코딩 에이전트를 오래 쓰면 한 가지 역설이 보인다.
에이전트는 변경을 많이 만들 수 있지만, 그 변경이 정말 좋아졌는지는 자주 흐려진다.
테스트 한두 개가 통과했다고 전체 품질이 좋아졌다고 말하기 어렵고, 반대로 사람이 보기에는 그럴듯한 리팩터링도 실제 지표에는 도움이 되지 않을 수 있다.
그래서 에이전트 자동화에서 중요한 질문은 “얼마나 자율적인가”보다 “무엇을 기준으로 유지하고 버릴 것인가”에 가깝다.
uditgoenka/autoresearch는 이 질문에 꽤 노골적인 답을 준다.
프로젝트의 출발점은 Andrej Karpathy가 공개한 autoresearch다.
Karpathy의 원본은 train.py를 반복 수정하고 5분짜리 학습 실험을 돌린 뒤 val_bpb가 좋아졌는지를 기준으로 변경을 유지하거나 버리는, 매우 좁고 측정 가능한 ML 연구 루프였다.
Claude Autoresearch는 이 구조를 Claude Code, OpenCode, OpenAI Codex 같은 코딩 에이전트의 명령·스킬 패키지로 옮긴다.
핵심은 크지 않다.
사용자는 Goal, Scope, Metric, Verify를 정한다.
에이전트는 한 번에 하나의 변경만 만들고, 검증 명령을 실행하고, 좋아지면 유지하고, 나빠지면 되돌린다.
즉 “에이전트가 알아서 해 준다”가 아니라, 쓰기 가능한 범위와 기계적 지표를 먼저 좁힌 뒤 반복을 맡긴다는 쪽에 가깝다.
무엇을 해결하려는가
현실의 에이전트 워크플로는 실패 기억이 약하다.
한 세션 안에서 여러 시도를 하더라도, 어떤 변경이 왜 좋아졌는지, 어떤 시도가 왜 되돌아갔는지, 이전 실패를 다음 반복에서 어떻게 피할지 체계적으로 남기지 않으면 같은 실험을 반복하기 쉽다.
특히 긴 작업에서는 context compaction, subagent 분기, 로컬 파일 변경, 테스트 실패가 섞이면서 “현재 최고 상태”와 “방금 실패한 가설”이 쉽게 흐려진다.
Autoresearch는 이 문제를 연구 방법론이라기보다 운영 프로토콜로 본다.
좋은 자동 반복에는 네 가지가 필요하다.
첫째, 수정 가능한 파일 범위가 작아야 한다.
둘째, 평가 기준은 사람이 그때그때 판단하는 감상이 아니라 숫자로 뽑히는 검증 명령이어야 한다.
셋째, 한 반복의 변경은 원자적이어야 한다.
넷째, 실패한 변경은 git을 통해 되돌아가고, 성공한 변경은 기록으로 남아야 한다.
이 접근은 ML 실험에만 갇히지 않는다.
README는 코드, 콘텐츠, 마케팅, 세일즈, HR, DevOps처럼 “숫자로 측정 가능한 목표가 있는 모든 영역”을 예로 든다.
다만 여기서 중요한 단어는 “모든 영역”이 아니라 “측정 가능한”이다.
Autoresearch가 잘 맞는 작업은 에이전트가 창의적으로 마음껏 바꿔도 되는 작업이 아니라, 검증 명령이 변경의 생사를 결정할 수 있는 작업이다.
핵심 아이디어 / 구조 / 동작 방식
Autoresearch의 기본 루프는 단순하다.
먼저 현재 상태와 git history, 이전 결과 로그를 읽는다.
다음으로 아직 시도하지 않았거나 이전에 가능성이 있었던 한 가지 변경을 고른다.
변경을 적용하고, 검증 전에 experiment: 성격의 커밋을 남긴다.
이후 테스트·벤치마크·점수 추출 같은 기계 검증을 실행한다.
지표가 좋아지면 커밋은 유지된다.
나빠지면 git revert로 폐기된다.
검증이 깨지면 제한된 횟수 안에서 고치거나 스킵한다.
마지막으로 결과를 TSV에 기록하고 다음 반복으로 넘어간다.
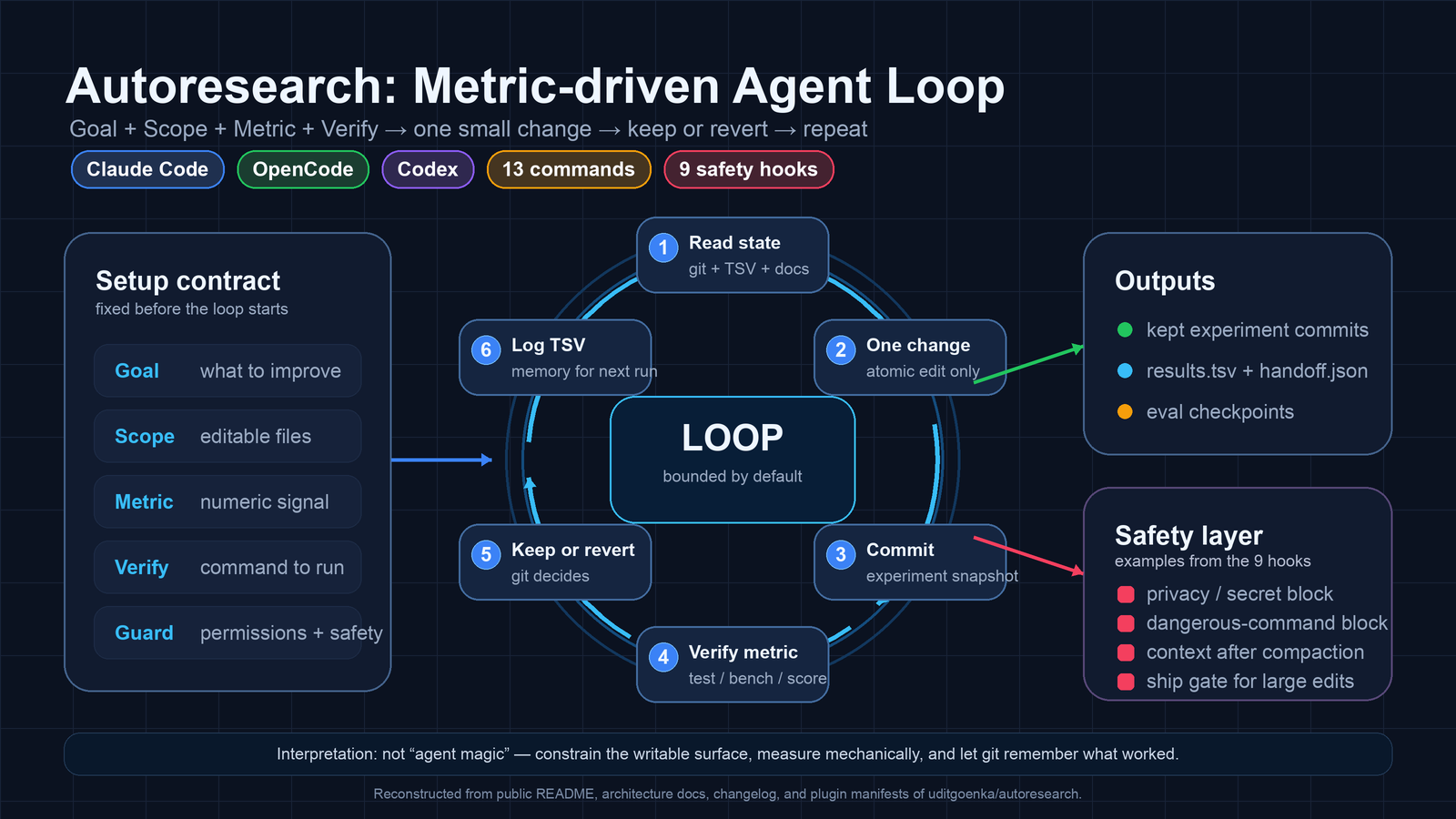
v2.1 계열의 더 큰 변화는 이 루프를 하나의 거대한 SKILL.md에 몰아넣지 않았다는 점이다.
저장소 문서는 v2.1.0에서 813줄짜리 monolithic skill을 41줄 수준의 routing file과 12개 이상의 self-contained command file로 쪼갰다고 설명한다.
README와 architecture 문서는 이 재구성으로 invocation당 토큰 비용이 약 100K에서 5~8K 수준으로 줄어, 대략 95% token reduction을 얻었다고 주장한다.
현재 README 기준 명령 집합은 13개다.
| 명령 | 역할 | 기본 반복 |
|---|---|---|
/autoresearch |
핵심 modify → verify → keep/discard 루프 | 25 |
/autoresearch:plan |
목표를 Scope, Metric, Verify 설정으로 변환 | one-shot |
/autoresearch:debug |
가설을 세우고 검증하며 버그를 추적 | 15 |
/autoresearch:fix |
테스트·타입·lint 오류를 하나씩 0으로 줄임 | 20 |
/autoresearch:security |
STRIDE + OWASP 기반 보안 감사 | 15 |
/autoresearch:ship |
checklist, dry-run, ship, verify를 거치는 출시 흐름 | linear |
/autoresearch:scenario |
12개 차원의 edge case 생성 | 20 |
/autoresearch:predict |
5개 expert persona의 사전 토론 | one-shot |
/autoresearch:learn |
코드베이스 scout → 문서 생성 → 검증 → 수정 | 10 |
/autoresearch:reason |
blind judge를 둔 adversarial reasoning | 8 |
/autoresearch:probe |
8개 persona로 요구사항을 캐묻고 제약을 표면화 | 15 |
/autoresearch:improve |
ICP, 경쟁 공백, 시장/UX/수익 관점에서 개선 후보와 PRD 생성 | 15 |
/autoresearch:evals |
과거 TSV 결과의 추세, plateau, regression 분석 | one-shot |
이 표에서 보듯 Autoresearch는 단순한 “무한 반복 명령” 하나가 아니다.
핵심 루프 주변에 plan, debug, fix, security, ship, scenario, predict, learn, reason, probe, improve, evals를 붙여서, 에이전트 작업의 앞단 탐색과 뒤단 평가를 함께 패키징하려 한다.
OpenCode에서는 underscore 명령 형태를 쓰고, Codex에서는 $autoresearch debug처럼 mention syntax를 쓰는 식으로 플랫폼별 표면도 따로 제공한다.
공개된 근거에서 확인되는 점
GitHub API와 저장소 파일을 기준으로 보면 uditgoenka/autoresearch는 빠르게 움직이는 초기 오픈소스 에이전트 패키지다.
조회 시점 기준 저장소는 2026년 3월 13일 생성됐고, 기본 브랜치는 master, 라이선스는 MIT, latest release는 2026년 5월 23일의 v2.1.2 — Product Improvement Engine이다.
API 값으로는 약 4.7k stars, 358 forks, open issue 1개가 확인된다.
| 근거 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| PyTorchKR 커뮤니티 글 | Claude Autoresearch를 Claude Code skill로 소개하고, Karpathy autoresearch의 원리를 확장한 도구로 설명 | 커뮤니티 확산의 출발점이지만 기술 claim은 공식 repo로 재검증해야 함 |
| 공식 GitHub README | Claude Code, OpenCode, OpenAI Codex 지원, 13 commands, 9 safety hooks, 95% token reduction 주장 | 단일 Claude Code skill에서 멀티플랫폼 개선 엔진으로 포지셔닝이 커짐 |
docs/system-architecture.md |
thin routing SKILL.md, 13 self-contained command files, transform layer, platform distributions 구조 |
스킬 문서 하나보다 command distribution architecture가 핵심이 됨 |
docs/project-changelog.md |
v2.1.0 modular rebuild, v2.1.1 hook system, v2.1.2 product-improvement command 추가 | 5월 하순에 기능과 구조가 연속적으로 바뀐 빠른 릴리스 흐름 |
claude-plugin/.claude-plugin/plugin.json |
version 2.1.2, 13 commands, MIT, author/repository metadata |
Claude plugin 배포 표면은 최신 README와 대체로 일치 |
.claude-plugin/marketplace.json, Codex plugin manifest |
일부 metadata는 2.1.0 또는 2.1.0-codex.0, 12 commands로 남아 있음 |
빠른 변화 속도 때문에 배포 메타데이터 간 drift가 존재할 수 있음 |
guide/hooks.md |
hooks are fail-open, privacy/dangerous-command/context-injection/notification 등 9개 hook 설명 | 안전장치를 제공하지만, hook crash 시 작업을 막지 않는 설계라는 한계도 명시됨 |
특히 v2.1.1의 9-hook 시스템은 주목할 만하다.
README와 hook guide는 scout-block, privacy-block, dangerous-cmd-block, iteration-context, subagent-context, dev-rules-reminder, simplify-gate, session-init, stop-notify를 설명한다.
이들은 node_modules, .git, __pycache__ 같은 context-wasting directory 접근을 막거나, .env, SSH key, credentials 파일 접근을 막거나, force-push·git reset --hard·위험한 rm -rf를 차단한다.
또한 긴 루프 중 TSV state를 다시 주입하거나, 세션 종료 알림을 보내는 역할도 한다.
다만 이 안전장치는 절대적 샌드박스가 아니다. hook 문서는 hook이 crash하면 exit 0으로 허용하는 fail-open 설계를 명시한다.
이는 개발 흐름을 hook 오류 하나로 멈추지 않게 만드는 실용적 선택이지만, 보안 모델 관점에서는 “보조 가드레일”이지 “강한 격리”가 아니다.
따라서 Autoresearch를 실제 repo에 붙일 때는 검증 명령, scope, 권한, branch 전략을 여전히 사람이 잘 설계해야 한다.
또 하나 흥미로운 부분은 공식 product page와 GitHub repo 사이의 시간차다. udit.co/projects/autoresearch 페이지는 여전히 Claude Code 중심의 v1.0.3 설명과 보안 감사 명령을 크게 다룬다.
반면 GitHub README와 changelog는 v2.1.2, 멀티플랫폼, 13 commands, product-improvement research까지 훨씬 넓어진 상태다.
이 차이는 문서 품질 문제라기보다, 프로젝트가 짧은 기간에 “Claude Code용 루프 스킬”에서 “여러 agent host에 배포되는 개선 workflow 묶음”으로 빠르게 이동하고 있다는 신호에 가깝다.
실무 관점에서의 해석
Autoresearch의 가장 좋은 점은 자율성을 낭만화하지 않는다는 데 있다.
많은 agent 도구가 “스스로 고친다”는 문장으로 끝나는 반면, 이 저장소는 범위, 지표, 검증 명령, git rollback, TSV logging을 반복적으로 강조한다.
즉 에이전트의 지능보다 실험 설계의 형태를 제품화하려는 쪽이다.
실무적으로는 세 부류의 작업에 잘 맞는다.
첫째, test coverage, lint/type error count, benchmark latency, bundle size처럼 숫자가 명확한 코드 품질 작업이다.
둘째, security audit나 scenario generation처럼 체크리스트와 증거 수집이 중요한 반복 작업이다.
셋째, docs update나 product improvement research처럼 결과물을 만들되, 중간 산출물을 log와 handoff file로 남기는 작업이다.
반대로 metric이 빈약한 영역에서는 위험하다.
예를 들어 “글을 더 좋게 만들기”, “UI를 더 예쁘게 만들기”, “전략을 더 설득력 있게 만들기” 같은 작업은 검증 명령이 약하면 agent가 쉽게 proxy metric을 과최적화할 수 있다.
Autoresearch가 말하는 mechanical verification은 강점이지만, 그 mechanical signal이 잘못 설계되면 자동화는 잘못된 방향으로 더 빠르게 달린다.
또 하나의 실무 포인트는 branch와 권한이다.
Autoresearch는 실패한 변경을 되돌리고 성공한 변경을 커밋으로 남기는 방식이라 git history를 적극적으로 사용한다.
이 방식은 실험 로그를 남기기에 좋지만, 실제 제품 repo에서는 작업 브랜치, CI 비용, secret 접근, 배포 권한을 분리하지 않으면 부담이 커질 수 있다.
README의 safety invariant도 push, publish, deploy에는 명시적 사용자 승인이 필요하다고 둔다.
이건 기능 제한이라기보다 좋은 기본값이다.
내가 보기엔 Autoresearch의 가치는 “AI가 밤새 연구를 해 준다”보다 더 실용적인 곳에 있다.
반복 가능한 개선 문제를 보면, 사람은 목표와 검증식을 설계하고, agent는 작고 검증 가능한 변경을 많이 시도한다.
이 역할 분담이 맞아떨어질 때 Autoresearch는 coding agent를 대화형 보조자에서 작은 실험 운영자로 바꾼다.
반대로 검증식이 불명확하거나 scope가 넓으면, 같은 루프는 빠른 삽질 기계가 될 수도 있다.
그래서 이 프로젝트를 볼 때 핵심 질문은 “얼마나 자율적인가”가 아니다.
더 좋은 질문은 “이 작업의 성공을 숫자로 정의할 수 있는가, 그 숫자가 정말 원하는 품질을 대변하는가, 실패했을 때 되돌아갈 수 있는가”다.
그 세 가지에 답할 수 있다면 Autoresearch류 루프는 앞으로 많은 agent workflow의 기본 패턴이 될 가능성이 있다.