MoE 모델은 계산 효율의 상징처럼 보이지만, 실제 학습 스텝 안으로 들어가면 꽤 지저분한 병목이 나온다.
토큰마다 어떤 expert로 갈지 달라지고, expert별 token count가 runtime에 결정되며, GLU activation과 저정밀 quantization은 큰 tensor를 다시 읽고 다시 쓰는 memory-bound 구간을 만든다.
GPU의 Tensor Core는 빠른데, 그 주변의 동적 shape 질의와 intermediate tensor 이동 때문에 학습 step이 늘어지는 구조다.
NVIDIA의 기술 블로그 “Boosting MoE Training Throughput with Advanced Fusion Kernels”는 이 병목을 CuTe DSL 기반 fused MLP kernel로 줄이는 작업을 소개한다.
핵심은 새로운 MoE 학습 objective가 아니라, 이미 학습 스택 안에 있는 GroupGemm, activation, quantization, transpose, epilogue 처리를 더 깊게 합쳐 GPU가 기다리는 시간을 줄이는 것이다.
NVIDIA는 이 경로가 unfused path 대비 kernel-level 1.3~2배 수준의 개선을 보이고, full-stack DeepSeek-V3 pre-training에서는 8%, GPT-OSS pre-training에서는 93% end-to-end 개선에 기여했다고 설명한다.
이 글의 흥미로운 점은 개선이 한 레이어의 빠른 kernel 하나로 끝나지 않는다는 데 있다.
GLU epilogue fusion, host-device synchronization 제거, MXFP8/NVFP4 quantization fusion, CUDA Graph capture 가능성, 그리고 cuDNN Frontend·Transformer Engine·Megatron Core로 이어지는 배포 경로가 함께 묶인다.
즉 “MoE를 더 빠르게 학습한다”는 주장을 hardware-aware software stack 전체의 재배치로 풀어낸 사례에 가깝다.
무엇을 해결하려는가
표준 MoE 학습 iteration에서 NVIDIA가 지목한 병목은 크게 세 가지다.
첫째는 activation bottleneck이다.
SwiGLU, GeGLU, sReLU 같은 activation은 FC1 출력 전체를 읽고 activation 결과를 다시 쓰는 식으로 memory traffic을 만든다.
메인 GEMM은 Tensor Core에서 빠르게 끝났는데, activation과 그 뒤의 후처리 kernel이 timeline에 노출되면 GPU utilization이 떨어진다.
둘째는 CPU boundedness와 launch overhead다.
MoE에서는 expert별 token 수가 batch마다 달라진다.
기존 multi-stream grouped GEMM 경로는 이 shape 정보를 host가 알아야 kernel launch를 구성할 수 있고, local expert 수가 많아질수록 CPU launch와 host-device synchronization이 늘어난다.
이 동기화 지점은 full-iteration CUDA Graph capture도 어렵게 만든다.
셋째는 quantization cost다.
BF16 activation을 MXFP8이나 NVFP4 같은 더 낮은 precision으로 바꾸는 과정 역시 memory-bound다. activation output을 한 번 쓰고, quantization kernel이 다시 읽고, low-precision output과 transpose output을 다시 쓰면 핵심 GEMM 바깥에서 bandwidth를 계속 쓴다.
Blackwell 세대에서 주요 GEMM이 빨라질수록 이런 주변 memory pass는 더 비싸게 보인다.
핵심 아이디어 / 구조 / 동작 방식
NVIDIA가 제시한 kernel family는 sync-free MoE를 위해 세 가지 경로를 묶는다.
| 융합 경로 | 줄이는 병목 | 본문에서의 역할 |
|---|---|---|
GroupGemm + Quantize |
GEMM 뒤 별도 quantization memory pass | 저정밀 GEMM 입력을 만들기 위한 추가 read/write 축소 |
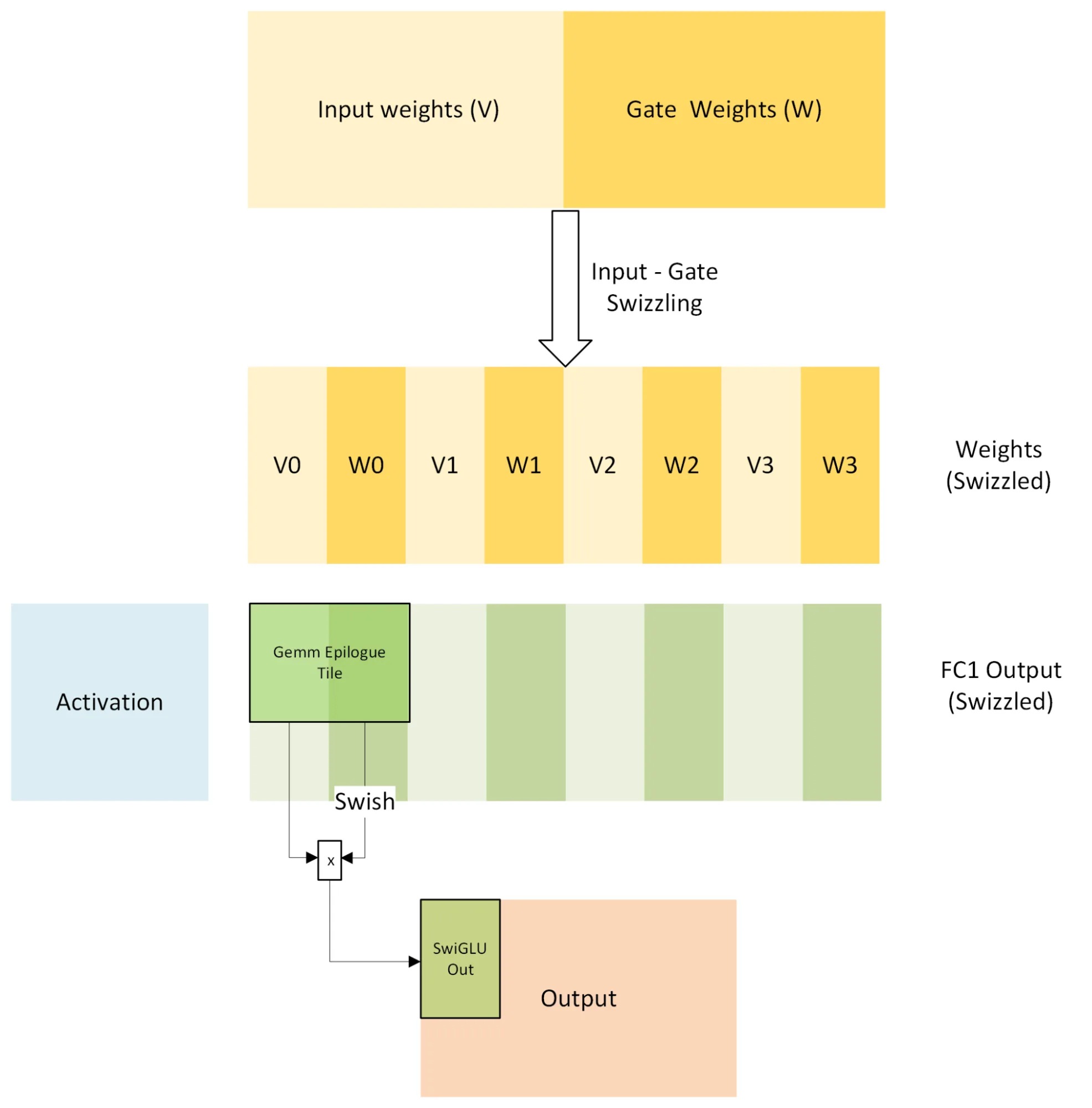
GroupGemm + Activation + Quantize/Transpose |
FC1 output, activation, quantization 사이의 intermediate tensor | forward MoE MLP에서 GLU 계열 activation과 후처리를 epilogue로 흡수 |
GroupGemm + dActivation + Quantize/Transpose |
backward dActivation과 transpose/quantization | FC2 dgrad 이후 backward GLU gradient 경로의 memory traffic 축소 |
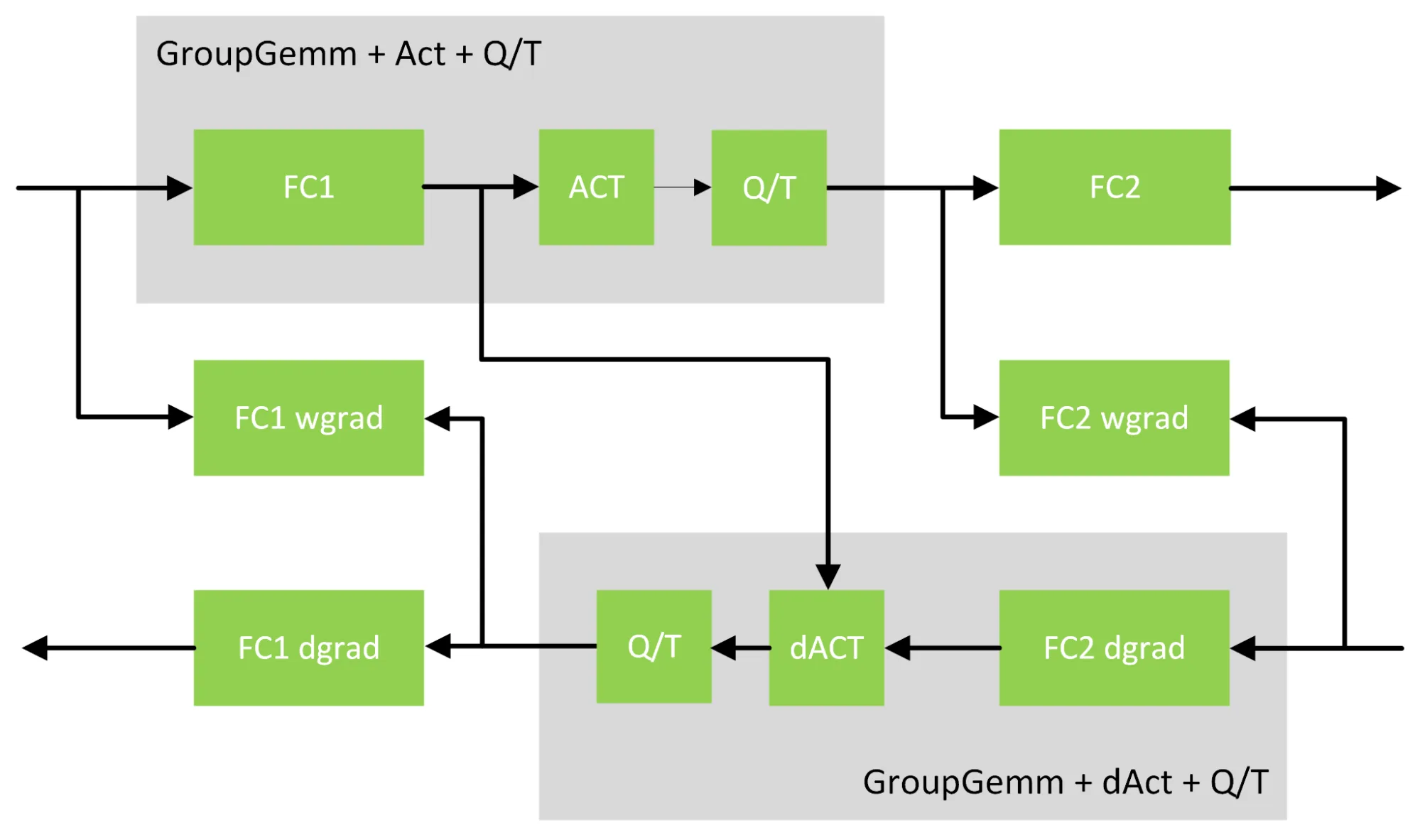
가장 직관적인 예는 GLU activation fusion이다.
SwiGLU는 gate 쪽 값에 Swish를 적용한 뒤 input 쪽 값과 곱해야 한다.
보통은 FC1 출력의 두 chunk를 global memory에 써 두고 다음 kernel에서 다시 결합한다.
NVIDIA의 설명은 weight를 input/gate column이 interleaved되도록 repack해, 같은 thread block이 epilogue 안에서 input half와 gate half를 함께 보게 만드는 방식이다.
그러면 GLU 계산이 GEMM epilogue 안으로 들어가고, 중간 tensor를 global memory에 왕복시키는 일이 줄어든다.
host-device synchronization 제거도 중요하다.
CuTe DSL GroupGEMM kernel은 expert별 token count를 GPU memory 안에서 추적한다.
CPU가 “이번 expert에는 token이 몇 개냐”를 알아내고 launch를 조립하는 대신, device-side 정보로 work를 구성하는 방향이다.
이 덕분에 CPU dependency가 줄고, 전체 iteration을 CUDA Graph로 잡을 수 있는 조건이 좋아진다.
quantization fusion은 MXFP8과 NVFP4 pre-training recipe에 직접 닿아 있다.
MXFP8에서는 activation output BF16을 읽어 MXFP8 output과 transposed output을 만들어야 한다.
NVIDIA는 이 단계를 GEMM kernel 자체에 넣어 BF16 intermediate의 추가 read/write를 줄인다고 설명한다.
NVFP4에서는 forward의 per-tensor amax, backward의 transposed Hadamard rotation output에 대한 amax 계산도 별도 memory pass가 되기 쉬운데, 이 역시 fused path의 대상으로 잡는다.
공개된 근거에서 확인되는 점
NVIDIA 블로그의 headline 수치는 kernel-level과 end-to-end를 분리해서 읽어야 한다.
본문은 fused kernel이 unfused path 대비 forward pass에서 최대 1.3배, backward pass에서 최대 2.1배 빠르다고 설명한다.
또한 full-stack DeepSeek-V3 pre-training setup에서는 8% end-to-end 개선, GPT-OSS pre-training setup에서는 93% end-to-end 개선에 기여했다고 제시한다.
후자는 단일 kernel만의 순수 microbenchmark라기보다, sync-free MoE와 CUDA Graph, communication overlap까지 포함한 application-level 결과로 보는 편이 안전하다.
cuDNN Frontend 저장소의 benchmark/cutedsl_fusion_kernels 디렉터리도 같은 방향의 근거를 제공한다.
README는 fused cuDNN Frontend grouped-GEMM+activation kernel을 unfused Transformer Engine path와 비교한다고 설명하며, 기본 shape는 experts=8, tokens/expert=4096, K=8192, N=4096, BF16이다. timing mode는 CUDA graph replay이고, benchmark 환경은 torch 2.12.0a0+nv26.05, transformer-engine 2.15.0, nvidia-cudnn-frontend 1.23.0, nvidia-cutlass-dsl 4.4.1로 기록되어 있다.
| Activation pattern | GB200 fused cuDNN | GB200 TE baseline | GB200 speedup | GB300 fused cuDNN | GB300 TE baseline | GB300 speedup |
|---|---|---|---|---|---|---|
| SwiGLU | 1.550 ms | 1.934 ms | 1.25× | 1.319 ms | 1.695 ms | 1.28× |
| dSwiGLU | 0.870 ms | 1.734 ms | 1.99× | 0.740 ms | 1.549 ms | 2.09× |
| sReLU | 0.739 ms | 1.041 ms | 1.41× | 0.675 ms | 0.873 ms | 1.29× |
| dSReLU | 0.781 ms | 1.341 ms | 1.72× | 0.686 ms | 1.163 ms | 1.70× |
| GeGLU | 1.544 ms | 1.890 ms | 1.22× | 1.317 ms | 1.631 ms | 1.24× |
| dGeGLU | 0.889 ms | 1.820 ms | 2.05× | 0.751 ms | 1.666 ms | 2.22× |
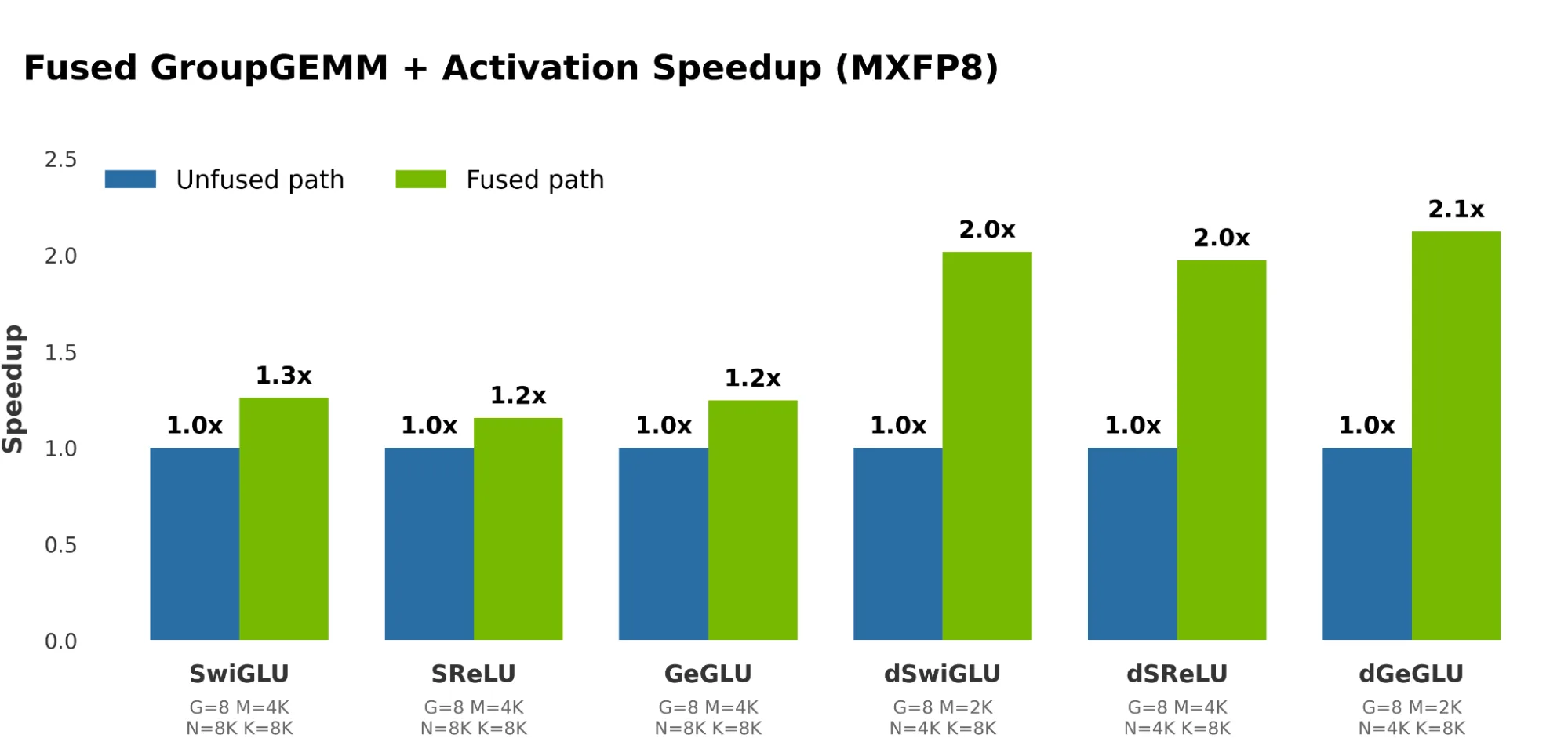
이 표에서 가장 눈에 띄는 부분은 backward GLU 계열이다. dSwiGLU와 dGeGLU는 GB200에서 각각 1.99×, 2.05×, GB300에서 2.09×, 2.22× 개선으로 기록되어 있다. forward GLU 쪽은 1.21.3× 수준이고, sReLU 계열은 1.291.72× 범위다.
즉 “1.3~2×”라는 표현은 activation pattern과 forward/backward 경로별로 꽤 다르게 나뉜다.
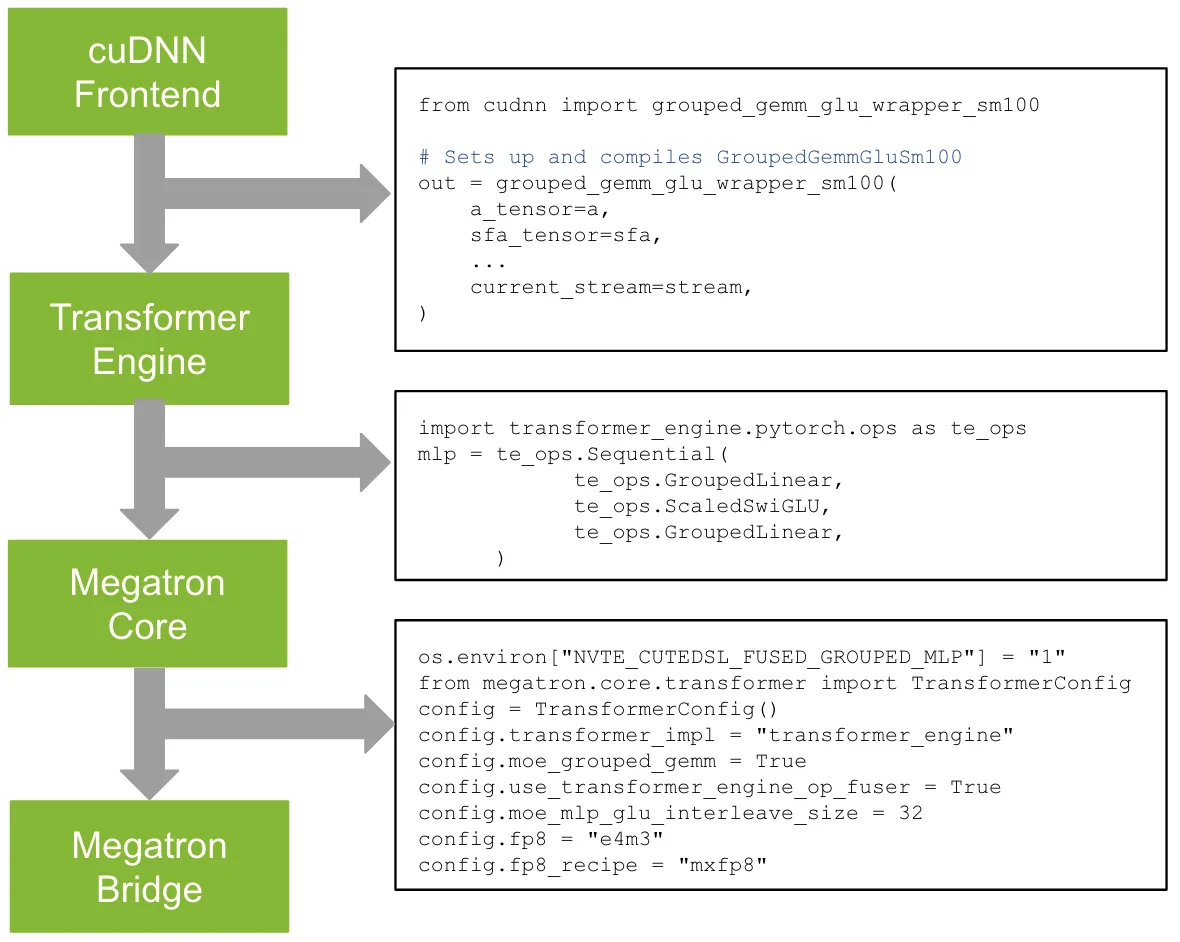
사용 경로도 구체적이다.
블로그는 cuDNN Frontend v1.23.0 이상에서 kernel이 제공되고, Transformer Engine v2.15 이상에서는 transformer_engine.pytorch.ops와 Sequential block의 pattern matching을 통해 접근할 수 있으며, Megatron Core 26.04-alpha.rc2 이상에서는 관련 knob를 통해 사용할 수 있다고 설명한다. cuDNN Frontend README도 첫 invocation에서 kernel을 compile하고 이후 cached object를 재사용하는 wrapper 경로를 언급한다.
NVIDIA는 AOT compilation으로 cubin을 disk에 cache하는 기능도 작업 중이라고 밝힌다.
실무 관점에서의 해석
이 사례의 핵심은 MoE 최적화가 “expert routing 알고리즘을 더 똑똑하게 만든다”에만 있지 않다는 점이다. modern MoE 학습에서는 routing이 만든 동적 shape, GLU activation이 만든 intermediate tensor, low-precision recipe가 만든 quantization pass, expert/data parallel communication overlap이 모두 같은 step time 안에서 경쟁한다.
그래서 한두 개의 kernel을 빠르게 만드는 것보다, CPU가 shape를 묻는 지점과 global memory를 왕복하는 지점을 함께 줄이는 편이 더 큰 end-to-end 효과로 이어질 수 있다.
특히 full-iteration CUDA Graph 가능성은 단순한 편의 기능이 아니다.
학습 iteration 안에 CPU launch나 synchronization이 남아 있으면 GPU가 충분히 빨라도 매 step마다 host가 execution을 다시 조립해야 한다. expert별 token count를 GPU 안에 두고 sync-free grouped GEMM을 구성하면, MoE block이 CUDA Graph-friendly한 형태에 가까워진다. large-scale pre-training에서는 이런 launch overhead 제거가 communication overlap, dynamic scheduling, cluster margin 같은 스케줄링 knob와 만나면서 application-level 개선으로 증폭될 수 있다.
다만 수치를 그대로 일반화하면 안 된다.
공개 benchmark는 NVIDIA GB200/GB300, 특정 grouped GEMM shape, BF16과 MXFP8/NVFP4 주변 경로, Transformer Engine baseline을 전제로 한다.
실제 개선 폭은 local expert 수, activation pattern, communication 비중, precision recipe, CUDA Graph capture 가능 여부, Megatron/Transformer Engine integration 상태에 따라 달라진다.
GPT-OSS pre-training의 93% 개선도 “모든 MoE 학습이 두 배 가까이 빨라진다”는 뜻이 아니라, 특정 full-stack setup에서 sync-free fused path가 크게 노출된 병목을 제거했다는 의미로 읽는 편이 맞다.
그럼에도 방향은 매우 분명하다.
LLM 학습 시스템의 다음 병목은 점점 “수학적으로 필요한 FLOPs”보다 “그 FLOPs를 먹이기 위한 주변 데이터 이동과 동기화”에 가까워진다.
NVIDIA의 CuTe DSL fused MoE kernel은 이 문제를 compiler/kernel/library/framework 경계에서 한 번에 밀어붙인 사례다.
MoE가 더 큰 모델의 기본 구성요소가 될수록, expert를 얼마나 잘 고르느냐만큼이나 expert MLP 주변의 작은 memory pass와 CPU synchronization을 얼마나 없애느냐가 학습 비용을 결정하게 될 것이다.