실시간 객체검출 모델의 경쟁은 오랫동안 CNN 계열과 YOLO류의 압축된 detector가 주도했다.
Transformer 기반 detector는 구조적으로 깔끔하고 end-to-end 학습이 가능했지만, 실제 배포에서는 지연 시간과 메모리, 그리고 도메인 전이 문제가 늘 따라붙었다.
반대로 GroundingDINO나 YOLO-World 같은 open-vocabulary detector는 강력한 범용성을 보여 주지만, 특정 산업 데이터셋에 맞춰 빠르게 돌려야 하는 상황에서는 무거운 text encoder와 latency가 병목이 된다.
Roboflow와 CMU의 RF-DETR: Neural Architecture Search for Real-Time Detection Transformers는 이 중간 지점을 정면으로 노린다.
핵심은 “더 큰 VLM을 fine-tuning하자”가 아니라, DINOv2로 얻은 시각 representation을 specialist DETR로 가져오고, weight-sharing neural architecture search로 목표 데이터셋과 하드웨어에 맞는 accuracy-latency Pareto curve를 찾자는 것이다.
논문은 이 접근이 COCO와 RF100-VL에서 실시간 detector의 frontier를 끌어올린다고 주장하고, 공식 저장소는 detection과 instance segmentation을 같은 rfdetr 패키지로 공개한다.
무엇을 해결하려는가
논문이 겨냥하는 문제는 두 겹이다.
첫째, open-vocabulary detector는 COCO처럼 웹 pre-training과 잘 맞는 범주에서는 강하지만, 실제 현장의 out-of-distribution class나 도메인 특화 이미지에서는 쉽게 흔들릴 수 있다. fine-tuning을 하면 in-domain 성능은 올라가지만, text encoder까지 포함한 무거운 VLM 구조는 실시간 배포에 불리하고 open-vocabulary generalization도 약해질 수 있다.
둘째, 기존 specialist detector는 빠르지만 COCO 중심으로 과도하게 조정된 경우가 많다.
특정 architecture, learning-rate schedule, augmentation recipe가 COCO validation 성능에 맞춰진 채 다른 데이터셋으로 넘어가면, “빠른 모델”이라는 장점만으로는 충분하지 않다.
Roboflow가 함께 제시하는 RF100-VL은 100개 object detection 데이터셋을 묶어 이런 전이성과 도메인 다양성을 보려는 benchmark다.
RF-DETR의 제안은 여기서 출발한다.
하나의 고정된 detector를 내놓는 대신, target dataset을 한 번 fine-tuning한 뒤 patch size, resolution, decoder depth, query 수, window attention 구성을 바꾼 여러 sub-network를 다시 학습하지 않고 평가한다.
즉 모델 선택을 “N/S/M/L 중 하나를 고른다”가 아니라 현장 latency budget에 맞는 Pareto point를 검색한다로 바꾼다.
핵심 아이디어 / 구조 / 동작 방식
RF-DETR는 LW-DETR 계열을 기반으로 하지만, backbone을 CAEv2에서 DINOv2 ViT로 바꾼다.
DINOv2는 더 느릴 수 있지만, self-supervised pretraining에서 얻은 시각 feature가 작은 데이터셋과 다양한 도메인에서 더 강한 전이 신호를 준다는 것이 논문의 해석이다.
이 손실을 NAS가 다시 회수한다.
느린 backbone을 그대로 쓰는 것이 아니라, 어느 resolution과 patch size, decoder/query 조합이 특정 latency 안에서 가장 좋은지를 찾는 방식이다.
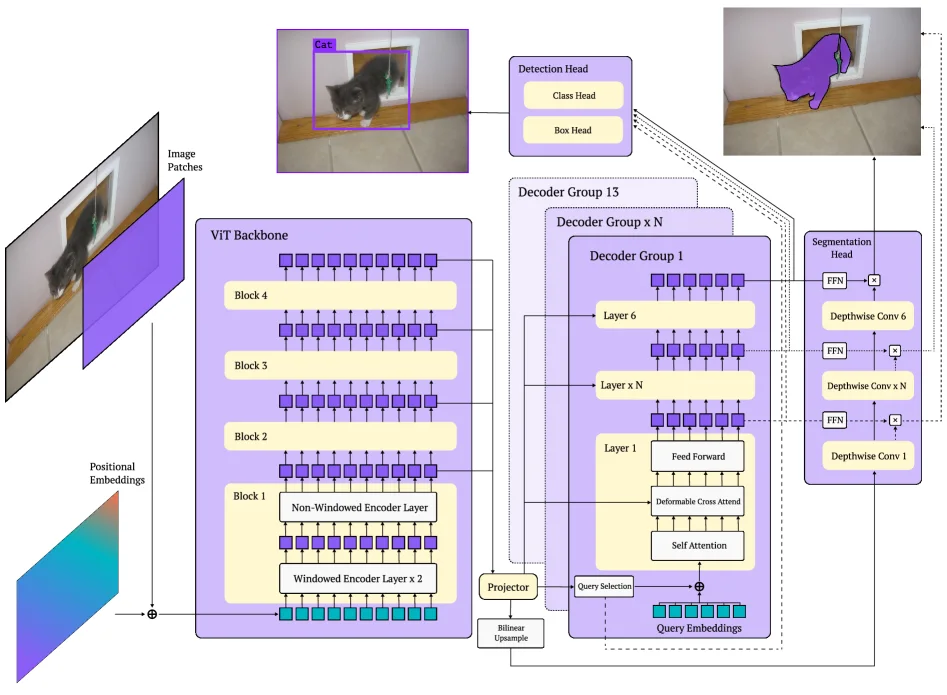
구조적으로는 세 가지가 눈에 띈다.
첫째, multi-scale feature projector에서 BatchNorm 대신 LayerNorm을 사용한다.
작은 batch나 다양한 데이터셋에서 foundation backbone의 지식을 덜 깨뜨리기 위한 선택으로 읽힌다.
둘째, windowed attention과 non-windowed attention을 interleave해 latency와 global context 사이의 균형을 맞춘다.
셋째, segmentation head는 MaskDINO/YOLACT식 prototype mask 계열에 가까운 가벼운 구조로 붙어, 같은 계열에서 detection과 instance segmentation을 함께 다룬다.
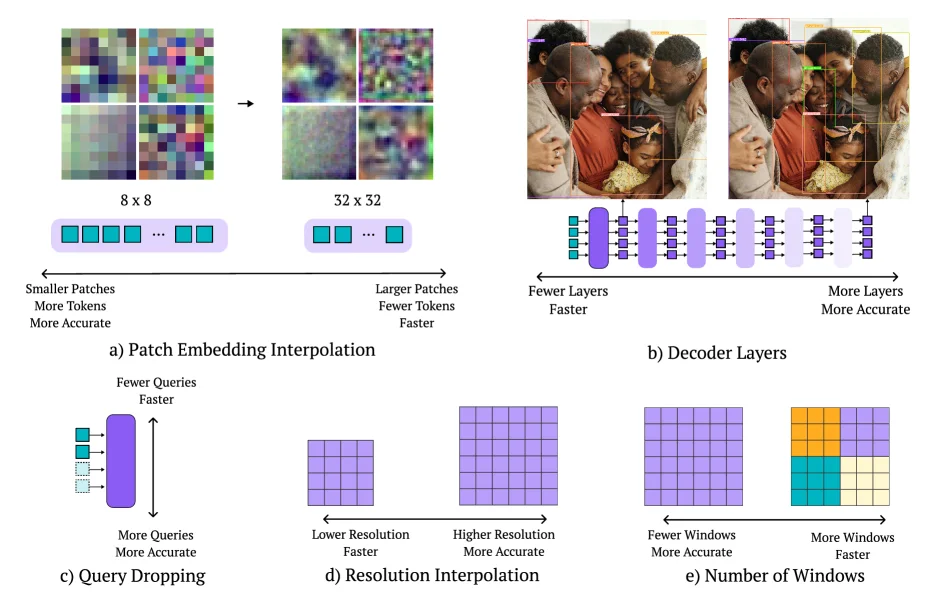
NAS search space도 단순한 width/depth scaling이 아니다.
논문은 다음 knobs를 함께 다룬다.
| NAS knob | 바꾸는 것 | 실무적 의미 |
|---|---|---|
| Patch size | ViT tokenization granularity | 토큰 수와 작은 객체 표현 사이의 균형 |
| Image resolution | 입력 해상도 | 작은 객체 recall과 latency의 직접 trade-off |
| Decoder layers | DETR decoder depth | 정확도와 decoder 지연 시간 조절 |
| Query tokens | object query 수 | dense scene에서 후보 수와 계산량 조절 |
| Attention windows | windowed attention block 구성 | local/global context와 latency 조절 |
공개된 근거에서 확인되는 점
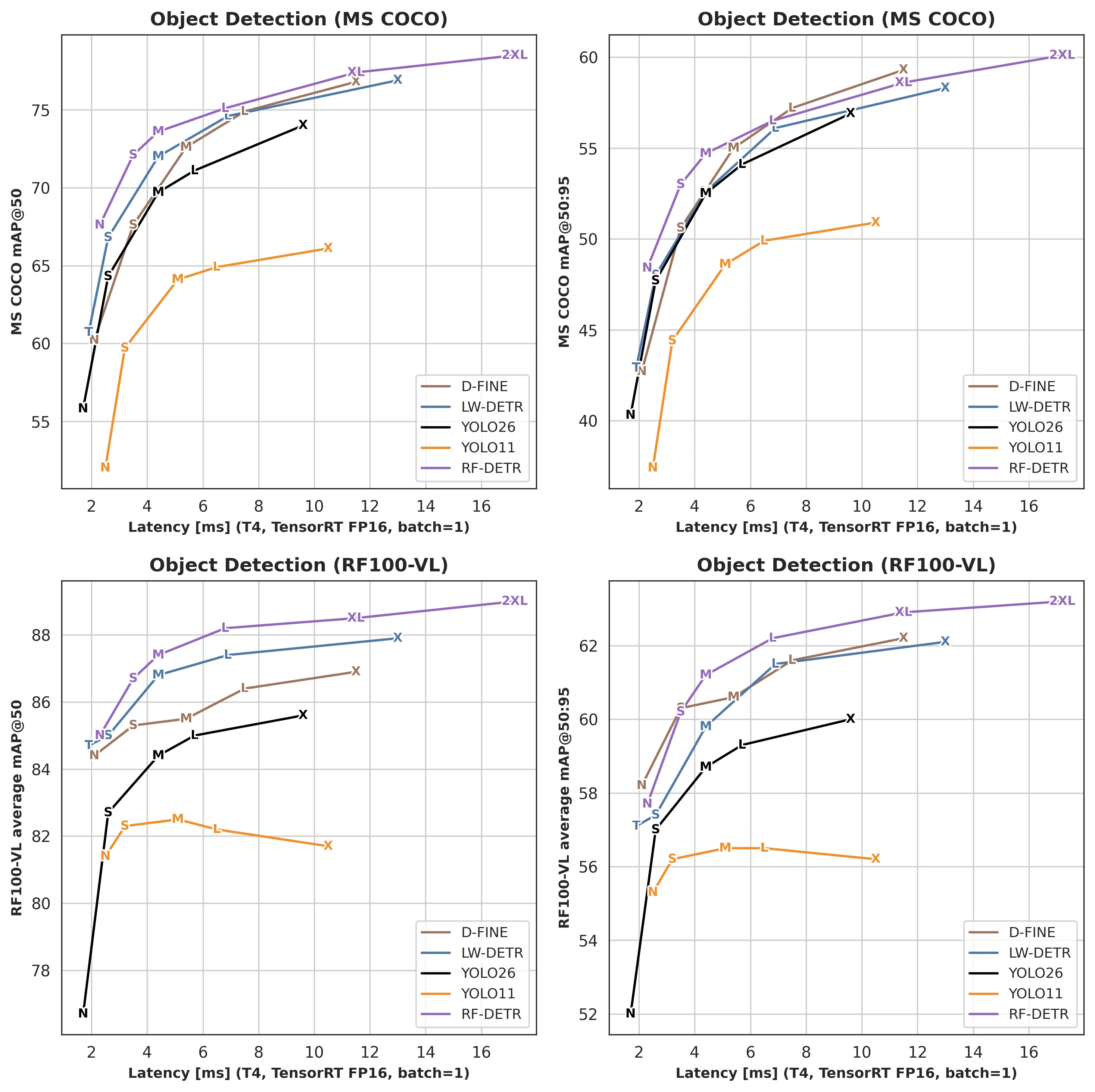
논문 초록의 가장 큰 headline은 RF-DETR 2XL이 COCO에서 60.1 AP를 기록하며 “실시간 detector 중 처음으로 COCO 60 AP를 넘었다”고 주장하는 대목이다.
또 RF-DETR Nano는 논문 표 기준 COCO에서 2.3ms / 48.0 AP를 기록해 D-FINE Nano보다 5.3 AP 높다고 보고된다.
현재 공식 문서의 release table은 RF-DETR-N을 48.4 AP50:95 / 2.3ms, RF-DETR-L을 56.5 AP50:95 / 6.8ms, RF-DETR-2XL을 60.1 AP50:95 / 17.2ms로 제시한다.
| 모델 | COCO AP50:95 | COCO AP50 | RF100-VL AP50:95 | RF100-VL AP50 | Latency | Params | 비고 |
|---|---|---|---|---|---|---|---|
| RF-DETR-N | 48.4 | 67.6 | 57.7 | 85.0 | 2.3 ms | 30.5M | Apache 2.0 |
| RF-DETR-L | 56.5 | 75.1 | 62.2 | 88.2 | 6.8 ms | 33.9M | Apache 2.0 |
| RF-DETR-2XL | 60.1 | 78.5 | 63.2 | 89.0 | 17.2 ms | 126.9M | Plus / PML 1.0 |
RF100-VL 결과도 이 논문에서 중요하다. paper table 기준 RF-DETR 2XL fine-tuned variant는 RF100-VL에서 63.5 AP / 89.0 AP50 / 15.6ms를 보고한다.
같은 표의 GroundingDINO Tiny는 62.3 AP / 88.8 AP50 / 309.9ms로 제시된다.
논문이 강조하는 “GroundingDINO Tiny보다 1.2 AP 높고 약 20배 빠르다”는 주장은 이 비교에서 나온다.
다만 이 latency는 측정 경로가 모델마다 다를 수 있으므로, 논문은 TensorRT 지원 여부와 PyTorch latency를 구분해 별표로 표시한다.
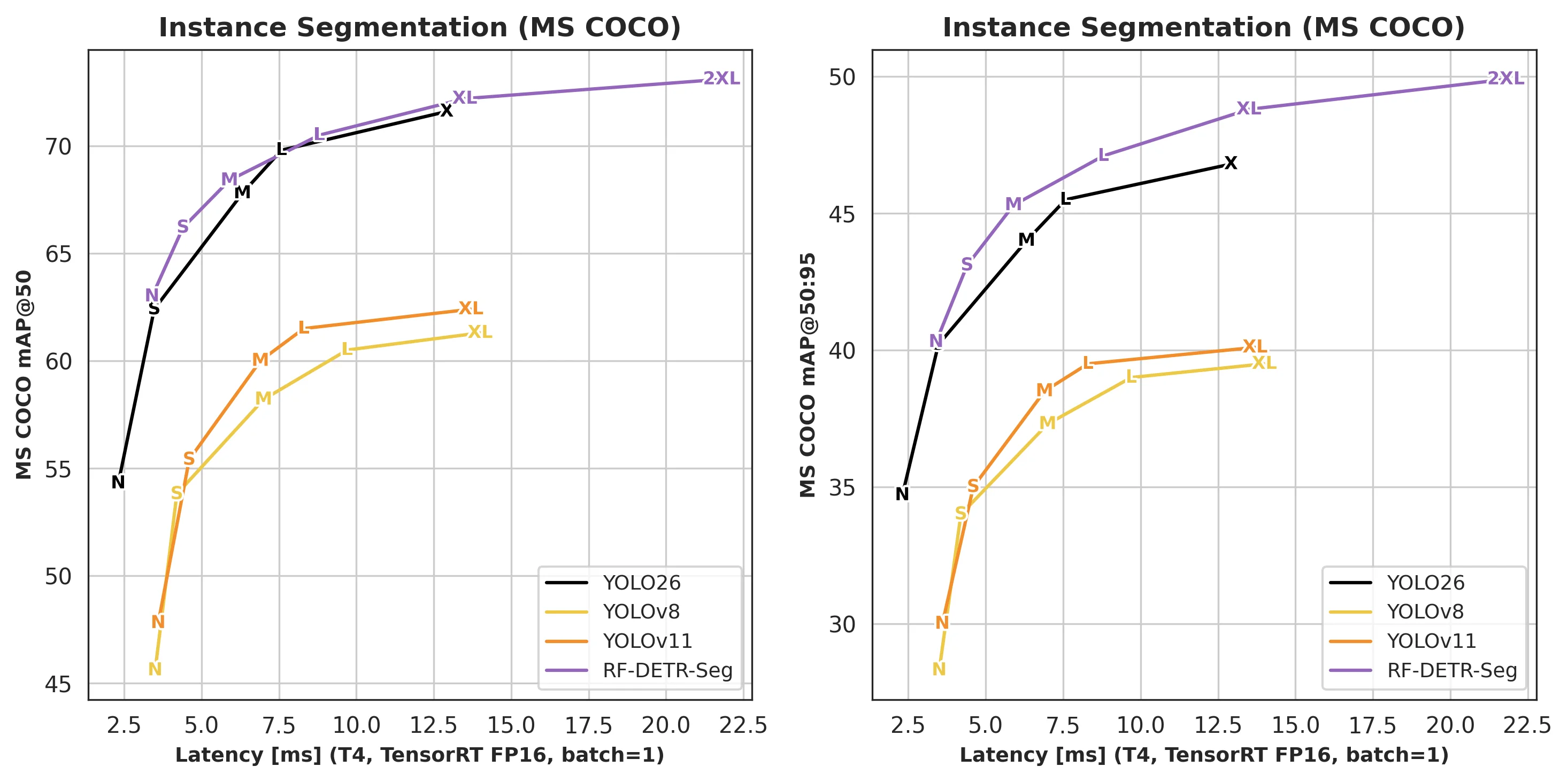
Segmentation 확장도 단순 부록이 아니다.
공식 문서의 RF-DETR-Seg 표에서 Seg-N은 40.3 COCO AP50:95 / 3.4ms, Seg-L은 47.1 / 8.8ms, Seg-2XL은 49.9 / 21.8ms를 기록한다.
논문과 문서는 RF-DETR-Seg Nano가 YOLOv11-Seg XL보다 높은 COCO AP를 더 낮은 지연 시간으로 낸다는 점을 강조한다.
또 하나 중요한 근거는 latency benchmarking 방식이다.
논문은 GPU power throttling과 overheating이 latency variance를 크게 만든다고 지적하고, forward pass 사이에 200ms buffer를 둔 측정 방식을 사용한다.
이는 sustained throughput을 재려는 목적이 아니라, accuracy와 latency를 같은 artifact에서 재현 가능하게 비교하려는 장치다.
실무적으로는 이 대목이 꽤 중요하다. detector benchmark는 mAP 숫자보다 latency 측정 조건이 더 쉽게 흔들리기 때문이다.
공개 릴리스 표면도 확인된다.
GitHub 저장소 roboflow/rf-detr는 기본 브랜치가 develop이고, 2026년 5월 26일 확인 시점에 약 7.3k stars / 937 forks를 갖고 있다.
최신 GitHub release와 PyPI stable package는 1.7.0이며, PyPI의 rfdetr는 Python >=3.10을 요구한다.
README와 문서는 기본 rfdetr 패키지와 Apache-designated 모델을 Apache 2.0으로 설명하지만, rfdetr_plus와 RF-DETR-XL/2XL detection 모델은 PML 1.0으로 분리한다.
따라서 “코드가 공개됐다”와 “모든 weight/variant가 동일한 오픈소스 라이선스다”는 같은 말이 아니다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv v2 | 2025-11-12 제출, 2026-02-03 업데이트, ICLR 2026 | 연구 논문은 CC BY 4.0 |
| GitHub | roboflow/rf-detr, 최신 release 1.7.0 |
학습·추론·export·benchmarking 도구를 포함한 공개 코드베이스 |
| PyPI | pip install rfdetr, Python >=3.10, stable 1.7.0 |
실제 패키지 배포 경로가 있음 |
| Plus package | pip install rfdetr[plus] |
XL/2XL detection variant는 별도 라이선스 경계 필요 |
| Docs | ONNX, TensorRT, TFLite export 언급 | 연구 모델보다 배포 스택을 의식한 프로젝트 |
실무 관점에서의 해석
RF-DETR의 의미는 “Transformer detector도 빠르다”보다 조금 더 구체적이다.
실무에서 중요한 것은 어떤 모델 하나가 leaderboard의 한 점을 찍었느냐가 아니라, 데이터셋과 하드웨어가 바뀔 때 latency budget 안에서 다시 최적점을 찾을 수 있느냐다.
RF-DETR는 DINOv2 backbone의 표현력을 그대로 가져오되, 배포 시점에는 resolution, patch, query, decoder depth를 조절해 여러 operating point를 만든다.
이건 foundation backbone을 product detector로 번역하는 방식에 가깝다.
그 점에서 RF-DETR는 open-vocabulary detector와 직접 같은 역할을 하는 모델은 아니다.
GroundingDINO류가 “처음 보는 이름을 텍스트로 지정해 찾는” 범용성을 노린다면, RF-DETR는 target dataset에 맞춘 closed-vocabulary specialist detector다.
대신 text encoder를 떼고, DETR-style end-to-end detector와 TensorRT/ONNX/TFLite 배포 경로를 중심에 둔다.
즉 새로운 class를 prompt로 던져 찾는 모델이 아니라, 현장의 class set과 latency constraint를 정해 놓고 강하게 fine-tuning하는 모델로 읽어야 한다.

장점만 있는 것은 아니다.
RF-DETR의 작은 모델은 파라미터 수만 보면 YOLO Nano류보다 훨씬 크다.
예를 들어 공식 문서의 RF-DETR-N은 30.5M parameters이고, YOLO11-N은 2.6M parameters다.
RF-DETR가 주장하는 이득은 “가장 작은 모델”이 아니라 비슷한 실시간 latency envelope에서 더 높은 AP를 얻는다는 쪽이다.
따라서 메모리 footprint, cold start, TensorRT build, edge accelerator 지원, 모델 라이선스까지 같이 봐야 한다.
또한 NAS 기반 workflow는 제품팀에게 새로운 운영 질문을 만든다.
어떤 데이터셋에서는 작은 객체가 많아 query와 resolution이 중요할 수 있고, 어떤 데이터셋에서는 window count나 decoder depth가 latency 대비 효율적일 수 있다.
논문 부록은 RF100-VL dataset characteristics와 architecture knobs의 상관관계를 분석하지만, 강한 선형 규칙 하나로 끝나지는 않는다.
실무적으로는 “RF-DETR 기본 모델을 가져다 쓰면 끝”이 아니라, target dataset에서 search/evaluation loop를 제대로 돌릴 수 있는 MLOps가 필요하다.
내가 보기에 RF-DETR의 가장 흥미로운 지점은 비전 Transformer 시대의 다음 병목을 정확히 짚는다는 데 있다.
이제 더 강한 backbone을 만드는 것만으로는 충분하지 않다.
DINOv2 같은 pretraining prior를 실제 공장, 의료, 문서, 항공, 스포츠, 농업 이미지 데이터셋에서 몇 ms 안에 동작하는 detector로 바꾸는 능력이 중요해졌다.
RF-DETR는 그 번역 과정을 architecture search와 배포 benchmark로 묶은 사례다.
그래서 이 논문은 vision foundation model의 “끝”이라기보다, foundation representation을 실시간 specialist model family로 제품화하는 방향의 신호로 읽는 편이 맞다.
범용 open-vocabulary 모델이 모든 현장 문제를 해결하지 못하는 한, 앞으로도 많은 팀은 closed-vocabulary detector를 fine-tuning하고 latency budget 안에서 압축해야 한다.
RF-DETR는 그 작업을 더 체계적인 Pareto search 문제로 재정의한다는 점에서 의미가 있다.