 수 있다.
다음 세대 foundation model이 단지 과거를 더 잘 재검색하는 시스템이 아니라, 현실의 상태를 계속 갱신하는 시스템이 되려면 recurrence를 다시 진지하게 봐야 한다는 주장이다.